
- 1阿里大数据之路:数据模型篇大总结(收藏)
- 2PostgreSQL - 查询表结构和索引信息_postgres 查询表的索引字段信息
- 3Android Studio的Gradle错误解决方法_android studio 错误 丢失的gradle项目信息。请检查ide是否成功地将其状态与gr
- 4FPGA原理和结构- 理解FPGA的基础知识_fpga原理和结构天野英晴pdf
- 5一文读懂:区块链的原理、技术、应用领域_区块链技术应用总结
- 6记录一下一些收藏的网页
- 7【开源物联网平台】FastBee使用EMQX5.0接入步骤_java 开源的物联网项目
- 8大数据相关招聘岗位可视化分析-毕业设计_基于大数据的招聘岗位可视化分析与展示
- 9【深度学习论文翻译】基于LSTM深度神经网络的时间序列预测(Time Series Prediction Using LSTM Deep Neural Networks)_epochs = configs['training']['epochs'],
- 10ecc加解密算法 c++_ECC相关算法解析
【腾讯云云上实验室】从零开始搭建爬虫+向量数据库+LLM大模型构建企业私有化知识库_基于私有大模型构建企业知识库
赞
踩
1. 前言
本文主要论证从零开始搭建爬虫->向量数据库->LLM大模型知识库过程,文章中不依赖任何爬虫、LangChain、Chat GLM等框架,从最原始角度通俗易懂、直观的解读大模型与向量数据库结合过程,给大家提供现阶段热门企业大模型解决方案建设思路和方向。
目前流行的中文开源大模型非ChatGLM(智普)、baichuan(百川)等莫属。虽然认知能力赶不上ChatGPT 3.5,但是它的开源吸引了广大的AI研究者。
目前大语言模型存在最大的问题在于:
1、研究成本高,如果搭建一个13B以及以上的模型,全量运行需要24GB以上显存,如果进行量化质量又达不到要求,前期研究就要投入大量成本并且如果有多个LLM项目并行开发就会遇到项目组之间抢资源问题;
2、训练成本高,回报率随机,对于广大进行“炼丹”的“仙人”们都知道,炼丹最大问题在于整理的训练集、训练轮数及各种参数可能导致炼出废丹,并且知识的日益更新,如果要更新知识就要重新训练;
3、胡乱说话(幻想),幻想就是你问一个问题,它有板有眼儿的给你回答,你不是专业人士可能就会被它的回答误导了。LLM的幻想并非真正的幻想,而是由其训练方式和数据源所决定的,LLM通过大量的互联网文本数据进行训练,这些数据包含了各种话题和语境。
以上就是目前LLM模型常见的问题,对于模型的研发者和使用者都是头痛问题。针对企业级AI应用,目前有个大家探索的方案就是向量数据库+LLM大模型结合,解决研究成本、训练及胡乱说话问题,通过知识库中准确的内容弥补数据的不足导幻想。
其原理就是将知识要点存储到向量数据库,在提问时通过分词或大模型对提问内容进行分解,从向量数据库提取出关键内容,然后再将内容喂给LLM模型,从而得到想要的答案,从而实现了AI数据库的可维护性,这个模型可以用于OpenAI API也可以用于LLM私有化模型。
接下来,我们从探索的角度来研究向量数据库+LLM大模型的应用(这里不使用LangChain 东西,因为他们封装很深不适合从原理上研究探索)

2. 实现目标
本次目标是搭建一个腾讯云向量数据库LLM知识问答系统:
1、搭建向量数据库(这里使用 腾讯云向量数据库Tencent Cloud VectorDB);
2、开发知识库采集及存储工具
(1) 编写爬虫工具,实现知识库数据爬取;
(2) 编写数据存储服务
3、开发LLM大模型对话功能,并将向量数据库知识库加入到大模型对话中来;
环境准备:
Python:3.10
LLM:ChatGLM 3
运行环境:Windows11 WSL2 Ubuntu22.04
开发工具:VsCode
3. 开发爬虫及知识库存储工具
3.1. 环境搭建
创建一个独立的python虚拟环境,内容存储再venv中
python -m venv venv激活venv执行:
vectorenv\Scripts\activate.bat3.2. 爬虫工具开发
确定要爬取的URL地址:
https://cloud.tencent.com/document/product/1709
编写Crawling.py爬虫,爬取向量知识库内容
引入依赖包:
- import requests
- import json
- import re
- from bs4 import BeautifulSoup
引用依赖:
- pip install bs4
- pip install lxml
定义相关变量:
- seed = "https://cloud.tencent.com/document/product/1709"
- baseUrl="https://cloud.tencent.com"
- appendUrlList=[]
- appendDataList = []
获取栏目所及子栏目所有URL地址,这里通过textarea的J-qcSideNavListData CSS进行定位,并从文本中得到JSON没描述信息。
- def getCrawl(seed):
- seeds = []
- seeds.append(seed)
- textdata = requests.get(seed).text
- soup = BeautifulSoup(textdata,'lxml')
- nodes = soup.select("textarea.J-qcSideNavListData")
- jsonObj=json.loads(nodes[0].getText())["list"]
- seeds.append(nodes)
- getChild(jsonObj)
-
- def getChild(nowObj):
- if nowObj is not None:
- for n in nowObj:
- links= baseUrl+n["link"]
- data={"title":n["title"],"link":links}
- appendUrlList.append(data)
- if n.get("children") is not None:
- getChild(n.get("children"))

遍历爬取到的地址信息,来获取指定页面正文内容,这里对正文中的html标签需要去除,不然会有大量干扰内容:
- def crawlData():
- getCrawl(seed)
- for data in appendUrlList:
- url = data["link"]
- print("正在爬取:"+data["title"]+" "+data["link"])
- textdata = requests.get(url).text
- soup = BeautifulSoup(textdata,'lxml')
- nodes = soup.select("div.J-markdown-box")
- if nodes is not None and len(nodes)>0:
- text = nodes[0].get_text()
- text = text[:20000] #这里需要截取长度,不然会出现过长溢出
- stringText = re.sub('\n+', '\n', text)
- data={"url":url,"title":data["title"],"text":stringText}
- appendDataList.append(data)
- return appendDataList
至此,知识库动态获取部分完成,比较简单吧!
3.3. 向量知识库存储功能开发
3.3.1创建腾讯云向量数据库
腾讯云向量数据库目前低配置可免费使用,只需要在控制台搜索:向量数据库

选择一个你所在最近地域,点击新建创建一个

创建一个免费的测试版向量数据库

进入实例,开启外网访问:

设置允许访问的IP地址,如果只是测试用那就写0.0.0.0/0,这样所有ip都能访问,也省得多IP网络去研究自己到底哪个外网IP要进白名单

得到外网IP:
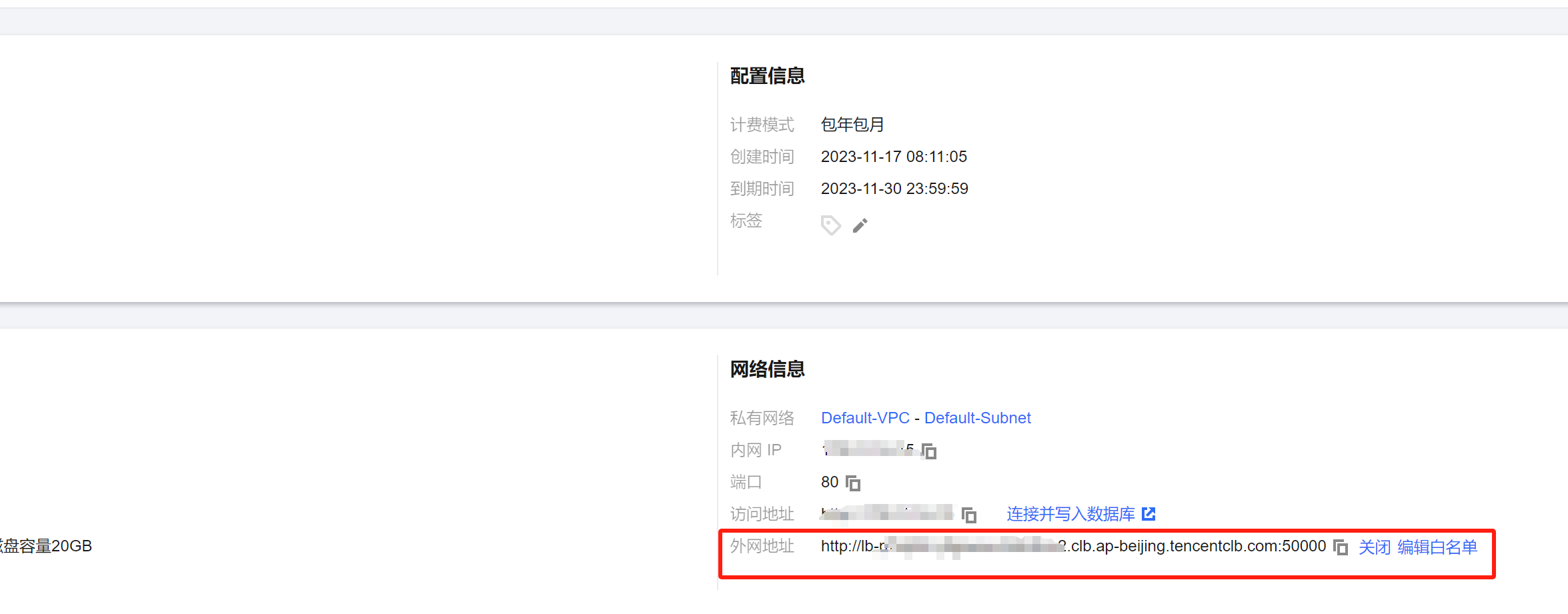
获取密钥:

得到这些信息了就可以将信息写入到代码中了。
另外如果你想要查询录入的数据或者创建库和集合也可以点DMC登录到管理端进行查看:

登录DMC

查询数据
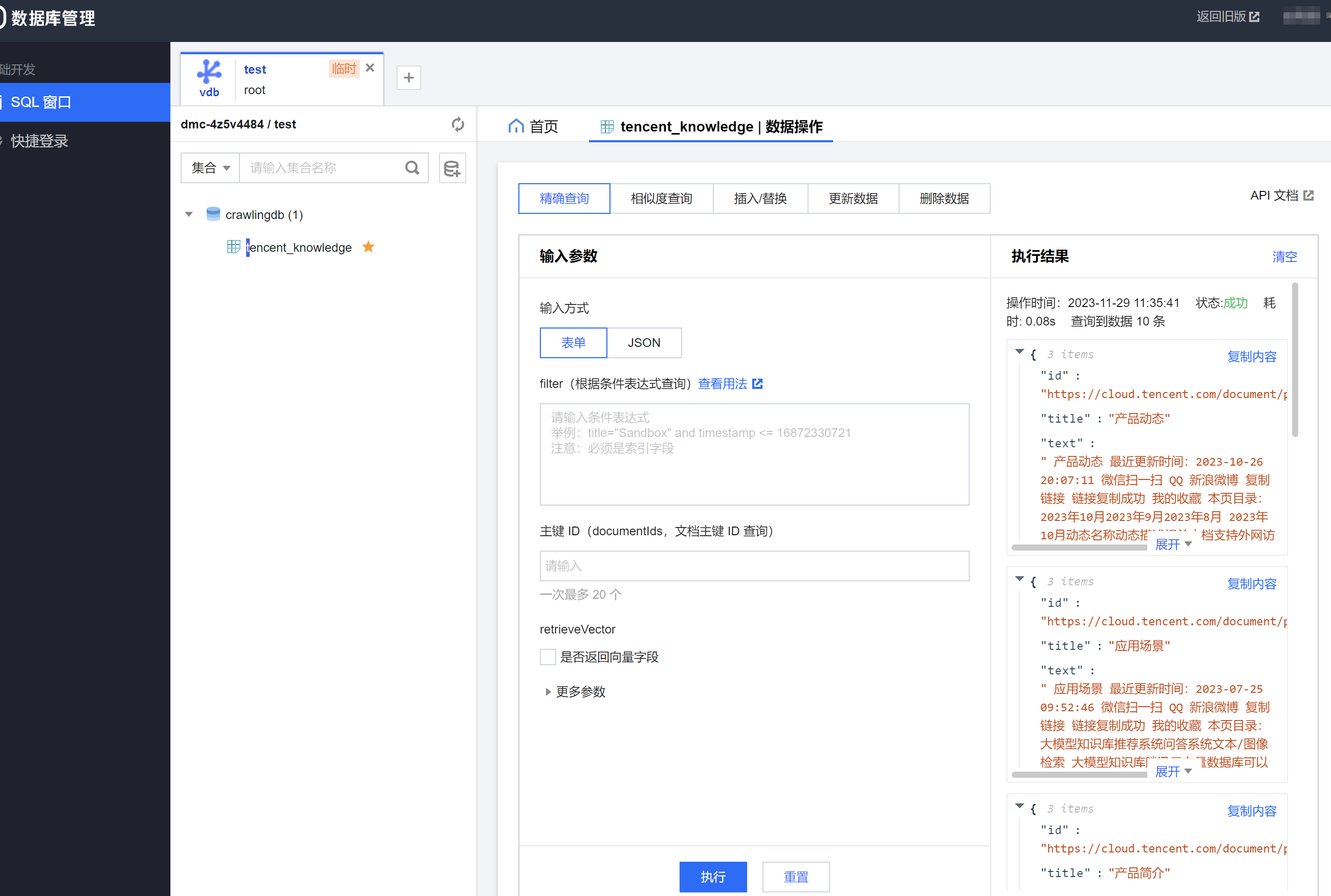
3.3.2开发向量存储
开始前需要注意:
1.【重要的事】向量对应的文本字段不要建立索引,会浪费较大的内存,并且没有任何作用。
2.【必须的索引】:主键id、向量字段vector这两个字段目前是固定且必须的,参考下面的例子;
3.【其他索引】:检索时需作为条件查询的字段,比如要按书籍的作者进行过滤,这个时候author字段就需要建立索引,
否则无法在查询的时候对author字段进行过滤,不需要过滤的字段无需加索引,会浪费内存;
4.向量数据库支持动态Schema,写入数据时可以写入任何字段,无需提前定义,类似MongoDB.
5.例子中创建一个书籍片段的索引,例如书籍片段的信息包括{id,vector,segment,bookName,page},
id为主键需要全局唯一,segment为文本片段,vector为segment的向量,vector字段需要建立向量索引,假如我们在查询的时候要查询指定书籍
名称的内容,这个时候需要对bookName建立索引,其他字段没有条件查询的需要,无需建立索引。
6.创建带Embedding的collection需要保证设置的vector索引的维度和Embedding所用模型生成向量维度一致,模型及维度关系:
创建TencentVDB.py文件
引入依赖包
- from Crawling import crawlData
- import tcvectordb
- from tcvectordb.model.collection import Embedding
- from tcvectordb.model.document import Document, Filter, SearchParams
- from tcvectordb.model.enum import FieldType, IndexType, MetricType, EmbeddingModel, ReadConsistency
- from tcvectordb.model.index import Index, VectorIndex, FilterIndex, HNSWParams, IVFFLATParams
关闭debug模式
tcvectordb.debug.DebugEnable = False创建一个class TencentVDB类,里面分块解释含义:
初始化链接tcvectordb的客户端,相关信息稍后在main传入
- def __init__(self, url: str, username: str, key: str, timeout: int = 30):
- """
- 初始化客户端
- """
- # 创建客户端时可以指定 read_consistency,后续调用 sdk 接口的 read_consistency 将延用该值
- self._client = tcvectordb.VectorDBClient(url=url, username=username, key=key,
- read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=timeout)
创建数据库和集合,这里也可以去腾讯云DMC中创建:
创建数据库和集合
- def create_db_and_collection(self):
- database = 'crawlingdb'
- coll_embedding_name = 'tencent_knowledge'
-
- # 创建DB--'book'
- db = self._client.create_database(database)
- database_list = self._client.list_databases()
- for db_item in database_list:
- print(db_item.database_name)
-
-
- index = Index()
- index.add(VectorIndex('vector', 1024, IndexType.HNSW, MetricType.COSINE, HNSWParams(m=16, efconstruction=200)))
- index.add(FilterIndex('id', FieldType.String, IndexType.PRIMARY_KEY))
- index.add(FilterIndex('title', FieldType.String, IndexType.FILTER))
- ebd = Embedding(vector_field='vector', field='text', model=EmbeddingModel.TEXT2VEC_LARGE_CHINESE)
-
- # 第二步:创建 Collection
- # 创建支持 Embedding 的 Collection
- db.create_collection(
- name=coll_embedding_name,
- shard=3,
- replicas=0,
- description='爬虫向量数据库实验',
- index=index,
- embedding=ebd,
- timeout=50
- )
Embedding可以选择多种
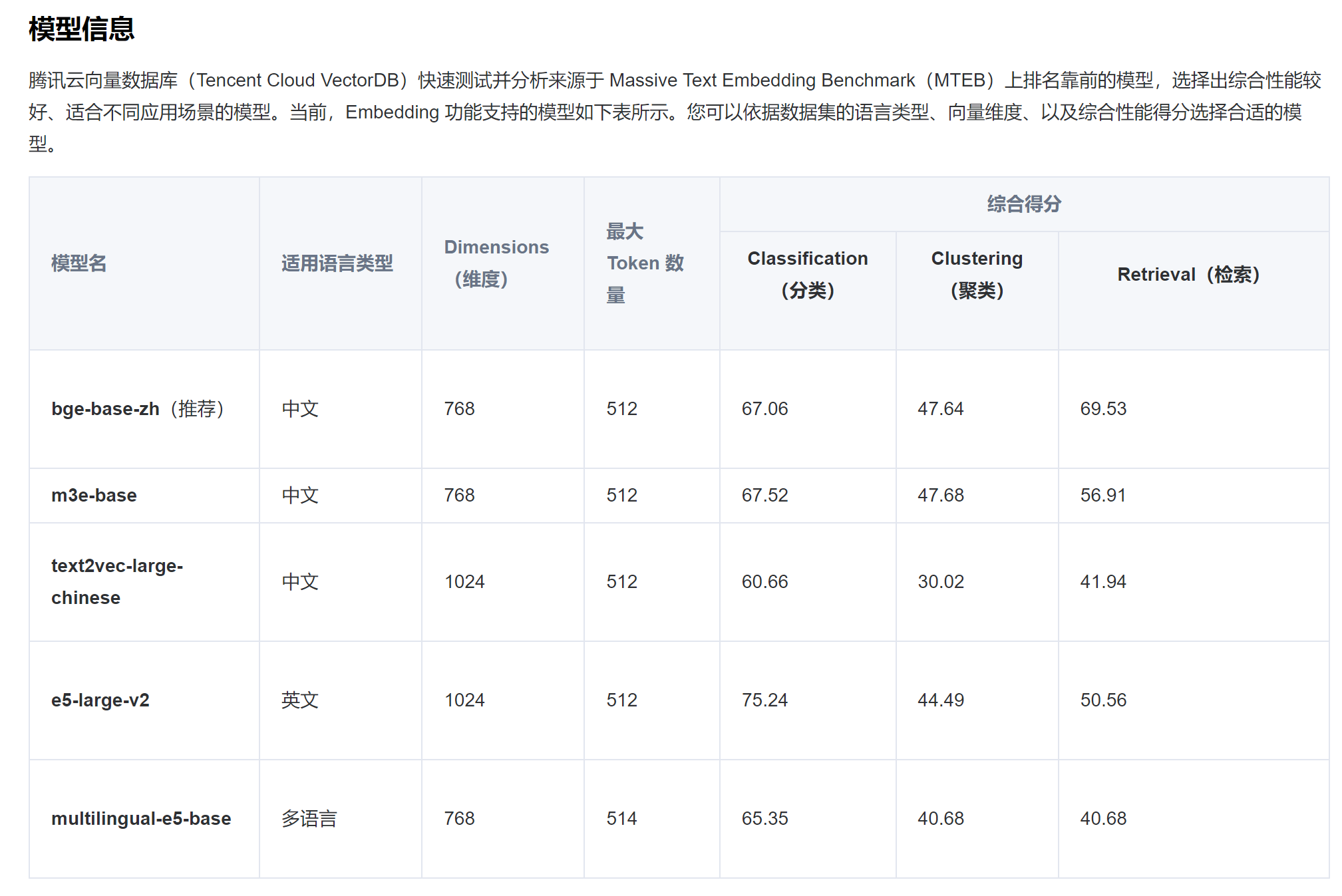
可根据实际情况选择需要使用的模型
以上模型枚举代码位置:\venv\Lib\site-packages\tcvectordb\model\enum.py
- BGE_BASE_ZH = ("bge-base-zh", 768)
- M3E_BASE = ("m3e-base", 768)
- TEXT2VEC_LARGE_CHINESE = ("text2vec-large-chinese", 1024)
- E5_LARGE_V2 = ("e5-large-v2", 1024)
- MULTILINGUAL_E5_BASE = ("multilingual-e5-base", 768)
调用爬虫并写入数据到向量数据库
- def upsert_data(self):
- # 获取 Collection 对象
- db = self._client.database('book')
- coll = db.collection('book_segments')
-
- # upsert 写入数据,可能会有一定延迟
- # 1. 支持动态 Schema,除了 id、vector 字段必须写入,可以写入其他任意字段;
- # 2. upsert 会执行覆盖写,若文档 id 已存在,则新数据会直接覆盖原有数据(删除原有数据,再插入新数据)
- data = crawlData()
- docList =[]
- for dd in data:
- docList.append(Document(id=dd["url"],
- text=dd["text"],
- title=dd["title"]))
- coll.upsert(documents=docList,build_index=True)
- print("成功将数据写入腾讯云向量数据库")
调用:
- if __name__ == '__main__':
- test_vdb = TencentVDB('http://xxxxxxxx.clb.ap-beijing.tencentclb.com:50000', key='xxxxx', username='root')
- test_vdb.upsert_data()
执行后会输出:
如果提示:
code=1, message=There was an error with the embedding: token rate limit reached 说明采集内容过多,免费账户限流了,需要删除一些已存储的集合。
登录查看数据是否入库:

4.开发LLM模型对话功能
LLM使用ChatGLM3,这个模型我还是比较喜欢的它的6B速度快,数据的准确性也比较高,我这边进行提问时大概要14G显存,如果显存少可以根据实际情况进行量化或者用autodl 之类云厂商虚拟化服务,反正搭建一套到验证完也不要10块钱。
引入依赖
创建文件 requirements.txt
- protobuf
- transformers>=4.30.2
- cpm_kernels
- torch>=2.0
- gradio~=3.39
- sentencepiece
- accelerate
- sse-starlette
- streamlit>=1.24.0
- fastapi>=0.104.1
- uvicorn~=0.24.0
- sse_starlette
- loguru~=0.7.2
- streamlit
导入LLM依赖
pip install -r requirements.txt下载ChatGLM3模型,国内下载地址:
https://modelscope.cn/models/ZhipuAI/chatglm3-6b/
https://modelscope.cn/models/ZhipuAI/chatglm3-6b-base/
https://modelscope.cn/models/ZhipuAI/chatglm3-6b-32k/summary
三选一即可,32K主要是支持长文本内容对话,模型比较大十多个G 最好放到固态硬盘上,能降低加载时间
编码ChatGLM聊天对话,这里使用streamlit作为聊天对话UI框架
引入依赖包:
- import os
- import streamlit as st
- import torch
- from transformers import AutoModel, AutoTokenizer
设定模型位置,我这里代码和THUDM目录在同一位置,也可以使用绝对路径指向下载好的模型文件夹
- MODEL_PATH = os.environ.get('MODEL_PATH', 'THUDM/chatglm3-6b')
- TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)
判断当前处理器是否Nvidia显卡,或者是否装了cuda驱动,如果没装请参考我这篇文章:
https://blog.csdn.net/cnor/article/details/129170865
进行cuda安装。
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'设置标题
- # 设置页面标题、图标和布局
- st.set_page_config(
- page_title="我的AI知识库",
- page_icon=":robot:",
- layout="wide"
- )
获取model,判断使用cuda还是cpu来计算
- @st.cache_resource
- def get_model():
- tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)
- if 'cuda' in DEVICE: # AMD, NVIDIA GPU can use Half Precision
- model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).to(DEVICE).eval()
- else: # CPU, Intel GPU and other GPU can use Float16 Precision Only
- model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).float().to(DEVICE).eval()
- # 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
- # from utils import load_model_on_gpus
- # model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
- return tokenizer, model
编写页面左侧一些调节开关以及历史聊天记录内容处理,支持历史内容分析。
- # 加载Chatglm3的model和tokenizer
- tokenizer, model = get_model()
-
- # 初始化历史记录和past key values
- if "history" not in st.session_state:
- st.session_state.history = []
- if "past_key_values" not in st.session_state:
- st.session_state.past_key_values = None
-
- # 设置max_length、top_p和temperature
- max_length = st.sidebar.slider("max_length", 0, 32768, 8000, step=1)
- top_p = st.sidebar.slider("top_p", 0.0, 1.0, 0.8, step=0.01)
- temperature = st.sidebar.slider("temperature", 0.0, 1.0, 0.8, step=0.01)
-
-
- # 清理会话历史
- buttonClean = st.sidebar.button("清理会话历史", key="clean")
- if buttonClean:
- st.session_state.history = []
- st.session_state.past_key_values = None
- if torch.cuda.is_available():
- torch.cuda.empty_cache()
- st.rerun()
-
- # 渲染聊天历史记录
- for i, message in enumerate(st.session_state.history):
- print(message)
- if message["role"] == "user":
- with st.chat_message(name="user", avatar="user"):
- st.markdown(message["content"])
- else:
- with st.chat_message(name="assistant", avatar="assistant"):
- st.markdown(message["content"])
-
- # 输入框和输出框
- with st.chat_message(name="user", avatar="user"):
- input_placeholder = st.empty()
- with st.chat_message(name="assistant", avatar="assistant"):
- message_placeholder = st.empty()
-
获取输入内容,使用model.stream_chat将数据内容发给transformers以流的形式打印输出出来。
- # 获取用户输入
- prompt_text = st.chat_input("请输入您的问题")
-
- # 如果用户输入了内容,则生成回复
- if prompt_text:
- input_placeholder.markdown(prompt_text)
- history = st.session_state.history
- past_key_values = st.session_state.past_key_values
- history = []
- for response, history, past_key_values in model.stream_chat(
- tokenizer,
- prompt_text,
- history,
- past_key_values=past_key_values,
- max_length=max_length,
- top_p=top_p,
- temperature=temperature,
- return_past_key_values=True,
- ):
- # print(response)
- message_placeholder.markdown(response)
- st.session_state.history = history
- st.session_state.past_key_values = past_key_values
以上步骤已经完成了大模型对话部分,后续将基于上述代码进行补充,完成与腾讯云向量数据库的对接,这里可以选择腾讯云也可以选择用Milvus等。
输出结果:

这时输入向量还是模型自己原始的理解没有和腾讯云向量数据库相关知识。
5腾讯云向量数据库与LLM大模型结合
在第四步基础上,我们需要进行以下内容补充即可完成本次大模型知识库开发
增加腾讯云向量数据库查询功能
- def searchTvdb(txt):
- conn_params = {
- 'url':'http://lb-xxxxx.clb.ap-beijing.tencentclb.com:50000',
- 'key':'xxxxxxxxxxxxxxxxxx',
- 'username':'root',
- 'timeout':20
- }
-
- vdb_client = tcvectordb.VectorDBClient(
- url=conn_params['url'],
- username=conn_params['username'],
- key=conn_params['key'],
- timeout=conn_params['timeout'],
- )
- db_list = vdb_client.list_databases()
-
- db = vdb_client.database('crawlingdb')
- coll = db.collection('tencent_knowledge')
- embeddingItems = [txt]
- search_by_text_res = coll.searchByText(embeddingItems=embeddingItems,limit=3, params=SearchParams(ef=100))
- # print_object(search_by_text_res.get('documents'))
- # print(search_by_text_res.get('documents'))
- return search_by_text_res.get('documents')
-
- def listToString(doc_lists):
- str =""
- for i, docs in enumerate(doc_lists):
- for doc in docs:
- str=str+doc["text"]
- return str
用户从向量数据库查询出内容,在内容前部增加一些辅助性描述,让LLM更容易懂我们对知识库使用的意图。
由于从向量数据库出来的内容比较多,鉴于条件不允许,这里加个开关,对于普通GLM聊天使用历史对话,使用知识库时关闭历史对话。
- def on_mode_change():
- mode = st.session_state.dialogue_mode
- text = f"已切换到 {mode} 模式。"
- st.session_state.history = []
- st.session_state.past_key_values = None
- if torch.cuda.is_available():
- torch.cuda.empty_cache()
-
- st.toast(text)
-
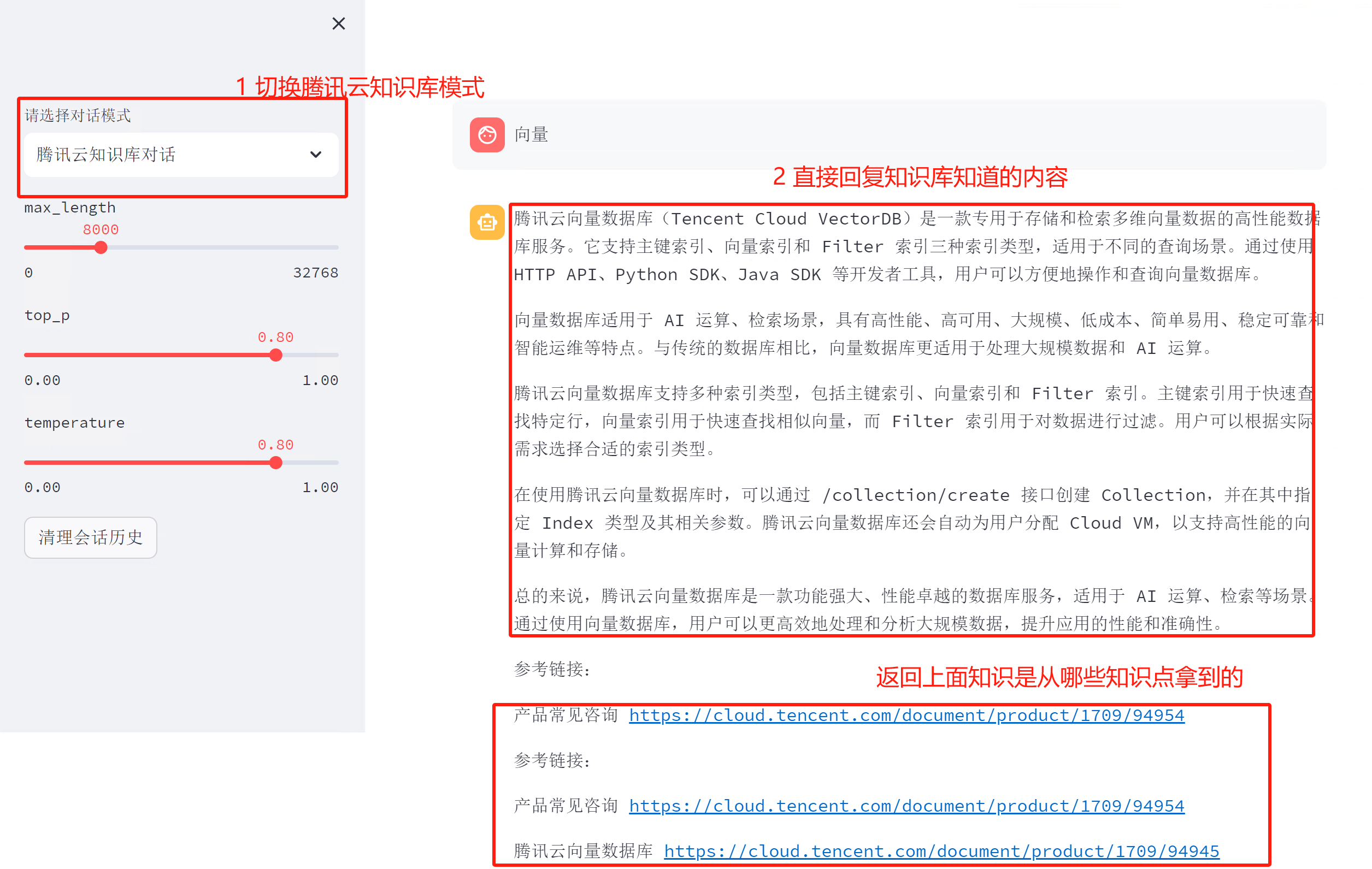
- dialogue_mode = st.sidebar.selectbox("请选择对话模式",
- ["腾讯云知识库对话",
- "正常LLM对话(支持历史)",
- ],
- on_change=on_mode_change,
- key="dialogue_mode",
- )
输入部分改为:
- if prompt_text:
-
- mode = st.session_state.dialogue_mode
- template_data=""
- if mode =="腾讯云知识库对话":
- result = searchTvdb(prompt_text)
- str = listToString(result)
- # print(str)
- template_data = "请按照\""+prompt_text+"\"进行总结,内容是:"+str
- template_data = template_data[:20000]
- else:
- template_data =prompt_text
-
- input_placeholder.markdown(prompt_text)
- history = st.session_state.history
- past_key_values = st.session_state.past_key_values
- history = []
- for response, history, past_key_values in model.stream_chat(
- tokenizer,
- template_data,
- history,
- past_key_values=past_key_values,
- max_length=max_length,
- top_p=top_p,
- temperature=temperature,
- return_past_key_values=True,
- ):
- # print(response)
- message_placeholder.markdown(response)
-
- endString = ""
- # 更新历史记录和past key values
- if mode != "腾讯云知识库对话":
- st.session_state.history = history
- st.session_state.past_key_values = past_key_values
- else:
- for i,doc in enumerate(result[0]):
- # print(doc)
- endString = endString+"\n\n"+doc["title"]+" "+doc["id"]
- response=response+"\n\n参考链接:\n\n\n"+endString
- message_placeholder.markdown(response)
最终成果:
封面
总结
从上面的实践得出结论,通过爬虫+向量数据库+LLM构建自己企业私有化AI模型的道路是可以通的,LLM模型越是强大,AI对向量数据库中内容长度以及认知度会更强。腾讯云向量数据库的性能表现出众,使用简单,Embedding支持类型丰富,大家可以上手试试。

