
- 1Python中模块及函数的引用_python 模块引用
- 2Http-请求和响应数据格式_网页请求行的格式
- 3[Git高级教程 (一)] 通过Tag标签回退版本修复bug_git 利用tag回退
- 4vscode预览github上的markdown效果_markdown preview github styling
- 52018.06.06论文:12个NLP分类模型_nlp语义分类模型
- 6核心算法模板_核心算法设计怎么写
- 7裁员潮2.0,职场人如何求生?
- 8初识EA(Enterprise Architect)_enterprise architect9 发布时间
- 9Spark学习(六):Spark SQL一_org.apache.spark.sql.{dataframe, sqlcontext}
- 10使用注解实现redis分布式锁毕设方案_redis实现分布式锁 注解
基于SpringBoot的图书推荐系统的_数据恢复书籍推荐
赞
踩
摘 要
网络信息技术的高速发展,使得高校图书馆的服务空间日益扩大,依据个人特点的针对性服务逐渐成为新服务模式的主导趋势。对于大多数用户而言,很难在大量的学术图书馆中快速找到他们想要的材料。另外,随着时代的不断发展,越来越多的新兴学科,学科的融合更是普遍。各种专业知识的爆炸性增长使大学图书馆必须扩大书籍的储存量,这是为建立和实施图书馆定制推荐系统提供了基本条件。个性化图书推荐服务改变传统图书馆被动服务方式,能根据用户的兴趣偏好主动地向用户推荐图书。
本文的重点是依据用户的多样需求追踪图书的最近资源,且及时告知用户,实现个性化的服务,且提高资源的使用效果,改变图书馆的服务模式。从被动到主动。协同过滤推荐算法的实现,可以让大学的师生们更方便快捷,且准确的得到自己需要的书目。从而避免了搜索时间造成的浪费。本文所做的工作主要包括以下几点:
(1)本文提出了对冷启动问题的优化、对数据稀疏性问题的完善、对缺失数据的处理操作。
(2)本文既说明了涉及的相关技术,同时进行了可行性和准确性评估,并讨论了个人定制书籍推荐中使用的推荐算法和混合算法。
(3)本文结合推荐系统的实际需求程度,基于SpringBoot的图书推荐系统的研究与实现。
关键词:SpringBoot、推荐算法、LFM
Abstract
With the rapid development of network information technology, the service space of university library is expanding day by day, and personalized service has gradually become the mainstream of new service mode. For most users, it is difficult to find the information they need in the large collection of university library. In addition, with the continuous development of the times, there are more and more new majors, and the professional integration is becoming stronger and stronger. The expansion of all kinds of professional knowledge makes university libraries have to expand their own knowledge storage, which also provides the basic conditions for the construction and implementation of library personalized recommendation system. Personalized book recommendation service has changed the passive service mode of traditional library, which can actively recommend books to users according to their interests.
The problem to be solved in this paper is to track the latest library resources according to the different needs of users, inform users at the first time, realize the optimization of personalized service and resource utilization, and change the library service mode from passive to active. Collaborative filtering recommendation algorithm enables college teachers and students to find the knowledge books they need more accurately and faster, reduces the search pressure of the library and saves a lot of time. The work of this paper mainly includes the following points.
(1) In this paper, the optimization of cold start, the improvement of data sparsity and the processing of missing data are proposed.
(2) This paper discusses the technology involved, analyzes its feasibility and accuracy, and discusses the personalized book recommendation algorithm and hybrid algorithm.
(3)Combined with the actual demand level of book recommendation system, this paper studies and implements a Book Recommendation System Based on springboot.
Key words: SpringBoot, recommendation algorithm, LFM
目 录
摘 要 I
Abstract II
目 录 III
图目录 VI
表目录 VII
第一章 绪论 8
1.1 选题背景及意义 8
1.2 国内外研究现状分析 9
1.2.1 图书管理系统的研究现状 9
1.2.2 推荐系统的研究现状 10
1.2.3 研究综述 11
1.3 研究目标及研究内容 12
1.3.1 研究目标 12
1.3.2 研究内容 12
1.4 本文组织结构 12
第二章 系统需求分析 14
2.1 系统可行性分析 14
2.1.1 经济可行性 14
2.1.2 操作可行性 15
2.1.3 技术可行性 15
2.2 系统角色需求分析 16
2.3 系统功能需求分析 17
2.3.1 图书借阅需求分析 17
2.3.2 图书归还需求分析 17
2.3.3 图书推荐需求分析 18
2.3.4 系统管理需求分析 19
2.4 系统非功能性需求分析 20
第三章 关键技术与难点分析 22
3.1 推荐系统简介 22
3.2 相关推荐算法 22
3.2.1 基于用户推荐 23
3.2.2 基于项目推荐 25
3.2.3 混合推荐 26
3.2.4 LFM算法 27
3.3 系统关键问题及解决方案 29
3.3.1 冷启动问题 29
3.3.2 数据稀疏性问题 30
3.3.3 数据缺失问题 31
第四章 系统总体设计 34
4.1 系统设计目标 34
4.2 系统总体架构设计 35
4.3 系统总体功能结构设计 36
4.4 系统网络架构设计 37
4.5 系统数据库设计 38
4.5.1 MySQL数据库 38
4.5.2 实体E-R图设计 39
4.5.3 数据库表结构设计 40
4.6 系统数据备份及恢复设计 42
4.7 系统接口设计 43
第五章 系统详细设计与实现 44
5.1 系统开发工具及环境 44
5.1.1 开发工具 44
5.1.2 开发环境 44
5.2 系统设计原则 44
5.3 系统功能模块详细设计与实现 45
5.3.1 图书借阅详细设计与实现 45
5.3.2 图书归还详细设计与实现 48
5.3.3 图书推荐详细设计与实现 49
5.3.4 系统管理详细设计与实现 51
第六章 系统测试 54
6.1 系统部署 54
6.2 系统测试方案 55
6.3 系统功能测试 56
6.4 系统性能测试 57
6.5 系统测试结果 58
第七章 总结与展望 60
参考文献 61
附录 64
致谢 69
图目录
图1 管理员用例图 16
图2 读者用例图 16
图3 图书借阅业务流程图 17
图4 图书归还业务流程图 18
图5 图书推荐业务流程图 19
图6 系统管理业务流程图 20
图7 推荐系统模块之间的关系 22
图8 推荐系统的推荐流程 23
图9 用户-项目图 24
图10 形成邻居集的过程 25
图11 项目-用户图 26
图12 混合推荐技术的组合方式 27
图13 LFM模型 28
图14 系统总体架构图 35
图15 系统总体功能结构 37
图16 系统网络拓扑结构图 38
图17 图书属性图 39
图18 读者属性图 39
图19 借阅属性图 40
图20 处罚属性图 40
图21 管理员属性图 40
图22 图书借阅功能结构图 46
图23 图书借阅类图 46
图24 查询借阅情况时序图 47
图25 图书借阅流程图 48
图26 图书归还功能结构图 49
图27 图书归还时序图 49
图28 系统管理功能结构图 52
图29 读者添加时序图 53
图30 Tomcat服务器结构 54
图31 图书借阅实现界面 59
表目录
表1 用户-图书表 23
表2 项目-用户表 25
表3 图书信息表 41
表4 读者信息表 41
表5 借阅信息表 41
表6 处罚信息表 41
表7 管理员信息表 42
表8 磁带库指标特性 42
表9 用户登录功能测试结果 56
表10 用户登录功能测试结果 57
表11 并发用户数与事务执行情况 58
表12 系统响应时间 58
第一章 绪论
1.1 选题背景及意义
随着信息技术的更新和科技的高速发展,我们逐渐地从信息匮乏的阶段过渡到大数据的时代,在互联网的大潮中,人们很容易地就能获取到更多、更全面的信息,但是从哲学的角度来看,可以知道事物具有两面性,当我们获取信息的方式日益快捷的同时,我们需要从这些大量的信息中获得自己真正感兴趣的信息,那么对于信息消费者而言,如何识别并选择出高质量的信息就成为了一项巨大的挑战。另外,对于互联网公司、网络信息提供商来说,如何让自己的信息从海量的数据中脱颖而出,并获得认可,需要投入大量的人力物力支持。正是由于上述矛盾,推荐系统产生了。推荐系统从最初的研究发展到现在,一直都是电子商务系统里的一个极为重要的角色,它的任务就是在用户和信息之间建立一个桥梁,不仅可以方便用户获得自己需要的信息,还能够确保项目的信息被推送给可能对它感兴趣的用户,从而实现信息生产者和信息消费者的双赢。
书籍在人类社会发展的阶梯,传承了一代又一代人的智慧精华,拥有至关重要的地位。人类社会总是向前不断发展,文明程度越来越高,人们对知识的需求和追求欲望愈发强烈,书是知识的主要表达形式,而图书馆作保存着大量的知识,犹如一个仓库,人们想要学习知识,普离不开图书馆,因为图书馆书籍浩如烟海,想要在图书馆迅速找到自己需要的书籍不是件容易事,提高图书馆的效率已成为人们迫切希望的问题。就目前来看,很多图书借阅系统还是存在很多问题,如界面繁杂、操作不便、不能实时推荐等,因此建设一个界面友好、操作简便的具有实时推荐的图书馆管理系统非常重要。图书馆传统的管理方法难以满足于当前时代发展的现实需要,在图书馆当中引进信管系统,能够有效地改善对应的管理基本过程,为管理者和读者带来相当大的方便。优秀的信管系统可以增强图书馆内部管理,避免内部图书资源的流失,优化读者借阅的基本体验,切实地提升检索效率,并且带来个性化的图书推荐功能,由此为所有用户带来具有针对性的体验。因此本论文开展对图书推荐系统进行研究具有较高的现实意义。
1.2 国内外研究现状分析
1.2.1 图书管理系统的研究现状
20世纪50年代初,最早的国外图书馆管理系统起源于美国。而图书馆管理系统的真正发展是在1964年LC提出了著名的“马尔克计划”,即以机器可读形式地记录图书馆的书目纪录。到了1970年以后,自动化系统逐渐成形,还开始出现联机编目协作网。直到1990年以后,图书馆的局域网发展到了与Internet相连接目前,在国外,像一些比较先进的国家,如美国和澳大利亚等,有几个比较大的软件公司已开发出比较著名的图书馆管理系统,如Aleph500系统和Horizon系统等。Aleph500系统的智能化程度较高,它所采用的关系数据库很大程度上提高了系统的安全性能和稳定性能,它还釆用了两种结构:多层客户机服务体系结构和分布式逻辑结构。当下位列世界领先的水平的Horizon系统,其自动化程度较高。它是一个全面开放的系统,它的产生基于互联网,需要采用UI界面和B/S结构的相关体系结构,可用于多重标准平台上。
随着科技的发展,大多数以前依赖纯人工管理模式的图书馆正逐渐通过使用计算机来实现对图书馆管理,管理及服务逐步实现自助化及自动化,随着电子书的普及,图书馆内的文献资源也将逐步实现电子化、数字化,届时读者只需在图书馆借阅自己所需书籍即可。图书馆在社会中的角色非常重要,负责图书采购、编目整顿和推动文化传播等各项工作,有力地保障了人们的学习和研究,为他们提供借阅、参考资料文献的服务。
在图书馆管理系统研究上,马玉祥提出了一个基于Deep Web数据集成的系统结构,并且根据这个系统结构对Deep Web数据集成中最为困难的“模式匹配”问题进行了深入的研究分析,进而提出了相应的模型和算法。这一算法和模型的问世为Dep web馆藏图书集成查询系统的设计与实现提供了至关重要的技术支持,并且在Deep Web数据集成方面有较大的应用价值。
田青重点对有关图书馆图书管理系统的相关使用功能需求进行介绍,并在此基础上提出数据库设计方案,并对此方案进行改进,弥补了之前相关数据库设计的不足。刘晶等研发的小型图书管理系统,用C#开发前端界面和后台业务,用SQL作为数据库来存放读书信息。实现了信息管理、借还操作、图书排列及信息查询等多个必须功能。从结果上看前期工作已基本上满足日常图书管理工作的基本需求。何芸将移动AR与代理技术相结合,提出其在图书馆领域的应用架构,运用Android、VuforiaSDK、JADE等工具研究该架构的具体实现,并对架构中移动AR、情景敏感代理和用于排架、查询和动态情景更新的算法进行剖析。与当前图书管理系统相比,该系统使得服务与管理更泛在、更容易以及更智能。通过进一步的修改,这个系统可以有效地执行当前真实世界中图书馆繁重的图书管理任务。
1.2.2 推荐系统的研究现状
追本溯源,上个世纪九十年代,明尼苏达大学的一个名为“GroupLens”的研究小组的研究人员设计出了一款GroupLens系统。该系统用来向用户推荐其感兴趣的文章,它作为推荐系统的“鼻祖”,设计出了基于用户的协同过滤推荐引擎。而正是这个推荐模型为后来的推荐系统提供了方向,基于这个模型,人们又设计出了一系列的推荐算法,诸如:基于SVD的协同过滤推荐算法、基于项目的协同过滤算法等,目前常用的推荐算法还有基于内容的推荐、基于协同过滤算法的推荐、基于知识的推荐等。
国内的推荐系统起步较晚,但是到现在也有了较好的应用。淘宝、网易云音乐等网站或者软件上都会有“推荐”模块。其中,淘宝推荐系统的核心目标就是将买家、卖家和商品相互联系起来,其推荐规则有:基于内容的推荐;采用搜索引擎的技术,根据用户的实时搜索记录为其推荐优质的相关的宝贝;优质宝贝的推荐;基于关联规则的推荐等。
国外的亚马逊对推荐算法是基于ItemCF的研究,即是基于物品的协同过滤算法,是一种基于统计的算法,通过对上述算法的优化,形成余弦相似度算法,进行物品相似度的计算,建立起物品的相似度矩阵。由于亚马逊的用户数量比较庞大,可达到千万至上亿个,所以他们采用基于物品的相似度矩阵代替基于用户的相似度矩阵,大大的从时间和空间上减少了开销。
美国康奈尔大学的研究学者设计了一款叫做Mylibrary的网络个性化的电子图书推荐系统。该系统是基于查询分析设计的,它由两大部分组成:MyLinks和MyUpdates。其中,MyLinks可以让用户自己来搜索并整理包括本校电子图书以及其他互联网中的电子资源,相当于针对用户个人的自主服务的主页;MyUpdates部分可以及时地通知读者新到的电子图书资源,比如说,定期地告知读者他们可能会感兴趣的新到的图书、期刊等,这样可以帮助读者减少查询资料的时间,还提升了读者对系统的使用兴趣。
国内的最为有名的图书推荐系统有“豆瓣读书”、当当网的图书推荐系统等。其中,豆瓣网的“豆瓣猜”用到了基于用户的协同过滤推荐技术,首先对于如何确定应该推荐哪些种类的图书,豆瓣猜的核心理念在于为用户提供“具有媒体性的产品”,也就是说为用户提供尽可能多样化的、符合其兴趣的、还能够被广泛传播的图书;然后对真实的数据集进行深入的挖掘分析,根据用户对的关注、评分、收藏等行为分析出用户的偏好特点,从而将符合用户兴趣的图书进行推荐。总的来说就是先广泛撒网,然后根据用户的反馈有的放矢地进行个性化推荐。另外,豆瓣网的推荐引擎还使用了分布式的平台对推荐算法进行改造,缩短了推荐过程中的运算间,减少了运算的内存,有效地缓解了推荐系统面临海量数据时存在的瓶颈问题。
1.2.3 研究综述
通过了解国际上图书推荐系统发展的实际情况,发现其重点存在如下问题:
(1)在对图书馆管理系统的发展历程进行全面了解的基础上可发现,其在初期仅为一种单机版的系统,但在局域网技术持续创新的基础上,逐渐产生了C/S模式的图书馆管理系统,在以往深受人们的欢迎,其在20世纪末期中,是运用最为频繁的一种系统架构模式,现阶段人们仍旧持续运用该种模式的图书馆管理系统,大部分地方图书馆以及高校内运用的管理系统仍是该类系统。虽然相较于初期的系统,C/S模式相对较为良好,但其也存在着不可避免的问题,例如资源共享性、平台封闭性、功能弹性等方面的问题,而现阶段传统业务难以与数字资源整合起来,难以运用数字资源实现相应的技术标准,因此,对新技术进行开发以使图书馆管理需求得到满足的工作开展刻不容缓。
(2)以往的图书鉴购系统大体上是基于手工建立的,因此采访人员在对荐购图书记录进行统计以及读者对图书的荐购等方面的便利性相对较低。
(3)在以往的图书荐购模式中,由于信息传递相对较为复杂,读者在对图书进行荐购时,会规定其应在特定的时间地点内集中开展,过程相对较为繁杂,而在该种地点和时间便利性相对较低的影响下,读者运用图书荐购系统的次数相对较少,所以,图书荐购系统推广的难度相对较高。
而本文是在与图书馆存在的具体的业务需求融合的基础上设计了图书推荐系统并实现了相应的功能。在搭建一个将图书馆业务包含在内的集中统一的一体化管理系统的基础上,对处于领先地位的网络爬虫和大数据技术进行运用,以使网站和该系统间资源的整合可得以良好的达成。在基础功能得到满足的标准下,还额外将图书推荐功能加入其中,将私人特定的读书喜好个性化的推荐至所有用户。与以往的图书推荐系统对比,该系统可个性化定制或推荐图书至所有的用户,使读者对图书的查阅和借阅更加高效,进而使用户的满意度得以提高。
1.3 研究目标及研究内容
1.3.1 研究目标
设计出一个存在着实时推荐功效、操作可靠便捷、界面简单友好的图书推荐系统是本文研究设计工作的主要宗旨。使图书馆各种资源如期刊、图书等有关信息的借阅更加高效,使图书馆管理人员的负担得以缩减是本文研究设计工作的主要目的。为了对所有读者的信息资源进行良好的整合,对本系统开发的统计模块进行细分,将其划分为四大模块,其中包含图书馆所有方面的内容,可全面的统计图书馆总体的业务。
在总结本系统存在的需求目标的基础上,得到以下结论:
(1)将图书信息供应至读者,使其可对图书进行查询、借阅、归还;
(2)将实时推荐功能供应至读者;
(3)达到全流程追踪图书借阅和归还过程的数据信息的目标;
(4)将图书借阅排行榜予以供应,将实际的数据信息供应至图书管理员。
1.3.2 研究内容
本文的主要研究内容有如下几个方面:
(1)分析图书管理系统及推荐系统的研究背景、国内外研究现状分析,并发现限制其发展的因素。
(2)深入研究推荐算法,包括常见的协同过滤算法、基于内容的推荐算法等,并在此基础上使用模糊聚类算法进行优化改进。
(3)结合SpringBoot框架,将改进的推荐算法合理地并行化,使之可以高效地运行在Web平台之上。
(4)使用图书的相关数据集对系统进行功能测试和性能指标测试,并且展示结果。
1.4 本文组织结构
本文具体细分为以下七个部分进行了研究设计:
第1章,绪论,对本文的章节安排和重要内容、图书馆推荐系统研究现阶段的具体情况、项目研发的意义和背景进行了简要的论述。
第2章,系统需求分析,首先对系统的可行性进行了研究,在可对系统进行研发的先决条件下,对系统应实现的性能和所有功能、所有环节的业务流程进行全面的研究。
第3章,推荐系统相关技术介绍,大体上论述了系统开发时具体运用的推荐技术等。
第4章,系统总体设计,在该部分中,开始对系统地设计相关的功能和模块,并且根据对系统的软件构成和网络拓扑的设定,对该系统中应存在的数据库和应实现的所有性能进行了深入全面的设计。
第5章,系统详细设计与实现,遵循预先设计运用编程技术完成运行界面以及功能详细设计工作。
第6章,系统测试,针对系统的运行和程序运用相匹配的测试工具进行检验,使系统投入运用前的最后一步工作得以完成。
第7章,总结与展望,归纳系统研究流程,并展望将来的发展情况。
第二章 系统需求分析
在对系统进行开发的过程中,最为关键的一项工作就是需求分析,与此同时,该项工作也是难度最高的工作。由于在需求调研工作开展过程中,存在着系统变更所产生的费用、用户需求实时变动、系统研发人员和用户沟通存在障碍等问题,因此只有基于对用户具体需求进行明确开发系统,系统的完善程度才有所保障。
2.1 系统可行性分析
在学校图书馆规模持续增大以及图书馆数量持续增多的形势下,对该部分相对较为庞大的体系进行管理是难度极高的一项工作。由于图书的状况是实时发生变动的,因此针对图书必须运用动态管控方式。而该件事情就管理者而言,相对较为繁杂,其中,每天必须完成借阅、查询、存储图书信息这一常规业务。在初步开发阶段,应开展大量的调研工作,以对用户具体存在的需求进行全面的了解,进而对开发的规模和目标进行明确,系统可行性研究工作的开展离不开前期的调研工作。而兴办单位的实力和规模决定着图书馆的大小和规模。
图书馆中有很多书籍和资料,书籍数量接近数千万,而读者在搜索所需的书籍时通常需要花费大量不必要的时间。尤其是随着现代科学技术的飞速进步,知识激增,图书资源的增长也越来越快。快速“爆炸”的资源通常超出了许多读者可识别的范围。因此,依据通常的搜索通过优化算法和搜索模块获得的大多数书籍详细信息都不是您想要或喜欢的。因此,为了更好地处理该特定要求以及获取特定信息时出错的问题,现在对搜索推荐系统进行了很多讨论。但是,这种推荐系统存在很多问题。例如,当读者基本上缺乏信息,数据和信息时,很难进行数据的定量分析和统计分析;由于许多推荐系统都采用协作过滤算法优化算法,因此它们必须依赖客户才能获得书籍的审阅信息,因此许多搜索推荐系统,尤其是公共图书馆的推荐系统都很难获得这种资源。由于读者仅搜索书籍,因此不涉及对书籍资源的评论。在很大程度上,存在特定情况。某些类型的书籍属于少数派,或者客户群相对太小,因此不能有效地推荐一些如今没人借用的新书。
2.1.1 经济可行性
因为学校图书馆的借阅者这项工作并不具备商业利益,因此为了使系统的研发成本得以缩减,应缩短系统的设计开发时间,使该项工作在短期内就可完成。在所设计和实现系统时,应对开发效率提升、开发成本缩减目标的达成高度重视,系统操作也应实现实用、简单、方便的目标。本文在对该系统开展成本/效益分析工作的过程中,主要运用的是任务分解技术,通过观察分析结果可发现,其可实现通过最小的投入获取到最大的回报的目标。由于就复杂程度而言,该图书管理信息系统处于一般程度,与此同时,其可参考大量的成功的高校图书管理信息系统的搭建案例,因此该系统开发过程相对较为便捷。因此其成本投入相对较小。在该系统投入使用之后,图书管理工作的开展将十分便捷。即可使工作更加高效,又可对不必要的开支和中间环节进行缩减。所以就经济角度进行考量,该系统的开发完全可行。
2.1.2 操作可行性
该系统的界面应最大限度的追寻易用、简洁的目标,基于标准化对界面的新颖度和美观度进行考量,可最大限度的友好的完成。而且该系统的操作极为简单,运用的人员大体上并不需求培训,仅依赖联机帮助和用户手册就可对该系统的操作进行全面的掌握。就图书管理者而言,其可在运用该软件的过程中真切的感受到该特征。总而言之,在该用户组织内,该系统的操作方式完全可行。
2.1.3 技术可行性
就技术可行性角度进行考量,该系统的编程语言和后台数据库分别运用的是Java语言、MySQL数据库。并且在开发阶段,对AJAX、XML、Photoshop等大量技术进行了全面的运用。基于我们的现状以及了解对比,最终开发环境选取了Eclipse,其可使系统的开发迅速完成,其数据库访问通道是内部集成的,可使数据库的管理更加便捷。该环境从实质上讲,是一个集成式开发环境,是将程序开发、查错、测试等功能集为一体的开发环境。其已发展成为现阶段系统开发过程中首要选取的技术工具。该种开发语言环境相对较为专业、面向对象的编程工具,在对大量成熟、具备着强大功能的应用程度进行开发时相对较为适用,尤其是在对数据库运用程序进行开发的过程中,其应是第一选择。除此以外,MySQL不但可在大中型数据库管理中运用,搭建分布式关系数据库,也可在桌面数据库开发过程中运用。对所有编程语言十分井筒的老师和计算机专业的学生构成了该系统的研发团队。其中极大多数人员都具备信息系统开发的经验。所以,通过观察人员团队知识架构可发现,该部分人员对开发该图书管理信息系统的能力已经全面掌握。除此以外,学校在该几年的系信息化环境改良的过程中,对于网络环境来讲,学校已经全面覆盖了学校网络。
所以,从互联网环境以及系统研发人员素质方面均进行考量,就技术而言,该系统的开发完全可行。
2.2 系统角色需求分析
在图书管理的现状和用户提出的要求的基础上可知,系统重点存在着管理员和读者两种类型的用户角色。
(1)管理员,主要职责是对系统后台和前台进行维护,系统管理员可完成系统内包含的每一项功能,例如图书管理、读者管理等,如图1所示,为具体的系统管理员用例图。
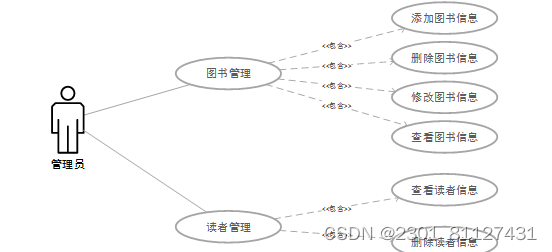
图1 管理员用例图
(2)读者。读者要到图书馆借阅图书,他们到图书馆来主要是借书、还书、预约图书、交罚金等。读者用例图如图2所示。
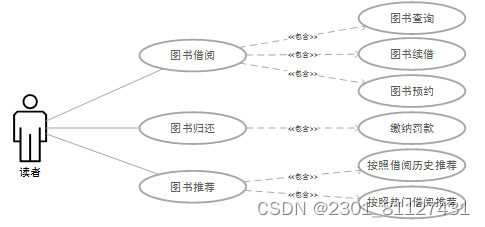
图2 读者用例图
2.3 系统功能需求分析
2.3.1 图书借阅需求分析
读者首先查阅相关图书,系统显示该图书信息,如果该书已经借出并未被预约,则读者可以申请预约,反之则可以申请借阅,如果读者有超期未还的书或者已经达到了最大可借用浏览的值,就不能在借了。业务的流程见图3。

图3 图书借阅业务流程图
2.3.2 图书归还需求分析
读者首先选择需要归还的图书,并提交归还申请。如果该书超期,则读者还需要缴纳相应的罚款。业务流程如图4所示。
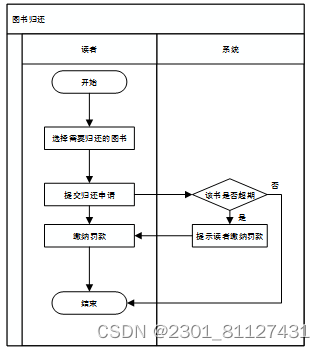
图4 图书归还业务流程图
2.3.3 图书推荐需求分析
读者登录系统后,系统会自动为读者推荐相关图书。如果该读者未曾借阅过,则会向读者推荐系统中的热门借阅图书,否则会根据读者喜欢借的书进行推荐。工作流程如图5所示。
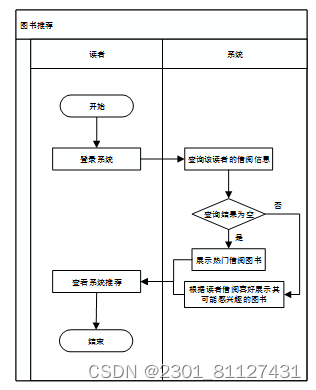
图5 图书推荐业务流程图
2.3.4 系统管理需求分析
系统管理,包括图书管理和读者管理。图书管理功能,是管理员用于管理图书信息的模块。它提供给管理员丰富的功能,包括添加图书的完整信息,修改图书的信息,删除无用的图书信息。对读者的管理也是管理员所必要的功能,管理员可以对某个不正规的读者进行管理,可以查看所有读者的信息,同时对某些不正规的读者信息,管理员有权对有关其所有的信息进行删除。以删除图书信息为例,其业务流程如图6所示。
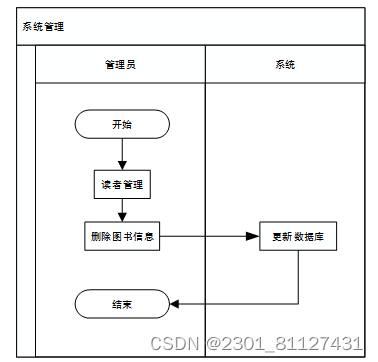
图6 系统管理业务流程图
2.4 系统非功能性需求分析
公共图书馆是系统管理方法的关键设计方案目标。系统内存具有较高的应用频率,因此性能方面存在着极高的要求,在系统设计和时间过程中,应对其安全性进行保障,避免损坏或丢失系统中所储存的借阅、读者、图书等信息,否则将会造成极为严重的后果。其所提出的要求具体如下:系统性能高,安全,功能全面。可操作性相对简单,易于学习,训练和掌握,界面相对较为没管;数据存储存在着较高的可靠度和安全性;易操作性和易维护性目标可最大化达成,将基础支持供应至系统,使系统可顺利运转。
(1)系统性能。由于高校人员总数较大,公共图书馆系统使用的用户数较大,因此该系统适用在访问用户量超过五百人的情况,在某个相对特殊的时间,大量用户也将浏览系统。因此,最高值时并发用户总数最少应为1000人。针对用户提出的普通请求,系统应在2秒内做出响应,将页面内容正常输出。可适当的延长大数据量报表加载、文件上传下载、报表的数据信息导入和其他操作的响应,但是响应速度应保持在用户愿意接受的级别。
(2)可靠性能。达到全天持续平稳运行的目标,系统可在运用大量服务器的基础上使大量用户访问的压力缩减。应在周末的某个时间段内或下半夜对系统进行常规的维护升级,防止对用户的正常使用产生影响。若出现了紧急维护的状态应提前在系统对话框中通知给内部用户。对于由非人为错误导致的网络服务器关闭、异常等状况,应将预先拟定完成的异常处理响应机制进行启动,以使出现的问题及时得到处理。应使系统应用数据库和程序的及时备份有所保证,以保障系统的恢复。
(3)可维护性。在系统运行阶段,系统的正常升级操作,以及异常问题的处理等已基本被涵盖,因此可以对系统的可维护性评估。而关于系统会出现的状况,可运用系统自拍错能力和日志跟踪方式将问题出现的地方探寻出出来,对问题出现的原因及时进行研究,拟定出相应的处理措施,对系统缺陷和异常位置迅速进行修复。对程序流程进行编写后,解决代码的每个关键功能,并进行代码注释,以提高代码的可读性。进而使后续的维护更加便捷。
(4)可用性。系统若想正常运行,首先就需使以下条件得到满足:用户可借助浏览器对系统进行访问和登录;优良的软硬件基础设施。其次,系统应向用户展示功能页。保持友好和合理。布局特征,易于操作和合适的设计风格。该系统具有完整的操作说明,使客户可以更轻松地掌握和操作该系统。
(5)安全性能。首先,操作系统的安全性需要考虑。虽然操作系统在安全等级方面比较有优势,但是由于其功能结构很复杂,仍存在一些安全方面的漏洞。为有效保证计算机的安全,我们必须定期为计算机添加防火墙和定期更新为新的操作系统。第二,数据库安全性。在安全性方面,对于每一个应用系统来说数据库都是最为核心的。我们必须做到以下几点才会给数据的安全提供保障。第一,要对数据库的权限进行高效的分配管理,不可随意赋予用户权限;第二,定期备份本系统的设备和备件信息的数据,系统的备件信息是极为重要的,所以必须拥有定期备份图书信息备件信息的功能。
第三章 关键技术与难点分析
3.1 推荐系统简介
相较于网络广告、搜索引擎,可主动的“投其所好”,将个性化的推荐服务供应至读者是推荐系统与其之间最大的不同,并且当用户行为记录出现变动时,系统推荐的内内容也会随之出现相应的变动,当推荐系统的水准相对较高时,其可协助用户将自身最需要的内容从大量的信息中精确迅速的探寻出来,在该种情况下,可使用户的体验得到大幅度的提高。当推荐系统相对较为完善时,其最少应包含数据采集模块、推荐算法模块、推荐列表展示模块、建模模块四个模块,如图7,为该四个模块间具体存在的关系。

图7 推荐系统模块之间的关系
将系统需求的数据从原数据中搜集出来是数据采集模块的重要职责,用户对项目的打分情况、项目信息、用户信息、其余操作行为等都是系统中所包含的内容。在以协同过滤算法为基础的推荐系统内,针对搜集到的数据,数据采集模块会将其处理为{用户-物品-评分}的二维关系矩阵;针对搜集到的用户评价数据,数据建模模块对其开展适当的建模通过,基于此将相关物品和用户的兴趣爱好联系起来;在推荐系统内,最为关键的就是推荐算法模块,在该模块内,应在用户-物品模型的基础上,按照运用情景存在差异的选择,运用最为匹配的推荐算法将推荐结果运用出来,还应对推荐内容的时效性和精确性进行保障;最终,向用户展现推荐结果。
3.2 相关推荐算法
在社会逐渐迈入互联网+时代的过程中,移动互联网得到的迅猛的发展,其规模日益增大,人们平日的生产生活在电子商务的飞速发展下出现了极大的变动,人们的购物模式已经逐渐从传统观念转变为互联网模式,年轻人日益增多的需求在电子商务个性化推荐功能的基础上得到了满足。完成个性化推荐功能的关键是基于推荐算法的技术性。在个性化推荐系统中,每个人都应该逐步全面应用协作过滤推荐算法。本节将详细介绍几种类型的符号协作过滤推荐算法以及已经出现的一些问题,并选择推荐算法以推荐给客户以开发全面的考量。通常情况下,图书馆内储存着大量的图书数据,而运用推荐技术将数据个性化推荐至用户正式大量的图书存储数据存在的需求。除此以外,和用户间建立一种平稳可持续的关系、将个性化信息服务供应至用户是个性化图书推荐最终想要实现的目标,基于此。可降低用户流失程度,使用户对其更加依赖。而在电子商务系统推荐领域内该点已经得到了普遍运用。
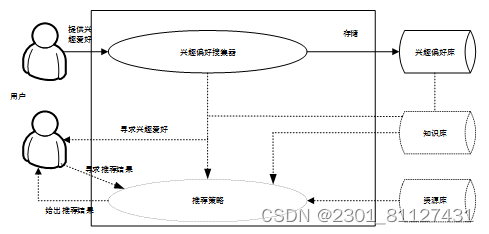
图8 推荐系统的推荐流程
3.2.1 基于用户推荐
该类型的推荐算法一开始就是根据用户作为基础开展研究工作,以用户为基础表明该算法的主体的用户,而从实质上讲,该类算法着重说明的是将部分喜好与你类似的其余用户的图书推荐至你。在个性化推荐技术中,该算法得到了极为广泛的运用。算法具体流程如下:第一步,搭建评分的矩阵R;第二步,对相似度进行运算;第三步,按照具体的相似度实时将推荐供应至用户。相似度的运算是以用户为基础的推荐算法中极为关键的内容,通过优化该算法以获得下一个的存在和高度相似性的“邻居用户”,并将“邻居用户”作为整体目标用户。且其并未拥有的图书或不包含的图书。如表1至表3,可将以用户为基础的推荐算法的推荐流程以及评分矩阵分别展示出来。
表1 用户-图书表

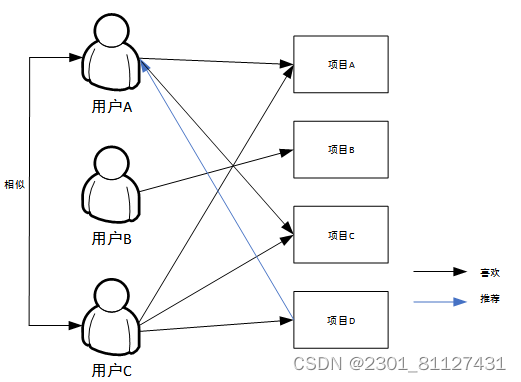
图9 用户-项目图
通过观察图9,可以发现A,B和C这三个用户都是有不同的“偏爱”和“非偏爱”的项目,在运用算法将存在差异的用户间的相似性探寻出来的基础上,获取到以下结论,用户A偏爱项目A、C,而用户C则较为偏爱项目A、C和D,即就兴趣爱好而言,用户A和用户C属于相似用户,也就是说,可将项目D推荐至用户A。与之相同,可将图书B4推荐至用户UA。该算法重要的运算步骤和流程如下:
(1)数据输入,构建用户-图书评分矩阵
搭建用户手册评级矩阵。图书是新的项目,可以在掌握用户对图书的评论后用户对图书的兴趣程度建立矩阵。当前基本施工系统软件中包含的用户和书籍数量分别为m个、n本,基于此,可运用m×n阶矩阵将用户-图书评分矩阵表现出来,其中用户对该本图书的评分通过矩阵中所有元素的值得以表示,当评分的具体数值较高时,就表明用户十分喜好该本图书,并且喜好程度随着数值的增高而增深,用P(i,j)代表评分值。
(2)生成最近邻居集
在协同过滤推荐算法中,形成最近邻居集极为关键。形成最近邻居集指的是在对算法进行运用的基础上,将与目标用户最为形式的N个用户探索,是将N个用户称为用户的邻居集的整个过程。协同过滤算法中具体的形成“最近邻居集”的过程如下图所示。K最近邻算法在对与样本个体相似程度最高的K个体进行运算的过程中,重点是在对样本个体间的距离或相似度进行运算的基础上进行,基于此形成邻居集。样本的个个数值决定着该算法的时间复杂度,应对其开展一次两两比较的过程。KNN算法重点是选取已精确划分的对象,在分类策略内,该方法仅在对最近的一个邻居或大量样本的类型进行掌握的基础上就可对存在着分类需求的样本的类型进行明确。周边数量存在着一定限制的样本是KNN算法实现的重要基础,而非依赖对类域进行识别的基础上来对其所属的类型进行明确,所以针对类域存在大量重叠或交叉现象的存在着分类需求的样本集,KNN算法相对较为匹配。
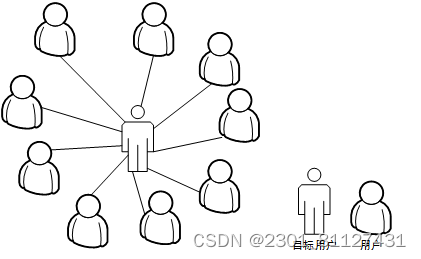
图10 形成邻居集的过程
3.2.2 基于项目推荐
计算相似性程度的时候,基于用户的协同过滤推荐算法是以用户为主题的,基于项目的协同过滤推荐算法与它的最大区别在于:是以工程项目主体的。此优化算法是Amazon(amazon)网站推荐系统软件底部的关键优化算法,并且也是较早的应用程序推荐算法。这两个推荐算法的过程极为相似。第一步是检索最近的邻居,第二步是建立新的项目用户评级矩阵,最后计算相似度。基本上,相似性可以是对新项目进行预测分析,评分和推荐(在本文中指书籍)。下表2给出了用户对项目的偏好情况,图11给出了参考协同过滤的推荐算法的推荐过程。
表2 项目-用户表

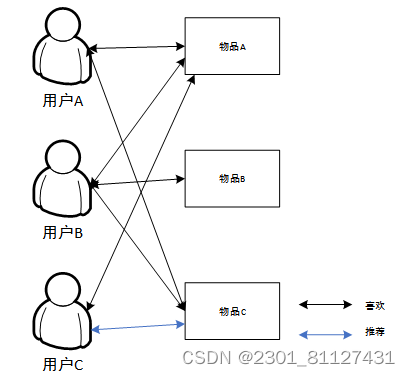
图11 项目-用户说明图
3.2.3 混合推荐
每个推荐系统都有其自身的优点和缺点。混合推荐系统结合了多种高度推荐的技术,因此可以提高高度推荐的效率和准确性。因为混合推荐系统是将各种推荐系统组合在一起进行科学研究,所以每个推荐系统都有其自身的优势。综合所有这些优点,就可以解决整个过程中遇到的许多问题。现实生活中的许多科研者,包括科研人员自己的工作都是使用混合推荐系统的算法向用户的提出有力的建议。最终的强推结果将递交给用户,即输出到客户端显示。基于项目的和基于内容的协同过滤推荐是其中较为常见的混合方式。推荐技术的组合有很多种的方法,如下图12所示。
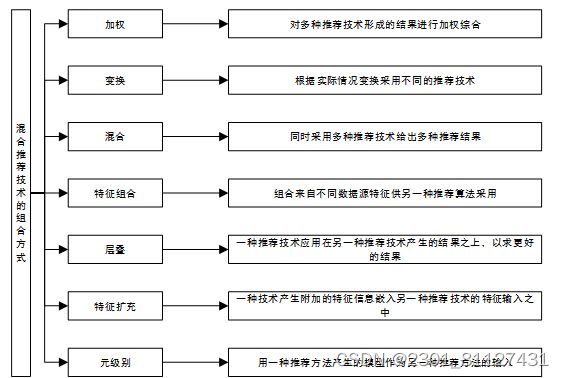
图12 混合推荐技术的组合方式
3.2.4 LFM算法
本文釆用的推荐算法是LFM算法,其中LFM算法主要是挖掘出大量信息中符合商品特征的潜在主题或者分类。LFM算法主要也是用作文本挖掘领域中的,同时它在推荐系统中也有举足轻重的作用,它能够基于用户的做法对于所有的item进行整合,整合出来的这些主题或者TOP-N就是可以作为用户所感兴趣的内容。
对于大量的数据来说,用户所感兴趣的内容少之又少,而针对不同的用户,所感兴趣的也各不相同,那我们在推荐的时候,所采用的推荐标准也就不同。我们在推荐的时候,应该是推荐用户所感兴趣的内容,例如书籍;我们就要推荐用户所感兴趣的类别下的书籍。那么前提就是要对所有的书籍进行分类,但是每个人对每本书的每种分类都有主观上的不同。因此,我们所注意的问题就有两个,一是我们需要知道用户对所有的类别的兴趣度;二是对于给定的类别来说,我们需要确定的是这个类别中的每本书所占的比例或者是权重有多大,这样可以方便我们之后推荐给用户。而LFM算法很好的解决了上面所说的问题。
对于给定的用户行为数据集(数据集中包括所有的用户,所有的item,以及用户对应的item所做评价的列表),假设我们使用3个用户,4个item,LFM所采用的分类数为4,则我们得到如图13的LFM模型。
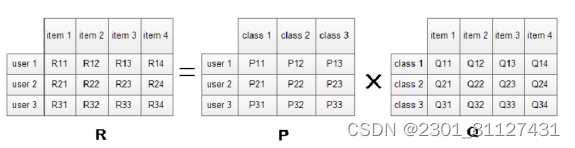
图13 LFM模型
其中R表示user-item矩阵,矩阵值Rij表现为user对item所做的评价,其中用具体数据来表示。只要得到某一个user对所有item的序列值,就可以进行推荐了。LFM算法要做的就是将R矩阵分解为P、Q矩阵来进行user关于item评价的预测,其中P矩阵代表user- class,矩阵,矩阵中的值表现为user对class的兴趣度,Q矩阵中的值作为item在class分类中的权重值。权重越高,表示更偏向于该类LFM计算用户user对物品item的兴趣度或者是评分。
(3.1)
之后的问题就是要解决如何得到P、Q矩阵的参数值,一般的方法就是采用最优化损失函数来求参数。下面我们确定一下数据集以及对评分的取值说明,再来定义损失函数。
数据集虽然是由所有的用户user,所有的物品item,以及user-item矩阵,但是其中主要是要包括所有的user对对应的item进行评分的项,这些项才是对我们有用的内容。对于每个用户,将用户(user)在该项目(item)上获得评分的项目作为正样本,并且兴趣值=1。且应该从所有样本中选择总数一致但未计分的负样本。另外,要求兴趣值=0,所以兴趣值的锁定范围是[0,1]。
我们通过收集正负样本来构造user-item的矩阵K,可以写为,这里规定:如果(U,I)是正的样本,那么就是1,反过来就为0。而损失函数的表达式如下:
(3.2)
上式中的是用于避免过度拟合的正则化项,其中λ是基于重复多次完成而获得的。损失函数的优化我们使用随机梯度下降算法,过程为:
(1)分别对和,求偏导来得到随机梯度下降的最快方向:
(3.3)
(3.4)
(2)通过迭代计算来不断优化下列函数中的参数,直到参数收敛。
(3.5)
(2.6)
我们可以看出α也是需要不断根据实际情况实验得到的,α表示的含义是学习速率,α越大,迭代下降的越快。因此,我们需要确定的参数的个数为三个,分别是分类数F、α以及λ。
对前过程分析后,就可以总结出LFM算法的特色:
(1)我们不需要关注数据集中的分类的方向,结果都是基于用户行为的数据集内容所自动聚类的,什么样的数据则有什么样的分类。
(2)同时我们不用关注分类的粒度问题,我们可以通过设置函数中的F来控制分类的粒度,分类数越大,粒度越细。
(3)对于一个item来说,我们不需要真正的将它归到符合它的类中,而是得到其归到该类的概率,是一种软分类。
(4)对于用户user来说,我们只需要知道他对于相应的物品item的兴趣值(评分),不需要关心所对应的分类。
3.3 系统关键问题及解决方案
3.3.1 冷启动问题
在一般的协同过滤算法系统软件中,冷启动问题主要分为以下两种类型:第一种是新用户的出现,并且根据用户评级数据检索最近的相似性。如果用户从未对它进行过评分,就不会强烈推荐它。第二种情况是最新项目的出现。由于最新的商品从未被用户评价过,因此强烈不建议使用。冷启动问题在很大的程度上阻碍了推荐算法的高效率。为了更好地解决冷启动问题,本文使用聚类算法和其他数据挖掘方法根据属性相似性聚类算法对用户或事物进行聚类,并从聚类算法的结果中找到新事物的最近邻居。或使用新事物K的所有最近邻居的综合得分来表示原始得分的平均值。
3.3.2 数据稀疏性问题
推荐算法在应用和发展趋势的全过程中都遇到很多问题。其中,稀疏性的关键问题和概念漂移的问题是两个具有很大影响性的难题,很大程度建议干扰系统进行的推荐治疗。稀疏性问题对于推荐系统的影响更加复杂和持久,多数影响都是长期性的,是推荐系统的最为关键的问题。针对推荐算法的研究工作有很大一部分是围绕数据稀疏性问题来进行的。本环节针对数据稀疏性问题的具体成因、影响方式和条件等进行了分析,提出了一些解决的方案和措施,并在此基础上进行讨论和总结。本节还针对稀疏性问题的影响,提出了一种协作推荐算法 WSBCF,这是一种给予加权相似度的推荐算法,能够缓解稀疏性问题对于推荐系统中相似度计算的影响,帮助在相似度计算中引入评分重复性数据,提升和优化传统项目中相似度计算,提升协作推荐算法中计算结果的准确性。前边的推荐系统中,关于内容过滤和协同过滤算法的研究是相对较丰富的。这种协同过滤算法的优化算法主要依靠用户的评论数据来衡量相似度而后实施推荐。如果事件的得分数据丢失或很小,或者事件的数量与不必要的用户评论数据相差甚远,这样的情况下,它不会转化为更好的推荐。尤其是有一个特殊的状况:相似的爱好者如果没有一起评论过某个产品,则以前的协同过滤算就无法准确地推荐它。
归根结底,推荐算法的关键是用户申请注册的规模,用户的等级信息和系统软件中存储的信息规模很大,产生了高维空间矩阵。这给计算增加了很大的难度。而且,推荐算法中的所有用户信息都存储在用于计分的矩阵中。评分数据基本上反映了用户自己的喜好,而用户数据是协作推荐是系统准确有力推荐的最关键基础。
与其他类型的影响问题相比,稀缺问题的成因和主要表现形式也显示出一定的共性,但也存在明显的差异。例如,冷启动问题是短时间周期的,也可以认为是稀疏性问题。可是在正常情况下,冷启动问题不容易破坏系统的推荐效果。、
系统中信息项目的总量巨大,而用户的评分访问信息项目相对数量就很少,这就导致了项目评分矩阵是稀疏性的高维矩阵。在推荐系统的部署和工作的整个时期都会收到稀疏性问题的困扰。所以,用户项目评分矩阵中缺少评分信息以及高维矩阵的特性都是造成稀缺性问题的因素。稀缺问题涉及所有方面,这就是为什么不能避免矩阵的高维空间流失的原因,特别是在当今外部环境是信息资源快速增长,信息量业务规模不断扩大的状态,用户总数继续增加,但是推荐算法无法操纵,信息量和用户数量的爆炸性增长导致用户事件审查引流矩阵呈现出增加的趋势离散系统。评分数据是反映用户信息需求的关键方法,也是推荐算法中用户兴趣爱好的基本基础。用户信息和偏好的缺乏也是导致评分稀疏的矩阵不佳的关键因素。在某些当前的系统软件中,更著名的移动电子商务网站(例如亚马逊在线书店,淘宝网站等)包含大量评论数据,并且在所有这些中,相对活跃的用户都在执行评论数据相对的总体审查数据仅占总产出的很小一部分。当收视率排行矩阵稀缺时,仅依靠用户收视率信息很难找到相似的用户集。因此,处理数据稀缺问题非常重要。许多人建议尝试一些不同的方法。常用的方法是使用预测分析的分数来填充缺失的分数数据,或者使用初始值(通常是平均值)来填充分数排放矩阵中的缺失标准值。 Badrul S强调此方法旨在改进。系统软件的高度推荐的准确性级别具有一定的优势,但可能会有很大的局限性。
但是,如果用户和事件信息包含在协同过滤算法系统软件中,则参考基于内容的强烈推荐,很可能可以很好地解决数据不足的问题。基于内容的强力推荐不依赖于用户对问题的评论,而仅基于用户自身的属性以及事物与其他信息之间的联系来衡量相似度,从而将其转化为强力推荐。但是,这种基于内容强烈推荐的方法也可能导致一些不良后果。例如,生成过多的正式强推荐很方便。在推荐书籍时,他们可能只会向读者强烈推荐一本独特类型的书籍。推荐算法具有很大的局限性。
3.3.3 数据缺失问题
数据记录中缺少数据很可能在多种情况下发生,基本上可以将其分为硬件配置原因和人为错误。机械设备是由于由于系统软件和硬件配置的元素导致的信息收集或存储错误而导致的数据不足,例如信息存储错误,运行中的内存或计算机硬盘损坏,以及导致无法在一定时间内收集信息成功。人为因素是由于人们特定情况的限制,由于数据丢失而造成的主观错误或故意隐瞒数据。在系统软件中,缺少数据的关键来自于学生的阅读记录和书籍录入记录。
对于数据缺失的解决手段,一般做法分为删除有缺失值的记录和用null值来对其进行补充。主观数据一般对实际数据进行补充来保障其可信赖度,而不通过插补的方法,这是因为人类本身将破坏数据的真实性,并且无法确保缺失值模式的其他属性的真实值。因此,在这种情况下,属性值的刀具半径补偿方法也是不可靠的。基本上,有清除数据和使用属性采用不同权重值的方法。清除具有缺失值的记录并立即消除数据是实现缺失值数据管理方法的最基本的优化算法。仅基于少量数据的消除,更容易确保数据结构的合理性。但是,存在这样的问题。当没有完全缺乏缺乏价值的数据结构时,必须通过确切的信息来发展它。解决值权重值的减少与源信息的差异。记录不完整的信息记录后,彻底的信息记录的权重值将有所不同,并且可以根据相应的回归算法获得日志记录的分支值。假设数据属性中存在对权重值的估计至关重要的转换元素,则此优化算法可以显着减少与原始数据的差异。假设表达元素与权重值之间的相关性较小,则不能通过该差值来减小它。如果有关数据记录的多个矩阵的特征值缺失存在问题,则必须为不同矩阵的特征值的缺失分量分配不同的权重。这样,将减少很大程度地改进优化算法的难度。此时的测量精度,使用权重值和原始数据的拟合程度的方法与具体方法不尽相同。
近似值不是缺失值的关键思想是计算最接近的适当值以填充缺失值。优势取决于基本消除不完整模式的方法所丢失的信息量。在特定的应用程序中,大多数数据设计计划报告都很复杂。每个报告的矩阵都有几个特征值设计计划。这种数据删除是对信息资源的消耗。假设某个矩阵的特征值减少了其他大多数矩阵的特征值,因此具有开发近似缺失值的替代方法和思想。有几种常见的方法:
(1)平均刀具半径补偿。信息的类型是需要空间的类型,而不一定是锁定类型。假设丢失的数据需要间隔的类型,则将特征的现有值的平均值替换为丢失的矩阵的特征值;假设丢失的数据不一定需要间隔类型,则只需遵循基本理论的大部分内容,便使用此功能出现频率最高的值作为丢失的数据。
(2)使用具有相似特征的等效值代替。值替代播放器中包含了平均替代播放器的优化算法,但是两者之间的区别在于,它使用类型聚类算法数据结构来计算缺少特征的数据实体模型,然后使用该值的平均值。数据属性填满。假设X(X1,X2,…,Xp)都是数据的所有要素属性,而Y是当前缺失值的过渡值。因此,第一步是聚合X或其非空子集,然后根据缺少数据记录对其进行分类。填写不同类型数据的平均值。假设在将来的数据计算中必须引入表达式变换值和Y来解决,则将这种替代优化算法与关系数据一起引入数据结构中,这可能会给数据计算带来一定的困难。
(3)最大似然(ML)。如果实际数据中的数据类型任意丢失,那么此时我们可以假设优化算法对于完整的模式本身是准确的,因此在观察所有模式的边缘分布之后,将其应用于不明确的数据将是巨大的。可能的(小和鲁宾)。该优化算法比清晰的案例和单值填充更准确,并且具有更广泛的应用范围。它的主要前提是要容纳大量数据。必须确保合理样本的数据足够,以便ML测量值可以被视为逐渐无误差,并在可接受的范围内服从标准正态分布。这种类型的优化算法的主要缺陷在于,它有可能导致某些最大值,从而导致云计算服务器的大量损失。
(4)多重刀具半径补偿(多重插补,MI)。多值刀具半径补偿的理论来源是贝叶斯估计。该核心概念的分配基于已观察到很长时间的数据,并且替代团队成员的标准值是可变的。通常情况下,根据替代球员的估计值,根据不同的数据构造各种可选的补给,并在此基础上找到更合适的替代的价值。
第四章 系统总体设计
4.1 系统设计目标
以集中统一规划为基础的全新的数据库数据管理模式就是图书推荐系统。管理借阅人员或数据从实质上将就是管理借阅信息、借阅者信息、书籍信息。图书推荐系统是极具代表性的信息管理系统,搭建后台数据库并对其进行维护、开发前端应用程序是其开发过程中重点包含的两个方面。就第一个而言,其应构建出数据具备较高安全性、较强完善性和一致性的库。而就后者而言,其应重点通过以下几方面设计该系统:系统功能设计和实现、数据库结构设计、业务流程分析等。在该部分工作开展的过程中,应全面的掌握数据库知识,并需对有关于管理系统的知识以及开发工具的运用进一步掌握。
根据我已学习和培训的相关专业知识的具体情况,系统软件打算使用B / S结构,即浏览器/服务器(Browser/ Server)结构。本质上,它是仅安装一个网络服务器(Server)及其维护,使用计算机浏览器(Browse)将移动电话软件作为移动客户端来操作。 B / S结构从实质上就是在Internet技术飞速发展的形势下,通过变动和优化C/S结构所获取的一种结构。重点对持续完善的WWW浏览器技术进行运用,在ActiveX技术手段和许多脚本语言表达了技术应用程序的基础,例如VBScript,JavaScript等,从而产生了一种新型的系统软件结构技术。
开发难度相对较低且拥有较强共享性、强分布性、总体拥有成本低、维护简便等都是B/S架构所具备的重要特征。但其也存在着数据传输速度相对较为缓慢、数据安全性问题、软件个性化特征显著降低、对服务器要求过高等不足之处,对于传统模式下特征的功能要求实现的难度相对较高。例如难以借助浏览器进行专用性打印输出、应答报表、输入大量数据。B/S体系结构之中,使用者可以通过浏览器发送请求,目标即是在网络中遍布的数目众多的服务器,接受了请求后,服务器的处理中心工作,并向浏览器反馈用户需求的信息。而数据库的访问、数据请求及加工及结果返回、应用程序的执行、动态网页的生成等其余工作则完全通过Web server完成。而Windows在操作系统内部逐渐植入浏览器技术的形势下,该种结构已然变为现今阶段的应用软件中,首个可以选取的体系构造。显而易见,与传统的C/S架构的应用程序相比,B/S架构的程序是一种极大的进步。
完成图书阅读智能管理系统开发设计总体目标的关键有以下多个层次
(1)页面设计友好美观。
(2)数据存储安全可靠。
(3)信息分类清晰准确。
(4)强大的查看功能,保证了数据查看的协调能力。
(5)完成全过程数据信息跟踪,实现全书阅读和还款的全过程。
(6)提供图书借阅排行榜,为图书管理员提供了真实的数据信息。
(7)提供灵活、方便的权限设置功能,使整个系统的管理分工明确。
(8)具有易维护性和易操作性。
4.2 系统总体架构设计
将数据访问、业务逻辑、界面显示分离开来是本系统运用RESTful架构重点存在的优势,在开发的各个环节中对一些功能高度关注,使开发效率提升,除此以外,通过科学的划分子功能模块,可使模块间的耦合性得以下降,并使代码的重用性提升。例如在对系统进行开发的过程中,若将系统开发为手机版和网页版时,两者只有在视图部分存在差异,在模型和控制器部分的代码存在着极高的重用性,可使开发周期和成本得以缩减等。本文设计的图书推荐系统整体的架构图见图14。
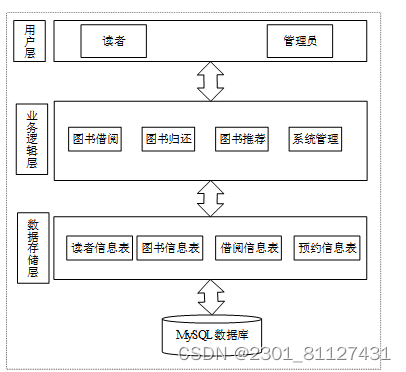
图14 系统总体架构图
以Web应用为对象,设计了RESTful架构风格,使系统可伸缩性提升、开发繁杂性下降是其主要的目标。HTTP/1.1协议等Web规范的设计指导原则就是REST。每一个Web应用都应遵循REST架构设计指导原则。当然不运用REST也可实现相关应用,但却违背了REST的指导准则,其需付出大量的代价,尤其是就流量相对较大的网站来讲,系统架构相对较为优良时,其URI的设计必定极为优良。将需求抽象为资源是开发设计人员具体的工作职责,并且资源抽象的精确度越高,最终设计的系统就越为良好。如下,为RESTful的资源接口设计原则:
(1)所有资源都存在着一个独一无二的资源标识URI,并会向外暴露资源。
(2)借助URI,可使得所有资源格式在服务器端和客户端进行传递,使各种存在差异的客户端可获取到同样的数据,使服务器组件得以简化,使系统的可伸缩性得以提升。比如,经常运用的JPG、JSON、HTML、PNG、XML等。其详细的展现形式为,运用Accept和 Content-Type字段在HTTP的Header中进行指定,比如将单人的信息看作一个资源,可将其通过图片展现出来,也可通过JSON格式将信息描述出来。
(3)针对服务器端的资料,客户端借助PUT、PST、DELETE、GET四个基础方法进行操作。REST借助HTTP协议内所包含的部分Request Method,向应用程序的更新、创建、删除、读取中进,行映射。在具体实践过程中,程序员仍偏向于运用PUT、PST、DELETE、GET,在公开REST API中出现的次数相对极少。采取该种措施的主要原因是拥有着更为良好的兼容性、开发便利。
(4)每一项操作都是无状态的。所有的客户端请求服务端都需拥有着充足的信息,使服务器服务端可对该请求进行全面的了解,并不需要将上下文信息储存至服务端中。这可使中间服务器不需保持任一状态对请求进行处理,进而使服务器负载平衡、路由、转发更加方便。
4.3 系统总体功能结构设计
对系统实施说明的一个流程就是功能模块划分,应抽象需求分析中所包含的感性描述,将其存在实现需求的功能提取出来,这是系统开发过程中十分重要的一个过程。读者和管理员是该图书馆借阅管理系统内重点包含的两类运用用户,管理员可管控图书借阅、读者、图书等信息,并可对罚金进行收取、催还逾期;而读者可维护自身的基础信息,除此以外,系统仅将查询个人借阅信息、图书信息等信息的操作权限供应至读者。如图15为本图书推荐系统具体的功能架构图。
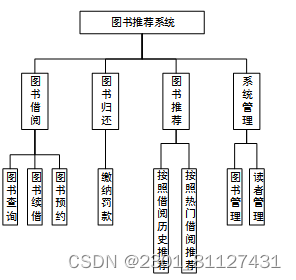
图15 系统总体功能结构
4.4 系统网络架构设计
将架构和技术基础供应至一个通信网络的设计、搭建、管理过程中的蓝图就是网络架构。其对数据网络通信系统的所有方面都进行了定义,其中包含了可能使用的网络布局架线的类型、使用网络层协议,用户应用程序接口模式等。网络结构具有符号层次结构。从层次的实质上讲,它是一种智能的Internet结构设计。它将日常的通信任务划分为许多相对较小的部分,且在完成特殊任务后,所有部分都将选择一种定义明确的方法,并选择融合起来。使网络安全防护的全面、多层次、及时有效合理有所保障是网络安全管理的主要目标。
该系统为B/S架构。在该模式下,通过用户计算机中本身包含的Web浏览器可使用户的操作和访问界面得以完全的实现,在JavaScript等脚本语言的基础上,就可通过浏览器对部分相对较为繁杂的事务逻辑进行处理和实现,但在处理重要事务逻辑的过程中,主要依赖的还是服务器段,在服务器前端仅存集中了少量事务逻辑的处理工作。如图16所示为详细的网络架构。
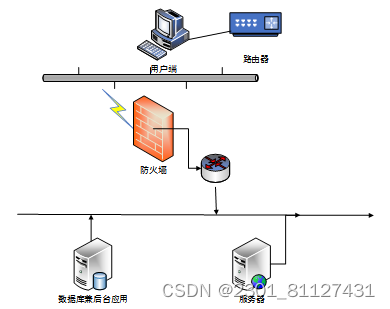
图16 系统网络拓扑结构图
4.5 系统数据库设计
数据库设计在一个新建系统的开发过程中占据着不可忽视的地位,它奠定了该设计的流程导向,数据库设计完整、准确才能更好的作为系统的后台支撑,且为系统实现服务。数据库设计是在功能需求与业务流程设计相结合的基础上开展的。
4.5.1 MySQL数据库
一个优秀的数据库将会决定图书馆借阅管理系统的成败与否,因此该图书馆推荐系统的数据库就选择了当下比较流行的MySQL。MySQL是 MySQL AB公司开发的,Sun公司于2008年1月中旬被顺势收购。随后Oracle公司又于2009年收购了SUN公司。当时没有任何人看好MySQL的前途,也不抱有丝毫乐观的态度作为一个小型关系数据库管理系统的MySQL的应用性范围非常宽泛,大部分都被应用在不同的但是规模较小的Internet网站系统中。其原因为MySQL数据库在体积方面和运行速度方面上都比较有优势,例如体积小、系统运行快,此外还具备成本低和数据库的源码比较开放等客观的优势,这也是大部分的中小型企业网站优先选择了MySQL作为企业网站开发后台的数据库的主要原因MySQL在处理多用户且多线程的结构化方面有很大的优势,此外在查询语言数据服务器方面也有很大的优势,下面我们再介绍他的其他优势
(1)更快的速度。
(2)在数据浏览级别,MySQL是可传递的。
(3)可移植,MySQL可以在各种版本的系统软件上运行。
(4)在编程语言应用程序级别上,MySQL具有很大的实用性。
(5)便于实际操作,MySQL在特征性能上具有出色的能力,并且具有相对简单的数据库结构
(6)免费使用,MySQL对于大部分的个人用户来说是免费的。
4.5.2 实体E-R图设计
数据是系统软件实施信息管理方法的关键组成部分。所有业务流程数据必须安全存储。另外,必须确保数据浏览的准确性。书籍的关键信息包括条形码,名称,类型,书柜,出版商,出版商和创作者,价格等。图书的属性图如图17所示。

图17 图书属性图
读者的主要属性包括读者证件号码、读者姓名等信息。读者的属性图如图18所示。
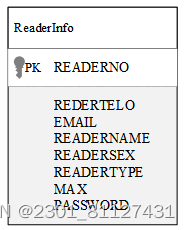
图18 读者属性图
图书借阅主要信息包括图书名称、归还时间、读者证件号码、读者姓名、是否归还等属性。图书借阅的属性图如图19所示。
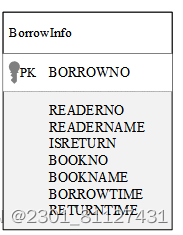
图19 借阅属性图
处罚的主要信息包括读者编码、读者名称、处罚原因、借书天数、处罚金额。处罚的属性图如图20所示。
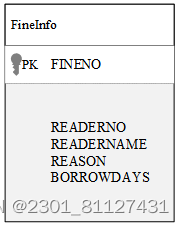
图20 处罚属性图
管理员的属性图如图21所示,管理员主要信息包括用户名、密码以及各种权限。

图21 管理员属性图
4.5.3 数据库表结构设计
E-R图设计完成后则需要进一步的进行数据库列表的规划,在这里说明一下,数据库表的功能是储存表单的数据和相关信息,在数据库使用时进行数据调用。本系统中总计包括五个数据表,具体如下表3到表7所示。
表3 图书信息表
字段名 类型 长度 主、外键 是否取空 字段说明
BOOKNO VARCHAR 20 主键 否 条形码
BOOKNAME VARCHAR 20 否 是 名称
BOOKTYPE VARCHAR 5 否 是 类型
BOOKSHELF VARCHAR 10 否 是 书架
AUTHOR VARCHAR 25 否 是 作者
PUBLISH VARCHAR 20 否 是 出版社
PRICE FLOAT 3 否 是 价格
SCORE FLOAT 3 否 是 豆瓣评分
表4 读者信息表
字段名 类型 长度 主、外键 是否取空 字段说明
READERNO VARCHAR 18 主键 否 证件号码
REDERTEL VARCHAR 20 否 是 联系方式
EMAIL VARCHAR 8 否 是 电子邮件
READERNAME VARCHAR 50 否 是 姓名
READERSEX VARCHAR 20 否 是 性别
READERTYPE VARCHAR 8 否 是 读者类型
MAX INT 8 否 是 最大借阅量
PASSWORD VARCHAR 20 否 是 登录密码
表5 借阅信息表
表6 处罚信息表
字段名 类型 长度 主、外键 是否取空 字段说明
READERNO VARCHAR 3 外键 否 读者证件号码
READERNAME VARCHAR 30 外键 否 读者姓名
REASON TEXT 255 否 是 处罚原因
BORROWDAYS INT 4 否 是 借书天数
表7 管理员信息表
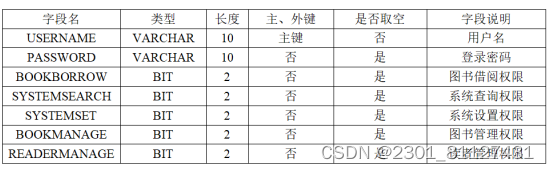
4.6 系统数据备份及恢复设计
保证系统备份产生的数据信息能够安全有效的存储对于本图书馆借阅管理系统来说是极为重要的一道防线。下面针对于数据备份系统由的组成结构和控制软件以及必备的系统功能三方面来仔细介绍该图书馆借阅系统的数据备份和数据恢复的设计原则。
(1)备份方式
本图书推荐系统的所采用的备份方式是当前最为主流的LAN-Free技术,它是基于SAN的一种可与多台存储设备直接相连的良好的备份技术。对于实现数据的自动存储备份则需要预先设定备份规则,定制相应的备份策略。备份存储的数据会利用光纤网络然后发送到与光纤交换机选接的磁带库。这种方式很大程度上提高了备份速度,因为它不占IM络带宽,备份数据也是利用SAN进行分离式存储,转移到异端设备上。
下面对系统备份所采用得LAN-Free模式具备的特性进行具体描述:第可提高系统容量;第二,系统的主体性能增长了400 Megabytes/sec;第三,采用可达15公里传输距离的单膜的光纤传输技术;第四,因为其较为优化的结构模式,应用网络得到完全的解放,同时也减轻网络使用负担;第五,极大程度上提高备份的性能和数据保管的安全性。
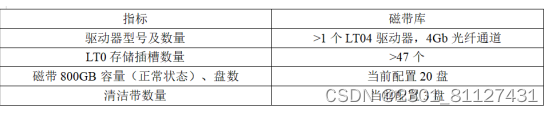
(2)磁带库选型
数据备份系统采用磁带库,系统的推荐指标特性配置,如表8所示。
表8 磁带库指标的特性
(3)备份软件
图书推荐系统的数据备份需要采用优秀的技术软件来实现,该数据备份软件需要具有如下特性。
支持种类众多的设备使用,还可用于多种操作系统和平台进行应用。
1)可用于常见的设施,计算机操作系统和应用平台。
2)可以与多种磁带技术结合使用。
3)适用于多种流行的数据库管理的备份数据,包括Informix和SOL Server等。
4)可以同时适配多种的模式,已有备份信息下,还可以加入新的备份,且能够做到隔离备份。
5)每项操作都有可备份的脚本有关信息。
6)能够支持SAN和NAS,还有其混合的网络应用,并且可以做到灾难的恢复支持。
4.7 系统的接口设计
PowerBuilder9.0对于数据库查询前端工程师而言,这是一个出色的工具。它给出了数据库的各种可靠接口,使得用户的应用程序能够访问各种不同的反异构数据库管理系统PowerBuilder9.0。它可以根据本地数据库,特殊数据库,ODBC等与它可以通过本地的数据库套接字和特定数据库专用的查询套接字,以及ODBC等与数据库进行查询访问的连接,这些连接都是在事务对象管理中完成的。
通常,PowerBuilder9.0有专用的数据库查询套接字或标准的数据库查询套接字用于创建与数据库查询的连接。这次的“ 图书推荐系统软件”选择了标准的数据库查询套接字(ODBC方法)来创建与数据库查询的连接。 ODBC方法应用数据库查询标准的SQL语句进行实际操作。因为ODBC方法属于标准化的数据库查询接口方法,所以客户不需要注意哪种类型的数据库智能管理系统到底是连接到了什么样的应用程序软件。
不管所有应用程序软件如何,如果它们使用ODBC方法创建与数据库查询的连接,则它们仅需要国家标准代码,而不必担心最底层代码的实际编写。开发和设计制造商进行底层级别的驱动程序开发。
ODBC主要运行于Windows平台上,它的标准化查询方法、标准化错误代码集、连接和注册到DBMS的标准方法以及标准数据类型,都给用户开发带来了巨大的方便。
本次图书推荐系统就是利用ODBC接口连接MySQL数据库管理系统。
第五章 系统详细设计与实现
5.1 系统开发工具及环境
5.1.1 开发工具
Eclipse专门用于开发Java,JEE的 Eclipse插件集合。Eclipse(Eclipse Enterprise Workbench,简称Eclipse)企业级工作平台是对Eclipse IDE的扩展,因为它可完整支持HTML、Struts,、CSS、JavaScript、SQL、Hibernate,所以我们可以利用它完成在数据库和JavaEE的开发、发布,可以对各种不同的应用程序服务器兼容,通过这些可以让开发人员更好的完成工作。它的JavaEE集成开发环境是非常丰富的,包括了完整完善的功能,例如编码功能、调试功能、测试的功能以及发布功能等。
5.1.2 开发环境
系统的实现采用的是基于SpringBoot框架模式进行开发web推荐引擎的。系统的开发前端框架使用的是Jquery+ EasyUI进行搭建的。后端的开发环境是采用的是经典的SpringBoot框架。整个系统的开发环境是:Eclipse10,Tomcat9.0,MySQL5.1.32,Hadoop1.2.1、Mahout0.6;系统开发的硬件条件是:Windows10平台、内存:6GB、硬盘:500GB。
5.2 系统设计原则
(1)首先应使系统功能的全面性有所保障,使运行阶段的可靠性有所保障,可对互联网中出现的所有问题进行应对,迅速做出对问题进行应对的措施和反应,应具备优良的健壮性。
(2)数据库在内存方面存在着较大的需求。因为图书馆本身就需对大量的数据进行存储,因此就图书馆管理系统而言,数据库的存储空间应保持足够大。
(3)响应时间短。在系统内会将用户、借阅归还、图书等大量的数据和信息进行存储,必须可保障在极短时间内将存在一定用处的信息供应至用户,使用户的良好体验有所保障。
(4)合理索引。为了使用户在对自身需求的书籍进行检索时更加高效迅速,应科学的设计系统的查阅书目的借阅归还时间功能,保障查阅条件的多样化,使用户可全面的查询到精确度最高的消息。
(5)安全性需求。首先应实现只有获取到权限的人员才可通过登录界面进入该系统内,对图书馆中所有的信息进行案例,并且应保障获得权限的人员的查看和管理范围仅可始终维持在自身获取的权限范围内,基于此,使信息的安全性有所保障。其次,有关于借阅归还时间信息、图书信息、用户信息等都应做到高保密性,在系统录入阶段,使信息的安全性有所保障,所有关键的信息都不可进行修改甚至删除。为了使上述标准得到满足,应管控存在差异的人员的权限,对其进行安控。信息安全存在着极高的重要性,应在管理工作开展前,良好的划分信息管理和人的管理的类型,并对其权限进行设置,以将高效便捷的数据供应至后续的查看和统计等操作中。
(6)具有良好的人机交互。就系统获取的认可度而言,使用人员的感受是最为关键的,在设计系统的过程中,应着重说明该操作使用者是否习惯,或使用人员平日工作的流程通过该流程整体是否可得到满足,应使使用人员通过运用系统获取到一定的便利性,而非自身应对一套新的工作流程重新学习,因此在调查人们具体存在的需求的过程中,应对学生、使用人员、外校人员、图书馆员工等最大限度的进行全面的询问,例如其新书籍存储的具体流程,学生借阅书籍的过程中第一步工作是到达暑假直接选取还是先对书籍条形码进行查询等。基于此,在设计环节中,为了可更加便捷的使用户拥有优良的使用体验,应搭建一个优良的人机交互界面,一方面可是系统整体的管控更加便捷,另一方面也可使网络的魅力被用户真切的感受到。
5.3 系统功能模块详细设计与实现
5.3.1 图书借阅详细设计与实现
(1)模块描述
此模块是进行图书借阅的模块,读者通过在该模块进行图书查询,并且对已经借阅的图书进行续借,对已借出的图书进行预约。
(2)功能结构设计
图书借阅主要负责对系统的借阅记录及信息进行操作,包括读者登记,录入还书信息,未借出图书,已借出图书,租借统计。其功能结构如图22所示。
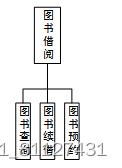
图22 图书借阅功能结构图
其实现关系如图23所示。
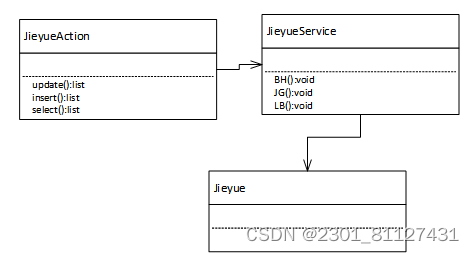
图23 图书借阅类图
(3)流程设计
下面以借阅图书查询,通过时序图来描述一下系统中对借阅管理中填写登记图书借阅信息功能的动作流程,如图24所示。在jieyue.jsp页面,用户输入查询条件进行验证,将查询条件传送至控制器,根据查询方法调用业务类,然后根据查询条件查阅借阅表,将查询到的结果封装到借阅集合中,一步步展示到前端页面上。
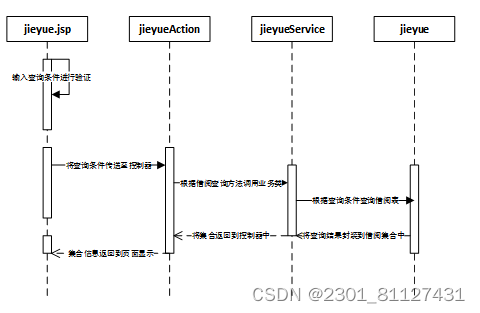
图24 查询借阅情况时序图
用户在借阅管理查询页面中,输入查询借阅信息后页面进行信息的验证,当信息格式合法时页面中的查询条件将被控制器中的查询方法调用到业务类中,根据控制器中的参数查询数据库中相应的信息,将查询到的结果存入到集合中,在控制器中将数据绑定到request中,最终将数据返回到查询显示页面。
图书借阅模块的流程图如图25所示。
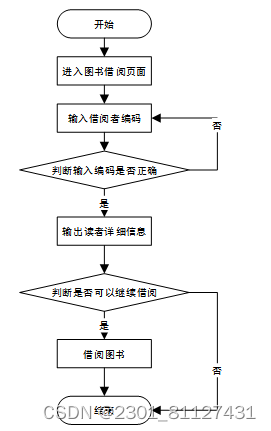
图25 图书借阅流程图
根据设计的流程图,进行图书借阅管理界面的详细设计。点击菜单栏中的“图书借阅”,进入图书借阅管理界面。在图书借阅时,可以根据读者条形码搜索已经存在的读者的各种信息。如果想借阅某本书,则输入图书条形码,单击“查找图书”,可以显示出该图书的相关信息、。然后在该图书中点击“借阅”,即完成了借阅操作。
5.3.2 图书归还详细设计与实现
(1)模块描述
图书归还功能是根据自己所已经借阅的图书进行归还,归还后自己的借阅单里将没有这条图书借阅记录,表示已经归还成功,在归还前如果有逾期则需要缴纳罚款。
(2)功能结构设计
图书归还的功能结构如图26所示。
图26 图书归还功能结构图
(3)流程设计
办理图书归还时,读者首先需要点击“借阅管理”进入相应的图书借阅列表,可以根据输入借阅人的信息来快速检索图书信息,并点击“详情”查看图书的具体借阅信息,看此书借阅是否超过规定期限,如未超过,则可点击“归还”按钮进行图书归还操作,反之若图书已超期则提示缴费后才能归还。
图书归还时序图如图27所示。页面展示已经借阅的图书列表,点击需要归还的图书,return.jsp页面将需要归还的图书传送至控制器,ReturnAction根据归还方法调用业务类ReturnService,并查询是否超过借阅期限,并返回结果,ReturnService将结果返回到控制器中,ReturnAction将归还结果返回到页面显示。
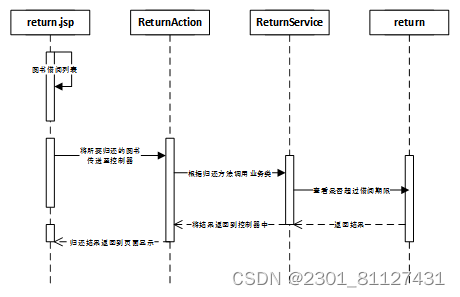
图27 图书归还时序图
5.3.3 图书推荐详细设计与实现
(1)数据预处理
将用户兴趣相对较高的图书信息向用户推荐,使用户在海量图书信息数据中探寻出自身存在着较高兴趣的图书更加便捷,就是本系统图书推荐算法的主要用途。在运用推荐算法之前,我们应对大量的用户-图书-评分数据进行收集,以对实验的开展提供支持。本文运用的数据均是通过亚马逊网站向开发者供应的开源数据集获取的,其中包含了用户图书评分数据 BX-Book-Ratings、图书数据BX-Books、用户数据BX- Users。在试验未开展时,应先预处理所获取的数据,重点通过一下几方面进行:
1)空值处理。在用户评分表内仅存在着图书评分、图书ISBN、用户ID三项数据。在实验过程中,该三个字段存在着十分关键的作用,因此这三项数据均必须存在,不可为空值。所以,应剔除掉三项数据中存在空值的项,以避免实验结果受到影响。
2)主属性处理。在图书信息数据表内,唯一识别的图书标号就是ISBN,将其作为主属性是极为匹配的,但在数据库内,ISBN的存储存在着某种限制,所以应对主键重新进行定义,将ISBN界定为副属性。但我们仍运用ISBN作为用户评分表中的一列,基于此才可对用户借阅的图书进行科学的判定。
(2)功能流程设计
上文对本系统最为关键的算法LFM算法进行了说明,本系统是在用户购买图书的基础上进行评分的。对该部分数据进行运用,将用户存在较大兴趣的图书发掘出来,向用户进行推荐。使网站的交易成功率得以提升。下文将对算法的运用进行全面的介绍。
对于上文论述的LFM算法就不再进行多余的论述了,用户评分数据表是我们需求的数据中最为关键的,通过观察该部分数据我们可发现,矩阵的行向量和列向量分别选取用户的ID和图书ISBN,对于某本图书某用户的评分则通过矩阵中的数值展示出来,算法描述中的R矩阵即为该矩阵。后续在对矩阵进行分解、求解R矩阵中的数值的过程中,将运用LFM算法开展相应工作。
算法详细表述如下:
输入:用户-图书-评分表R
输出:某一读者中所有item项中TOP5的图书信息
1)对P,Q矩阵进行初始化;
2)开始迭代;
3)将user读者以及user读者对图书感性的item集从数据集中取出;
4)随机抽样,以user用户为对象选择出数量一样的负样本,合并正负样本;
5)将item样本和user对该item的评分取出;
6)在上述公式的基础上,对初始参数进行填写;
7)实施算法,获取到算法误差,并对参数进行完善;
8)当误差不在发生变动时,获取到最佳的参数,并对R矩阵中的评分数进行运算;
9)排列某个读者的item集的次序,获取到评分最高的item项,将其作为TOP-5中的图书信息。
5.3.4 系统管理详细设计与实现
(1)功能模块描述
1)图书管理
其余管理操作的连接按钮还包含在图书管理页面内,而这是为了使管理员其余管理工作的开展更加便捷。管理员可将图书名称或编号等信息在搜索页面文本框进行输入,以对图书的信息进行模糊查询,对下方的搜索按钮进行点击,可将与图书有关的简要信息显示出来。与此同时,用户也可对精确搜索按钮进行点击,进入精确搜索的页面,将与图书有关额精确检索功能供应至使用者。
①图书检索功能:首先进入图书检索模块,在该模块中对单个或多个条件信息进行输入,之后点击检索按钮,若图书馆内存在着有关图书,则系统可将图书的信息显示出来;若检索项信息输入出现错误,则会显示图书不存在。
②新书上架功能:图书馆管理人员将图书的基础信息予以填入,其中条形码、图书编号、图书名称都是必填项,填写完成后点击上架按钮,当提示保存成功时则表明新书上架成功。
2)读者管理
管理注册用户的信息是读者信息管理模块最为主要的工作,当挂历人员对读者用户信息管理按钮进行点击后,就可进入到读者用户信息管理界面。在页面内,所有读者用户的基础信息是通过表格的方式体现的,对表格中每一行的“详情”按钮进行点击,就可对该读者用户注册的基础信息进行查阅,并且管理员在详情界面可修改用户基础信息。
①新增读者:当该模块中存在的“添加读者信息”按钮被管理员点击后,系统就会自行向对应的读者信息添加页面进行跳转,管理人员应遵循相应的标准将读者的联系方式、证件号码、姓名等具体的相关信息在该页面中进行输入,其中管理人员无法自行输入读者账号,系统会自行生成该编号,在所有信息输入完成后,点击“添加”按钮后,则表明读者用户新增操作成功完成。
②修改读者信息:当该模块中“修改”按钮被管理员点击后,管理员就可在修改页面中修改读者的条形码、身份证件、类型等信息,当修改操作成功完成后,则需将该部分信息重新在后台数据库中进行保存。
③删除读者信息:当该模块中“删除”按钮被管理员点击后,就可删除掉该用户的相关信息,也就是将数据库中该用户登记的信息的可用状态转变为冻结状态,当删除操作顺利完成后,该读者就无法对本系统进行访问。为了使管理员对图书馆的历史记录信息可更加便捷的进行管理,在删除用户信息后,后台数据库中仍将该读者的用户信息留存下来。
3)权限设置
但该模块中的“添加管理员”按钮被超级管理员点击后,超级管理员就对一个全新的管理员进行创建,重点是需输入管理员的账号密码等信息,在顺利完成添加操作后,超级管理员可将存在差异的操作权限赋予至所有新建的管理员账号中,超级管理员在将存在差异的权限赋予至管理员时,是在对存在差异的权限单选框内打对号方式的运用的基础上进行的。除此以外,拥有着权限设置的管理员也就是超级管理员才可修改或删除其余管理员的账号信息。
(2)功能结构设计
系统管理的功能结构如图28 所示。
图28 系统管理功能结构图
(3)流程设计
具有相关权限的管理员通过读者添加子模块来添加读者信息,也就是将新增读者信息上传至数据库的过程,时序图如图29所示。
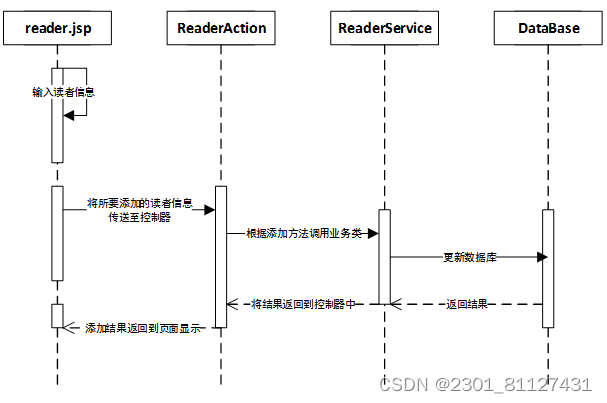
图29 读者添加时序图
在reader.jsp页面,由管理员输入读者信息,并将所要添加的读者信息传送至控制器,ReaderAction根据添加方法调用业务类ReaderService,并更新数据库,将结果一步步返回到页面显示。
第六章 系统测试
一个系统的完整开发,除需求分析阶段需要花费大量的时间之外,系统测试阶段也需要大量时间的去测试。一般情况下,在需求分析完成之后,系统的程序代码很快就能写出来,但是在这个过程中,难免会出现一些问题,这就要靠系统的测试阶段。
6.1 系统部署
系统采用现在主流的开发框架SpringBoot,但是它的基础也是JavaWeb项目,所以若是要运行系统,我们就需要服务器的支持。目前,JavaWeb项目服务器非常多,我们选取较为主流和简单的Tomcat作为本系统的服务器。
Tomcat是免费开源的轻量级应用服务器,在中小型项目或者用户访问量较少的小项目中非常受欢迎,也是学生开发JavaWeb项目首选的应用服务器。Tomcat的运行框架如图30所示。
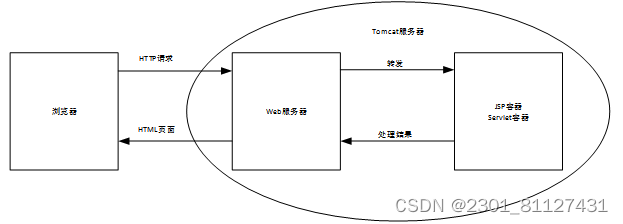
图30 Tomcat服务器结构
本系统采用的版本是Tomcat9.0,运行环境是 Windows10,要想部署服务器,我们需要先安装Tomcat,这一步不再详细介绍。重点是安装Tomcat之后,我们需要对相应的环境变量进行配置,包括开发环境JDK还有Tomcat的配置。JDK的环境变量为 JAVA HOME,JAVA HOME为JDK的安装根目录下。Tomcat的环境变量为CATALINA BASE和 CATALINA HOME,它们的设置内容都为Tomcat的安装根目录。这样我们就完成Tomcat的配置,接下来需要在开发平台下启动 Tomcat服务器,并在浏览器中输入http://localhost:8080来验证服务器是否正常启动。
为了使得Tomcat启动方便,Eclipse10中提供了Tomcat的配置环境,我们可以通过 Eclipse平台上菜单栏Window中的 Preferences中找到Tomcat选项,之后我们可以通过 Eclipse中Servers中查看到服务器的状态,并且可以直接进行开启。我们将所编写的项目部署在Tomcat服务器中,当服务器开启时,我们就可以通过在浏览器中输入项目地址,就可以启动项目了。
6.2 系统测试方案
软件设计的工会量相对较大,周期相对较长,因此不可避免的产生大量多种多样的问题,因此就需对系统进行测试,检验系统中存在的问题。为了使测试的工作量得到缩减,可在一定条件下对输入的数据进行选取,主要目标是将系统中出现错误的范围测试出来。可先在所有特定功能的模块内开展测试工作,当测试完成,并未出现问题之后,在检测系统总体,使系统总体的运行与标准完全符合。
(1)测试方法
黑盒和白盒测试是本文系统测试重点运用的测试方法。第一种测试方法仅需对现阶段的设计标准是否可通过外部得到满足,所有功能的运行是否正常,可实现预期目标。而不需对系统内部流程的精确合理高度重视;而第二种测试方式需对代码、业务流程、系统功能构成等信息进行掌握,通过数据和功能代码等方面发现存在一定概率存在的BUG。本次测试将运用黑盒测试方式,在对所有功能进行外部测试的基础上,将自身设置为对系统进行运用的用户,对系统可否满足初期制定的设计标准进行测试。
(2)测试目的
对软件运用后,研发出的产品与用户预期设计和基础需求的匹配度进行测试,发现、反馈、解决测试过程中存在一定概率存在的问题,对潜藏的问题迅速进行处理是系统测试的主要目的。在对系统存在的问题全部进行处理后,确保其毫无问题后将系统交付至用户,由其使用。
测试目标相对较为确定,需对性能水平、功能完善性等与标准的匹配度进行明确。就功能而言,用户每一项功能标准是否可通过功能模块得到满足,应制定与功能模块有关的操作手册。就系统性能而言,测试目标为运行的速度、用户界面、响应的及时程度、体验,除此以外,还包含在大量用户并发访问期间系统运行的平稳性测试。最终的测试目标为系统是否存在着兼容性的特性,以使系统可在存在差异的浏览器和操作系统中正常运用。
(3)测试范围
测试步骤、测试用例设计、测试工作的执行范围等就是系统测试范围。本文在具体需求的基础上重点开展性能测试和功能测试。重点测试图书管理系统的图书借还、图书管理、读者管理等功能。
6.3 系统功能测试
重点通过黑盒测试达到系统功能测试的目标,以对系统的功能模块的运行进行检验。
(1)测试目标:检查该系统的所有功能操作是否能够正常地运行。
(2)测试涵盖:功能实验测试重点测试图书馆借阅管理系统中包含的图书推荐、图书借阅、系统管理、图书归还四个功能模块。
(3)测试技术:在对多样化的测试用例进行设计的基础上,按照系统操作异常和操作正常两种情况对该系统可否使预计目标达成分别进行验证,也就是说,当系统操作正常时,遵循提前设计系统可否获取到科学的运行的结果;若系统的操作发生异常或错误,系统是否能够自动检测不当之处和错误类型,而后做出相关的安全提醒。
(4)完成标准:相较于预先的设置,最终设计出的图书馆借阅管理系统内所有功能模块输出的信息完全一样,所有功能都可完全按照初期设计完成,系统的报表功能中,系统能够自动统计报表的数据,而且做到准确无误。
(5)实验测试的重点:针对功能的测试中,关键的是对统计数据的展现方式、系统报表功能模块、查询功能的完善程度、系统可否自行对数据进行统计、数据更新的及时性、管理模块在图书储存及上下架过程中对信息进行记录的精确度等进行测试。
受篇幅限制,下面仅仅针对检验测试几个主要的功能模块。
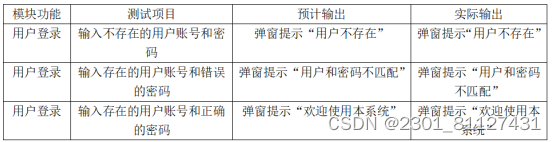
(1)用户的登录模块
用户登录是在系统内起着至关重要的作用,只有成功登录系统后才能对系统内的功能进行操作,下面对用户登录模块进行功能测试,测试结果如表9所示。
表9 用户登录功能的测试结果
(2)读者管理模块
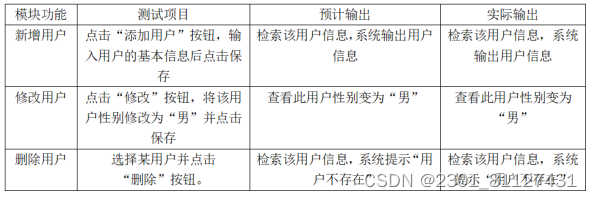
管理员可以对读者用户的咨询的管控,检索读者信息并可以对读者的性别等信息作出相应的修改。下面对图书管理模块进行功能测试,测试结果如下表10:
表10 图书管理功能的测试结果
6.4 系统性能实验测试
系统性能测试的首要任务是:对所有的工作环境中,系统运行的稳定性都进行相应的检测,而重点通过承担负载和承受压力两方面进行,在对Rational suite应用的基础之上,针对计算机运行时所面临的各种压力环境,如峰值、超负荷、正常等状态需要实现自由地模拟,将其作为使用环境对系统的性能进行监测。
(1)测试目标:对所有存在差异的工作负载中系统的正常运用与否、系统运行在系统压力出现变动时是否受到干扰测试。
(2)进行测试的范围:系统的分析时间、对用户的某些操作系统的相应反应时间,以及功能模块的切换时间和统计时间,还有查询结果的显示时间,最后是系统登录时间。
(3)测试技术:对多个地点、多名用户的操作方式进行模拟,对系统承受的压力和负荷持续进行提升,在该种情况下测试系统。
(4)完成的标准:若系统服务器所承担的压力相对而言比较小,则系统就可以流畅、极速的运行,当系统压力持续提升,逐渐达到峰值时,系统仍可运行,即便存在延迟,但用户的等待时间仍相对较短;与之相同,在系统负荷持续提升的过程中,系统还是可以正常地运行的,而且性能指标还可以继续保持在正常的区间,而不会发生有系统不正常、崩溃的情形。
(5)实验测试重要点:在一特定条件,即同一时间有大量的用户使用系统,在系统进行同样或存在差异的操作的过程中,系统能否精确运行进行测试。
重点通过测试用户并发数以及测试响应时间两方面开展性能测试工作。
(1)测试用户并发数。性能测试中最为关键的部分就是用户并发测试,该测试过程重点是在对用户访问量进行增加的基础上,最终达成提升系统负担的目的。而并发用户测试的实验重点在于系统的关键业务以和最为重要的功能,应选取重要的业务操作以及极具代表性的业务进行测试,如表11为具体的测试结果。
表11 并发用户数与事务执行情况
并发用户数 100 200 500
事务平均响应时间(s) 8.03 12.33 17.35
事务成功率 100% 100% 100%
(2)测试响应时间。为了将大量用户同时使用系统时,用户响应时间受负载、网络带宽、端口、延迟的变动产生的影响的方式精确的展现出来,下文对网络带宽和用户数目间存在的联系进行了测试。如表12为本文设计的系统在网络性能测试中的具体结果,通过观察该表可发现,该系统拥有着优良的性能,可同时供应390人运用,响应时间也使预期目标得以实现。
表12 系统响应时间
并发用户数 100 200 500
事务平均响应时间(s) 2.733 3.226 3.801
服务器端口流量(M/S) 62.2 76.5 96.7
丢包率 0.001% 0.001% 0.002%
6.5 系统测试结果
系统从功能性以及性能性两个方面进行了测试。在测试的过程当中也发现了些在编写代码过程中难以发现的问题,经过简单的代码的修改后,系统就能够正常运行。根据测试人员的反映,该系统具有操作简单、系统响应时间短、系统功能较为全面的特点,系统基本满足了用户的实际需求。
系统部分实现界面如下:
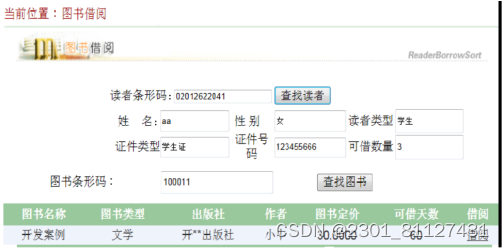
图31 图书借阅实现界面
第七章 总结与展望
在本次设计和研发系统的过程中,我学习到了以往从未学习到的知识,通过三年时间的学习,我通过书本获取了大量的理论知识,在本次实践过程中,该部分知识得以全面运用,使我获取了一次真切的研发系统的全面实现,这一方面巩固了我掌握的理论知识,另一方面还对我将其在生活中运用的能力进行了提高。
(1)首先对管理系统的研发背景进行了研究,对课题研究所具备的意义进行了论述,全面的研究了系统流程和功能方面存在的需求;
(2)在研究系统存在的需求的基础上,为了对可使相应需求得到满足的系统进行设计,选取了对应的开发语言和环境,表明了研发系统时运用的核心技术的原理、构成和特征;
(3)设计整个系统的结构,对重要功能模块的设计流程进行了说明,借助数据库表以及ER图对数据库进行了设计,使系统的总体设计得以完成。
(4)通过编码使有关功能模块得以实现,并针对系统的正常发布上限运用了系统测试的方式进行了验证。
系统开发这一工程的工程量相对较大,在开发过程中我也碰到了大量的困难,部分时间内甚至完全停滞,但我并未放弃,而是持续的对问题处理的措施进行探寻。自行查阅资料或者去向老师请教,或与同学进行探讨,其为了供应了大量的帮助,推动我本次系统开发更为良好的完成。即便最终的成果并非达到十分完美的程度,但我已在该过程中获取了相应的回报,实现了最初的目标。
在现阶段的高校图书馆领域内,基本上不存在可在具体实践中运用的现成的图书推荐系统,因此在试验过程中,本工作也无法与另一种推荐措施进行比较分析,无法将本工作中图书馆智能化推荐系统总体的优异层次进行良好的证明。另外,本工作中指出的对推荐图书结果的次序进行排列的算法的难度相对较低,因此在后续的研究过程中,本工作应以进一步对用户的阅读喜好和兴趣进行发掘的方向开展研究工作。
参考文献
[1]A Study on the Automated Compliance Test System for the LSD Protocol Providing the Digital Library Lending Model[J]. Journal of the Korea Society of Computer and Information,2017,22(4).
[2]. Science - Computer Science; Reports Outline Computer Science Findings from Ankara University (Evolutionary Approaches for Weight Optimization In Collaborative Filtering-based Recommender Systems)[J]. Computers, Networks & Communications, 2019.
[3]Abderrahmane Kouadria,Omar Nouali,Mohammad Yahya H. Al-Shamri. A Multi-criteria Collaborative Filtering Recommender System Using Learning-to-Rank and Rank Aggregation[J]. Springer Berlin Heidelberg,2020,45(4).
[4]马玉祥,冯骁.Deep Web数据集成中模式匹配算法的研究[J].西安欧亚学院学报,2009,7(01):64-68.
[5]田青.图书管理系统的系统分析及数据库设计[J].现代情报,2013,33(12):141-144.
[6]刘晶,周磊,牟群刚.小型图书管理系统的设计和实现[J].软件,2014,35(02):28-30.
[7]何芸.基于移动AR的情景敏感图书馆管理系统研究[J].图书馆杂志,2020,39(08):50-56+74.
[8]Brandon Martin,Pamela Louderback. Setting Sail for Tipasa: Preparing for an Interlibrary Loan System Transition[J]. Routledge,2019,59(8).
[9]Kai Zhou,Youhong Yuan. A Smart Ammunition Library Management System Based on Raspberry Pie[J]. Elsevier B.V.,2020,166.
[10]Preeti Mulay,Sangeeta Paliwal,Venkatesh Iyengar,Samaya Pillai,Ashwini Rao. Resolving multiple copies problem in unique-titles from biblio-records available through KOHA library management system[J]. Library Hi Tech News,2019,36(8).
[11]Ryan F. Buller. An Analysis of “Request It” Print Delivery Service in the Alma Library Management System and Its Impact on Physical Browsing in a Midsized Private Academic Library[J]. Routledge, 2020,45(1).
[12]CACM Staff. Recommendation algorithms, online privacy, and more[J]. Communications of the ACM,2009,52(5).
[13]许海玲,吴潇,李晓东,阎保平.互联网推荐系统比较研究[J].软件学报,2009,20(02):350-362.
[14]Batul J. Mirza,Benjamin J. Keller,Naren Ramakrishnan. Studying Recommendation Algorithms by Graph Analysis[J]. Journal of Intelligent Information Systems,2003,20(2).
[15]赵亮,胡乃静,张守志.个性化推荐算法设计[J].计算机研究与发展,2002(08):986-991.
[16]曹光辉,周奕.基于Android平台的“掌上图书”[J].电脑知识与技术,2020,16(01):86-87.
[17]曹异卿.基于Struts+Spring+Hibernate框架的图书借阅系统设计[J].电子世界, 2016(15):188-189.
[18]常有学,刘建胜,刘旭波.基于Spark的高校图书馆书目推荐系统[J].现代电子技术,2019,42(14):64-67+73.
[19]范奥哲,何利力.一种双向聚类协同过滤推荐算法研究[J].软件导刊,2020,19(05):78-82.
[20]关芳,高一弘,林强.基于协同过滤的高校图书馆纸本资源智能推荐方法实证研究[J].情报探索,2020(04):109-115.
[21]邝耿力.基于混合过滤的图书推荐系统的设计与效能评估[J].图书情报导刊, 2019,4(11):32-37.
[22]李欣,史宝坤,甄珍.高校图书管理系统数据库的设计与实现[J].计算机产品与流通,2020(05):196.
[23]林红.信息化图书管理的优势和必要性探析[J].中外企业家,2019(16):114+135.
[24]卢鹏飞.基于个性化推荐的图书馆检索系统设计[J].信息系统工程,2020(03):113-114.
[25]提平.基于LFM的图书推荐服务研究[J].科技传播,2020,12(07):46-47.
[26]汪琪.基于UML和Java的图书管理系统建模与实现[J].计算机产品与流通, 2019(07):168.
[27]苏宁馨,章华,张帆,金建.基于MVC架构的在线图书借阅及管理系统的设计[J].绥化学院学报,2019,39(05):135-138.
[28]王毛毛.基于java的图书管理系统研究[J].信息记录材料,2020,21(01):134-135.
[29]魏涛,刘亚军,叶传标,曹阳.基于萤火虫聚类的协同过滤推荐算法[J].电脑知识与技术,2019,15(33):289-291.
[30]杨彦荣,张莹.基于用户聚类的图书协同推荐算法研究[J].科技资讯, 2020, 18(09):198-199.
[31]杨云,李文如.基于Mahout的图书推荐系统研究[J].重庆科技学院学报(自然科学版),2019,21(04):98-102.
[32]张淼,刘东旭.基于协同过滤算法的音乐推荐系统的研究与实现[J].电子世界, 2020(10):63-64.
[33]林艳凤,苑吉洋.基于2K-means算法的读者兴趣分类图书自动推荐系统设计[J].现代电子技术,2020,43(20):141-144+148.
[34]张戈一,朱月琴,吕鹏飞,刘广开,胡博然.耦合协同过滤推荐与关联分析的图书推荐方法研究[J].中国矿业,2017,26(S1):425-430.
[35]丁勇,朱长水.基于Android平台的图书阅读推荐系统[J].计算机科学,2016,43(S1):523-525+554.
[36]郑祥云,陈志刚,黄瑞,李博.基于主题模型的个性化图书推荐算法[J].计算机应用,2015,35(09):2569-2573.
[37]孙彦超.基于聚类分析算法的图书推荐系统的研究[J].图书馆理论与实践,2015(05):76-79.
[38]匡文波.智能算法推荐技术的逻辑理路、伦理问题及规制方略[J].深圳大学学报(人文社会科学版),2021,38(01):144-151.
[39]曹意.基于人工智能技术的图书馆书目协同推荐系统[J].现代电子技术,2020,43(15):168-170+174.
[40]刘君良,李晓光.个性化推荐系统技术进展[J].计算机科学,2020,47(07):47-55.
[41]冷亚军,陆青,梁昌勇.协同过滤推荐技术综述[J].模式识别与人工智能,2014,27(08):720-734.
[42]聂飞霞.基于数据挖掘技术的移动图书馆个性化图书推荐服务[J].图书馆学刊,2014,36(05):104-106.
[43]杨圩生,罗爱民,张萌萌.基于信任环的用户冷启动推荐[J].计算机科学,2013,40(S2):363-365+397.
[44]聂珍,王华秋,周建.个性化推荐技术在图书馆服务中的应用[J].现代情报,2013,33(09):95-98+102.
[45]王晋月.基于Hadoop平台的图书推荐方法研究[J].电子设计工程,2019,27(24):20-23.
[46]王红.基于数据挖掘技术的图书推荐算法应用研究[J].现代信息科技,2019,3(23):20-21+24.
[47]吴文臣.数据挖掘技术在图书馆推荐系统中的应用研究[J].电脑知识与技术,2019,15(33):241-242+250.
[48]刘超慧,李宇根,陶浩武,周青.基于用户-图书资源特征的图书资源推荐技术研究[J].电子世界,2019(08):86-87.
[49]刘晓敏.协同过滤技术在图书推荐系统中的应用研究[J].中国教育技术装备,2018(08):61-62.
[50]张若冉.基于用户兴趣变化的高校图书馆个性化图书推荐研究[J].农业图书情报学刊,2017,29(11):10-14.
附录
/**
-
LFM(latent factor model)隐语义推荐模型,矩阵分解,训练得到U,I矩阵
-
对user-item评分矩阵进行分解为U、I矩阵,再利用随机梯度下降(函数值下降最快的方向)迭代求解出U,I矩阵,最后用U*I预测得出user对item的预测评分
-
这里U矩阵是user对每个隐因子的偏好程度,I矩阵是item在每个隐因子中的分布
**/
public class LFM extends AbsMF {public LFM() {
}public static void main(String[] args) {
String dataPath = “resultData.txt”;
LFM lfm = new LFM();
lfm.loadData(dataPath);
lfm.initParam(30, 0.02, 0.01, 50);
lfm.train();System.out.println("Input userID..."); Scanner in = new Scanner(System.in); while (true) { String userID = in.nextLine(); FastList<RecommendedItem> recommendedItems = lfm.calRecSingleUser(userID, 50); lfm.displayRecoItem(userID, recommendedItems); System.out.println("Input userID..."); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
}
/**-
初始化F,α,λ,max_iter,U,I
-
@param F 隐因子数目
-
@param α 学习速率
-
@param λ 正则化参数,以防过拟合
-
@param max_iter 迭代次数
*/
@Override
public void initParam(int F, double α, double λ, int max_iter) {
System.out.println("init… " + "F= " + F + "; " + "α= " + α + "; " + "λ= " + λ + "; " + "max_iter= " + max_iter + “;”);
this.F = F;
this.α = α;
this.λ = λ;
this.max_iter = max_iter;
this.U = new FastMap<String, Double[]>();
this.I = new FastMap<String, Double[]>();String userID = null;
Double[] randomUValue = null;
Double[] randomIValue = null;
//对U,I矩阵随机初始化
for (Entry<String, FastMap<String, Double>> entry : ratingData.entrySet()) {
userID = entry.getKey();
randomUValue = new Double[F];
for (int i = 0; i < F; i++) {
double rand = Math.random() / Math.sqrt(F);//随机数填充初始化矩阵,并和1/sqrt(F)成正比
randomUValue[i] = rand;
}
U.put(userID, randomUValue);
for (String itemID : entry.getValue().keySet()) {
if (I.containsKey(itemID))
continue;
randomIValue = new Double[F];
for (int i = 0; i < F; i++) {
double rand = Math.random() / Math.sqrt(F);
randomIValue[i] = rand;
}
I.put(itemID, randomIValue);
}
}
}
/**
- 随机梯度下降训练U,I矩阵
*/
@Override
public void train() {
System.out.println(“training U,I…”);
for (int step = 0; step < this.max_iter; step++) {
System.out.println(“第” + (step + 1) + “次迭代…”);
for (Entry<String, FastMap<String, Double>> entry : this.ratingData.entrySet()) {
String userID = entry.getKey();
for (Entry<String, Double> entry1 : entry.getValue().entrySet()) {
String itemID = entry1.getKey();
double pui = this.predictRating(userID, itemID);
double err = entry1.getValue() - pui;//根据当前参数计算误差
Double[] userValue = this.U.get(userID);
Double[] itemValue = this.I.get(itemID);
for (int i = 0; i < this.F; i++) {
double us = userValue[i];
double it = itemValue[i];
us += this.α * (err * it - this.λ * us);//后一项是来避免有过拟合正则化项的出现,而λ则是要在特定的场景中反复测试来得到。至于损失函数的优化方法,则是用“随机梯度下降”的算法
it += this.α * (err * us - this.λ * it);
userValue[i] = us;
itemValue[i] = it;
}
}
}
this.α *= 0.9;//每次迭代步长要逐步缩小
}
}
/**
- userID对itemID的评分
- U每行表示该用户对各个隐因子的偏好程度
- I每列表示该物品在各个隐患因子中的概率分布
- rating=P*Q
- @param userID
- @param itemID
- @return
*/
@Override
public double predictRating(String userID, String itemID) {
double p = 0.0;
Double[] userValue = this.U.get(userID);
Double[] itemValue = this.I.get(itemID);
for (int i = 0; i < this.F; i++) {
p += userValue[i] * itemValue[i];
}
return p;
}
}
致谢
三年过去了,研究生的生涯也即将结束。在北航大学就读期间,无论是在学业还是生活上,我都学到了很多东西。在这里,我有过幸福,也经历了不少沉重的事情,在学习生活中一度经受过困扰,犹豫过也想过放弃。但是最后,我选择了坚持,在此,一定要感谢我亲爱的老师们,以及朋友和同学们的帮助,你们的关心和鼓励是我坚持下去的动力!
撰写这份毕业设计论文的过程中,我不仅在理论的指导下,于实践过程中验证了学过的基本知识,还提高了自己的实践创新能力,并且对软件开发的整个过程有一定的了解。
本文的指导任务是在杜孝平教授的具体帮助下进行的。首先,我要感谢杜老师。在明确本文的主题研究目标、进程,以及到本文完美结束的过程中,杜老师给了我很多的帮助,在关键问题上为我提出了许多宝贵的建议,我真的受益匪浅。杜老师端正直爽,认真细致,对科研方向有着独特的见解。
其次,我要感谢孙天武老师,谢谢孙老师给我们提供良好的论文思路,使我可以有更清晰的科研目标。在日常的科研生活中,孙先生经常就学术研究问题与我们进行讨论和沟通,并帮助我们每个人摆脱学术研究的困惑,教育大家进行学术研究时要孜孜不倦,不要被困难吓到,而是一定要坚持。
然后,我要感谢实验室中的朋友。正是大家的呵护和不遗余力的帮助使我在遇到困难时坚持不懈、不知疲倦地走了下来。实验室中的每个人的欢笑声还仿佛在我的耳畔。我们曾一起交流流学术、研究问题,快乐地打篮球,一起去自助餐厅吃饭等等。感谢大家一起和我度过这三年的硕士生生涯。
最后,我要感谢我的父母和朋友,他们默默地鼓励我完成硕士的学习和生活。这种独特的三年生活使我能够学习和训练专业知识,使我成长很多,并使我变得更强大。多亏我的母校,多亏了软件学院,这样我才能拥有这么好的机会与优秀的老师和同学一起
互相讨论学术和人生,并且,我在吸收知识的过程也交往了许多志同道合的朋友,这三年的硕士生涯让我无比充实和幸福。

