
- 1虚拟机配置(hadoop)前置准备_开启3台虚拟机, 配置主机名
- 2Python学习实验报告(1)_python实验报告
- 3Redis-在springboot环境下执行lua脚本
- 42023 英特尔On技术创新大会直播 | 边云协同加速 AI 解决方案商业化落地_英特尔张宇博士
- 5Android安卓App应用程序开发后如何运行到真机上?_安卓开发怎么在手机上演示
- 6西电计网ARP欺骗实验_win11 cain软件
- 7解决页面滚动条出现和消失的过程页面会横向移动的问题_css滚动条出现和消失页面动一下
- 8小白向攻略简单易懂,怎么用DomoAI将手机里面的视频转换成丝滑流畅高帧数的动画_domo ai
- 9轻松上手MYSQL:MYSQL事务隔离级别的奇幻之旅
- 10Python - 简易版计算器(附完整代码)_python计算器
mysql数据库设计
赞
踩
mysql基本数据类型
-
数值型
-
整数
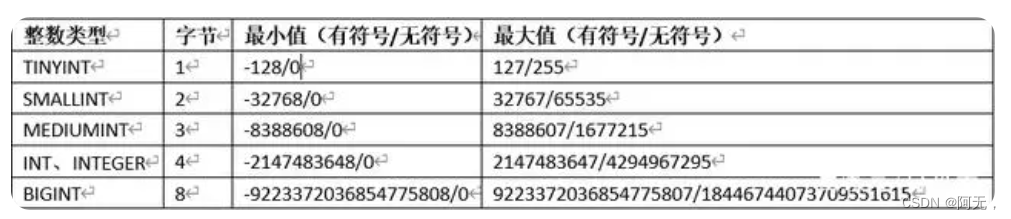
-
小数
- 定点数(建议使用这个,不存在精度损失,如货币运算)
decimal(m,d) 指定整数位与小数位长度的小数类型,8字节
m代表整数位数和小数位数的总长度,d代表小数位数的长度
如果超出则插入临界值,例如整数位数指定两位,插入100的话,它就会自动插入99 - 浮点数(会丢失精度)
float/double,4字节/8字节
- 定点数(建议使用这个,不存在精度损失,如货币运算)
-
-
字符型
- 较短的文本
- char(10)
括号中指定最长字符数,
char是定长的,例如指定长度是10,只写入两个字符,依然占据10个字符的长度 - varchar(10)
长度是可变的,例如指定长度是10,只写入两个字符,只会占据两个字符的长度
- char(10)
- 较长的文本:text,blob(较长的二进制数据)
- 较短的文本
char最大长度为255,varchar则大很多。
我们可以预见数据的长度,就用char。

- 日期型
- date,日期,4字节
- datetime,时间,8字节
- timestamp 时间戳,4字节
关系型数据库设计:三大范式的通俗理解
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
而通常我们用的最多的就是第一范式(1NF)、第二范式(2NF)、第三范式(3NF),也就是本文要讲的“三大范式”。
第一范式(1NF):要求数据库表的每一列都是不可分割的原子数据项。
举例说明:
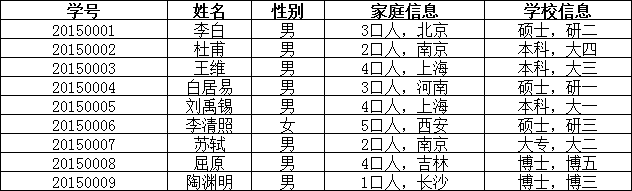
在上面的表中,“家庭信息”和“学校信息”列均不满足原子性的要求,故不满足第一范式,调整如下:
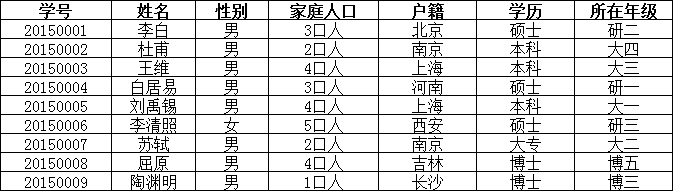
可见,调整后的每一列都是不可再分的,因此满足第一范式(1NF);
第二范式(2NF):在第一范式的基础上更进一步,目标是确保表中的每列都和主键相关。
第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
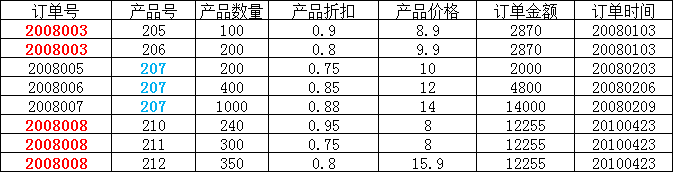
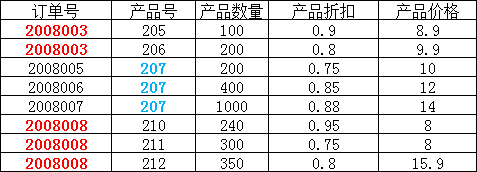
在上图所示的情况中,同一个订单中可能包含不同的产品,因此主键必须是“订单号”和“产品号”联合组成,
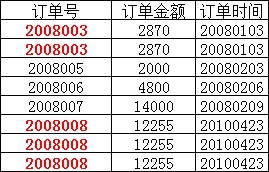
但可以发现,产品数量、产品折扣、产品价格与“订单号”和“产品号”都相关,但是订单金额和订单时间仅与“订单号”相关,与“产品号”无关,
这样就不满足第二范式的要求,调整如下,需分成两个表:
第三范式(3NF):在第二范式的基础上更进一步,目标是确保表中的列都和主键直接相关,而不是间接相关
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
举例说明:
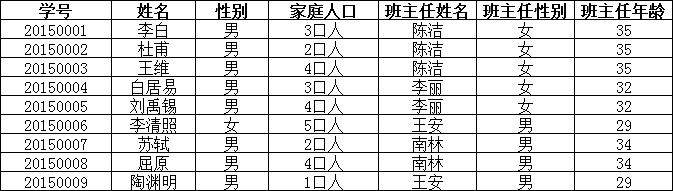
上表中,所有属性都完全依赖于学号,所以满足第二范式,但是“班主任性别”和“班主任年龄”直接依赖的是“班主任姓名”,
而不是主键“学号”,所以需做如下调整:
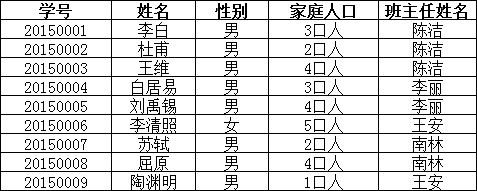
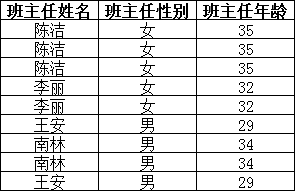
这样一来,就满足了第三范式的要求。
ps:如果把上表中的班主任姓名改成班主任教工号可能更确切,更符合实际情况,不过只要能理解就行。
反范式
反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能。
例如:在上例中的 user_role用户-角色中间表增加字段role_name。
反范式化可以减少表的关联查询(join),多表联查还有可能会引起索引失效,所以在有些场景使用反范式是会极大提高查询效率的。
具体的场景还没找到,找到再来补充
mysql表设计
主键设计问题
为什么一定要设一个主键?
因为你不设主键的情况下,innodb也会帮你生成一个隐藏列,作为自增主键。所以啦,反正都要生成一个主键,那你还不如自己指定一个主键,在有些情况下,就能显式的用上主键索引,提高查询效率!
主键为什么不推荐有业务含义?
因为任何有业务含义的列都有改变的可能性,主键一旦带上了业务含义,那么主键就有可能发生变更。
主键一旦发生变更,该数据在磁盘上的存储位置就会发生变更,有可能会引发页分裂,产生空间碎片。
时间字段用什么类型?
回答:此题无固定答案,应结合自己项目背景来答!把理由讲清楚就行!
一般会使用datetime或者timestamp这两种类型存储。
-
varchar,如果用varchar类型来存时间,优点在于显示直观。但是坑的地方也是挺多的。比如,插入的数据没有校验,你可能某天就发现一条数据为2013111的数据,请问这是代表2013年1月11日,还是2013年11月1日?其次,
做时间比较运算,你需要用STR_TO_DATE等函数将其转化为时间类型,你会发现这么写是无法命中索引的。数据量一大,会影响效率,是个坑!在 存储的时间将来不需要进行
大量计算的前提下,可以考虑选择varchar类型,反之,选择datetime类型。 -
timestamp,该类型是四个字节的整数,它能表示的时间范围为1970-01-01 08:00:01到2038-01-19 11:14:07;存入是整型,显示是日期格式。
2038年以后的时间,是无法用timestamp类型存储的。
但是它有一个优势,timestamp类型是带有时区信息的。一旦你系统中的时区发生改变,例如你修改了时区
SET TIME_ZONE = "america/new_york";
- 1
你会发现,项目中的该字段的值自己会发生变更。这个特性用来做一些国际化大项目,跨时区的应用时,特别注意!
-
datetime,datetime储存占用8个字节,它存储的时间范围为1000-01-01 00:00:00 ~ 9999-12-31 23:59:59。显然,存储时间范围更大。
但是它坑的地方在于,他存储的是时间绝对值,不带有时区信息。如果你改变数据库的时区,该项的值不会自己发生变更! -
bigint,也是8个字节,自己维护一个时间戳,表示范围比timestamp大多了,就是要自己维护,不大方便。
为什么不使用字符串存储日期?
字符串无法完成数据库内部的范围筛选
如果需要使用时间戳timestamp和int该如何选择?

货币字段用什么类型?
回答:如果货币单位是分,可以用Int类型。如果坚持用元,用Decimal。
千万不要答float和double,因为float和double是以二进制存储的,所以有一定的误差。
打个比方,你建一个列如下
CREATE TABLE `t` (
`price` float(10,2) DEFAULT NULL,
) ENGINE=InnoDB DEFAULT CHARSET=utf8
- 1
- 2
- 3
然后insert给price列一个数据为1234567.23,你会发现显示出来的数据变为1234567.25,精度失准!
为什么不直接存储图片、音频、视频等大容量内容?
回答:我们在实际应用中,都是用HDFS来存储文件。然后mysql中,只存文件的存放路径。mysql中有两个字段类型被用来设计存放大容量文件,也就是text和blob类型。但是,我们在生产中,基本不用这两个类型!
主要原因有如下两点
- Mysql内存临时表不支持TEXT、BLOB这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。导致查询效率缓慢
- binlog内容太多。因为你数据内容比较大,就会造成binlog内容比较多。大家也知道,主从同步是靠binlog进行同步,binlog太大了,就会导致主从同步效率问题!
因此,不推荐使用text和blob类型!
字段为什么要定义为NOT NULL?
- 索引性能不好
- 查询会出现一些不可预料的结果
create table table_2 ( `id` INT (11) NOT NULL, name varchar(20) NOT NULL ) # 表数据为 id name 1 zs 2 3 4 ls select count(name) from table_2; # 你会发现结果为2,但是实际上是有四条数据的!类似的查询问题,其实有很多,不一一列举。 # 记住,因为null列的存在,会出现很多出人意料的结果,从而浪费开发时间去排查Bug.

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
根据MySQL的官网文档及《mysql技术内幕-存储引擎》和《高性能Mysql》一说,MySQL中存储null的确为额外占用一些空间,但将这些列从null优化为not null,并非会有很大的性能提升。
null的问题主要还是一些逻辑方面的问题,比如可能会使计算复杂些,会让我们处理的时候要多考虑些,亦或者是和其他中间件进行结合的时候,其他中间件对null的处理不太友好而出现一些问题等。
char、varchar和text的设计
最近有表结构设计中出现了varchar(10000)的设计引起了大家的讨论,我们下面就来分析分析。
char、varchar和text基础知识
-
char(n)和varchar(n)中
括号中n代表字符的个数,并不代表字节个数,所以当使用了中文的时候(UTF8)意味着可以插入m个中文,但是实际会占用m*3个字节。 -
同时char和varchar最大的区别就在于
char不管实际value都会占用n个字符的空间,而varchar只会占用实际字符应该占用的空间+1,并且实际空间+1<=n。 -
超过char和varchar的n设置后,
字符串会被截断。 -
char的上限为255字节,varchar的上限65535字节,text的上限为65535。
-
char在存储的时候会
截断尾部的空格,varchar和text不会。 -
varchar会使用1-3个字节来存储长度,text不会。
总体来说
- char,存定长,速度快,存在空间浪费的可能,会处理尾部空格,上限255。
- varchar,存变长,速度慢,不存在空间浪费,不处理尾部空格,上限65535,但是有存储长度实际65532最大可用。
- text,存变长大数据,速度慢,不存在空间浪费,不处理尾部空格,上限65535,会用额外空间存放数据长度,故可以全部使用65535。
结构设计中出现了varchar(10000)用什么类型?
当varchar(n)后面的n非常大的时候我们是使用varchar好,还是text好呢?这是个明显的量变引发质变的问题。我们从2个方面考虑,第一是空间,第二是性能。
-
首先从空间方面:
从官方文档中我们可以得知当varchar大于某些数值的时候,其会自动转换为text,大概规则如下:
- 大于varchar(255)变为 tinytext
- 大于varchar(500)变为 text
- 大于varchar(20000)变为 mediumtext
所以对于过大的内容使用varchar和text没有太多区别。
-
其次从性能方面:
索引会是影响性能的最关键因素,而对于text来说,只能添加前缀索引,并且前缀索引最大只能达到1000字节。
而貌似varhcar可以添加全部索引,但是经过测试,其实也不是。由于会进行内部的转换,所以long varchar其实也只能添加1000字节的索引,如果超长了会自动截断。
所以我们认为当超过255的长度之后,使用varchar和text没有本质区别,只需要考虑一下两个类型的特性即可。(主要考虑text没有默认值的问题)
但是个人推荐使用varchar(10000),毕竟这个还有截断,可以保证字段的最大值可控,如果使用text那么如果code有漏洞很有可能就写入数据库一个很大的内容,会造成风险。
故,本着short is better原则,还是使用varchar根据需求来限制最大上限最好。
部分内容引用自:
https://www.cnblogs.com/billyxp/p/3548540.html
https://www.cnblogs.com/wsg25/p/9615100.html
https://www.cnblogs.com/youngdeng/p/12855570.html
https://baijiahao.baidu.com/s?id=1706684904063421331&wfr=spider&for=pc
如果有人祈求佛祖保佑另一个主,那就只有一种可能,她的那个主是真是存在的。
《三体》刘慈欣

