
- 12024年信息素养大赛图形化编程、Python、算法创真题汇总_2024全国青少年信息素养大赛的图形化编程进复赛是线下
- 2golang学习笔记struct-继承_go语言继承其他package中的struct
- 3git clone error: RPC failed; curl 56 GnuTLS recv error (-54): Error in the pull function
- 4关于python使用hadoop(使用python操作hdfs)_python 执行hadoop fs 命令
- 5计算机专业是万金油,为什么说自动化专业是万金油专业
- 6NFS 速度变慢问题排查 性能优化_nfs 可以在高流量负载的情况访问速度会变慢
- 7将本地项目上传到新的git仓库的流程_我们本地已经开发好了 项目现在要上传到指定的git仓库要如何操作
- 8ue5.1的增强输入(学习笔记)_enhanced input local player subsystem
- 9图片像素分析与功能实现_图片是由一系列像素点构成的
- 10【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 团队派遣(100分) - 三语言AC题解(Python/Java/Cpp)
遗传算法的编码方式以及MATLAB实现_遗传算法离散变量怎么编码
赞
踩
系列文章目录
遗传算法原理以及matlab代码_matlab遗传算法代码_电气不会转控制的博客-CSDN博客
前言
提示:这里可以添加本文要记录的大概内容:
由于遗传算法不能直接处理问题空间的参数,因此必须通过编码将要求解的问题表示成遗传空间的染色体或者个体。 这一转换操作就叫做编码,也可以称作(问题的)表示(representation)。
在变成实现遗传算法时,首要遇到的关键问题就是编码。编码的方法会直接影响到了遗传算法后续的一系列操作,交叉、变异等,并且编码方式选取的好坏也会直接影响到算法的收敛速度和最优值。
编码也就是问题表达:首先实现从性状到基因得映射,即编码工作,然后从代表问题可能潜在解集得一个种群开始进行进化求解。(粒子群,蚁群都需要问题表达)
提示:以下是本篇文章正文内容,下面案例可供参考
一、编码是什么?
编码就是对问题进行数字化,在遗传算法中就是采用基因序列表达具体问题,然后对基因序列(表达后的问题)进行比较运算得到对应的基因序列结果,再将基因序列结果进行解码变成解决问题的实际结果。
如图所示,首先将问题用基因序列进行表达,然对基因序列进行操作(交叉,遗传,变异,选优等)然后得到最有基因序列,通过解码即可得到最优解。
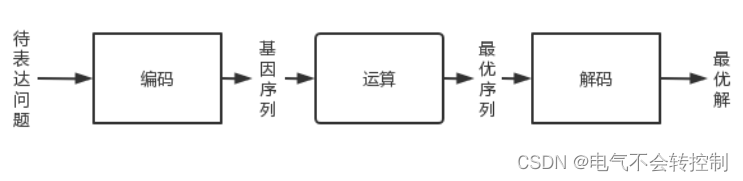
具体实例:
例1 利用遗传算法求解整数区间[0,31]上的二次函数y=(1-x)^2的最小值。
解:一共有0~31,共32个整数,5位二进制码可以表示32个不同的数,因此采用5位二进制编码。
若x=10,编码:y=01010b,解码:x=decimal(string),x=1*8+1*2=10。
例2 利用遗传算法求解整数区间[-5,5]上的二次函数y=(1-x)2的最小值。
解:一共有-5~5,共11个整数,4位二进制码可以表示16个不同的数,因此采用4位二进制编码。
若x=4,编码:y=01001b,解码:x=-5+decimal(string),x=1*8+1*1-5=4。
二、二进制编码
1.整数区间
二进制编码就是采用二进制序列来表示问题,就如例1所示。
对其进行一般化分析:
更一般的:如果自变量取值范围为整数区间[a,b] ,需要多少位二进制?如何解码?
解:一共有b-a+1个可能取值,假定需要m位二进制码,m需要满足公式
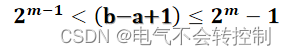
解码:x=a+decimal(string)
2.实数区间
更一般的:如果自变量取值范围为实数区间[a,b],要求保留到小数点后n位,需要多少位二进制?如何解码?
解:一共有(b-a)×10^n个可能取值,假定需要m位二进制码,m需要满足公式

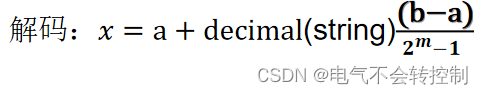
上述例子的问题都是有确定个数,当被描述问题是一个范围值时,没有具体的保留小数位数,就需要根据实际情况自行确定二进制位数。二进制数量越大,越精确,但是计算量也就越大。
3.多变量
例 利用遗传算法求解函数y=(1−x_1)sinx_2的最小值,其中x_1∈(−1,2),x_2∈(−1,1),要求精确到小数点后两位。
解:每个个体(解)应该是二维向量 x=[x1, x2]
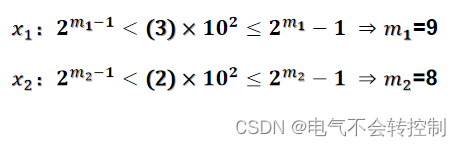

例2
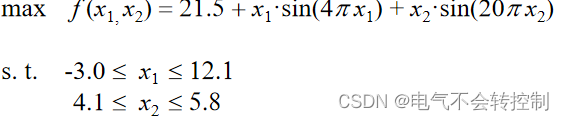
解:

基因型——表现型

4.运算操作(交叉,变异)
Crossover(交叉)
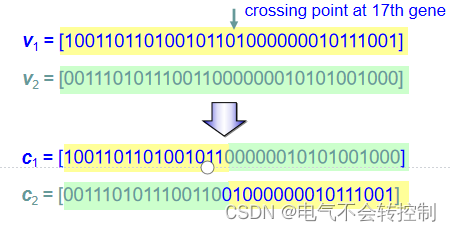
Mutation(变异)
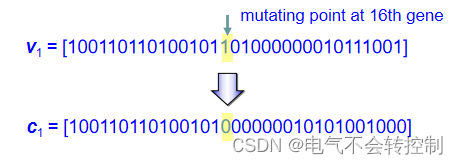
三、实数编码

假定决策变量x为d维向量,x^(i)表示第i号个体, x_j^(i)表示第i号个体第j维变量元素,表达多维变量,对精度要求高,二进制编码和解码不方便,是否可以用实数表示?
如果编码方式改变,遗传算法中的交叉操作和变异操作的方式也应该随着改变,适应新的编码方式。
1.实数编码的交叉操作
二进制交叉:1到(k-1)位不变,从第k位之后做交换
而实数编码没有类似于二进制编码的序列,所以不能按照这个方法进行交叉,一下是一些较为简单的实数交叉算法:
1.linear operator(线性交叉)
从{ (x(1)+ x(2)) , (1.5x(1)− 0.5x(2)) , (−0.5x(1) + 1.5x(2) }选两个最好的,作为x(1), x(2)
2.directional heuristic crossover(定向启发式交叉)
x(i)=rand()×(x(i1)−x^(i2))+x(i1) 其中:x(i1) 优于x(i2) 目的是使得子代更接近优势父代
3.arithmetic crossover (weighted average)(加权平均式交叉)

目的是使得子代的多样性更好
4.geometrical crossover(加权平均式交叉)

以上四种交叉方法,都是较为基础的方式,面常用的实数交叉方法是Simulated binary crossover (SBX)
****5.Simulated binary crossover (SBX)****
实数交叉: 1到(k-1)位不变,第k位进行SBX计算,从r+1位开始做交换

第k位进行SBX计算
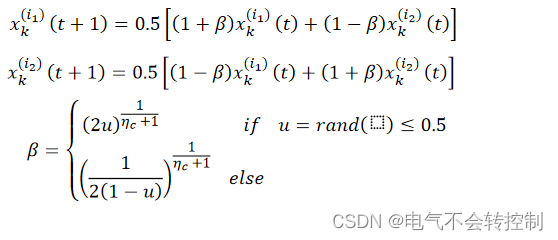
其中ηc是自行选取,ηc越大子代越接近父代,ηc越小子代多样性越好,通常取20,30。
2.实数编码的变异操作
一般实数编码对应的编译操作都是采用多项式变异 ( polynomial mutation operators )
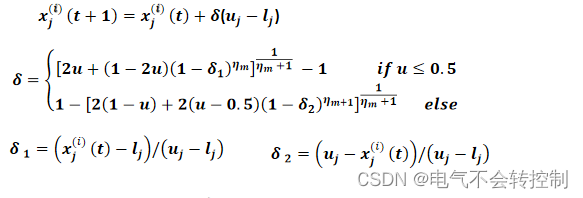
因为变异是为了提高种群的多样性,所以需要引入随机数,其中u=rand()。
而ηm通常取20,30
四、MATLAB代码实现
其中二进制编码的代码在第一章遗传算法与MATLAB实现中已经给出,
链接如下:https://mp.csdn.net/mp_blog/creation/editor/126653614
接下来的代码只是针对实数编码的遗传算法。
main.m
- clear
- clc
- t1=cputime;
- num=50; % 表示群体的大小,根据问题的复杂程度确定。
- gen=100; % 迭代次数,这里只采用100次迭代
- pm=0.02; % 变异概率,一般 1/dim
- pc=0.8; % 交叉概率
- p=init(num); % 初始化种群
- for i=1:gen
- son1=crossover(p,pc); % 在种群中进行实数遗传交叉得到子代
- son=mutation(son1,pm); % 子代还需进行变异才能成为真正子代 son
- son=[p;son]; % 将父代和子代合并 ,进行选择
- p=select(num,son); % 采用锦标赛的选择算子,产生新种群
- [p_best,value]=best(p);
- yy(i)=value;
- end
- yy(1)=yy(2);
-
- plot_ga(p) % 画出新种群
- % 迭代后最终的最优目标值
- t2=cputime;
- t=t2-t1;
- da=['种群: ',num2str(num),';迭代: ',num2str(gen),';目标值: ',num2str(value),';运行时间: ',num2str(t)];disp(da)
- figure(2)
- plot(yy)
- title('GA最优个体适应度','fontsize',12);
- xlabel('进化代数','fontsize',12);
- ylabel('适应度','fontsize',12);
-
-

select
- function p=select(num,son)
- p=zeros([num,2]);
- s=size(son);
- p_obj1=fun1(son);
- %-------------------------------锦标赛-------------------------------------
- randidx=randperm(s(1)); %打乱顺序进行锦标赛
- son_s1=son(randidx,:);
- p_s1=p_obj1(randidx,:);
-
- for i=1:round(s(1)/2-0.5)
- if (p_s1(2*i-1,2)==0)&&(p_s1(2*i,2)==0) %判断约束条件
- if p_s1(2*i,1)>=p_s1(2*i-1,1)
- p(i,:)=son_s1(2*i,:);
- else
- p(i,:)=son_s1(2*i-1,:);
- end
- end
- if (p_s1(2*i-1,2)==0)&&(p_s1(2*i,2)>0) %判断约束条件
- p(i,:)=son_s1(2*i-1,:);
- end
- if (p_s1(2*i-1,2)>0)&&(p_s1(2*i,2)==0) %判断约束条件
- p(i,:)=son_s1(2*i,:);
- end
- if (p_s1(2*i-1,2)>0)&&(p_s1(2*i,2)>0) %判断约束条件
- if p_s1(2*i,2)<=p_s1(2*i-1,2)
- p(i,:)=son_s1(2*i,:);
- else
- p(i,:)=son_s1(2*i-1,:);
- end
- end
- end
-
plot_ga.m
- function plot_ga(p)
- clf(figure(1))
- figure(1)
-
- x=[-4:0.01:4];
- y=[1:0.01:6];
- [X,Y]=meshgrid(x,y);
- Z= 21.5+X.*sin(4.*pi.*X)+Y.*sin(20.*pi.*Y);
- mesh(X,Y,Z)
- title('GA最优个体适应度','fontsize',12);%打点
- hold on
- p1=fun1(p);
- % plot3(p(:,1),p(:,2),p1(:,1),'r*',[50])
-
- scatter3(p(:,1),p(:,2),p1(:,1),[50],[1 0 0],'o');
- hold on
mutation.m
- % mu1tation--变异
- %子代染色体序列中,可能变异导致 1 变为 0 、 0 变为 1 。
-
- function son=mutation(son1,pm)
- s=size(son1); %获取数据大小
- son=zeros(s); %定义变异后子代
- for i=1:s(1) %循环产生变异子代
- son(i,:)=son1(i,:);
- if(rand(1)<pm)
- if(round(rand(1))==0) % 确定k=1时,进行杂交
- u=rand(1); % 确定u,
- if(round(u)==0)
- a=-1+((2*u)+(1-2*u)*(1-(son(i,1)+4)/8)^20)^(1/21); % 确定δ,
- else
- a=1-((2-2*u)+(2*u-1)*(1-(4-son(i,1))/8)^21)^(1/21);
- end
- son(i,1)=son(i,1)+a; % 进行杂交
- son(i,1)=max(-4,min(4,son(i,1)));
- else % 确定k=2时,进行杂交
- u=rand(1); % 确定u,
- if(round(u)==0)
- a=-1+((2*u)+(1-2*u)*(1-(son(i,2)-1)/5)^20)^(1/21); % 确定δ,
- else
- a=1-((2-2*u)+(2*u-1)*(1-(6-son(i,2))/5)^21)^(1/21);
- end
- son(i,2)=son(i,2)+a;
- son(i,2)=max(1,min(6,son(i,2)));
-
- end
- end
- end
- end
init.m
- %init
- % init.m是进行群体的初始化,产生初始种群,num表示群体的大小,dim表示染色体的长度
- function pop=init(num)
- pop=zeros([num,2]); % 有两个实数,生成两个值
- pop(:,1)=8*rand(num,1)-4; % 由约束条件生成x1
- pop(:,2)=5*rand(num,1)+1; % 由约束条件生成x2
- end
fun1.m
- function f=fun1(x)
- x1=x(:,1);
- x2=x(:,2);
- f(:,1) = 21.5+x1.*sin(4.*pi.*x1)+x2.*sin(20.*pi.*x2); %目标值
- for i=1:size(x1)
- if ((x1(i))^2+(x2(i))^2)<20
- f(i,2) = 0;
- else
- f(i,2) = ((x1(i))^2+(x2(i))^2)-20;
- end
- end
- % x1^2+ x2^2 <20
- % -4.0 <x1 <4
- % 1<x2 <6
- end
fittest.m
- % fittest.m
- % 1,计算目标值,2.计算对应适应值
- % 设定优秀阈值h,小于h不能直接进入下一代种群选择,大于h适应值为目标值,和子代一起进入选择。
-
- % 1,计算目标值,
- function p_fit=fittest(p)
-
- x1=zeros([1,20]);
- p1=zeros([1,20]);
- for i=1:20
- for j=1:10
- x1(i)=x1(i)+2^(10-j)*p(i,j);
- end
- end
- x=(x1*4/1023)-2; %2^10-1=1023
- for i=1:20
- if x(i)>0.5
- p1(i)=1-sin(10.*x(i)).*cos(x(i)); %计算目标值
- end
- if x(i)<=0.5
- p1(i)=sin(10.*x(i)).*cos(x(i)); %计算目标值
- end
- end
-
- % 2.计算对应适应值,以及确定优秀个体
- h=-0.5;
- j=1;
- for i=1:20
- if p1(i)>h
- p_fit(j,:)=p(i,:);
- j=j+1;
- end
- end
-
crossover.m
- % 交叉
- % 对于下面两个父代,x,y。染色体被分为两组,相互交叉得到子代 x',y'。
- % x=x1 x2 交 y=y1 y2
- % x=x1' y2 叉 y=y1' x2
-
- function son=crossover(p,pc)
- s=size(p);
- son=zeros(s);
- for i=1:round(s(1)/2-0.5)
- if(rand(1)<pc) % 判断是否杂交
- u=rand(1); % 根据u的大小确定β,
- if(round(u)==0)
- a=(2*u)^(1/21); % 确定β1,
- else
- a=(2-2*u)^(-1/21); % 确定β2,
- end
- if(round(rand(1))==0) % k=1时,第一个实数杂交,第二个互换
- son((i-1)*2+1,1)=0.5*((1+a)*p((i-1)*2+1,1)+(1-a)*p(i*2,1)); % 进行杂交
- son(i*2,1)=0.5*((1-a)*p((i-1)*2+1,1)+(1+a)*p(i*2,1));
- son((i-1)*2+1,2)=p(i*2,2);
- son(i*2,2)=p((i-1)*2+1,2);
- else % k=2时,第二个实数杂交,
- son((i-1)*2+1,2)=0.5*((1+a)*p((i-1)*2+1,2)+(1-a)*p(i*2,2)); % 进行杂交
- son(i*2,2)=0.5*((1-a)*p((i-1)*2+1,2)+(1+a)*p(i*2,2));
- son((i-1)*2+1,1)= p((i-1)*2+1,1);
- son(i*2,1)=p(i*2,1);
-
- end
- else
- son((i-1)*2+1,:)=p((i-1)*2+1,:);
- son(i*2,:)=p(i*2,:);
- end
- end
- end
best.m
- function [p_best,value]=best(p)
- p1=fun1(p);
- [value,b]=max(p1(:,1));
- p_best=p(b,:);
总结
以上就是今天要讲的内容,本文简单介绍了遗传算法的二进制编码和实数编码所对应算法中(交叉,变异)操作的方式。


