
- 1怎么在vite项目中全局导入一个scss文件_vite scss
- 2Linux命令整理_命令行不用用户传输文件怎么设置
- 3Docker容器化部署Redis_容器部署redis
- 4简述达梦和ORACLE数据库的些些比较_达梦数据库和oracle
- 5ICLR 2023 | 大模型上下文学习的无限扩展方法:kNN Prompting
- 6《白话机器学习的数学》第4章——评估
- 7阿里云盾占用资源的问题AliYunDun,AliYunDunUpdate_阿里云服务器阿里云盾占用内容怎么办
- 8【数据结构11】栈和队列OJ题之用队列实现栈_东华大学oj用队列实现栈
- 9探索LLamaFile:Mozilla Ocho的高效文件管理利器
- 10在win10折腾Flowise:部署和尝试
RAGFlow 实现_ragflow 支持文件数量
赞
踩
RAGFlow(Retrieval-Augmented Generation Flow)是一个基于深度文档理解的开源引擎。它可以为规模企业提供简化的 RAG(检索增强生成) 工作流程,结合大型语言模型提供真实的对话功能,重点是它能够支持私有化的知识库,弥补大语言模型在特定场景中相关知识的不足,很好的解决了个性化应用的纵深问题。
这篇文档描述的是知识库的构建、管理与应用。管理层面的输入是知识库文档,返回的是文档的管理状态,结合前端页面,用户可以方便的管理自己的知识库。应用层面的输入是用户的会话内容,输出的是相关性文档切片集合,后续工作流可以通过接入到大语言模型生成话术文案,疏通逻辑,实现仿写、渲染等效果。
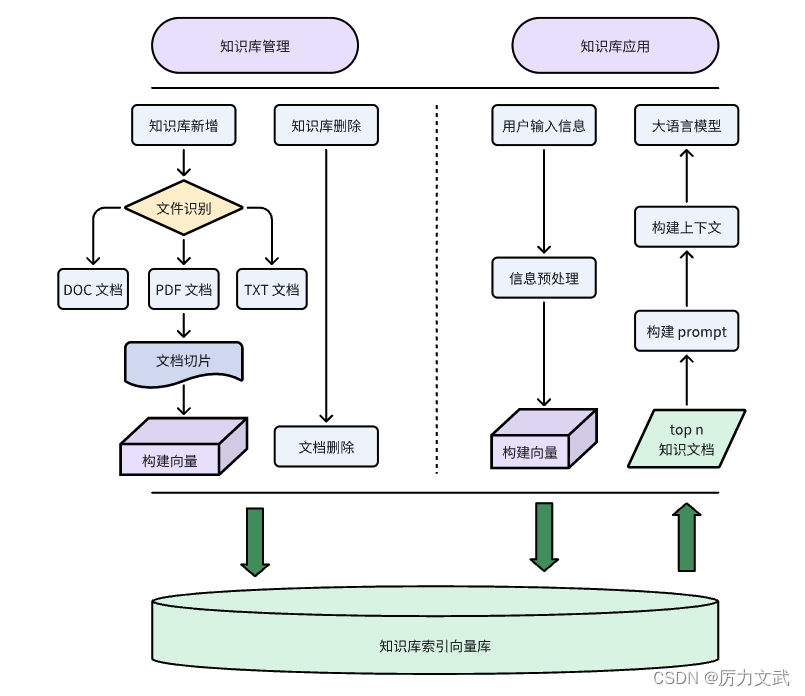
-
新增知识库
-
文件类型:支持 docx、pdf 和 txt 格式文本,语言为中文、英文或中英文混排;
-
文档切片:切片长度可以根据业务特点,长度控制建议在 512 - 1024 之间为宜;
-
构建向量:将文本拆分为单词或基本单元,提取特征,采用算法转化为数值向量。
-
索引存储:文档 ID、文档地址、文档片段及片段向量,以及业务的其他扩展字段;
-
-
删除知识库
-
根据文档 ID 删除向量库中该文档的所有记录,记录包括文档地址、片段和向量;
-
删除操作采用真实删除,因为文档修改会变更分片和向量,使更新操作意义不大;
-
-
检索知识库
-
对用户输入进行预处理,处理过程包括敏感信息提示与过滤,文本的纠错和编排;
-
对预处理后的信息进行构建,构建过程必须与构建时使用的组件与模型保持一致;
-
对向量库检索,根据业务要求返回分片数,相似度阈值区间建议在 0.6 - 0.9 之间;
-
根据文档分片组装 prompt,提交大语言模型服务生成符合用户要求的全新的文档;
-
结合用户的会话历史、背景及上下文信息来进行重新构建和渲染,生成目标内容;
-
向量模型(部分)
| 序号 | 模型 | 维度 | 描述 |
| 1 | BAAI/bge-small-en-v1.5 | 384 |

