
- 1【软件测试】 1+X初级 功能测试试题
- 2【报错笔记】Windows下spacy en_core_web_sm安装解决方式_win spacy
- 3Android 原生项目集成 Flutter_android 原生集成flutter
- 4LLM应用开发与落地:调用自定义函数_llm从自然语言中判断用户的意图是否是要调用这个函数
- 5清华大学推荐人工智能A类B类期刊与会议汇总!!!发论文必备_iclr是a会吗
- 6电子元器件商城与数据手册下载网站汇总_datesheet 下载
- 7在Java中使用Redis_java 访问 redis
- 8【ctf.show-misc赛题】_ctfshow杂项签到
- 9SLAM中的块矩阵与schur补
- 10OpenFeign Could not extract response: no suitable HttpMessageConverter found for response type 问题解决_feign.codec.decodeexception: could not extract res
YoloV4模型训练集傻瓜式操作流程------《深度学习》_yolov4训练教学
赞
踩
目录
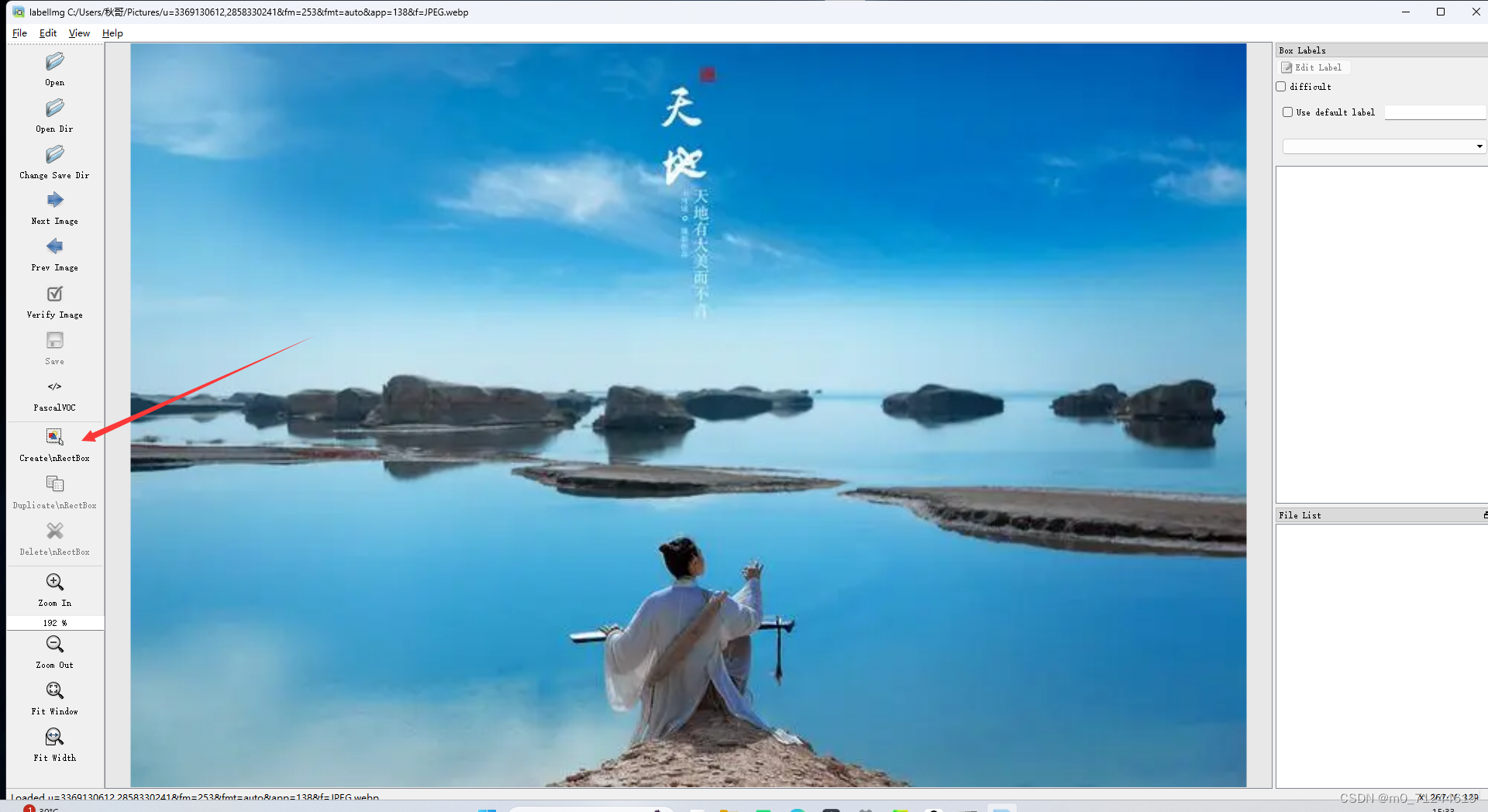
2.3 点击create/nRectBox,然后圈出你想收集的数据集框架。
一.什么是YoloV4
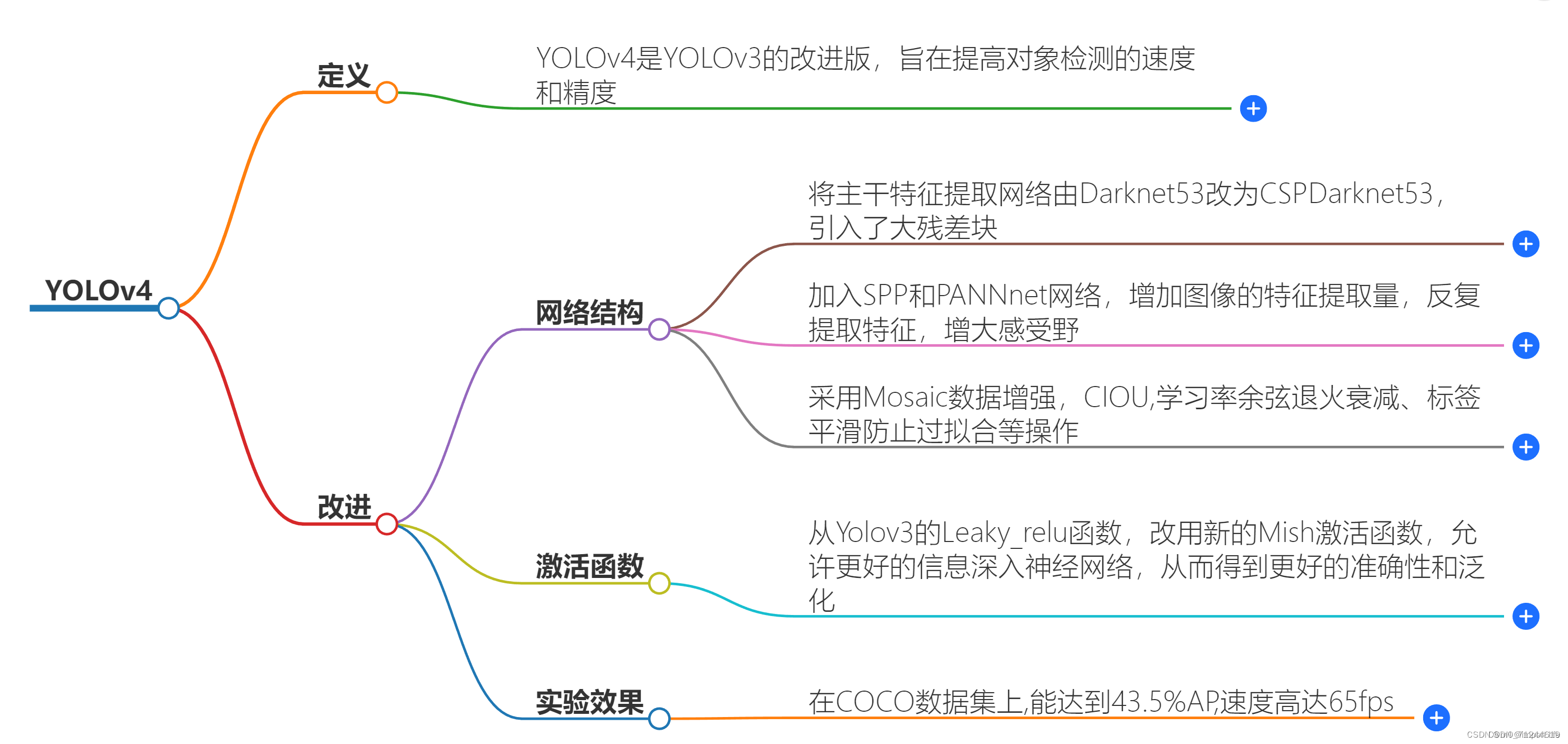 个人对Yolov4的理解不够清晰和深刻,如果片面的来说明会导致读者产生误解,所以理论部分建议大家看一些更权威的论文或者博客,知乎文章等,比如:
个人对Yolov4的理解不够清晰和深刻,如果片面的来说明会导致读者产生误解,所以理论部分建议大家看一些更权威的论文或者博客,知乎文章等,比如:
https://blog.csdn.net/weixin_44791964/article/details/106214657
二.数据准备
在数据准备博主为大家准备了两个方式:
1.参考别人的直接下载(最简单直接),比如:
https://aistudio.baidu.com/datasetdetail/92360
2.使用labellmg来自己创建训练集
labellmg提供:
链接:https://pan.baidu.com/s/1zSedWZiMBjsY5PI53PR_Zg 提取码:jv47
这里以一张图片为例子
2.1 打开labellmg
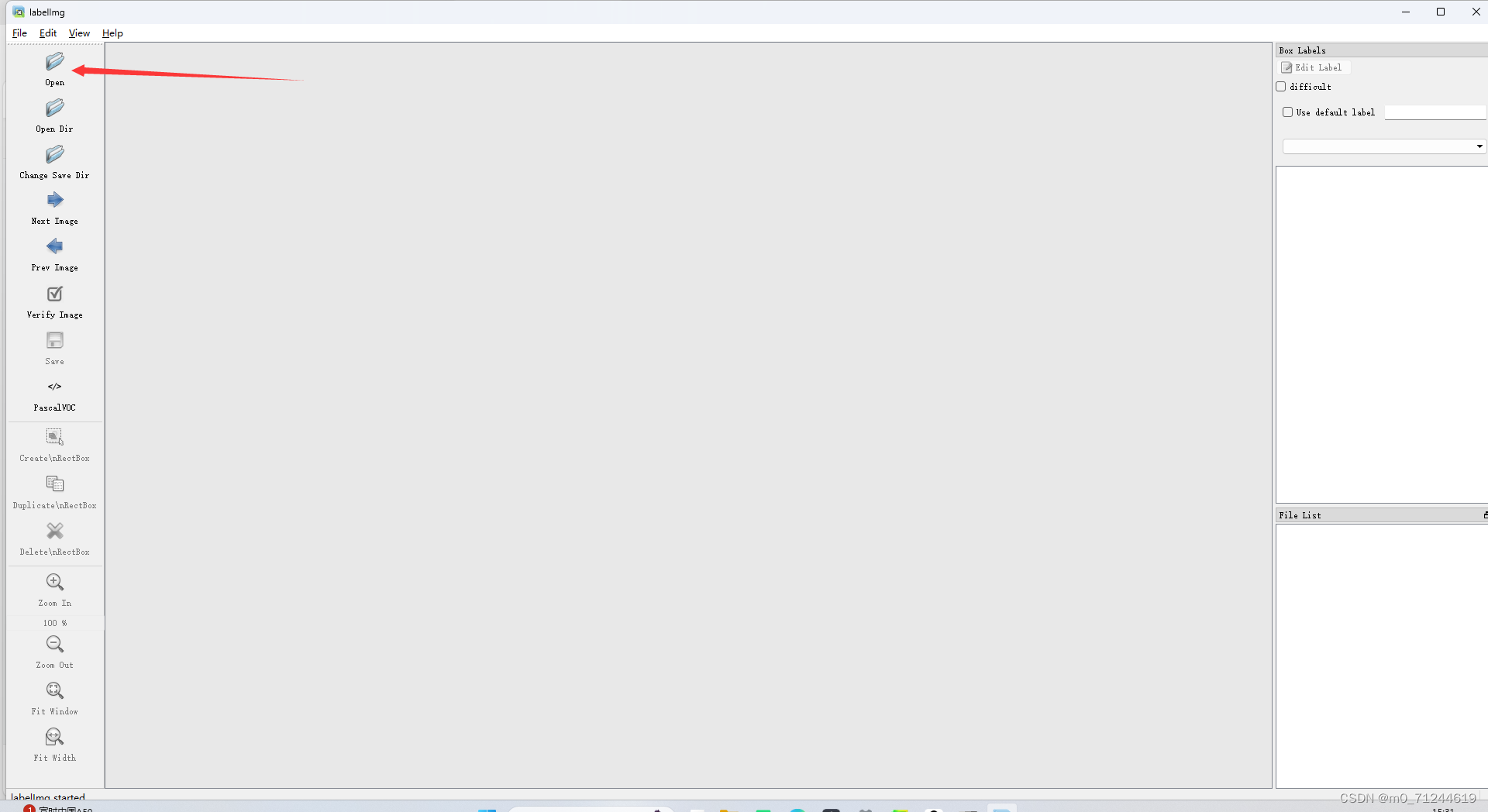
 2.2 打开open,选择你需要照片的路径
2.2 打开open,选择你需要照片的路径
2.3 点击create/nRectBox,然后圈出你想收集的数据集框架。
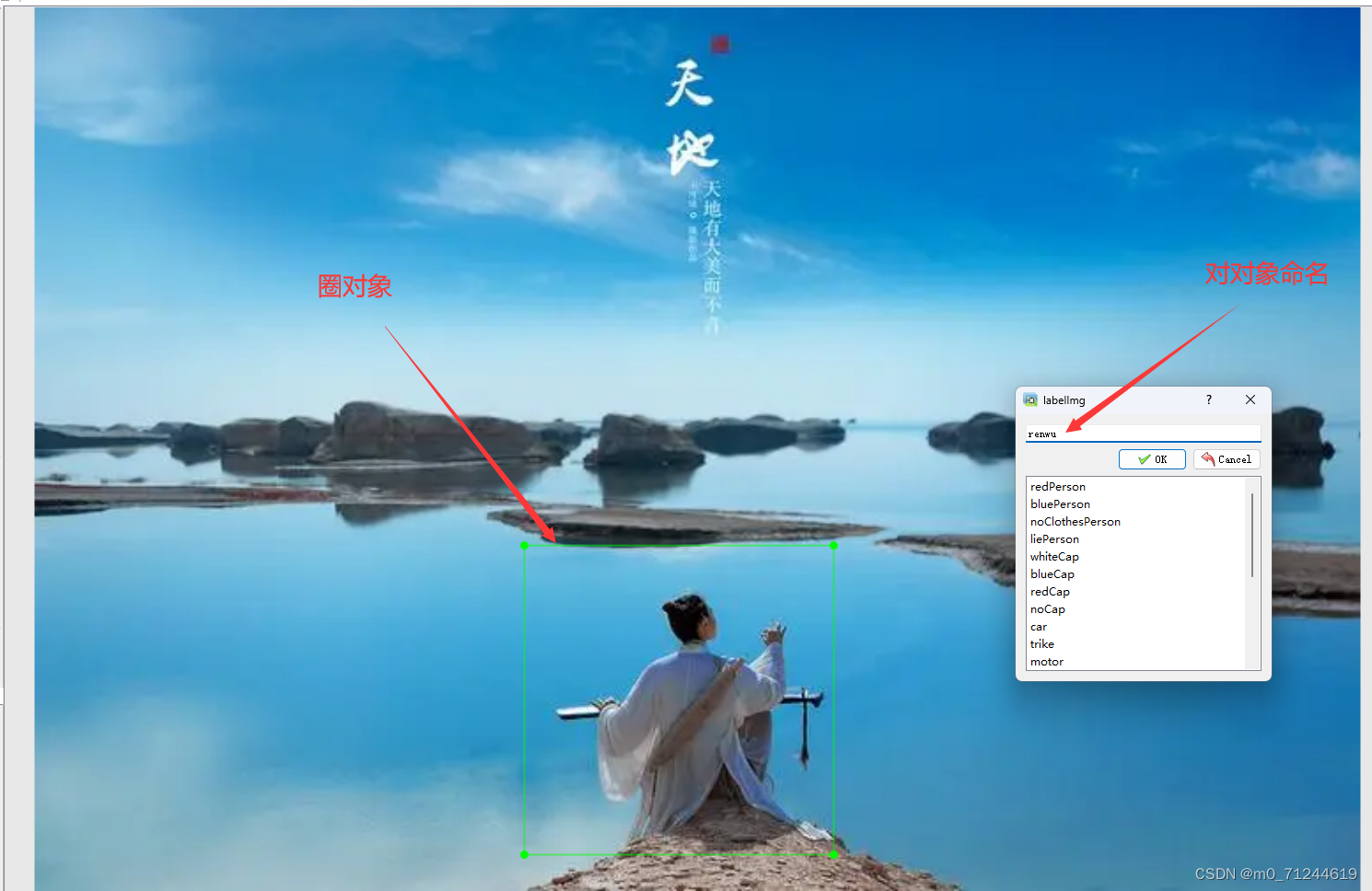
注: 这里需要说明一下对对象命名是为了后续在代码训练的时候统计计数的,最好不要乱起名,同时最好相同类型的对象命名相同的名字。(简单来说这个命名相当于就说组名,然后在后面的代码中会统计这个组里面有多少数目。)
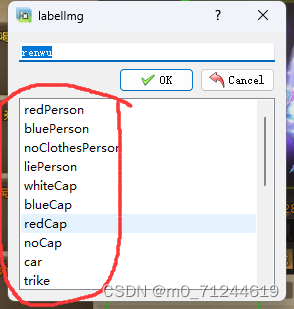
2.4 命名后,一定要记住命名的名字!!!!
命的名如果太多 或者不好记可以在图中标记的文件里的文件里添上,也可以直接把里面的全部删除后添上。这个文件是提供给选项的。可以自己想好组名后写上去在去收集数据。

在这张图上没有想要收集对象的话,就可以保存了,(摁Ctrl+s或者labellmg左侧的Save)
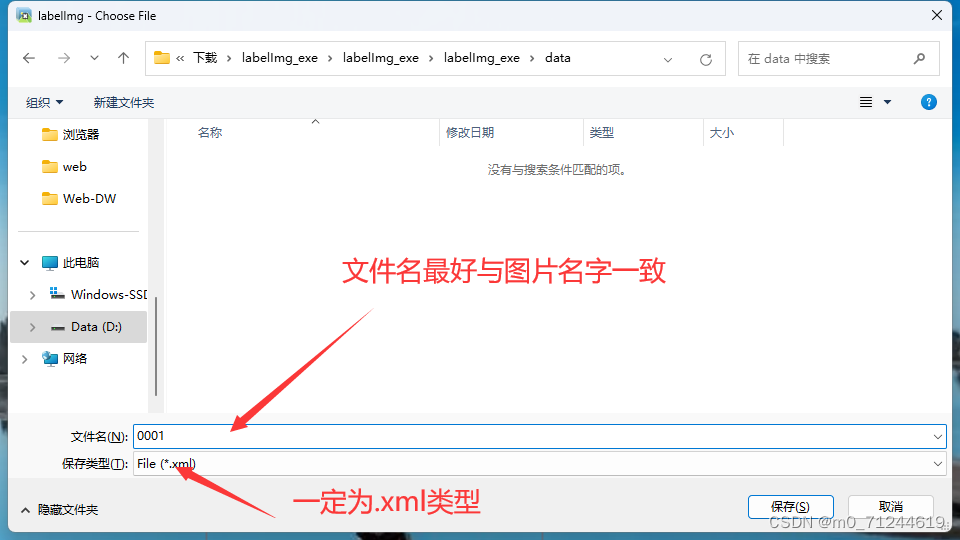
注:
1.文件名字与图片一致是为了保证不乱序,众所周知代码是默认遍历来的,万一存放的时候文件不按先后排序就影响代码的输出结果了。
2. 保存类型为.xml是因为YoloV4读取xml文件。
然后就一直重复上述步骤收集就行,想收集多少就收集多少,不过一般情况下 估计会不少于几百张图片。 最最最最少是100张,一般情况下可能需要500张。
三.运行代码的前期准备
代码提供:
链接:https://pan.baidu.com/s/1zSedWZiMBjsY5PI53PR_Zg 提取码:jv47![]() https://pan.baidu.com/s/1zSedWZiMBjsY5PI53PR_Zg?_at_=1714204932507#list/path=%2F文件里有提供的1001张图片和训练集,可以替换成自己的训练集:
https://pan.baidu.com/s/1zSedWZiMBjsY5PI53PR_Zg?_at_=1714204932507#list/path=%2F文件里有提供的1001张图片和训练集,可以替换成自己的训练集:
3.1 准备的图片导入
打开 yolov4-pytorch-master文件夹后找到VOCdevkit文件
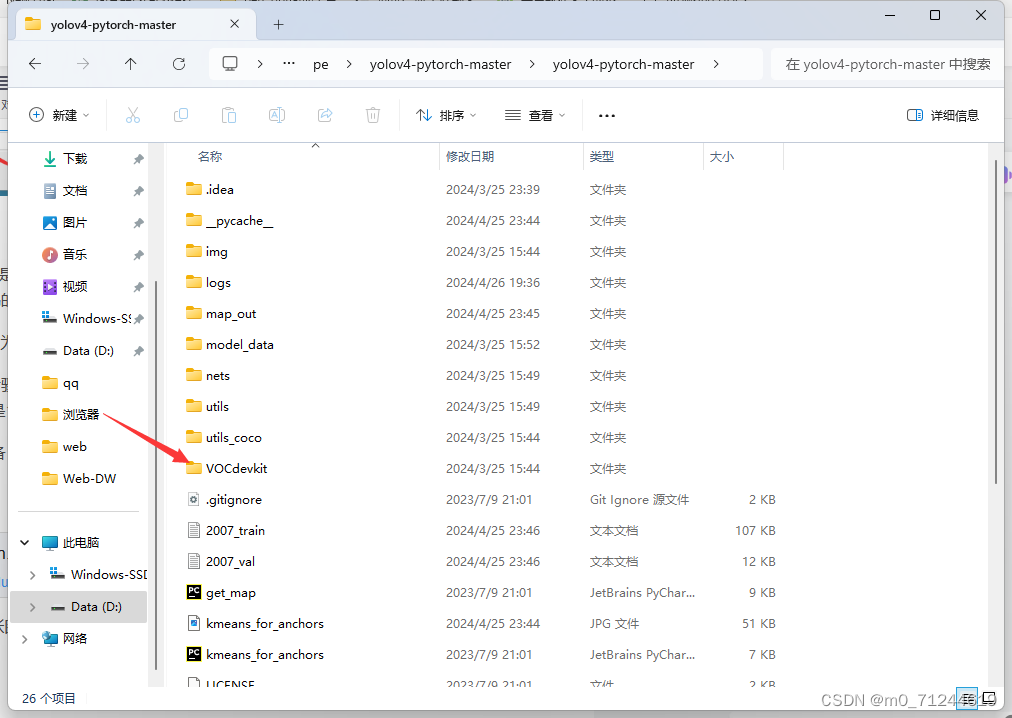
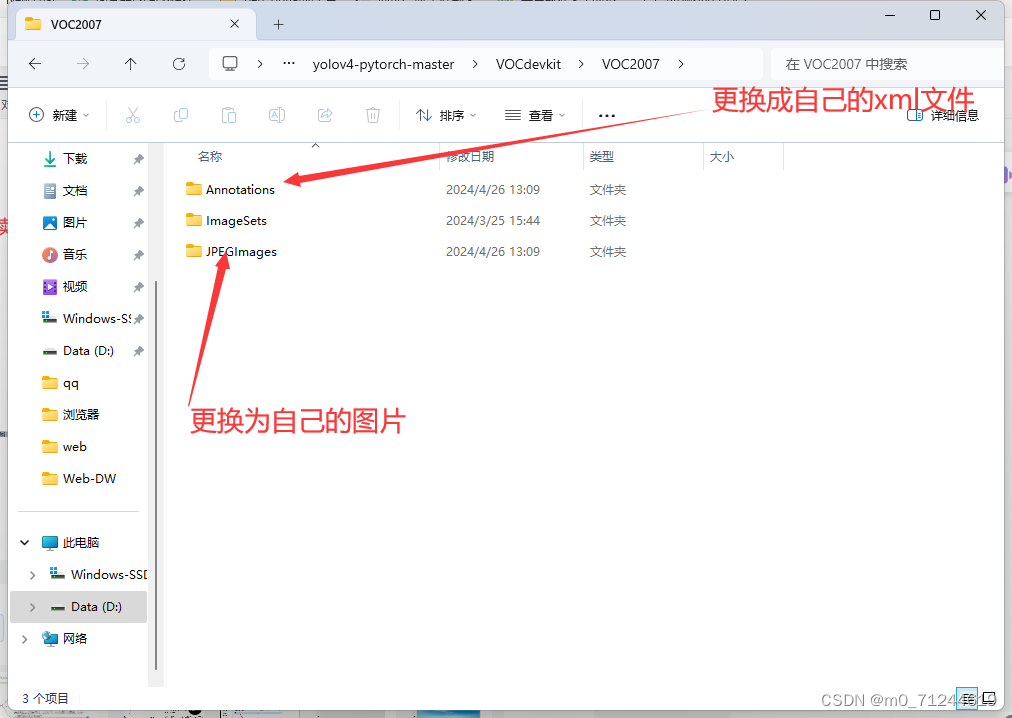
注:这两个文件夹的名字最好不要更改, 图片类型为jpg格式。
3.2 python外库环境准备
- Package Version
- ----------------------- ------------
- absl-py 2.1.0
- bigtree 0.17.0
- chardet 5.2.0
- colorama 0.4.6
- contourpy 1.2.1
- cycler 0.12.1
- filelock 3.13.4
- fonttools 4.51.0
- fsspec 2024.3.1
- graphviz 0.20.3
- grpcio 1.62.1
- h5py 3.11.0
- importlib_metadata 7.1.0
- importlib_resources 6.4.0
- install 1.3.5
- Jinja2 3.1.3
- kiwisolver 1.4.5
- Markdown 3.6
- MarkupSafe 2.1.5
- matplotlib 3.8.4
- mpmath 1.3.0
- networkx 3.2.1
- numpy 1.26.4
- opencv-python 4.9.0.80
- packaging 24.0
- Pillow 9.5.0
- pip 23.3.1
- protobuf 5.26.1
- pydot 2.0.0
- pyparsing 3.1.2
- python-dateutil 2.9.0.post0
- scipy 1.13.0
- setuptools 68.2.2
- six 1.16.0
- sympy 1.12
- tensorboard 2.16.2
- tensorboard-data-server 0.7.2
- torch 2.2.1+cu121
- torchaudio 2.2.1+cu121
- torchvision 0.17.1+cu121
- tqdm 4.66.2
- typing_extensions 4.11.0
- Werkzeug 3.0.2
- wheel 0.41.2
- zipp 3.18.1

个人不太建议上述这样下载,太麻烦了,更建议先运行查看缺少哪些库。比如:
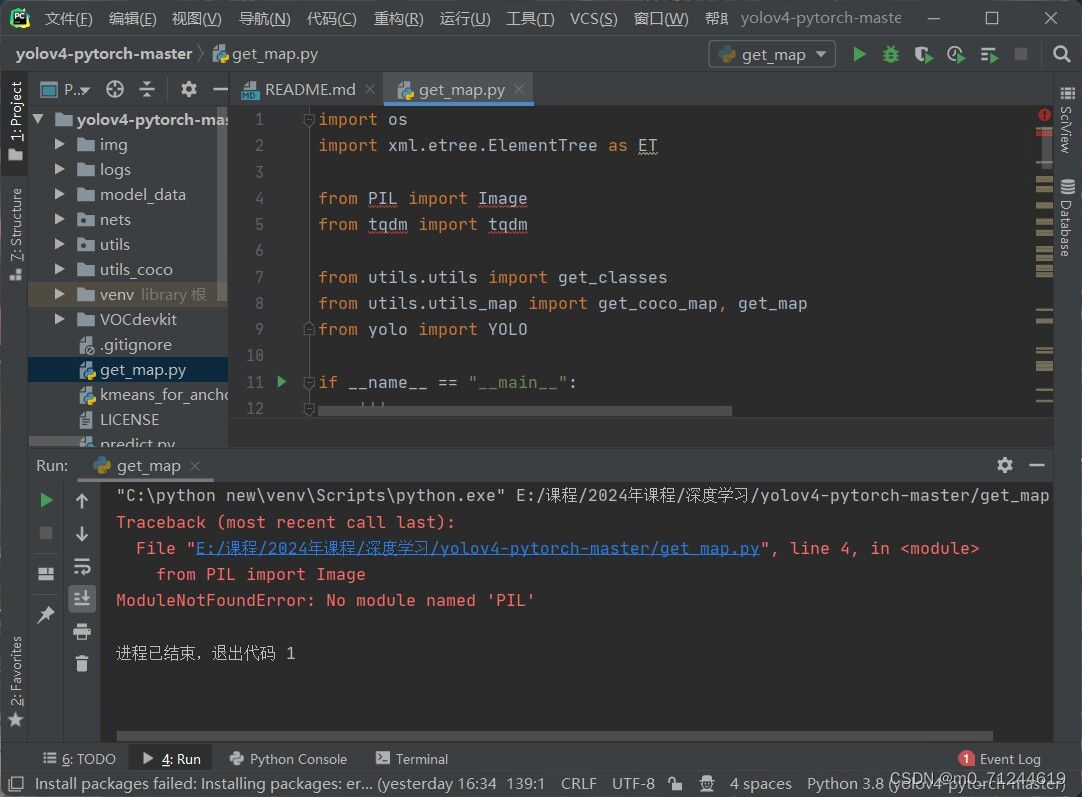
图片中显示PIL 和tqdm 两个库没有 我们可以直接运用pip下载,特别提醒一下 可以用一下pip镜像源。
pip镜像源大全
中国大陆用户推荐使用阿里云,腾讯云,清华大学,中国科技大学等镜像源,速度较快。
使用方法:
PILpip install -i https://pypi.tuna.tsinghua.edu.cn/simple
3.3 命名(组名 2.3所说的)更换
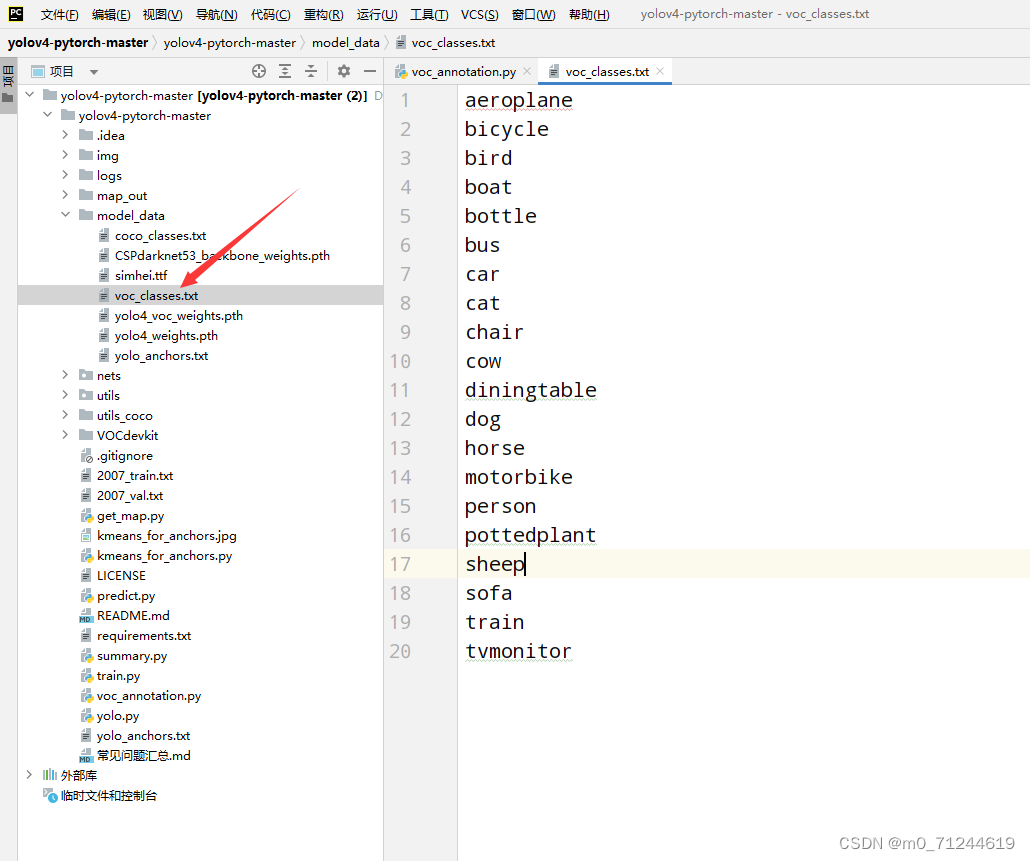
在yolov4的文件下的model_data文件下的voc_classes.txt文件里替换掉自己数据集命的名。
如果有人忘记了怎么办,两个方法:
1.打开自己的.xml文件,可以看到源码就行
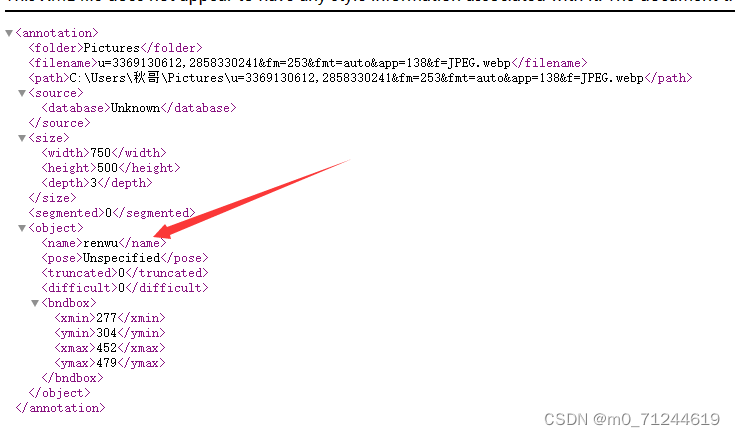
图上标的就是自己命的名
2.打开labellmg中data中的自己记得有命名的文件
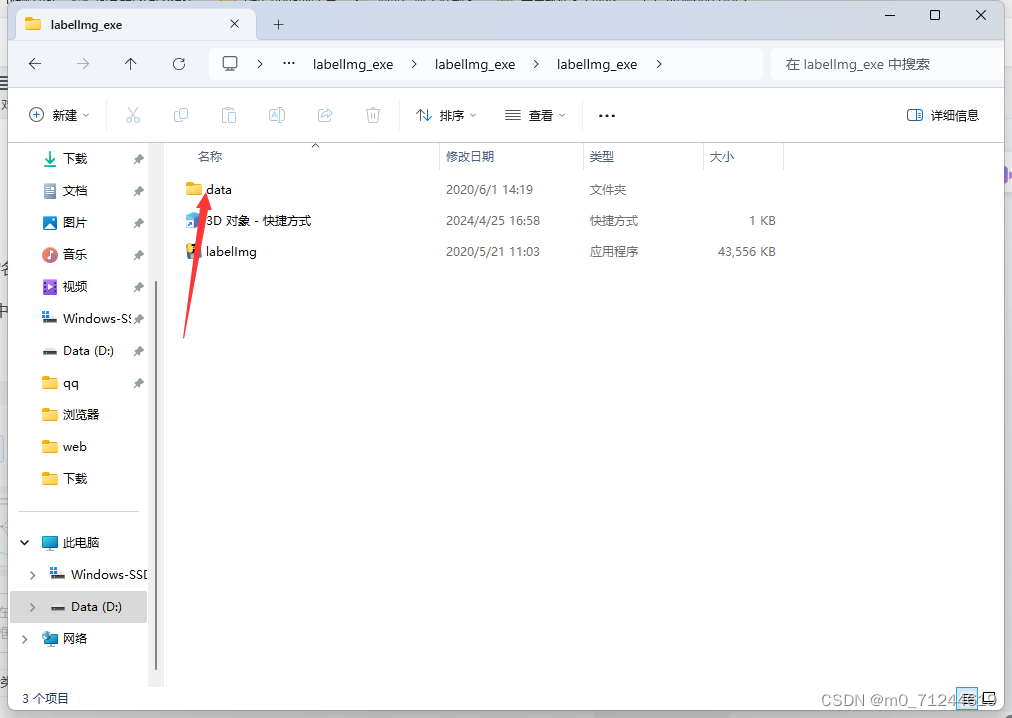
如果在前面收集的时候记得有的话直接copy(复制)过去就行。
四.运行代码
优先运行voc_annotation.py代码,这个代码一定要能运行,他是创建你收集图片和xml的数据集(2007_train.txt和2007_val.txt),后续的代码都是以这个数据集为载体的。
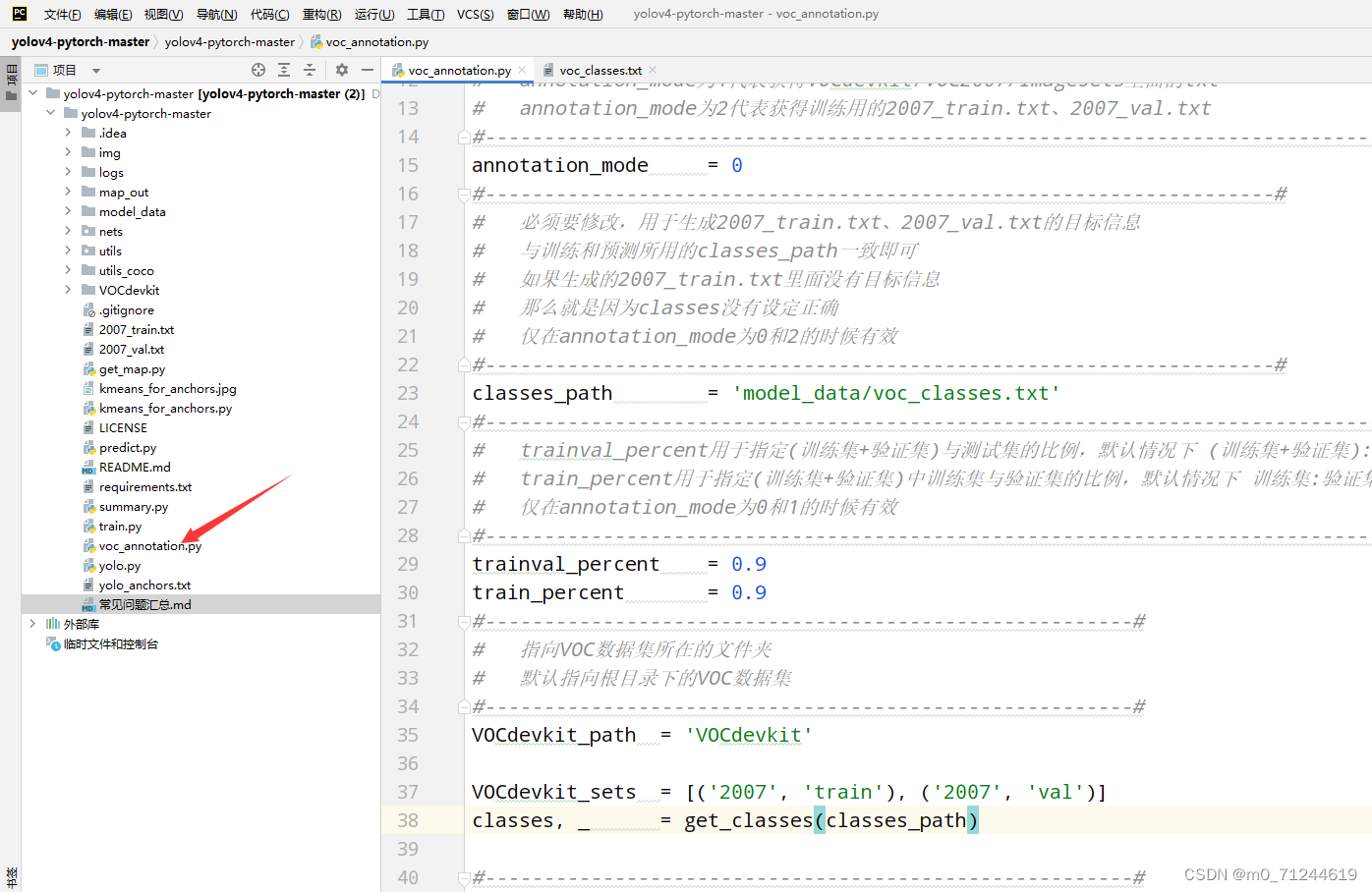
然后运行train.py文件的代码
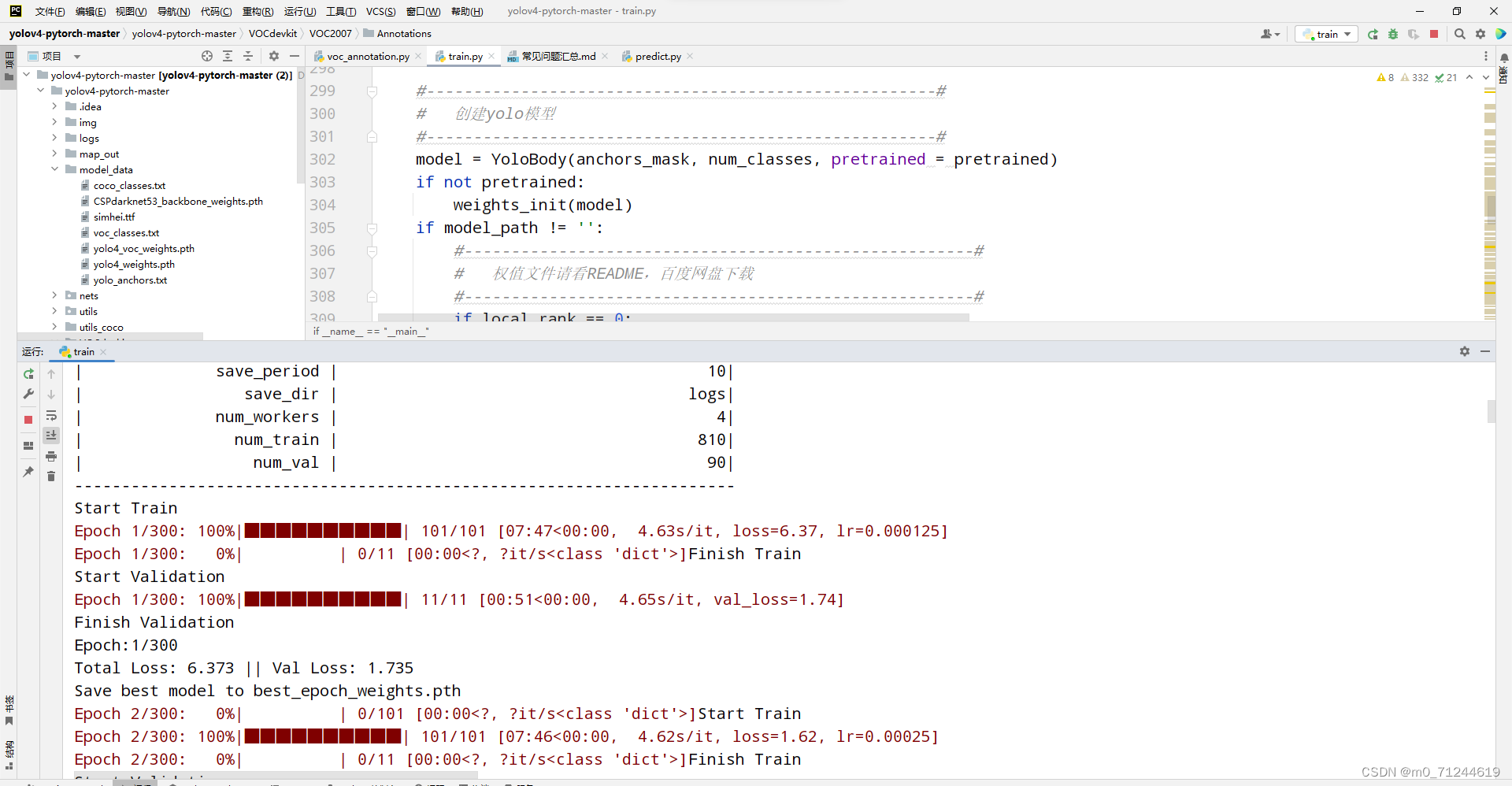
接下来慢慢等他300个列车运行完成即可,这个过程有点慢。可以耐心等待。过程中可以看到每个列车的丢失。
到这里yovol4的训练过程就大致是这样的。期间还有一个predict.py文件,对于此文件的解释:
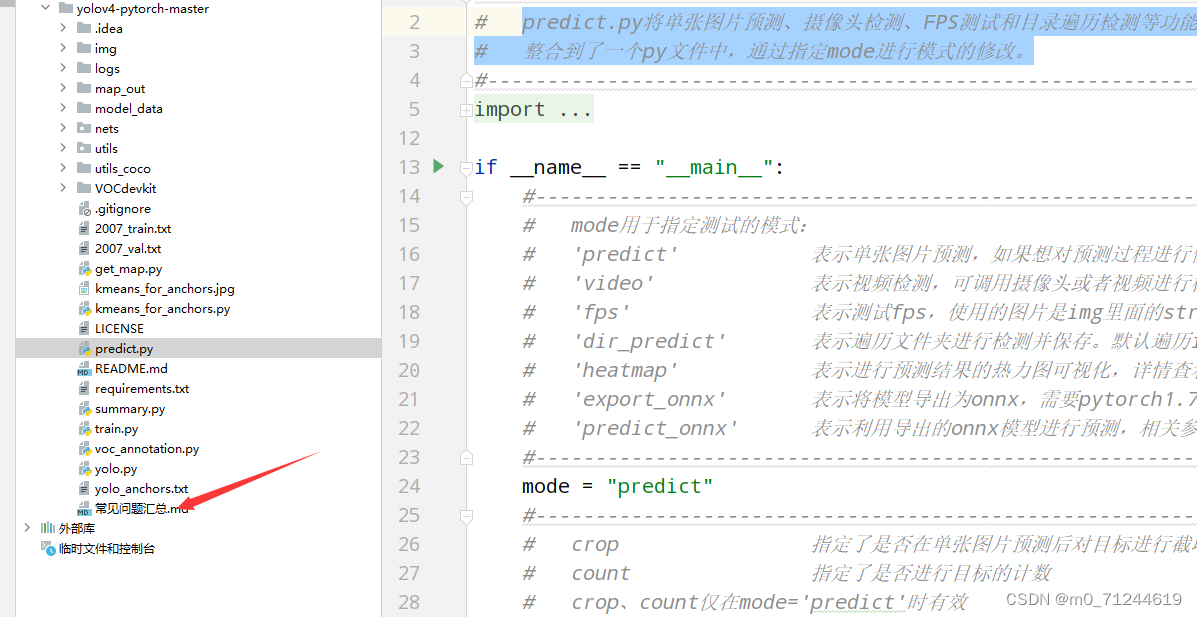
predict.py将单张图片预测、摄像头检测、FPS测试和目录遍历检测等功能整合到了一个py文件中,通过指定mode进行模式的修改。
如果在过程中遇到了问题,详情可以查看 常见问题汇总.md文件
博客连接为:
https://blog.csdn.net/weixin_44791964/article/details/107517428
这位博主写的很详细,如果在对yolov4的理解比较深 推荐去观看。
谢谢!

