
- 1外包公司值不值得去?_现在外包值得做吗
- 2【已解决】ModuleNotFoundError: No module named ‘torch._six‘_modulenotfounderror: no module named 'torch
- 3大数据工程师简历_成为大数据工程师所需的技能
- 4半球展开图_棱锥的展开图.ppt
- 5ECMAScript 与 JavaScript的联系 以及为什么会有浏览器兼容的问题?_ecmascript 兼容性
- 6推荐项目:CLIP-ONNX - 加速CLIP推理速度的神器!
- 7MyBatis——MyBatis实现多表查询_mybatis多表查询
- 8老徐WEB:最简单详细的轮播图原理和制作过程(一)_最简单的网页轮播图
- 9LoRA中值得注意的微调细节_lora微调
- 10Python 实战之淘宝手机销售分析(数据清洗、可视化、数据建模、文本分析)_数据可视化手机价位图的代码
AI 内容分享(四十):如何用AI搞定实战项目_mj生图
赞
踩
目录
前言
2023年,被称为ai设计元年,aigc在c端的蓬勃发展和大规模应用,让更多人体验到了ai的巨大潜力,其强大的创作力为设计师们提供更多精彩创意的同时也为行业带来了重大的机遇和变革。
其中midjourney通过其简单易上手的操作,和丰富极具视觉冲击力的画面给行业内带来了巨大的震撼,在生成插图的效率,光影,氛围上具有很大的优势和可能性!
但是与此同时,midjourney(后称MJ)在应用中也有着难以绕开的弱势和缺陷,也就是生成图片的精度很难控制,随机性很高,需要大量的跑图合成,而这需要消耗设计师大量的时间和精力,在这一方面,另一款ai软件stable diffusion(后称SD)无疑在生成图片的控制性这方面会表现的更加出色。
本文基于VDC设计团队项目实际应用的案例,带你了解更多关于MJ和SD的应用方法,让他们成为你设计路上披荆斩棘的利器。

本次案例是中秋活动主视觉设计,考虑融合传统节日元素和不同赛道的属性特色,吸引用户参与活动。下面我会以这个需求进行设计延展,全程AI辅助设计,各位看官请坐好,准备发车了!
创意构想
1-1 ChatGPT构思框架
在不确定设计方案的情况下,可以利用A大语言模型来帮助我们更好的理解需求,这里我得到了中秋节的部分设计元素,以及具体需求背景下,给出的一些方案建议。结合中秋节和视频、直播、音乐主题的活动视觉设计,可以考虑融合传统节日元素增加吸引力。

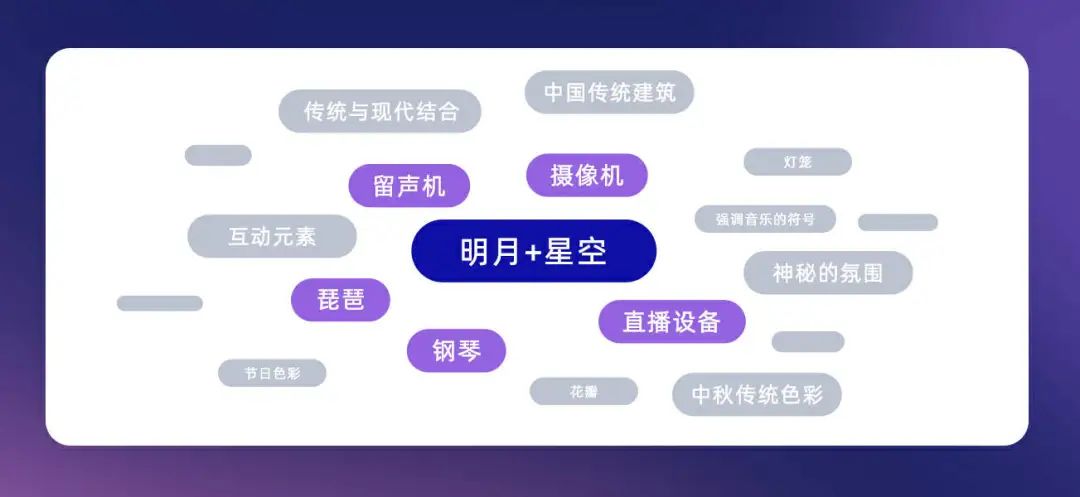
1-2 拆解主体元素 & 总结设计关键词
基于这些元素,总结出一系列MJ关键词,指导后续的视觉设计。
主体视觉输出
2-1 MJ生图 多方案探索
我们先梳理一下三种常用的MJ生图方式:

关键词直出:图片效果完全由关键词主导,且图片中的大部分元素为国外设计风格,出图可控性差。
垫图+关键词:相对可控制图片效果,通过控制--iw参数调整垫图权重(参数越大,最终效果与垫图越相似,-般用--iw 2)
图生图:通过多张图片融合,MJ自动生成图,图片效果与喂图有关(需要多张风格相似的图片才能保证最终出图效果稳定)
基于上面这3种出图方法,我们基本可以排除“关键词直出”这个方法,因为我们的主题是属于国内的中秋传统节日,“垫图+关键词”和“图生图’这两种方法是首选,我们只需要找图喂图即可,而且还能控制出图风格。
2-2 确定主体 / 多图拼合 / 手动优化
-
核心元素选择:从多个方案中挑选最能代表主题的核心视觉元素。以-直播-入口为例:结合MJ的AI能力和预备的垫图,生成多个设计草案。
-
垫图+关键词


方案对比与选择:对比不同草案,根据设计目标和美学标准选择最合适的方案。选择效果还不错的一个继续跑图,如有必要需要我们多刷几次,然后垫图套娃,每次生成的图片细节还是不太一样,如果“抽卡”的时间过长,失去了耐心,那也不用纠结,时间太长就失去了我们使用Al的意义,直接选出自己最心仪的,后续到ps里进行合成就好。
同理生成整体环境,可以一次性多生成一些,用同样的关键词,确保生成的风格统一。其它入口也会用到。

细节调整:进行元素拼合和手动优化,以提升整体视觉效果。
2-3 其他主体同上
风格一致性:对主视觉的其他视觉元素重复以上步骤,以确保整体设计的统一。

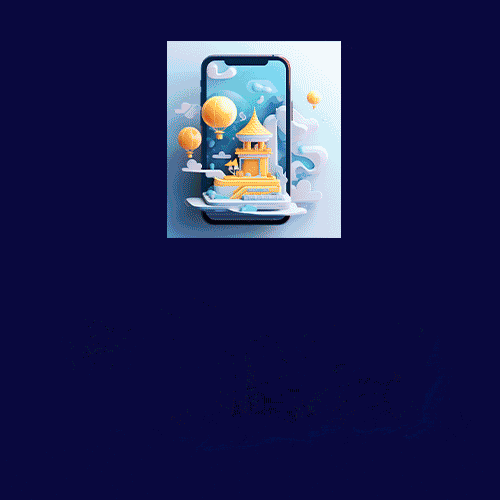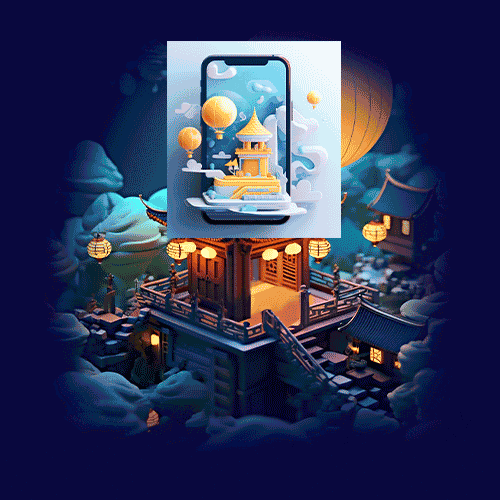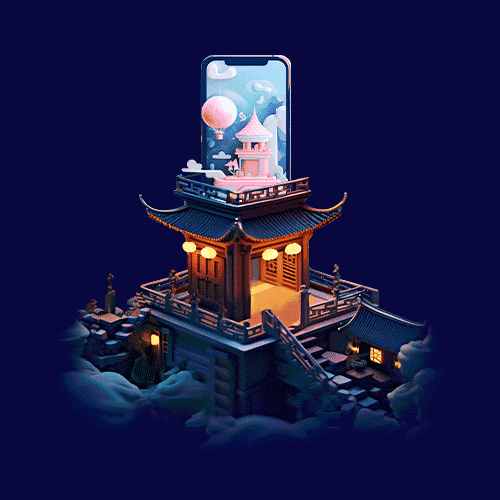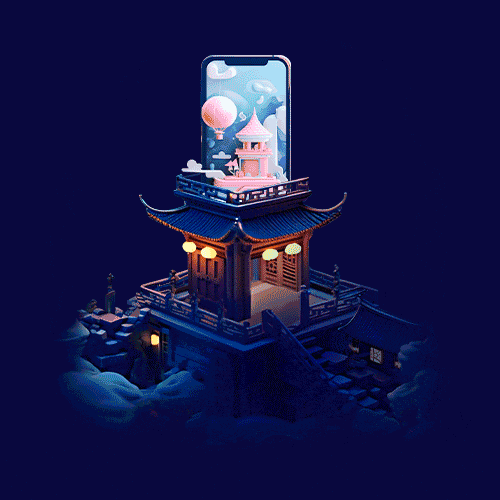
最终视觉呈现
最后将其他主体入口进行合并细化,调整空间层次并深入刻画氛围,质感以及细节等,即可完成中秋活动主视觉+主会场的设计。

日常活动模版案例

通过对相应标题关键词输入,生成书籍,建筑,等部分结构元素,但风格并不尽如人意,还需要搭配合适的风格关键词的输入以及想要的风格图片的垫图,当然最后还需合成,调色以及细节调整等,得到最终的效果(上图)
类似写实风格的图更要注意关键词的使用,并且要注意生成人像是否存在结构问题,尤其是在五官和肢体上,MJ很容易渲染出错。
常用3D效果的关键词以及关键词文档的整理


日常banner应用效果展示

不得不说MJ在这种小banner的应用上起到了非常明显的作用,得益于尺寸的优势,通过构图和裁剪的方式也能达到规避有问题的细节,整体对效率的提升非常显著。

MJ是使用中优势很明显,上手快,细节丰富极具视觉冲击力,出图相对较快,对于不要求细节的快速出图和脑爆等有着先天的优势,但是也存在相应的问题,如结果不可控,局部失真,细节过于繁琐等等,需要翻墙,费用较贵等等。SD则在这些方面有更好的优势:本地部署,无需梯子,设计产出相对可控等,但也有劣势所在:上手难度较大,对电脑配置要求很高,效果依赖于选择的模型和lora等。

下面我将对界面,使用和案例展示对stable diffusion做一个简单的介绍以帮助更多的同学去了解这款功能强大的ai软件,内容很干,谨慎食用。
Stable diffusion必须了解的几个概念
1.Checkpoint:用来训练的非常多的图片合集,称之为大模型,往往决定画面的风格

2.Lora:可以简单理解为调整图片细节的微调模型,往往在生成结果上能起到决定性作用,所以现阶段很多大厂在部署工作流会训练很多的lora模型,例如ip训练,场景训练,人物训练等等,一般lora单个使用也可以多个同时使用,共同作用于图片。

SD常用拓展插件:帮助你更好的去使用和控制sd生成高质量的图片,在提升你的工作效率上会有比较大的帮助,下面会列出一些使用频率比较高的插件。

sd的界面介绍:
看似参数很多,但是往往只需要注意几个主要参数即可:
正向关键词:描述页面的主要内容,反向关键词控制画面不要出错,正向关键词和反向关键词都是有套路的,有兴趣的可以公众号留言,发送一些常用的关键词合集
采样方法:相当于选择生成画面的滤镜,
采样迭代步数:不要太高,一般在20-30之间,
高清修复:把基础生成的图片选择合适的倍率放大分辨率重新绘制,高清修复后的图片往往细节更加丰富,但尺寸一般不要超过1500x1500,尺寸过大容易爆显存
提示词相关性:图像与提示词之间的匹配程度
Seed:跟midjourney功能一样不再赘述
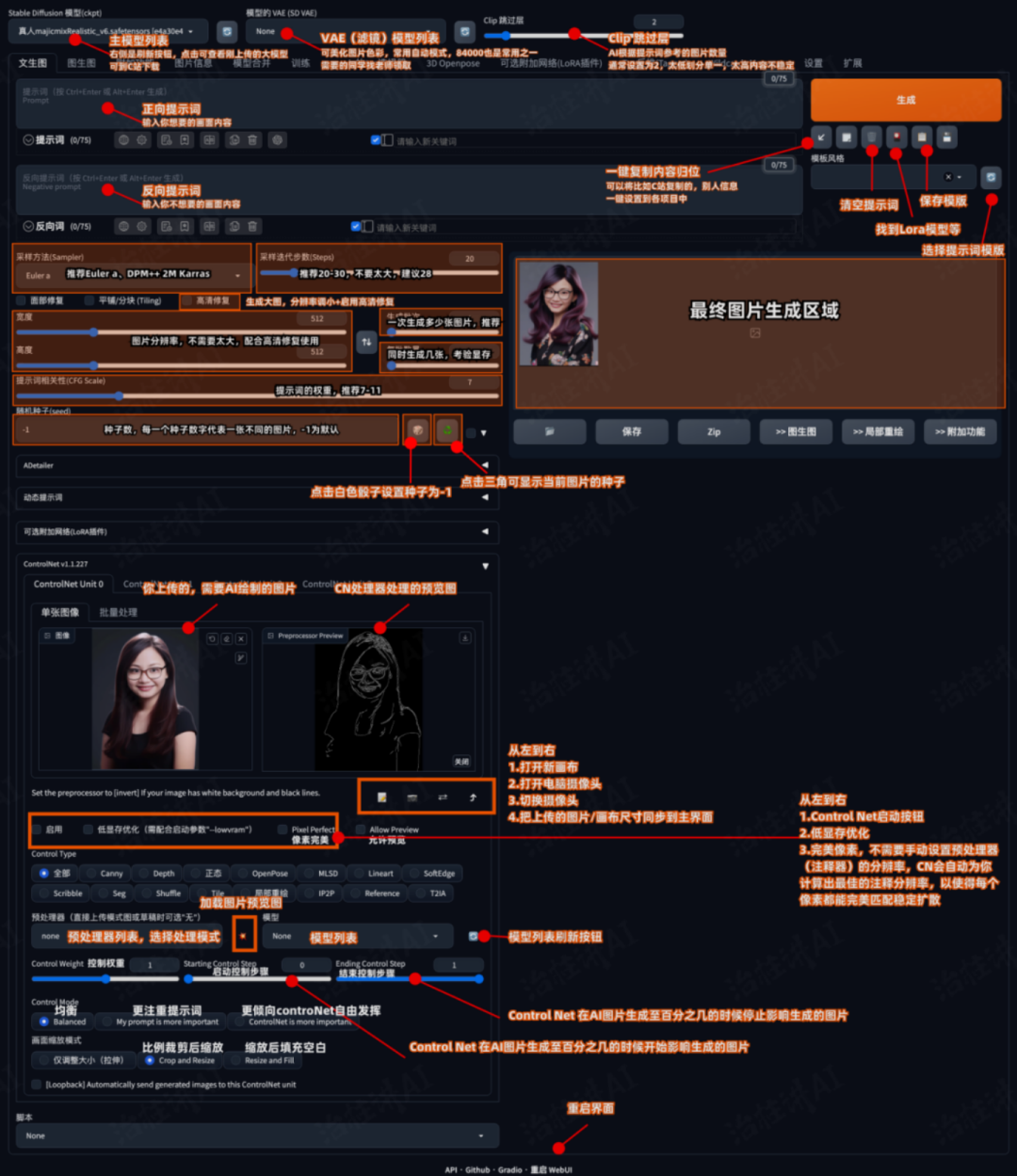
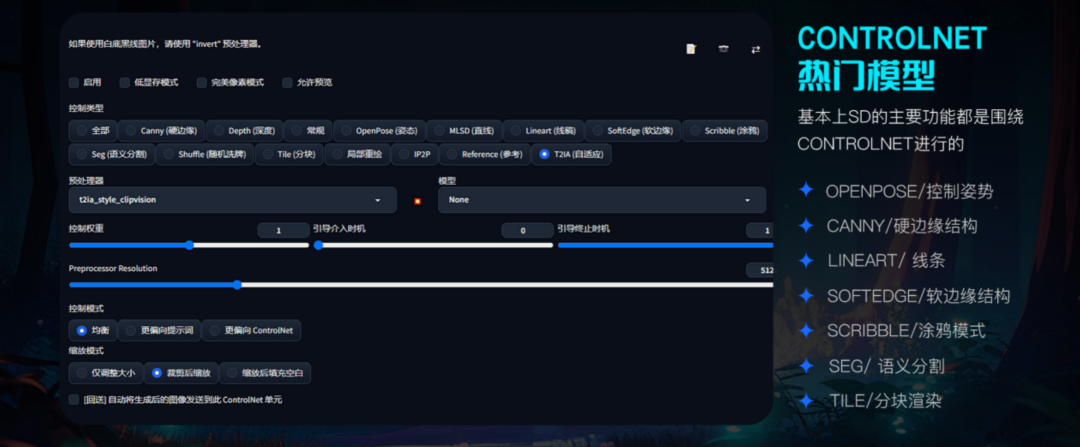
Controlnet:是用来控制ai生成图像的插件,也是mj跟sd最大的功能区分之一。在controlnet出现之后,我们就能通过模型精准的控制图像生成,比如:上传线稿让ai帮助我们填色渲染,控制角色的姿态动作等等
Stable Diffusion 的实践落地
基本概念介绍完后
下面通过几个案例介绍一下sd究竟能在工作中帮助我们完成什么?
01/企业ip的3d立体化
用一个项目带你了解如何将ip从二维平面转化为3d立体的全流程:
•选择anything模型,导入一张ip的设计草稿,并在提示词框中写下提示词prompt
Positive prompt:(masterpiece:1,2), best quality, masterpiece, highres, original, perfect lighting,(extremely detailed CG:1.2), drawing, paintbrush,
Full body, Cute,Solo, no human, simple background, big eyes, standing, looking at the viewer, cartoon,belly, dripping top, chin, blacklines,monochrome,white background,(simple background:1.2) <lora:animeoutlineV4_16:1>
Negative prompt: NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
•选择seekyou模型,并在正向提示词框中更新提示词颜色信息,重新生成
Positive prompt:(masterpiece:1,2), best quality, (extremely detailed CG:1.2), drawing, paintbrush,High purity,High saturation,FULL BODY, CHIBI,Cute,Solo, no human, simple background, brown eyes, standing, looking at the viewer, cartoon, pink body, white belly, red dripping top, white chin, (white background:1.5),(simple background:1.2)
•选择disney模型和blindboxlora,将色稿转为3d画面
Positive prompt:((best quality)), ((masterpiece)), ( extreme detailed, highest detailed, official art, beautiful and aesthetic:1.2), depth, composition, Solo, no one, simple background, full body, brown eyes, standing, looking at the viewer, cartoon, pink skin, white belly, dripping top, white chin, clay material, <lora:blindbox_v1_mix:0.8> <lora:shinkai_makoto_offset:1>

•与mj不同,sd可以选择更多不同风格的大模型,并通过更改描述词prompt和选择不同类型的lora可以在保留ip原有特征的基础上,进行一键换肤,产生更多全新的ip形象

02/如何通过stable diffusion生成头像挂件
首先,我们利用市面上现有的头饰lora,探索sd使用单一lora生成挂件的效果,打开【文生图】功能,首先选择合适的模型,我这里选择了gameiconinstitute作为基底模型,然后导入头像挂件的正向和反向提示词模版,更改头像挂件的具体描述内容,调整好采样步数和采样器,就生成了一些对应的效果图,如下图左边所示:
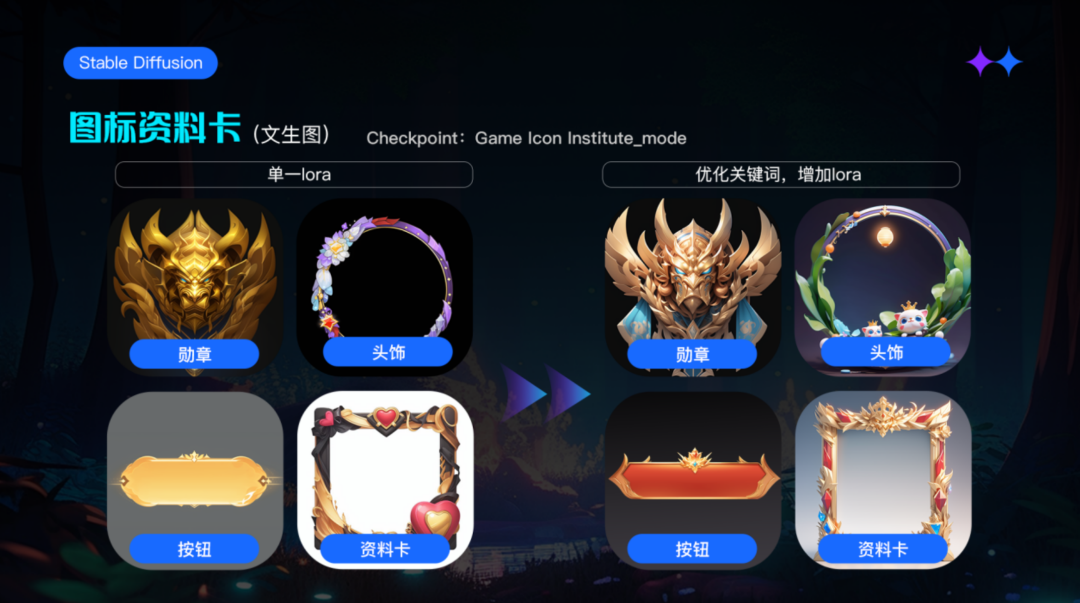
单一lora生成的结果,并不理想,细节错误较多,风格较为扁平,缺少层次,视觉效果一般,风格较为老套等等,没有办法直接进行使用。为了提升生成的效果我们优化了正向提示词,同时采用多个辅助效果的lora进行配合,共同作用于头像进行二次尝试,得到了如上图右边效果:可以看出画面的整体的立体性,光影质感也更强了,给人的感觉更加的完整,高级。
那为了使sd能更好的理解我们的需求,生成更便于我们使用的头像挂件风格,这里也可以引入midjourney进行配合使用,来得到更好的效果。
•首先,我们在mj中垫入几张风格合适的参考图,撰写相应的关键词prompt:
/inmage:game avatar frame with round metal frame,jewel wings, translucent material, purple background, light purple and pink wings,Transparent, golden,shiny,diamond oranment,bright,digitally illustrated,impasto original,4k,super detailed --s 250 --niji 5

•根据以上图的垫图,生成的一些图像如下,可以看出一些图片的局部还是比较精美的,但是整体的风格相对过于扁平,同时头像的结构性错误较多,难以直接进行使用,这也是midjourney最大的问题之一,结果不可控,往往需要多次抽卡才能得到一张可以使用的画面素材。

•摘取各生成图中的其中一些局部元素,放入ps中手动合成出一个你想要的头像挂件,细节可以暂时不用过于考究,只需要把形状拼好就行,如下图,可以看出画面的效果还是相对有些扁平了,显得层次不是很突出

•为了得到更好的画面效果,我们可以将拼好头像挂件,导入到sd的图生图中,重新进行渲染,只需要更改描述词的细节信息,就可以得到一张质感更强,效果更立体,细节更丰富,结构更合理的3d精美头饰,再利用remove网站一键抠图,导入到ps中优化局部细节,就可以得出一个令人满意的静态头像挂件

03/通过ai软件部署工作流完成相应的设计活动
与上文生成勋章挂件相似:因为用mj直接生成匹配度高的图片比较困难,我们可以采取另外一种思路,让mj生成单个元素,然后再在ps中进行后期优化和合成,这种方法具有比较好的可控性,我们需要MJ垫图生成元素——ps拼画面——sd优化光影细节,后期也能做到修改画面的效果
例如:下面我们通过中秋活动的家族房主视觉进行实际的项目演示
1.利用chatgpt进行设计目标拆解
1.首先本次活动的主题:中秋节—的家族房赛道的主视觉设计,需要在画面中体现家族房,音乐的相关元素,同时赋予画面一种中秋团圆的氛围感
2.我们可以利用chapgpt进行创意脑爆,分析后将设计目标进行拆解,具象成具体画面中的元素和风格调性

3.然后将这些关键词进行汇总,形成关键词示意图,得出我们最终的设计方向

2.使用midjonrny生成画面中需要的元素
1.找相应风格的参考图倒入mj中生成相应的设计元素如下图

2.将一些合适的设计元素导入到ps中,微调细节和风格参数,因为需要跟聚合页的设计风格进行一个较大的区分,所以将左图中的偏红色效果的设计稿,直接整体改颜色,结果如下图

3.将拼合稿倒入到sd中通过ai优化光影细节
倒入到sd中的图生图模式,选择redanimated大模型,在正向提示词框中输入画面的颜色和元素信息,选择图生图模式,打开controlnet中的canny模式和tile模式,迭代步数选25,采样方法选择:euler a,提示词引导系数选择7,重绘幅度选择0.65,多生成几次,生成效果如右图,可以看出画面的光影效果已经很不错了,基本能达到我们正常输出画质要求。接下来再在PS中合成需要的页面即可。

部分ai设计项目(含局部)


在AIGC时代,AI设计辅助工具的强大功能,专业模型的训练有效的降低了生产难度。这改变了设计的生产模式,不仅在设计初期的创意探索,而且在设计实施过程中都是设计师的得力助手。
但不可否认的是,目前的AIGC工具仍然存在着许多问题,如midjourney无法完美控制画面生成的结果,stablediffusion总是容易出现形体结构错误等,真正的完美落地仍然需要专业设计师的大量介入与修复,虽然AI能为我们提供非常惊艳的作品,但真正出色的设计离不开设计师的创意和想法。AI提供的图片只是工具,设计师们需要将其巧妙结合,实现项目落地,这将更加考验设计师们的专业技能。AI虽然是强大的工具,但最终还需要设计师的审美、创意和设计执行能力。
希望本篇文章,能为大家在完成项目需求中提供一些启发,共同努力进步!通过AI在设计工作中的应用与设计师专业能力的结合,我们可以发现更多创意与设计的可能性。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

