
Hadoop伪分布式集群安装_安装hadoop伪集群
赞
踩
1、下载好VMware安装虚拟机
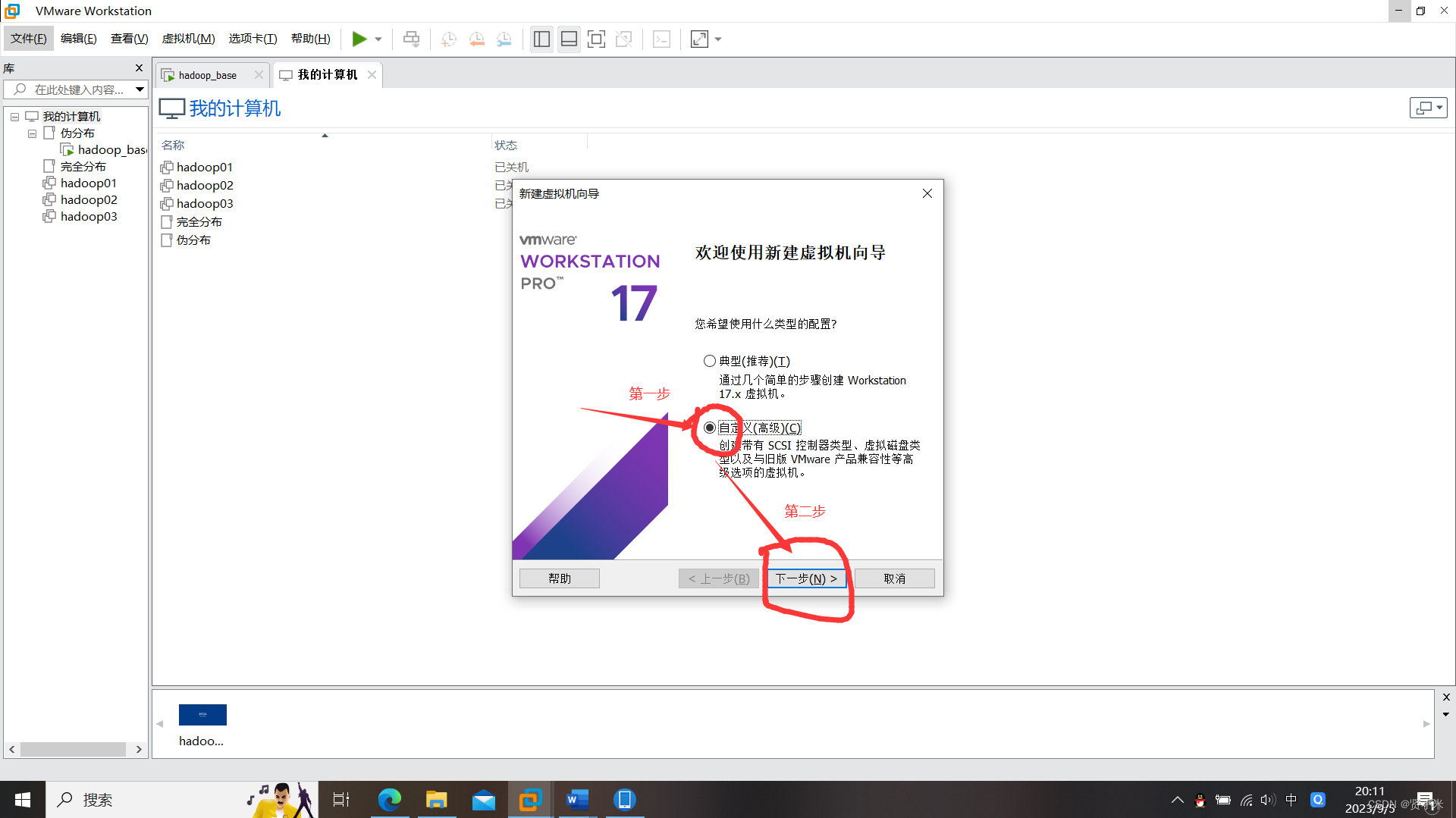
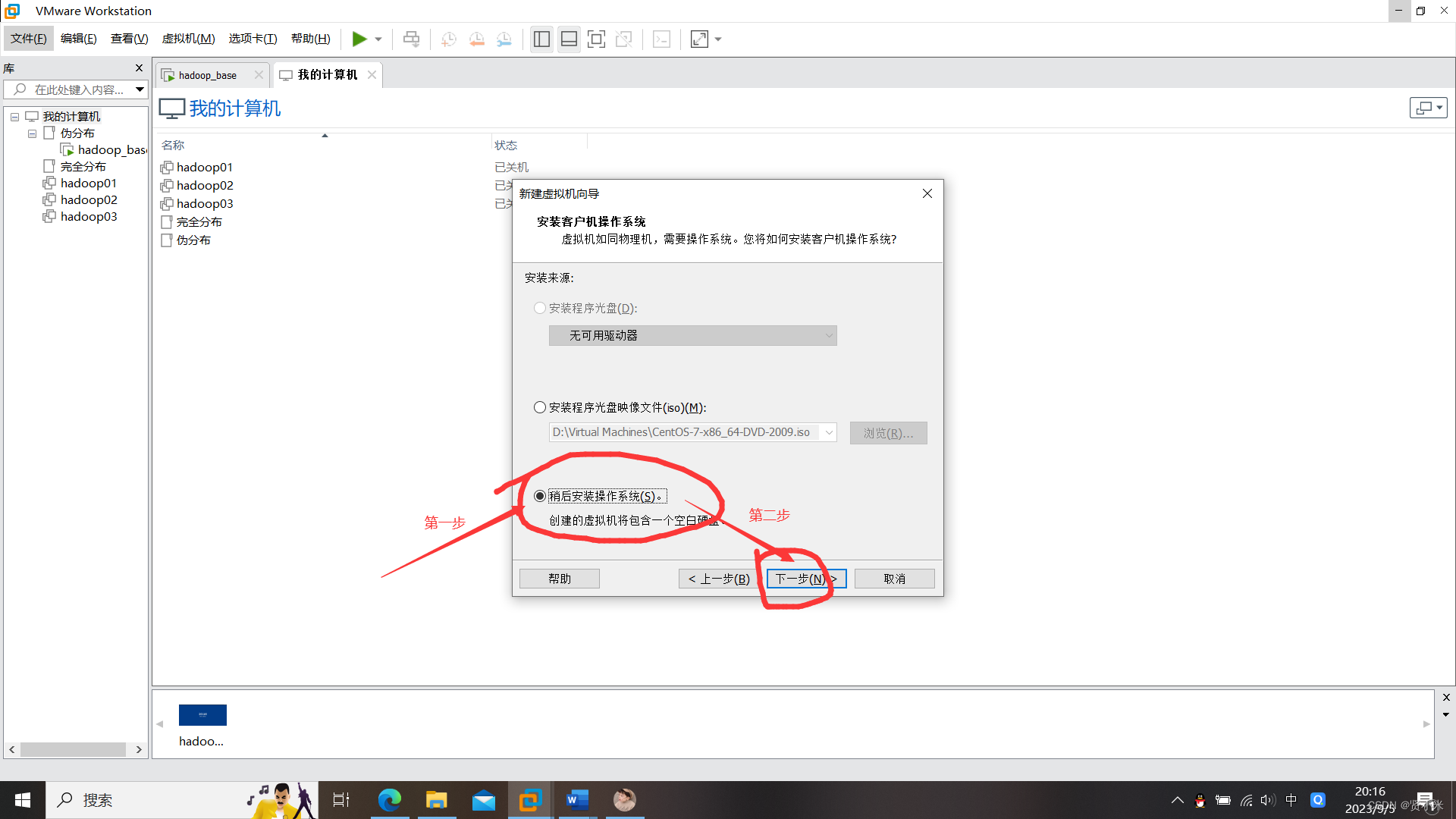
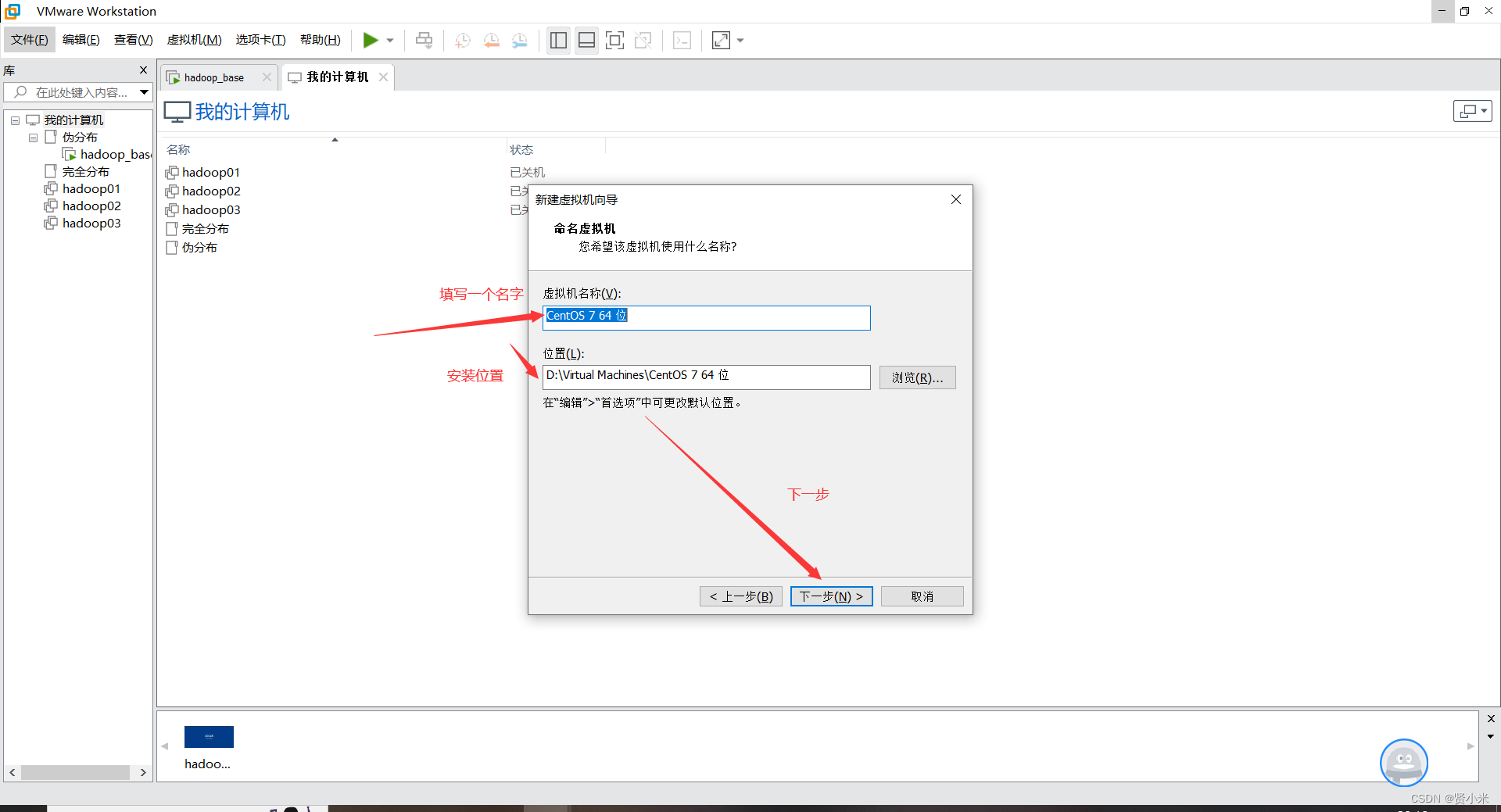
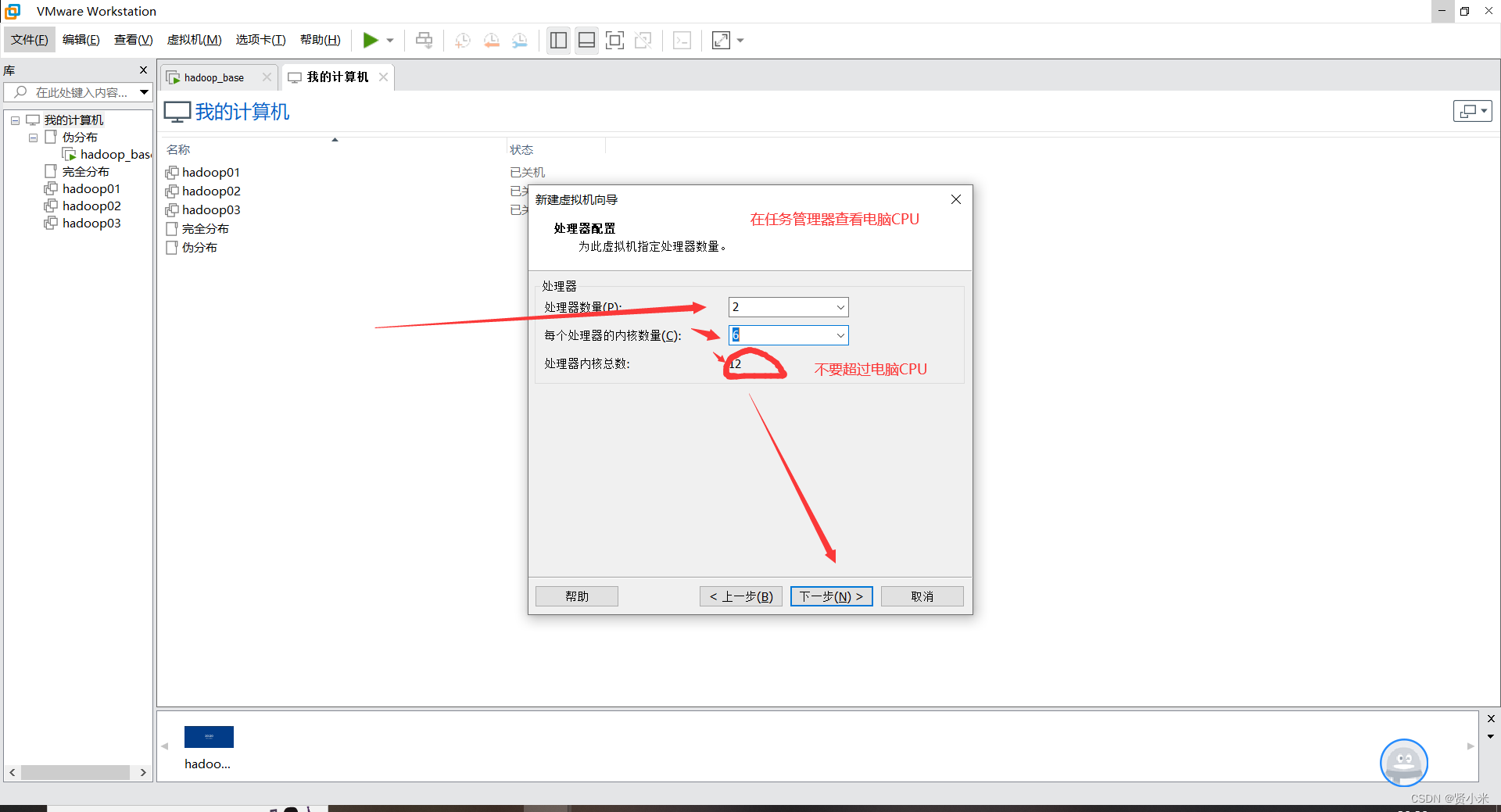
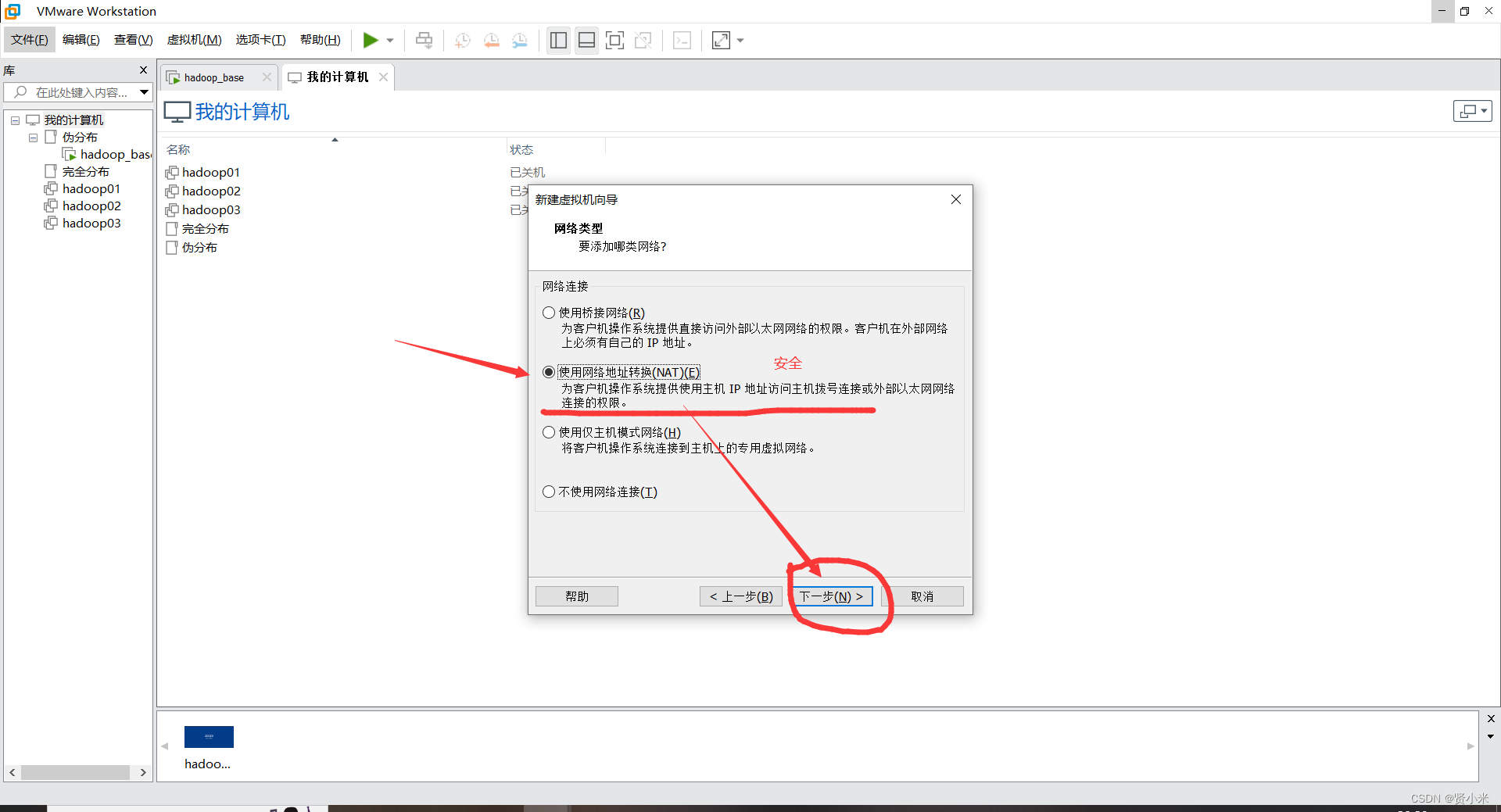
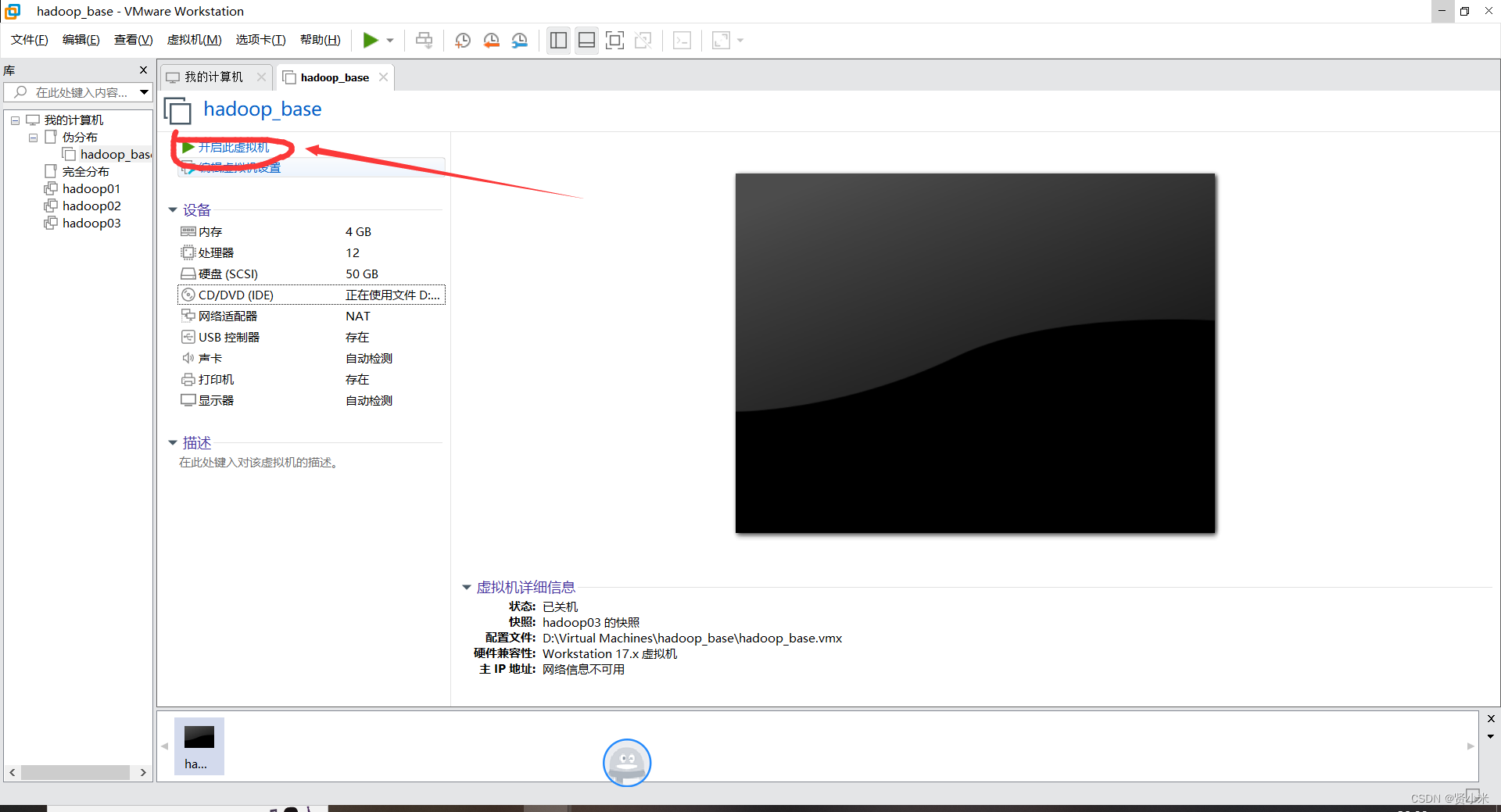
打开VMware,点击文件->点击虚拟机->创建新的虚拟机

虚拟机安装设置









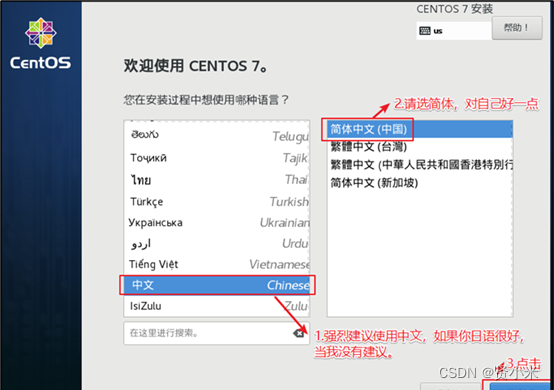
(1)时间设置
选择和自身电脑时间一样即可
(2)软件选择
点击软件选择->点击GHOME->点击完成
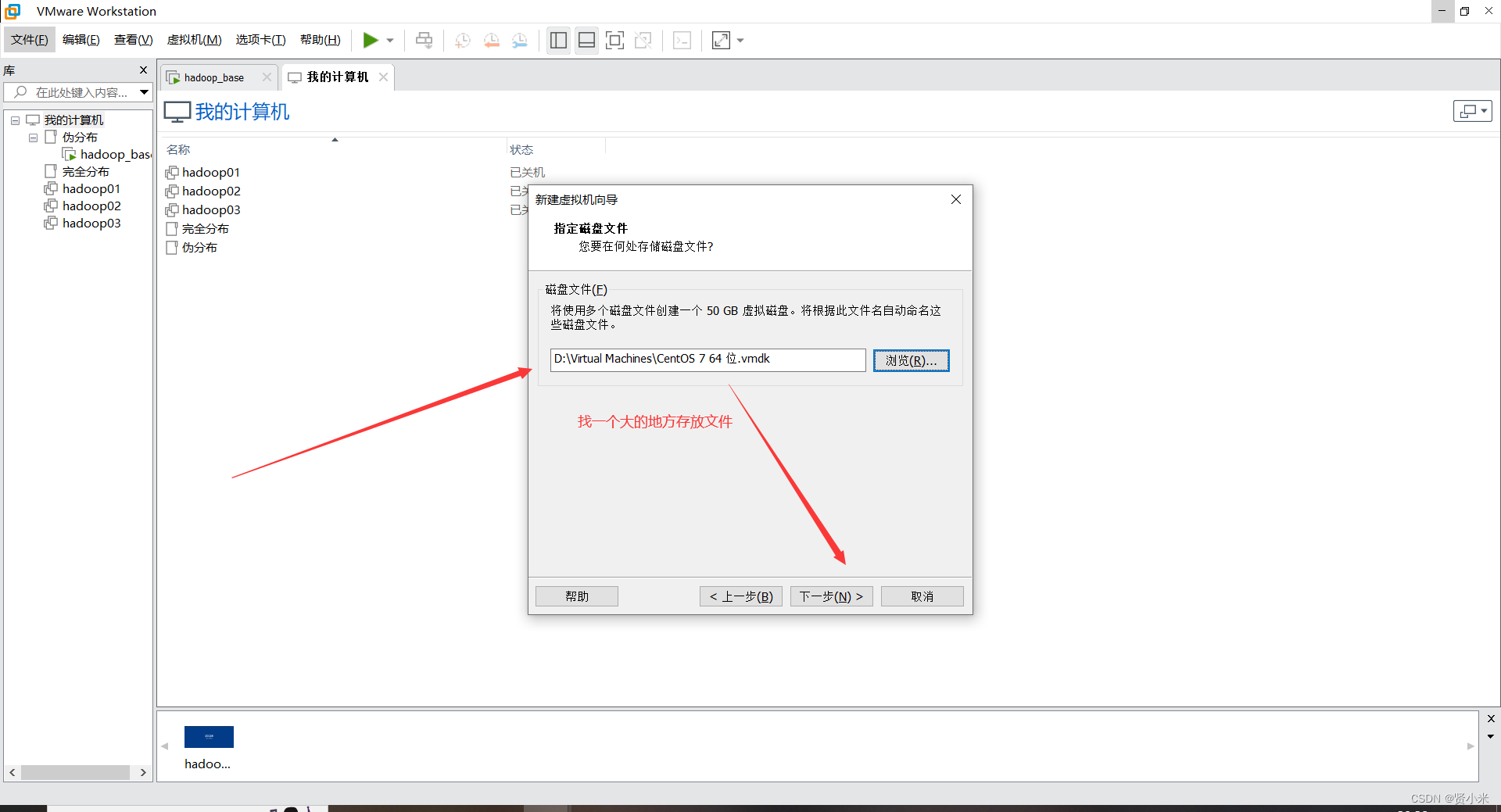
(3)安装位置(配置磁盘分区)
点击其他存储设置->点击我要配置分区->点击完成
(4)手动添加分区
点击选择为标准分区->点击+(加号)
(a)/boot -> 1G -> 添加挂载点 -> 修改文件系统为ext4 -> 点击+(加号)
(b)swap -> 4G -> 添加挂载点 -> 点击+(加号)
(c)/ -> 45G -> 添加挂载点 -> 修改文件系统为ext4 -> 点击完成
(5)kdump
把启用kdump前的对勾去掉
(6)网络和主机名
打开网络按钮 -> 修改主机名 -> 点击应用 -> 点击完成
(7)SECURITY POLICY
这个随便好了
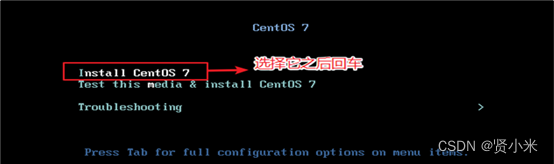
(8)开始安装(慢慢等待)
(9)设置root用户密码(一定不要忘了)
(10)一直前进下一步 ,安装完,重启,重启后切换为root用户
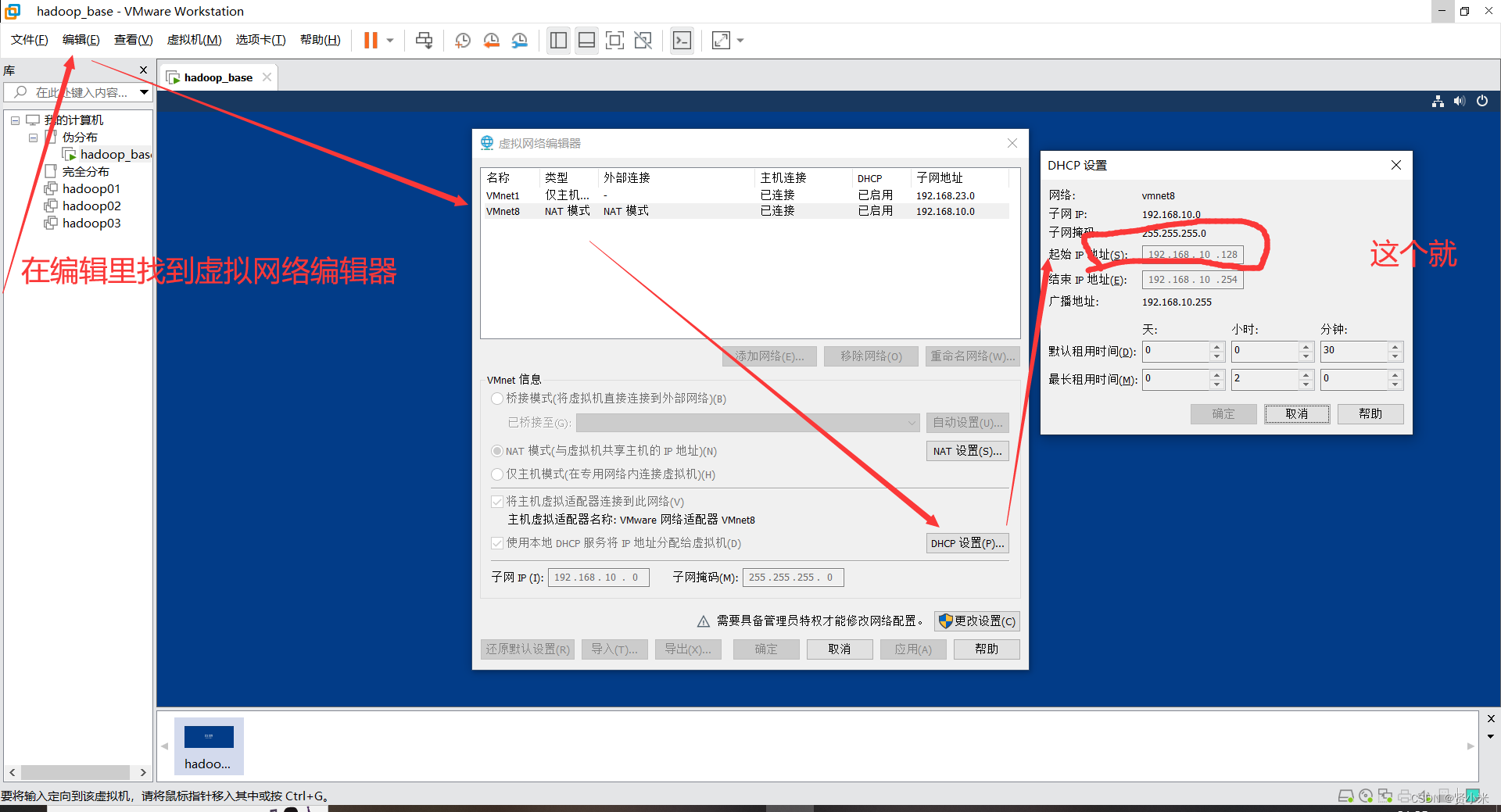
2、网络配置

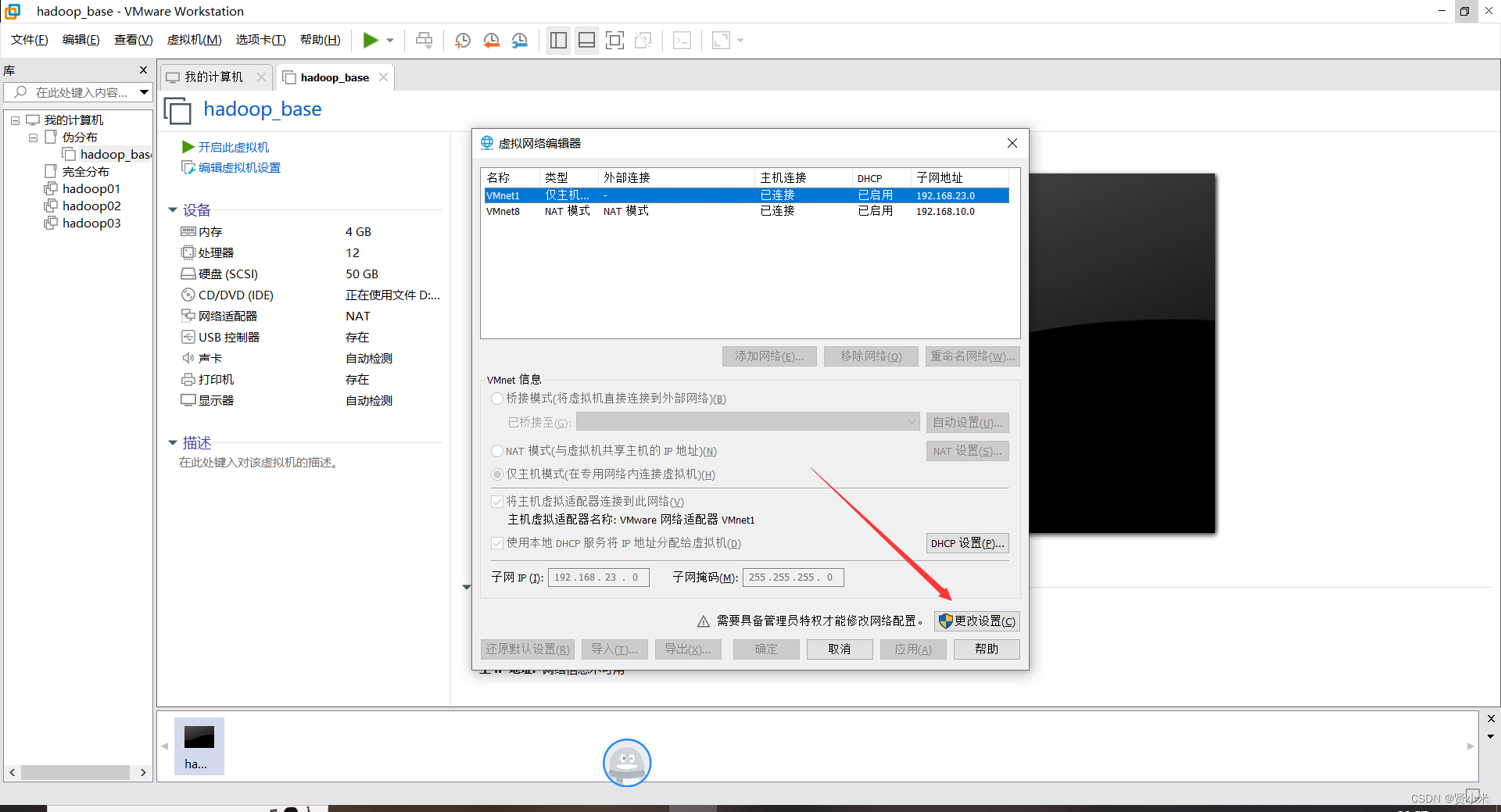

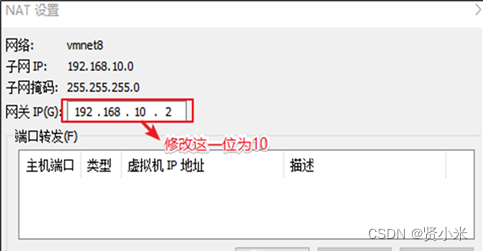


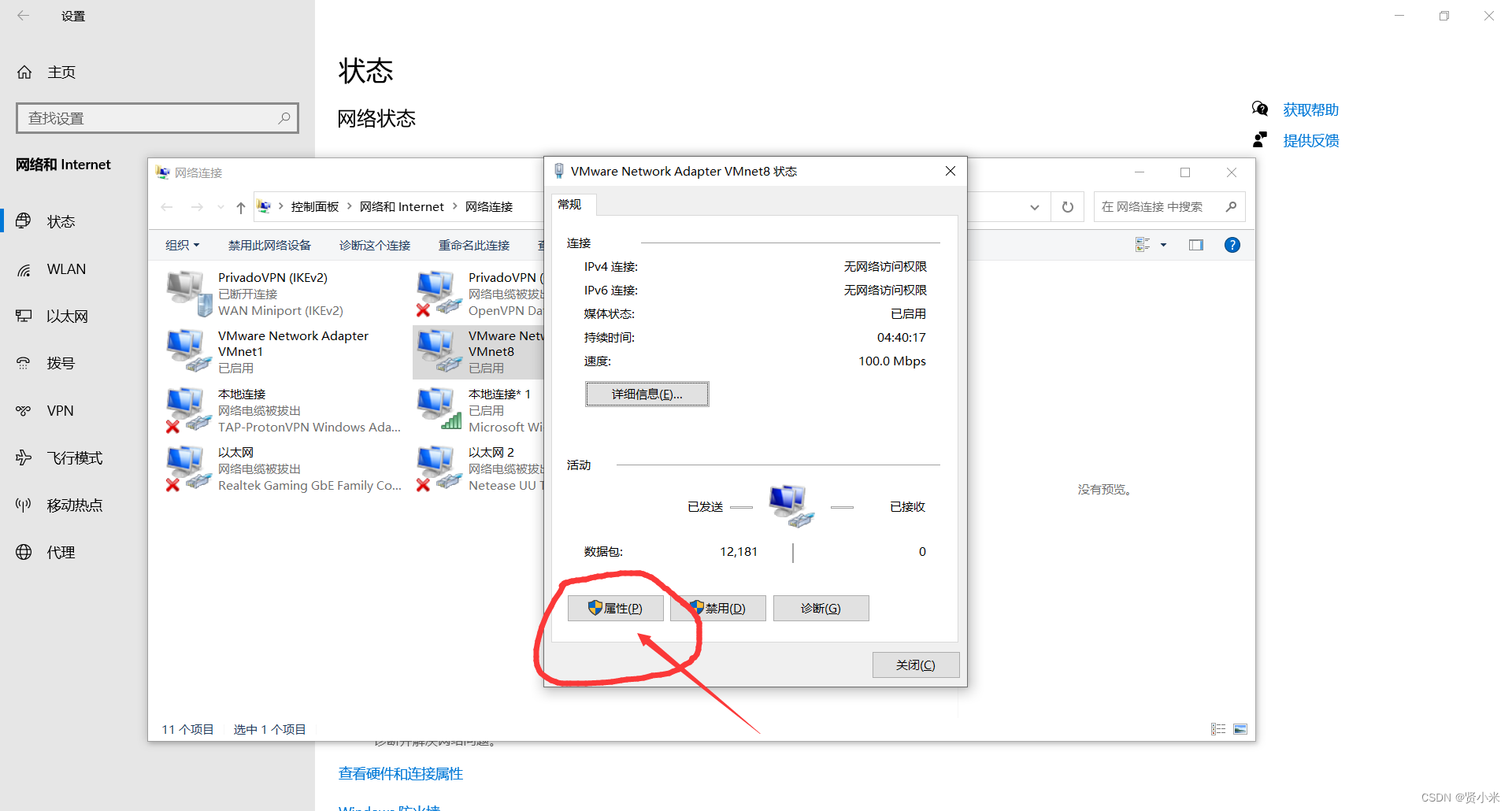
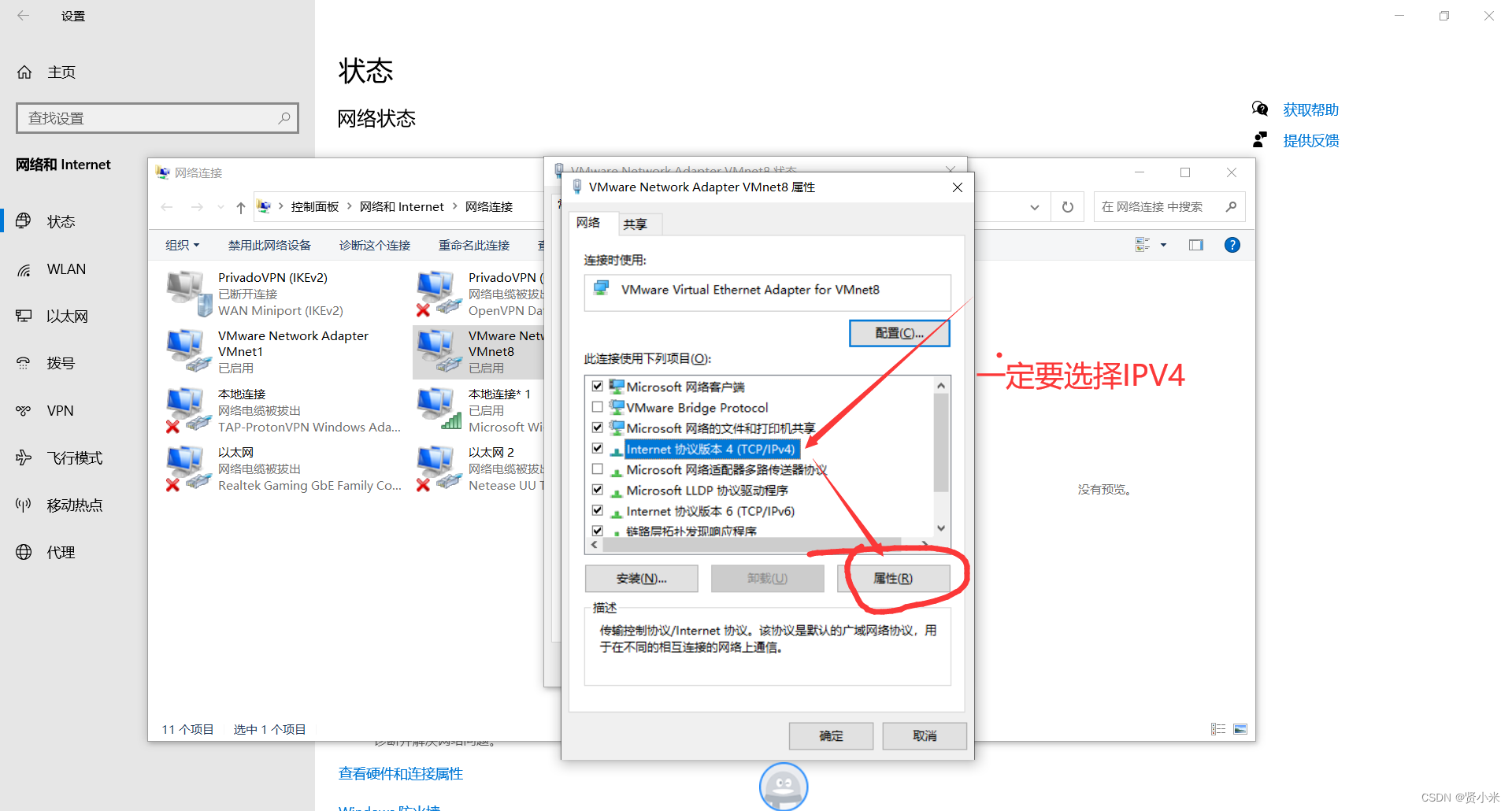
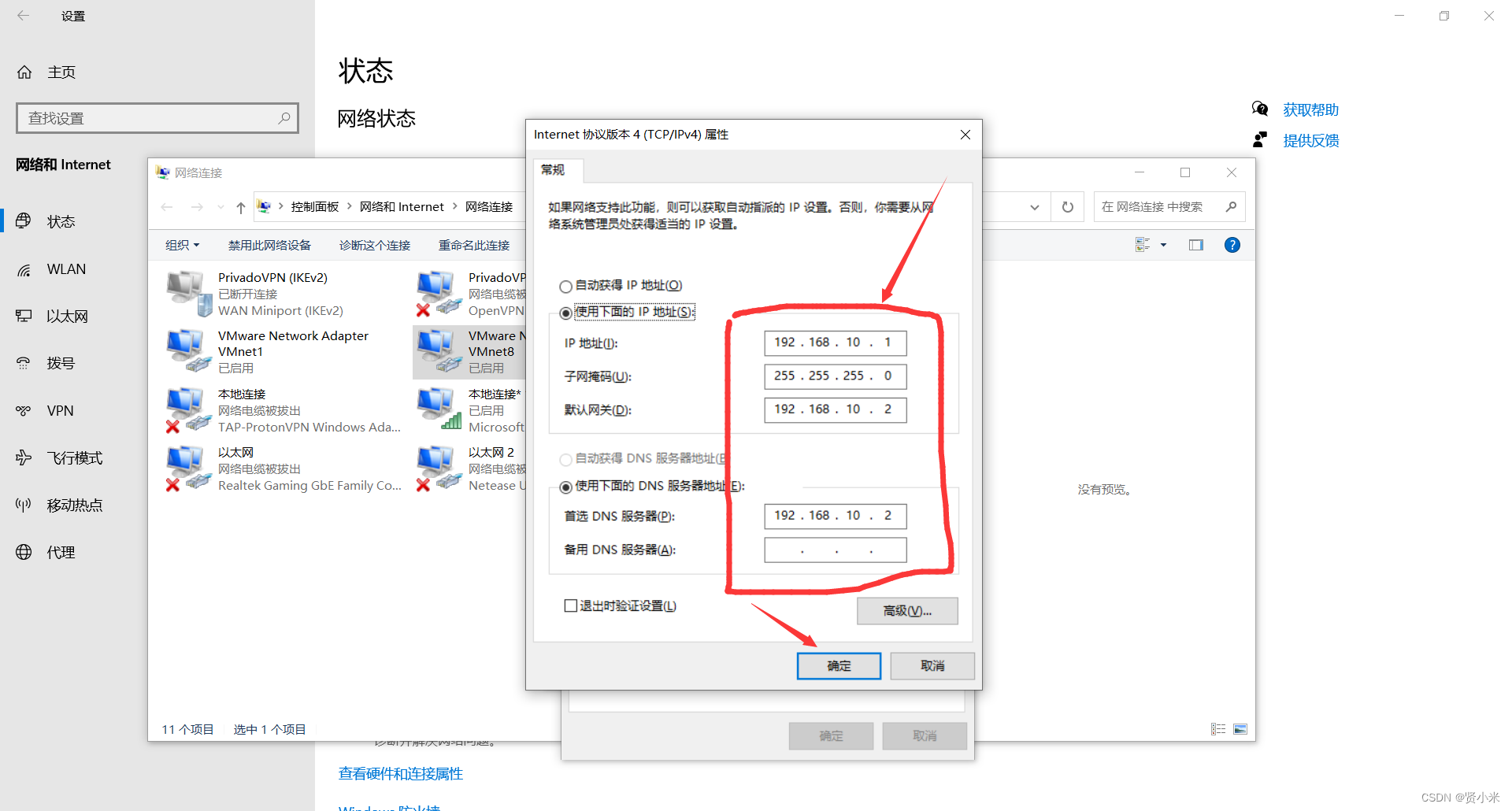
打开虚拟机,进行ip配置
输入命令 vim /etc/sysconfig/network-scripts/ifcfg-ens33 回车

执行systemctl restart network命令,重启网络服务
关闭防火墙,关闭防火墙开机自启
systemctl stop firewalld
systemctl disable firewalld.service
修改主机名
hostnamectl set-hostname hadoop101(hadoop101为主机名)
重启
reboot
3、正式开始伪分布式安装
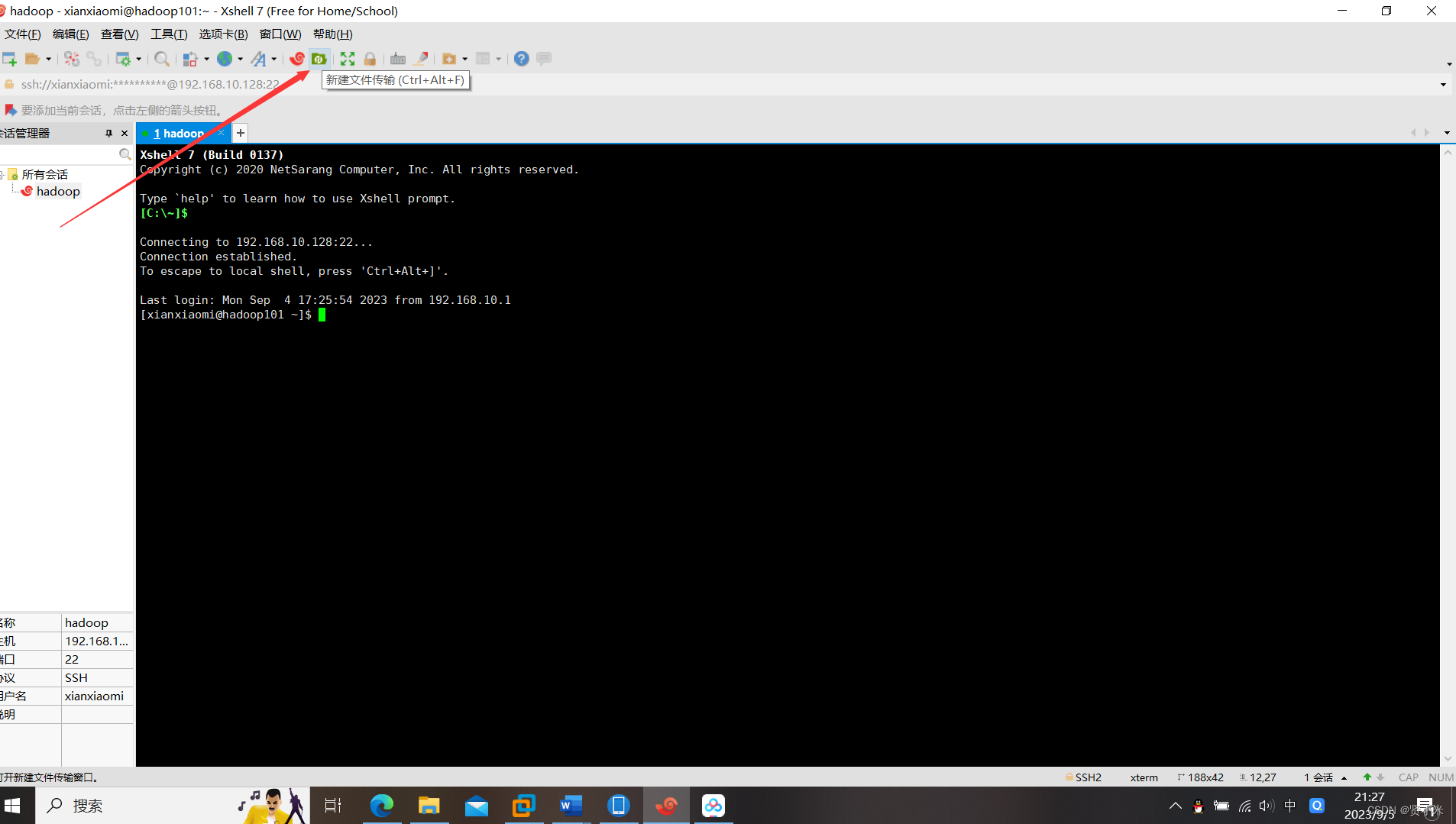
(1)先使用Xshell和Xftp上传解压jdk和hadoop
首先,下载好,jdk和hadoop的压缩包,还有Xshell和Xftp软件
链接:https://pan.baidu.com/s/1vbPMqrK8pkLnlxp5zwJQHg?pwd=u7ge
提取码:u7ge
打开Xshell 

(2)配置文件
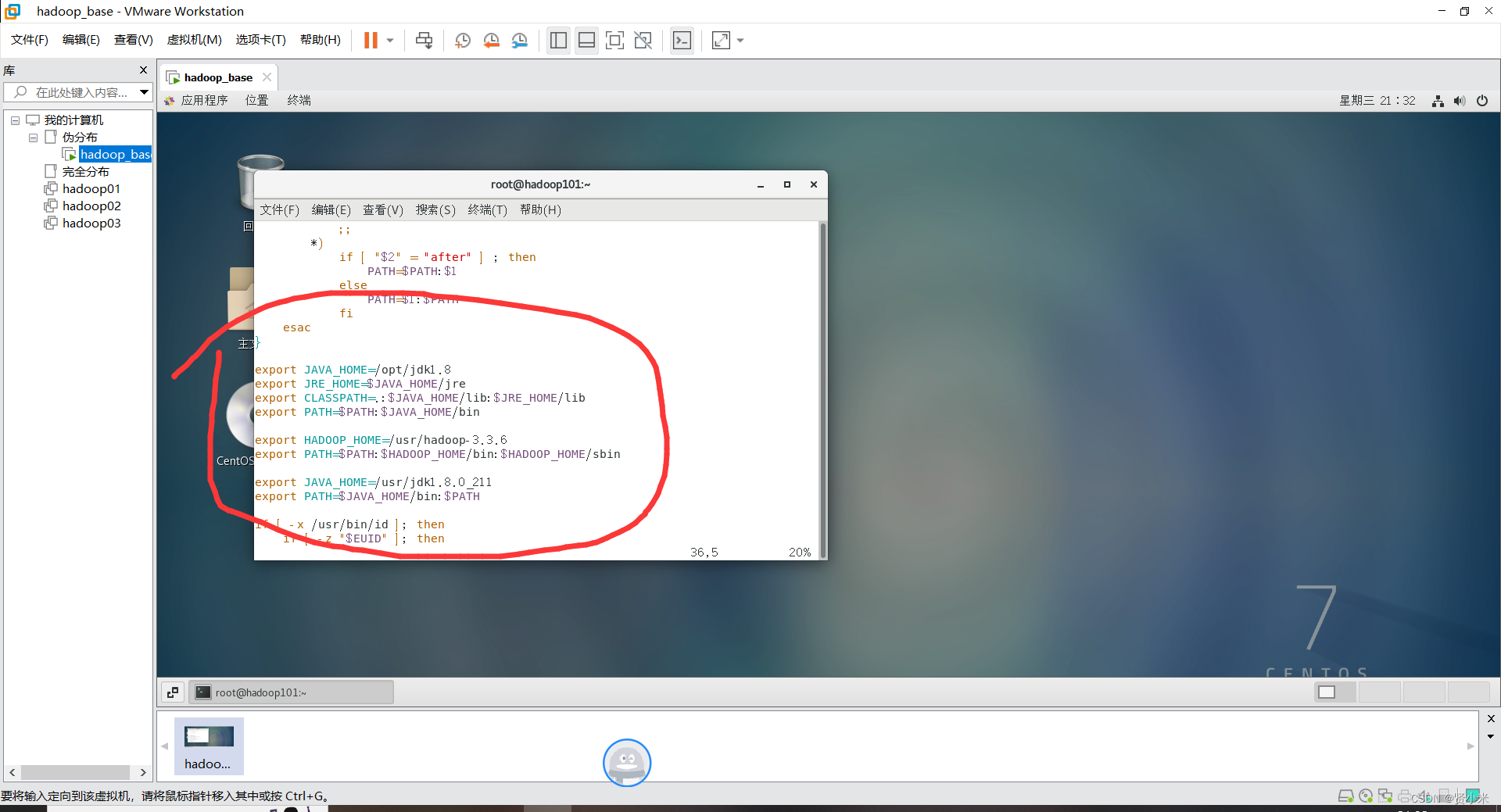
配置JDK
执行命令:
vim /etc/profile
文件中填写这些
export JAVA_HOME=/opt/jdk1.8
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME=/usr/jdk1.8.0_211
export PATH=$JAVA_HOME/bin:$PATH
按esc,shift+; 输入wq回车
生效JDK
source /etc/profile
配置SSH免密登录
# 执行该命令后遇到提示信息,一直按回车就可以
ssh-keygen -t rsa
# 将你的公共密钥填充到一个远程机器上的authorized_keys文件中,注意将下边命令里的hadoop修改为自己主机的名字
ssh-copy-id hadoop101
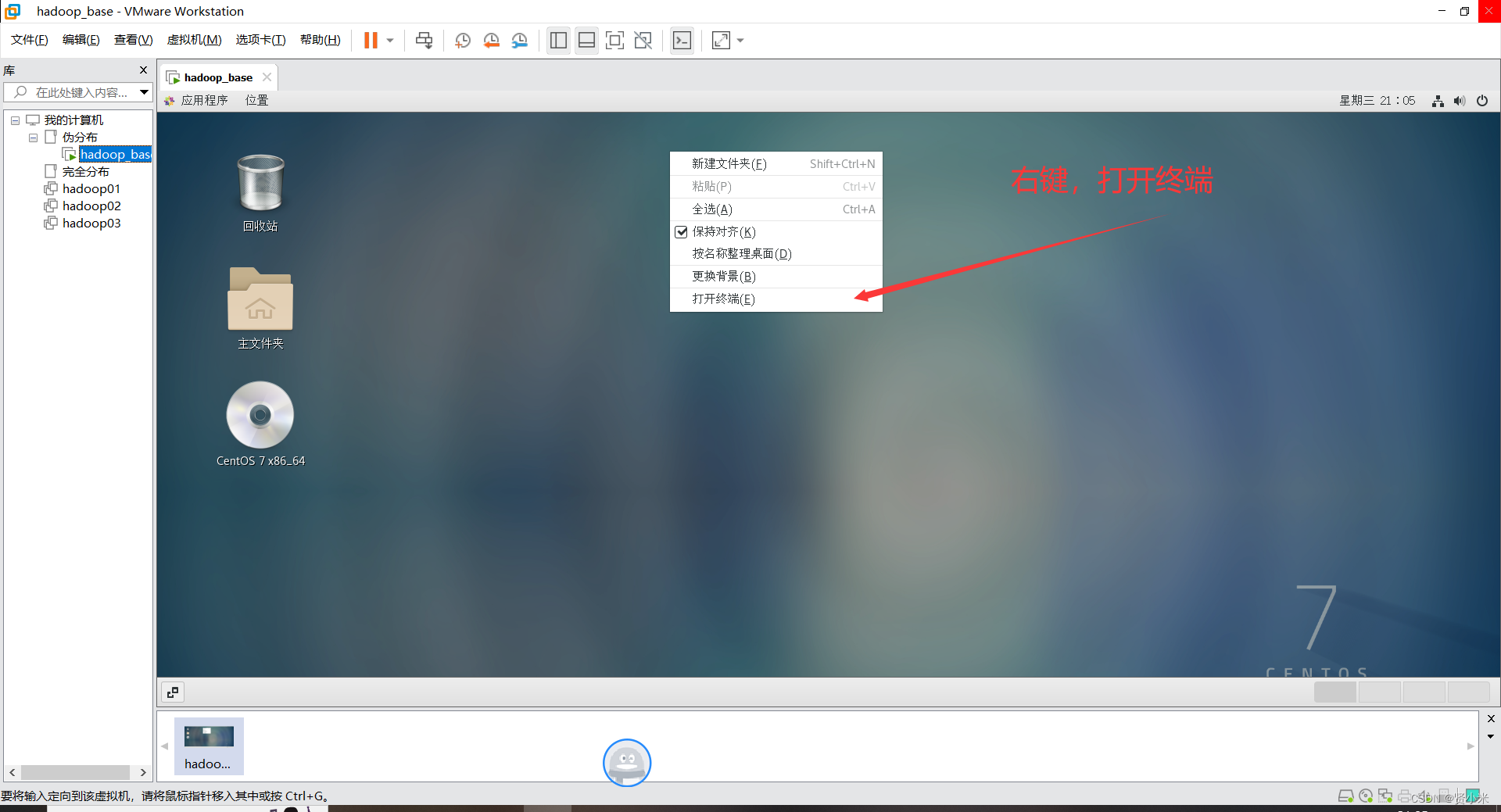
进入hadoop所在配置文件目录,例如/usr/hadoop-3.3.6/etc/hadoop
在此目录打开终端
配置hadoop-env.sh文件
执行命令
vim hadoop-env.sh
在文件中添加如图所示代码:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export JAVA_HOME=/usr/jdk1.8
HADOOP_SHELL_EXECNAME=root

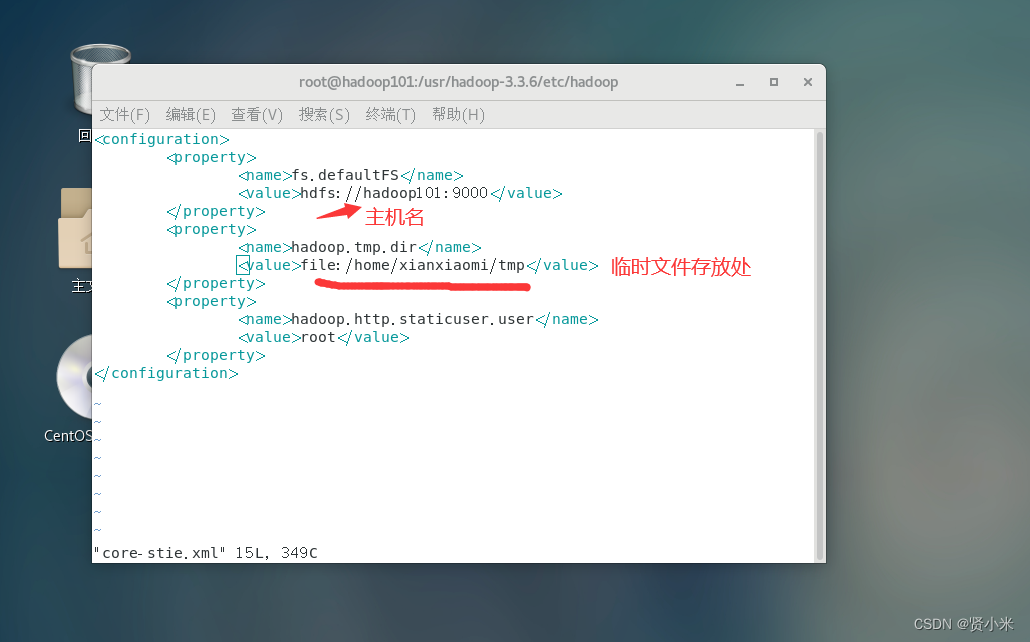
修改core-site.xml文件(一定根据自己虚拟机进行修改,不要直接复制)
执行命令
vim core-stie.xml
添加如下代码
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/app/hadoop/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
修改hdfs-site.xml
执行命令
vim hdfs-stie.xml
添加如下代码
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/hadoop3/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/hadoop3/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>

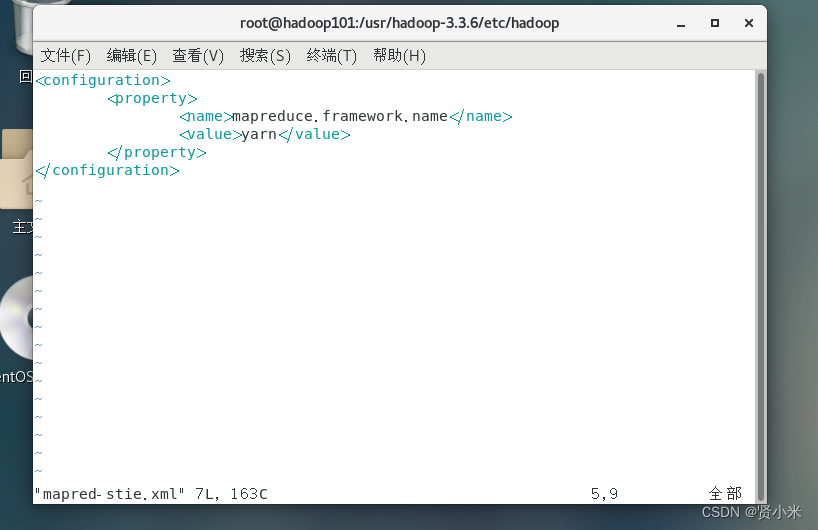
修改mapred-site.xml
执行命令
vim mapred-stie.xml
添加如下代码
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
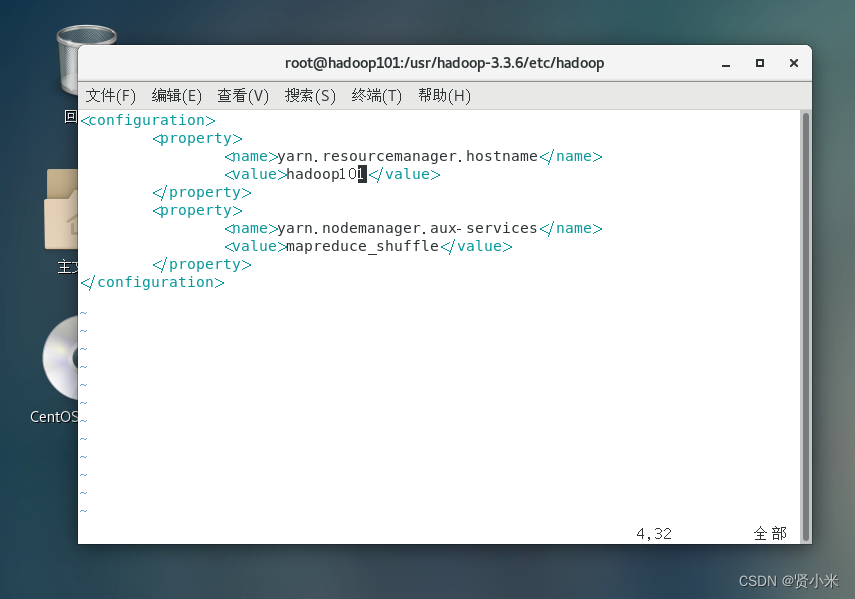
修改yarn-site.xml
执行命令
vim yarn-stie.xml
添加如下代码:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改workers文件
执行命令
vim workers
添加如下代码:
master
(说明:这个是你的主机名称hostname)
第一次使用需要格式化集群
hdfs namenode -format
出现如图所框选的信息表明成功
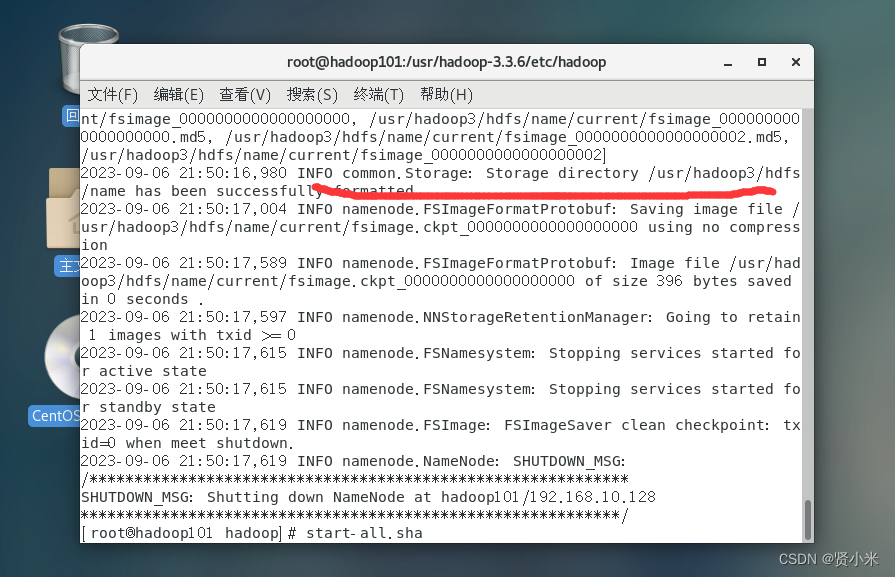
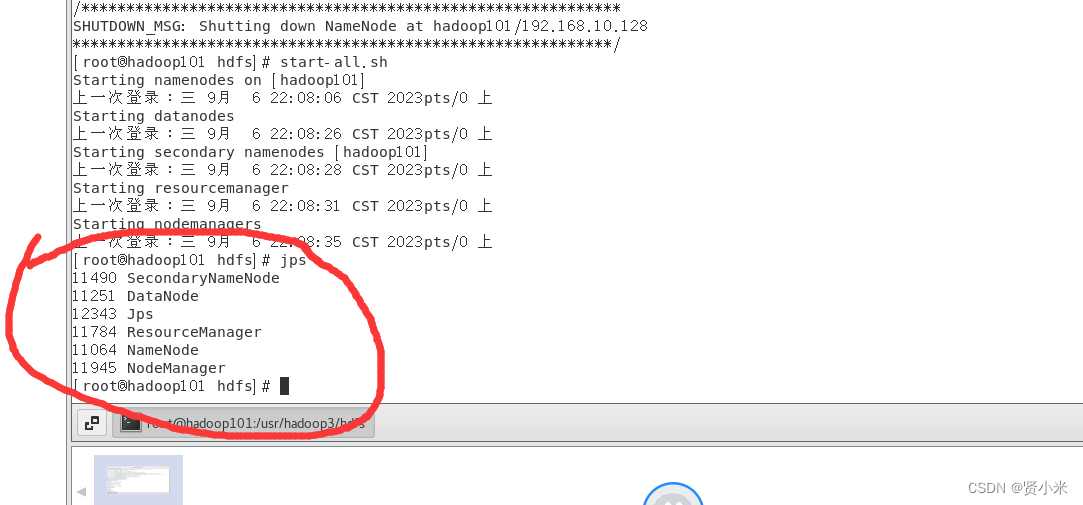
启动集群
start-all.sh
#或者分别启动hdfs和yarn
start-dfs.sh
start-yarn.sh
执行jps命令进行验证是否启动成功,出现以下5个进程表示启动成功。

完成,谢谢大家!!!

