
热门标签
热门文章
- 1GitHub 创始人资助的开源浏览器「GitHub 热点速览」
- 2WPF版的权限管理系统
- 3【面试精选】00后卷王带你三天刷完软件测试面试八股文
- 4jar包混淆和防反编译工具proguard使用简介
- 5Docker 部署kafka_docker kafka
- 6python3IDE下载手机安卓版,手机版python下载安装
- 7华为OD 技术综合面,手撕代码真题整理(七):字符串的不重复子串 | 二叉树的最大路径和_华为od面试手撕代码python
- 82024最详细Python安装教程(新手)
- 9阿里云网盘内测(附下载地址)_阿里云盘内测版官网
- 10C++数据结构 2.最简单的排序算法--冒泡排序_c++冒泡排序法代码数据结构
当前位置: article > 正文
mindspore ChatGLM-6B_mindspore格式的chatglm模型
作者:IT小白 | 2024-07-18 03:59:51
赞
踩
mindspore格式的chatglm模型
一些大语言模型可以下载对应的模型参数后,进行推理和微调。
配置环境
- %%capture captured_output
- # 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
- !pip uninstall mindspore -y
- !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
-
- !export HF_ENDPOINT=https://hf-mirror.com
- !pip install mindnlp
- !pip install mdtex2html
- !pip install gradio
首先安装mindspore,mindnlp,mdtex2html,gradio库。
配置huggingface的环境变量。由于huggingface.co被墙访问不了,所以设置镜像hf-mirror.com。这样运行代码后,会从镜像下载模型。
- from mindnlp.transformers import AutoModelForSeq2SeqLM, AutoTokenizer
- import gradio as gr
- import mdtex2html
-
- model = AutoModelForSeq2SeqLM.from_pretrained('ZhipuAI/ChatGLM-6B', mirror="modelscope").half()
- model.set_train(False)
- tokenizer = AutoTokenizer.from_pretrained('ZhipuAI/ChatGLM-6B', mirror="modelscope")
一般这种大语言模型和图像生成模型都有封装好的pipeline和API。
这里直接从modelscope下载ChatGLM-6B模型,采用half的半精度,这种简版的模型权重更小,需要的运行占用内存更少,适合推理。设置推理模型。加载对应的分词器。
估计十几二十几分钟下载好模型的参数。
- prompt = '你好'
- history = []
- response, _ = model.chat(tokenizer, prompt, history=history, max_length=20)
- response
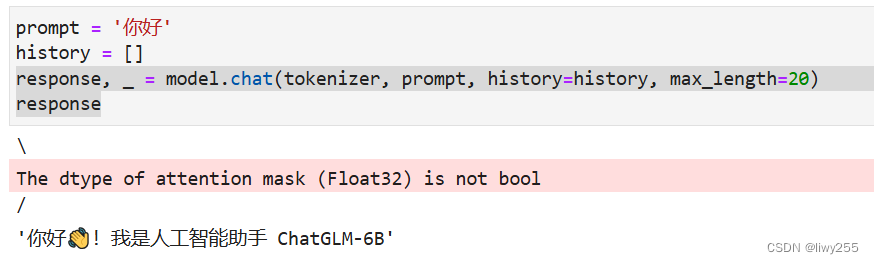
然后就可以输入问题进行交互了。history模式里面放置之前的对话,每一个是问答元组。
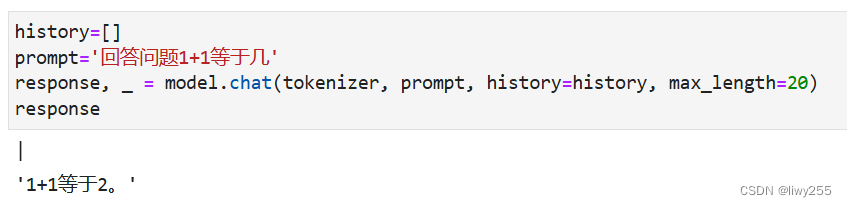


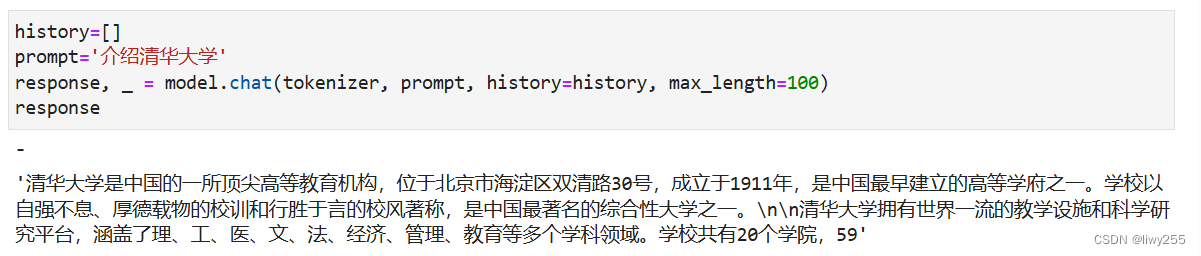 当然这样有最大长度限制,多的部分后面会被截断。
当然这样有最大长度限制,多的部分后面会被截断。
这就是简易部署大语言模型的方式。一般需要提前下载模型参数。主要考虑下载的速度,存储空间是否足够,显存大小。我是在mindspore上面尝试的。当然如果是使用大语言模型的话,最方便的还是使用在线的大语言模型,比如chatgpt4,通义千问,文心一言,kimi,豆包这些吧。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/843475
推荐阅读
相关标签

