
- 1ROS2学习_ros2 tf2 view
- 2html画圣诞树—动态效果展示【炫酷合集】_html 超好看的圣诞树
- 3如何看待鸿蒙HarmonyOS?
- 4startActivityForResult替代方案registerForActivityResult
- 5【MOOC】JS脚本|便于复制粘贴中国大学MOOC网站的测试题和选项_mooc脚本
- 6json的数据结构
- 7python中.txt文件的使用【txt读取和写入】_python写txt文件
- 8铁打阿里,流水美团,校招Offer薪资曝光后,伤了老员工的心_阿里和美团offer比较
- 9计算机毕业设计springboot大学文献检索查新自助服务系统278t69【附源码+数据库+部署+LW】
- 10windows10 python版本管理工具_windows python版本管理工具
ID3决策树Python代码实现_id3决策树代码
赞
踩
1.首先输入用于分类的数据

注:labels是特征的名称
2.计算给定数据集的信息熵
首先让我们看一下信息熵的公式
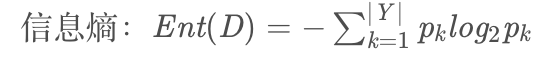
所以计算信息熵的代码实现是:

注:line[-1]是标签列,labelCounts字典是统计正负样例的个数,numData是总样例的个数。信息熵公式中的pk就是标签列各属性样例个数比上样例总个数。比如根结点所有样例标签列集合是[优等,中等,下等],优等有20个样例,中等有30个样例,下等有40个样例,那么pk就分别是20/70,30/70,40/70。
3.划分子数据集
前面我们讲过,决策树是递归进行的。每次我们都要计算当前特征下各个属性的信息熵,那么就要当前特征特定属性有多少样例,其中有多少正例和负例。
那么代码可如下表示
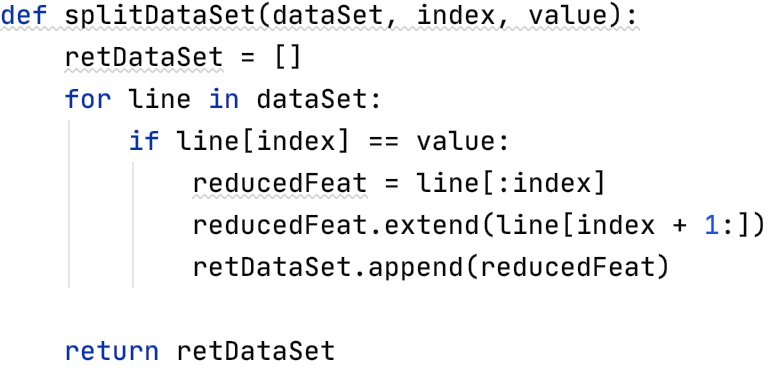
注:dataSet是当前节点下的数据集,index是当前属性的下标,value是当前属性。比如对于上面我们creat的数据集来说,我想知道根蒂=蜷缩的数据有哪些,那么index就是1,value=蜷缩。
4.选择信息增益最大的特征来生成决策树新的分支
我们先来看,信息增益的公式如下所示:
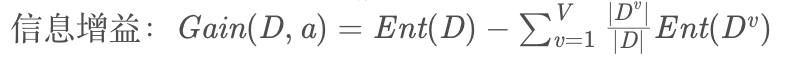
所以想要求出当前特征的信息增益,需要求出当前节点的信息熵,再求出当前特征下各属性的信息熵,再根据公式进行计算。则代码如下:

注:baseEntropy是当前节点的信息熵,featList是当前节点当前属性下的所有取值,uniqueVals是对featList去重,接下来就是求当前特征下各个属性的信息熵,然后进行信息增益的计算,最后取所有特征中信息增益最大的特征作为划分分支
5.返回该节点数据集中类别出现次数最多的类别

注:倒叙排列classCount得到一个字典集合,然后取出第一个就是结果(好瓜/坏瓜),即出现次数最多的结果。sortedClassCount的形式是[(),(),(),...],每个键值对变为元组并以列表形式返回
6.构建决策树
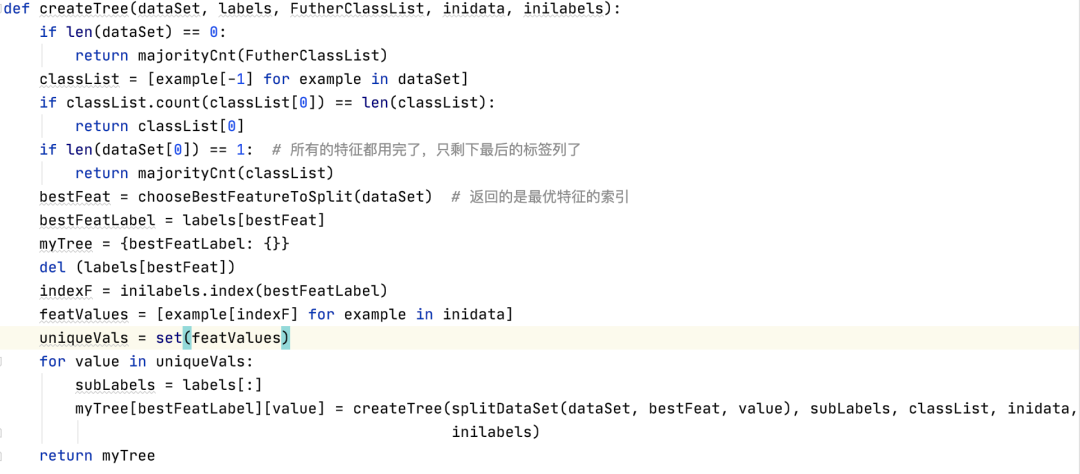
注:停止划分结点的三种情况:a)所有的类标签完全相同,则直接返回该类标签;b)使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组,那么出现相同label多的一类,作为结果;c)如果该结点为空集,则将其设为叶子结点,节点类型为其父节点中类别最多的类。
喜欢的话点个关注哦~ 会每天分享人工智能机器学习内容,回复关键字可获取相关算法数据及代码~


