
- 1Vue 登录权限配置_vue3登录游客登录和管理员登录
- 2STM32_PWM呼吸灯_stm32pwm的呼吸灯设计总结
- 3python网球比赛模拟_2019-05-12 Python之模拟体育竞赛
- 4如何理解期权的保证金和权利金的区别?
- 5python做应用程序错误_pythonw.exe应用程序错误
- 6Python+Selenium详解(超全)_selenium,python
- 7云服务器搭载zookeeper集群遇到的坑,java.net.BindExxeption和java.net.SoketTimeoutException_quorumlistenonallips=true
- 8提取数据_python pdf文件提取表格数据
- 9【联邦学习+区块链】TORR: A Lightweight Blockchain for Decentralized Federated Learning_federated learning blockchain call for paper
- 10【编程入门题--二维数组的转置】
协同过滤推荐算法在python上的实现_协同过滤算法
赞
踩
1.引言
信息大爆炸时代来临,用户在面对大量的信息时无法从中迅速获得对自己真正有用的信息。传统的搜索系统需要用户提供明确需求,从用户提供的需求信息出发,继而给用户展现信息,无法针对不同用户的兴趣爱好提供相应的信息反馈服务。推荐系统相比于搜索系统,不需要提供明确需求,便可以为每个用户实现个性化推荐结果,让每个用户更便捷地获取信息。它是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。
智能推荐的方法有很多,常见的推荐技术主要分为两种:基于用户的协同过滤推荐和基于物品的协同过滤推荐。
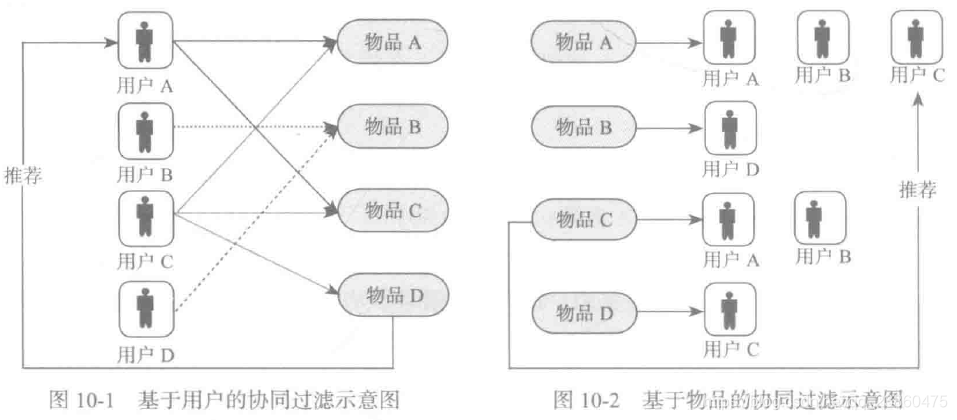
基于用户的协同过滤的基本思想相当简单,基于用户对物品的偏好找到邻居用户,然后将邻居用户喜欢的物品推荐给当前用户。计算上就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到N个邻居后根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。图10-1给出了一个例子:对于用户A,根据用户的历史偏好,这里只计算得到一个邻居用户C,然后将用户C喜欢的物品D推荐给用户A。
基于物品的协同过滤推荐的原理和基于用户的原理类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。图10-2给出了一个做例子:对于物品A,根据所有用户的历史偏好,喜欢物品A的用户都喜欢物品C,得出物品A和物品C比较相似,而用户C喜欢物品A,那么可以推断出用户C可能也喜欢物品C。
2.相似度算法
实现协同过滤算法的第一个重要步骤就是计算用户之间的相似度。而计算相似度建立相关系数矩阵目前主要分为以下几种方法:
(1)皮尔逊相关系数
皮尔逊相关系数一般用户计算两个定距变量间联系的紧密度,它的取值在[-1,1]之间。用数学公式表示,皮尔逊相关系数等于两个变量协方差除于两个变量的标准差。计算公式如下所示:
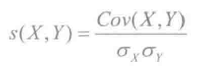
由于皮尔逊相关系数描述的是两组数据变化移动的趋势,所以在基于用户的协同过滤系统中经常使用。描述用户购买或评分变化的趋势,若趋势相近则皮尔逊系数趋近于1.也就是我们认为相似的用户。
(2)基于欧几里德距离的相似度
欧几里德距离计算相似度是所有相似度计算里面最简单、最易理解的方法。它以经过人们一致评价的物品为坐标轴,然后将参与评价的人绘制到坐标系上,并计算他们彼此之间的直线距离。计算出来的欧几里德距离是一个大0的数,为了使其更能体现用户之间的相似度,可以把它规约到(0.1]之间,最终得到如下计算公式:

只要至少有一个共同评分项,就能用欧几里德距离计算相似度,如果没有共同评分项,那么欧几里德距离也就失去了作用。其实照常理,如果没有共同评分项,那么意味着这两个用户或物品根本不相似。
(3)余弦相似度
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦相似度更加注重两个向量在方向上的差异,而非在距离或长度上,计算公式如下所示:

从图10-3可以看出距离度量衡量的是空间各点间的绝对距离,跟各点所在的位置坐标直接相关;而余弦相似度衡量的是空间向量的夹角,更加注重的是体现在方向上的差异。而不是位置。如果保持X点的位置不变,Y点朝原方向远离坐标轴原点,那么这个时候余弦相似度是保持不变的,因为夹角不变,而X、Y的距离显然在发生改变,这就是欧氏距离和余弦相似度的不同之处。

(4)调整的余弦相似度
调整的余弦相似度计算,由于基于余弦的相似度计算没有考虑不同用户的打分情况,可能有的用户偏向于给高分,而有的用户偏向于给低分,该方法通过减去用户打分的平均值消除不同用户打分习惯的影响,公式如下:
其中表示用户u对物品i的打分,
表示用户u打分的平均值。该公式主要用于基于物品的协同过滤推荐系统。
3.预测算法
实现协同过滤算法的第二个重要步骤就是预测用户未评价物品的偏好,基于物品的协同过滤预测是用对用户u已打分的物品的分数进行加权求和,权值为各个物品与物品i的相似度,然后对所有物品相似度的和求平均,计算得到用户u对物品i打分(基于用户的协同过滤预测同理),公式如下:
其中为物品i与物品N的相似度,
为用户u对物品N的打分。
4.实例
以推荐课程为例,部分数据如下:

基于用户的协同过滤给俞俊、刘斯推荐三门课程,运行结果如下:

python代码

基于用户和基于物品都有:
点击可查看大图。

5.Item-CF和User-CF选择
一、user和item数量分布以及变化频率
(1) 如果user数量远远大于item数量, 采用Item-CF效果会更好, 因为同一个item对应的打分会比较多, 而且计算量会相对较少
(2) 如果item数量远远大于user数量, 则采用User-CF效果会更好, 原因同上
(3) 在实际生产环境中, 有可能因为用户无登陆, 而cookie信息又极不稳定, 导致只能使用item-cf
(4) 如果用户行为变化频率很慢(比如小说), 用User-CF结果会比较稳定
(5) 如果用户行为变化频率很快(比如新闻, 音乐, 电影等), 用Item-CF结果会比较稳定
二、相关和惊喜的权衡
(1) item-based出的更偏相关结果, 出的可能都是看起来比较类似的结果
(2)user-based出的更有可能有惊喜, 因为看的是人与人的相似性, 推出来的结果可能更有惊喜
三、数据更新频率和时效性要求
(1) 对于item更新时效性较高的产品, 比如新闻, 就无法直接采用item-based的CF, 因为CF是需要批量计算的, 在计算结果出 来之前新的item是无法被推荐出来的, 导致数据时效性偏低;
(2) 但是可以采用user-cf, 再记录一个在线的用户item行为对, 就可以根据用户最近类似的用户的行为进行时效性item推荐;
(3) 对于像影视, 音乐之类的还是可以采用item-cf的
6.结论
(1) Item-based算法的预测结果比User-based算法的质量要高一点。
(2) 由于Item-based算法可以预先计算好物品的相似度,所以在线的预测性能要比User-based算法的高。
(3) 用物品的一个小部分子集也可以得到高质量的预测结果。
如果对你有帮助,请点下赞,予人玫瑰手有余香!

