
传神论文中心|第11期人工智能领域论文推荐_are long-llms a necessity for longcontext tasks gi
赞
踩
在人工智能领域的快速发展中,我们不断看到令人振奋的技术进步和创新。近期,开放传神(OpenCSG)社区发现了一些值得关注的成就。传神社区本周也为对AI和大模型感兴趣的读者们提供了一些值得一读的研究工作的简要概述以及它们各自的论文推荐链接。
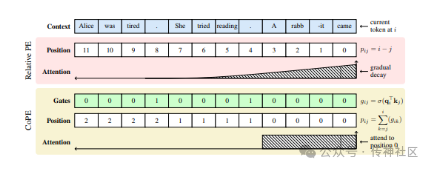
01 Contextual Position Encoding
传神社区注意到这篇文章中有以下亮点:CoPE (Contextual Position Encoding) 提出了新的位置编码方法,使得位置可以根据上下文进行条件化,仅在特定标记上递增位置。此方法使位置编码具备上下文依赖性,并能够表示不同层次的位置抽象。通用位置编码方法可以聚焦于特定的词、名词或句子,从而在语言建模和编码任务上提升了困惑度指标。CoPE 的引入为自然语言处理领域带来了革命性的进展。
论文推荐链接:
https://opencsg.com/daily_papers/KzznKrcihYKa
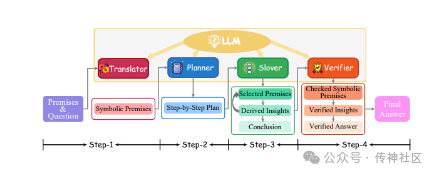
02 Symbolic Chain-of-Thought
传神社区注意到这篇文章中有以下亮点:Symbolic Chain-of-Thought 提出了一个改进大型语言模型(LLM)逻辑推理能力的方法,通过将符号表达和逻辑规则与链式思维(CoT)提示相结合来实现。该提示技术被称为 Symbolic Chain-of-Thought,是一个完全基于 LLM 的框架,包含以下关键步骤:1) 将自然语言上下文转换为符号格式,2) 根据符号逻辑规则逐步推导解决问题的方案,3) 使用验证器检查翻译和推理链。Symbolic Chain-of-Thought 通过引入符号逻辑和验证机制,显著提升了 LLM 在逻辑推理任务中的表现。
论文推荐链接:
https://opencsg.com/daily_papers/cYZ36wSXvpkr
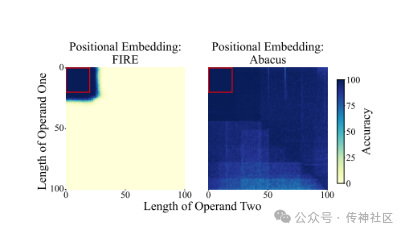
03 Abacus Embeddings
传神社区注意到这篇文章中有以下亮点:Abacus Embeddings 通过在单个 GPU 上训练 20 位数,实现了对 100 位数加法问题 99% 的准确率。该研究主要解决了变压器模型在精确追踪数字位置上的挑战。通过为每个数字添加一个编码其相对位置的嵌入,Abacus Embeddings 显著提升了模型的性能。这些改进还能够迁移到包括排序和乘法在内的多步骤推理任务中,展示了其在复杂数值计算任务上的卓越表现。
论文推荐链接:
https://opencsg.com/daily_papers/inC3fyAqubaF
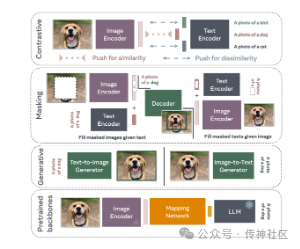
04 Introduction to Vision-Language Modeling
传神社区注意到这篇文章中有以下亮点:《Introduction to Vision-Language Modeling》介绍了视觉-语言模型的基本概念和关键技术细节。书中详细讲解了这些模型的工作机制,并提供了有效的训练方法指南。作为一本入门读物,该书为希望在视觉-语言领域深入研究的学者和工程师提供了全面的知识基础和实用的训练技巧。
论文推荐链接:
https://opencsg.com/daily_papers/XA4BcHjB16JT
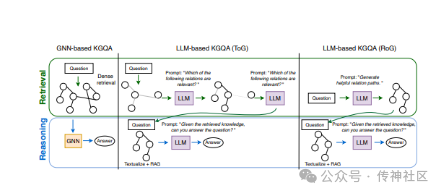
05 GNN-RAG
传神社区注意到这篇文章中有以下亮点:GNN-RAG 将大型语言模型(LLM)的语言理解能力与图神经网络(GNN)的推理能力相结合,以 RAG 风格进行集成。GNN 负责提取相关的图信息,LLM 则利用这些信息执行知识图谱问答(KGQA)。这种方法显著提升了基础 LLM 在 KGQA 任务上的性能,经过调优的 7B LLM 能够超越或匹敌 GPT-4 的表现。GNN-RAG 为改进知识图谱问答提供了一个有效的框架,展示了强大的应用潜力。
论文推荐链接:
https://opencsg.com/daily_papers/3cT1X69bNkYL
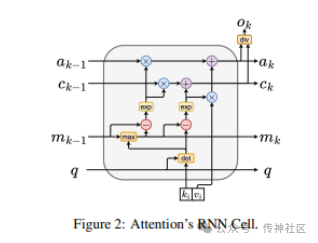
06 Attention as an RNN
传神社区注意到这篇文章中有以下亮点:Attention as an RNN 介绍了一种新的注意力机制,能够像 Transformer 一样进行并行训练,同时在引入新标记时保持常量内存使用,类似于 RNN。该注意力机制基于并行前缀扫描算法,允许高效计算注意力的多对多 RNN 输出。实验证明,该方法在 38 个数据集上的性能与 Transformer 相当,但在时间和内存效率上更具优势,为注意力机制的设计和应用提供了新的思路。
论文推荐链接:
https://opencsg.com/daily_papers/thLRExqL4Fhk
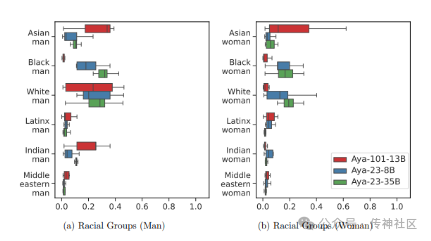
07 Aya23
传神社区注意到这篇文章中有以下亮点:Aya23 是一组多语言模型家族,专注于支持多达 23 种语言。通过有意减少支持的语言数量,Aya23 将更多的容量和资源分配给这些特定语言,从而在这些语言上的表现优于其他大规模多模态模型。实验表明,Aya23 在所关注的语言上取得了显著的性能提升,为特定多语言任务提供了更高效和准确的解决方案。
论文推荐链接:
https://opencsg.com/daily_papers/LuGdLyjqhLPb
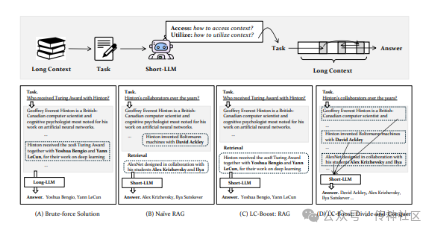
08 Are Long-LLMs A Necessity For Long-Context Tasks?
传神社区注意到这篇文章中有以下亮点:《Are Long-LLMs A Necessity For Long-Context Tasks?》主张长-LLMs 并非解决长上下文任务的必需品。本文提出了一种推理框架,使短-LLMs 能通过自适应地访问和利用上下文来处理长上下文任务。该方法通过将长上下文分解为短上下文并采用决策过程进行处理,显著提升了短-LLMs 在长上下文任务中的表现。这一创新框架为长上下文任务提供了一种高效而实用的解决方案。
论文推荐链接:
https://opencsg.com/daily_papers/CTyoCAiqGuXw
09 Financial Statement Analysis with LLMs
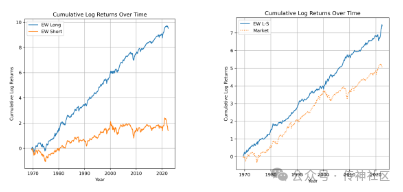
传神社区注意到这篇文章中有以下亮点:《Financial Statement Analysis with LLMs》探讨了大型语言模型(LLMs)在财务报表分析中的应用,表明这些模型能够生成有价值的见解,尤其在趋势分析和财务比率计算方面。研究显示,GPT-4 在财务分析领域的表现与一些专门的窄域模型相当,并且基于其预测实现了可盈利的交易策略。这表明 LLMs 在财务分析和投资策略制定中具有巨大潜力。
论文推荐链接:
https://opencsg.com/daily_papers/25BSPofJousb
10 SimPO
传神社区注意到这篇文章中有以下亮点:SimPO 提出了一种更简单和高效的偏好优化方法,采用无参照的奖励机制。该方法使用序列的平均对数概率作为隐式奖励,不需要参照模型,从而在计算和内存使用上更为高效。研究表明,SimPO 的表现优于现有方法如 DPO,并且生成了性能最强的 8B 开源模型。SimPO 为偏好优化提供了一种计算和内存高效的新途径,在性能和资源利用上均取得了显著进展。
论文推荐链接:
https://opencsg.com/daily_papers/hbXeSxtM4VYC

欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

