
- 118个产品经理常用AI工具及产品经理专属提示词_产品经理ai助手
- 2就是这么简单!破解激活AutoCAD 2019 for mac v2019.0.1(附图文讲解)_autocad201901.dmg
- 3ChatGPT对软件测试的影响,2024年“金三银四”来袭_chatgtp在软件测试的应用
- 4【全程录屏GPT3.5升级4.0】2024最新GPT4升级订阅详细指南_gpt3.5升级到gpt4要多久时间
- 5前后端都用得上的 Nginx 日常使用经验
- 6idea和VSCode的Terminal设置_idea terminal改用linux shell
- 7努力学计算机四年,终于进腾讯了!_程序员鱼皮的公司叫什么
- 8AI赋能教育:AI人工智能在教育中的 8 个应用示例(老师必须收藏)_ai分析在教学评价中的应用
- 9hive3从入门到精通_李昊哲小课
- 10Docker 大势已去,Podman 万岁;再见Docker,是时候拥抱下一代容器工具了_docker大势已去
太强了!LIama 3.1正式发布
赞
踩
Datawhale干货
编辑:量子位、Datawhale
刚刚,LIama 3.1正式发布,登上大模型王座!
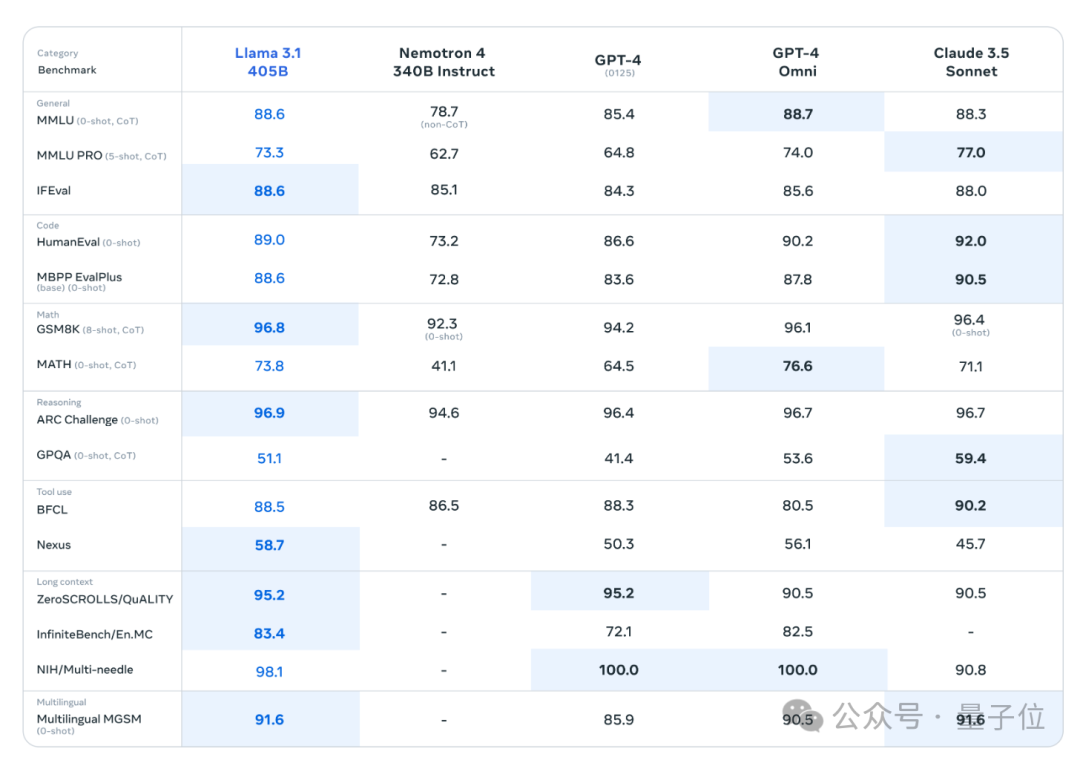
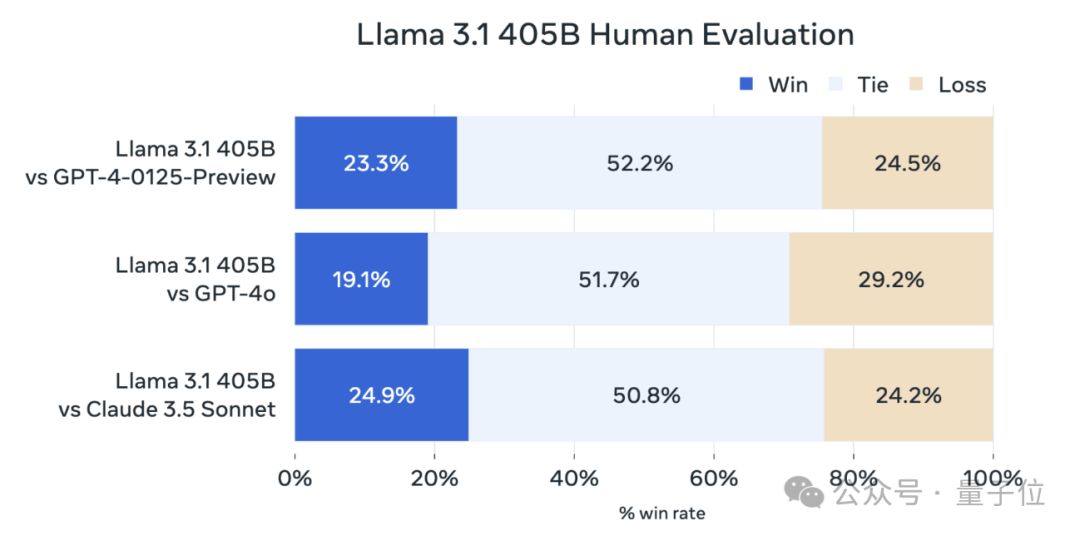
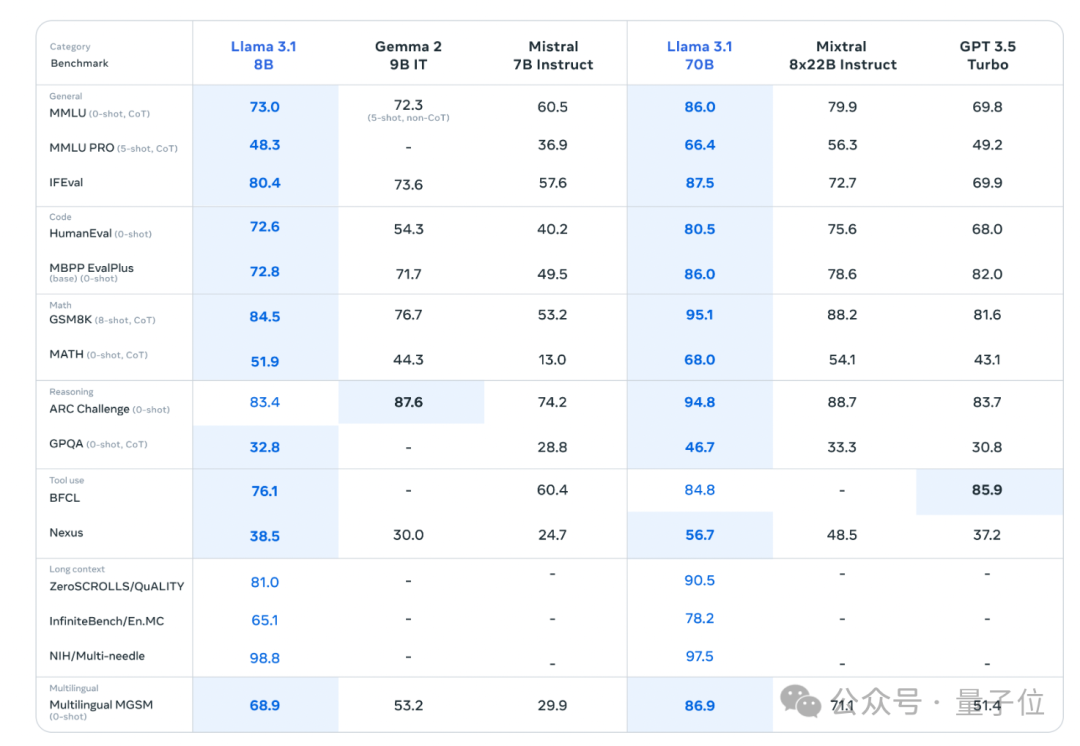
在150多个基准测试集中,405B版本的表现追平甚至超越了现有SOTA模型GPT-4o和Claude 3.5 Sonnet。
也就是说,这次,最强开源模型即最强模型。
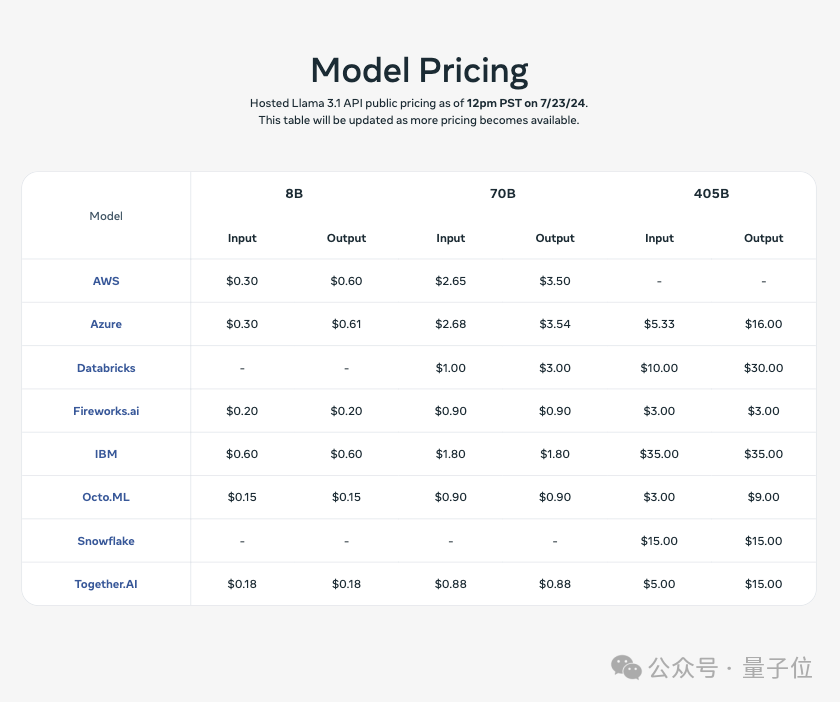
各大云厂商也在第一时间上线了的Llama 3.1的支持,价格是酱婶的:
LIama 3.1官方正式发布
首先来看模型能力。
Llama 3.1将上下文长度扩展到 128K、增加了对八种语言的支持。
其中超大杯405B版本,在常识、可操纵性、数学、工具使用和多语言翻译等能力方面都追平、超越了现有顶尖模型。
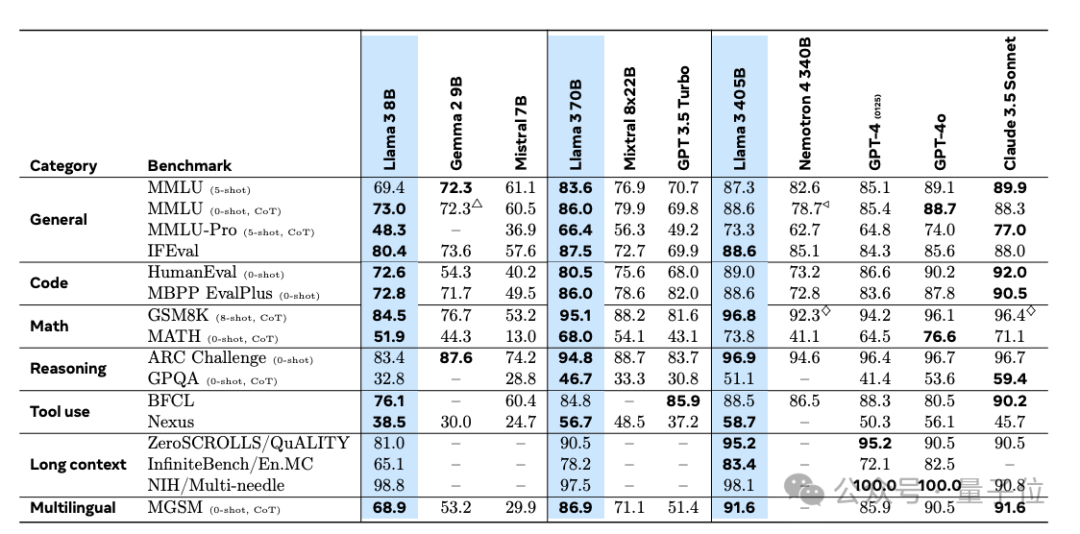
除此之外,也推出了8B和70B模型的升级版本,能力与同等参数下的顶尖模型基本持平。
再来看模型架构。
官方介绍,要在超15万亿个token上训练 Llama 3.1 405B模型挑战不小。
为此他们大幅优化了整个训练栈,并把模型算力规模首次扩展到了超过16000个H100 GPU。
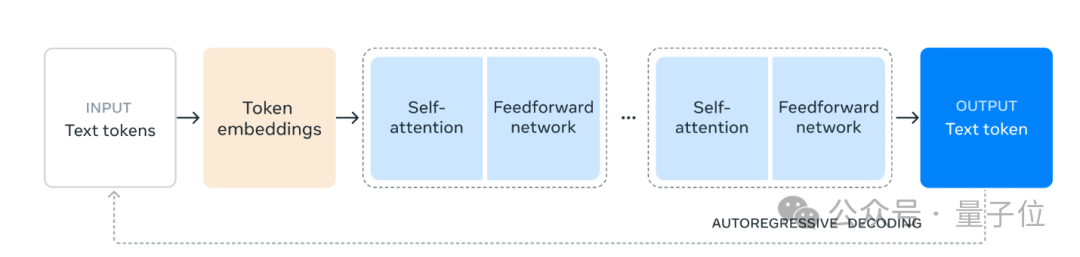
具体来说,还是采用标准的仅解码器的Transformer架构,并做一些细微改动;并采用迭代的post-traing流程,每轮都有SFT(监督微调)和DPO(直接偏好优化),以提高每个能力的性能。
与Llama以前的版本相比,他们提高了用于预训练和post-training数据的数量和质量。
而为了支持405B这样尺寸模型的大规模生产推理,Meta将模型从16位(BF16)量化到8位(FP8)数值,有效地降低了所需的计算需求,并允许模型在单个服务器节点内运行。
在指令微调方面,Meta还提高了模型对用户指令的响应能力、增强了它遵循详细指令的能力,同时保证安全性。
在post-training阶段,Meta在预训练模型的基础上进行多轮对齐。
每一轮都包括监督微调(Supervised Fine-Tuning, SFT)、拒绝采样(Rejection Sampling, RS)和直接偏好优化(Direct Preference Optimization, DPO)。
他们使用合成数据生成来绝大部分SFT示例,并数次迭代。
此外,还采用了多种数据处理技术来将这些合成数据过滤到最高质量。
总计15T tokens使用Llama 2模型做清理和过滤,而代码和数学相关的数据处理流水线则主要借鉴了Deepseek的方法。

除了最基本的根据提示词响应,Meta官方表示,任何普通开发者可以用它做些高级的事情,比如:
实时和批量推理
监督微调
针对特定应用评估模型
持续预训练
检索增强生成 (RAG)
函数调用
合成数据生成
而这背后也是由它的强大生态伙伴支持。

Datawhale发布Llama3.1 部署及微调教程
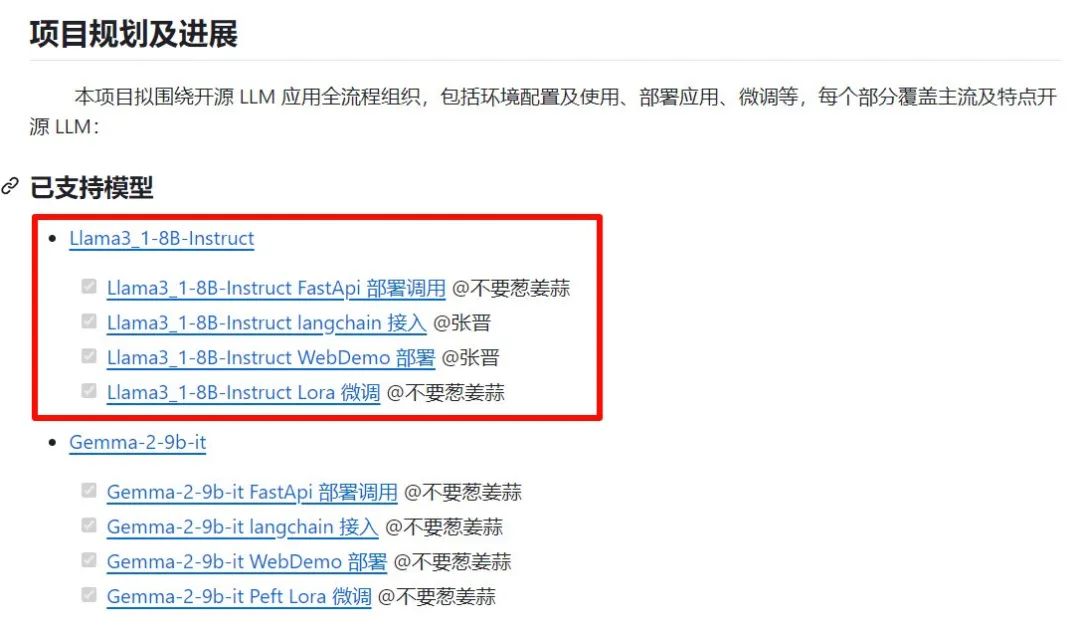
开源地址:https://github.com/datawhalechina/self-llm/tree/master/models/Llama3_1
参考链接:
[1]https://about.fb.com/news/2024/07/open-source-ai-is-the-path-forward/
[2]https://ai.meta.com/blog/meta-llama-3-1/


