
- 1【Python】解决Python报错:ImportError: dynamic module does not define module export function (PyInit_xxx)
- 2SQL Server中的命名管道(named pipe)及其使用_sqlserver named pipes
- 3SQL Server遍历表的几种方法_sql server 循环遍历数据库中的表
- 4产品经理如何有效的进行项目管理_产品经理做项目需要争取什么资源
- 5图片清晰度修复软件免费版,这几个分享给大家!_免费图片修复清晰度免费csdn
- 6S-安全基线-nginx加固_nginx基线加固
- 7hvv蓝初 看完可去 面试可用 面经
- 8如何实现简单的ip反爬
- 9JVM:常见的面试题和答案_jvm面试题总结及答案
- 10如何看待SD3 版本,和SDXL相比有何优势?_sd3和sdxl
【阿里YYDS】通义千问正式开源 Qwen2_qwen2-72b 上下文长度
赞
踩
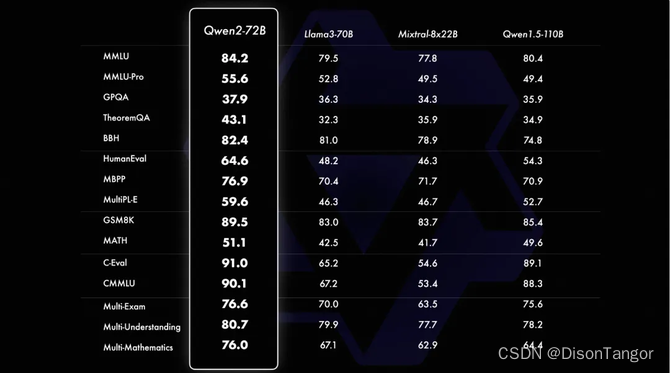
Qwen2–72B正式开源,性能全面超越开源模型Llama3-70B,也超过文心4.0、豆包pro、混元pro等众多中国闭源大模型。
在过去一段时间里,Qwen系列模型从Qwen1.5升级到Qwen2,Qwen2分5个尺寸,包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B。此次开源的Qwen2是阿里云最强模型,目前已经在Hugging Face和ModelScope上同步开源信息,用户可下载使用。Qwen2-72B上下文长度达到128K tokens,在自然语言理解、知识、代码、数学及多语言能力上均有出色表现。在基准测试中,可以匹敌Llama-3-70B-Instruct。
下载地址: https://modelscope.cn/organization/qwen
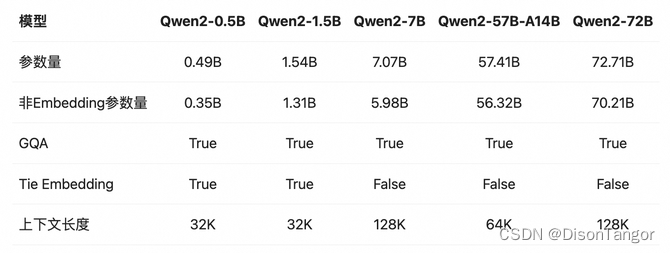
在Qwen1.5系列中,只有32B和110B的模型使用了GQA。这一次,所有尺寸的模型都使用了GQA,以便让大家体验到GQA带来的推理加速和显存占用降低的优势。针对小模型,由于embedding参数量较大,使用了tie embedding的方法让输入和输出层共享参数,增加非embedding参数的占比。并且不只在中英文中训练,还加入了27种语言的训练集。

指令
同时还推出了Instruct版本,而不是Chat版本。
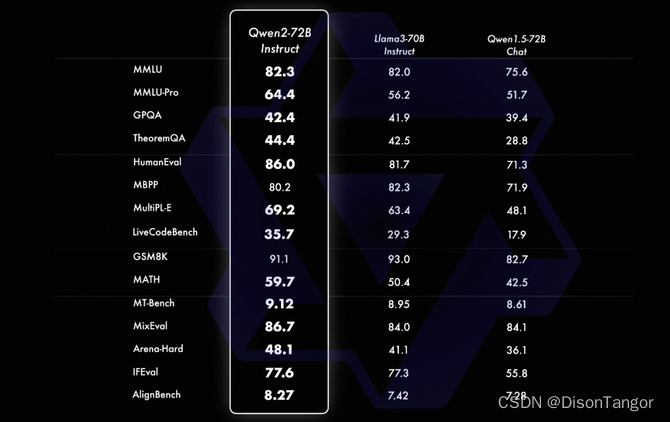
Qwen2-72B-Instruct在提升基础能力以及对齐人类价值观这两方面取得了较好的平衡。相比Qwen1.5的72B模型,Qwen2-72B-Instruct在所有评测中均大幅超越,并且了取得了匹敌Llama-3-70B-Instruct的表现。
而在小模型方面,Qwen2系列模型基本能够超越同等规模的最优开源模型甚至更大规模的模型。相比近期推出的最好的模型,Qwen2-7B-Instruct依然能在多个评测上取得显著的优势,尤其是代码及中文理解上。
代码 & 数学
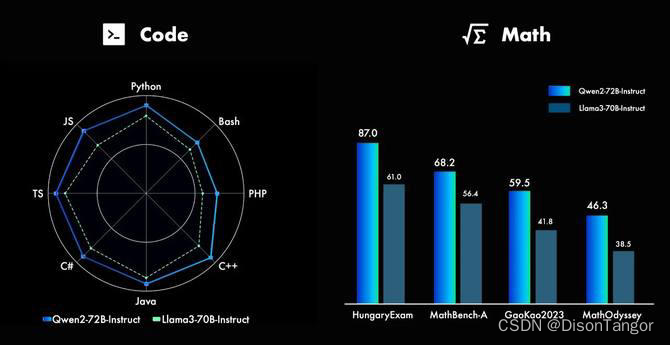
长上下文
Qwen2系列中的所有Instruct模型,均在32k上下文长度上进行训练,并通过YARN或Dual Chunk Attention等技术扩展至更长的上下文长度。
此外,Qwen2系列中的其他模型的表现也十分突出:Qwen2-7B-Instruct几乎完美地处理长达128k的上下文;Qwen2-57B-A14B-Instruct则能处理64k的上下文长度;而该系列中的两个较小模型则支持32k的上下文长度。
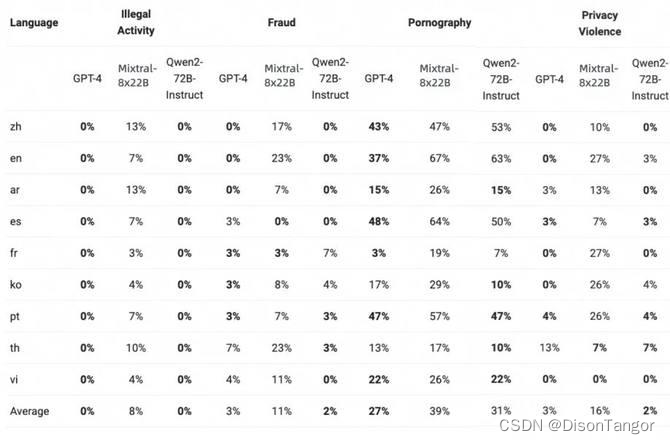
安全
下表展示了大型模型在四种多语言不安全查询类别(非法活动、欺诈、色情、隐私暴力)中生成有害响应的比例。测试数据来源于Jailbreak,并被翻译成多种语言进行评估。我们发现Llama-3在处理多语言提示方面表现不佳,因此没有将其纳入比较。通过显著性检验(P值),发现Qwen2-72B-Instruct模型在安全性方面与GPT-4的表现相当,并且显著优于Mixtral-8x22B模型。
开源运动的核心是科学的延伸。艾萨克·牛顿爵士写道:“如果我能看的更远,是因为我站在巨人的肩膀上。” 历史上最伟大的思想家之一承认,他对人类伟大理解的贡献不是来自他单一的天才,而是来自成千上万的伟大或渺小思想共同创造出的一个可以被他的特殊思想火花点燃并变化的世界。

