
- 1java 本地验证失败_java – 引起:org.postgresql.util.PSQLException:致命:用户“admin”的密码验证失败...
- 2如何优化一个运行缓慢的SQL查询?有哪些常见的优化技巧?_sql查询慢的优化步骤
- 3WARNING: Ignoring invalid distribution -ip 解决方案
- 4Mac install homebrew【mac 安装 homebrew 】
- 5【论文笔记】中文词向量论文综述(一)_文本向量化论文
- 6java毕业设计之医院预约挂号系统(ssm项目源码+LW+PPT)_免费源码javaee: ssm医院预约挂号及候诊管理系统
- 7html天气预报静态页面,天气预报_HTML静态页面_带读秒时钟
- 8C++:[STL]浅谈Allocator以及详解STL之sequence container的操作及使用(vector)_allocatortype
- 9移动机器人调度监控软件全面升级(三)_移动机器人调度系统
- 10C++ 11 nullptr 比 NULL 的优势比较
南京大学发布百万规模文本生成视频数据集OpenVid-1M
赞
踩
“巧妇难为无米之炊”,文生视频作为一个在AI中较为年轻的研究方向,由许多至关重要的问题还尚未解决,其中之一就是缺乏大规模高质量数据集,因此,最近南京大学提出了一个名为OpenVid-1M的大规模高质量数据集,它包含了100万个带有字幕的高质量视频片段。
除了数据集,他们还提出了一种新颖的多模态视频扩散Transformer(MVDiT),能够同时提取视觉标记和文本标记中的结构信息和语义信息。与以往主要关注视觉内容的DiT架构不同,MVDiT通过并行的视觉-文本架构增强文本和生成视频之间的一致性。其核心机制包括多模态自注意力模块、多模态时间注意力模块和多头交叉注意力模块,分别用于增强标记间的交互、确保时间一致性和融合文本语义信息。
论文标题:
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
论文链接:
https://arxiv.org/pdf/2407.02371

OpenVid-1M数据集
OpenVid-1M是一个精确的高质量数据集,包含超过100万个视频片段,每个视频分辨率至少为512x512,并附有详细的描述性字幕。该数据集的特点主要可以概括为:
1、小而美:相比于之前的同类数据集,WebVid-10M包含带水印的低质量视频,Panda-70M包含许多静态、闪烁、低清晰度的视频以及短字幕。而OpenVid-1M是一个去除了低质量视频的数据集,具有卓越的视频质量和富有表现力的字幕,规模更小但能对模型起到更好的训练效果。
2、更加高清:OpenVid-1M数据集中包含了43.3万个1080p视频片段,筛选构建的子集OpenVidHD-0.4M旨在推进高清视频生成的研究,而高清视频正是现实世界中视频呈现的主流形式。

一些数据集中的视频截图
OpenVid-1M数据集从ChronoMagic、CelebvHQ、Open-Sora-plan和Panda中筛选而来,由于Panda数据集比其他数据集大得多,因此下面详细介绍Panda-50M的数据过滤细节:
-
美学评分:视觉美学对于视频内容的满意度和愉悦感至关重要。为了增强文本生成视频的效果,论文使用LAION美学预测器过滤掉美学评分较低的视频。
-
时间一致性:相比于图像生成,文本生成视频任务更加复杂,但可以通过利用相邻视频帧的信息来提升质量。这些任务需要高视觉质量和时间一致性,因此时间一致性对于训练至关重要。论文使用CLIP提取视觉特征,通过研究相邻帧之间的余弦相似度来衡量时间一致性。论文过滤掉时间一致性得分较高(几乎静止)和得分较低(频繁闪烁)的视频片段。
-
运动差异:论文引入UniMatch来评估光流得分作为运动差异评分,选择运动平滑的视频。仅靠时间一致性得分不足以过滤掉包含高速运动对象的视频,因此论文保留光流得分适中的视频片段,以获得运动平滑的子集。
-
清晰度评估:高质量的视频对于文本生成视频任务至关重要。由于Panda-50M包含许多模糊片段,论文过滤掉清晰度较低的视频片段。
-
剪辑提取:在上述步骤之外,一些视频片段可能包含多个场景,因此论文引入级联剪切检测器来分割多场景片段,确保每个片段仅包含一个场景。
-
视频字幕:获取视频片段集后,论文使用大型多模态模型LLaVA-v1.6-34b为其重新生成字幕,创建表达性强的描述。由于CelebvHQ缺乏字幕,因此论文为其视频片段也提供了字幕。
下面给出了OpenVid-1M和Panda-50M在四个维度的数据质量对比:
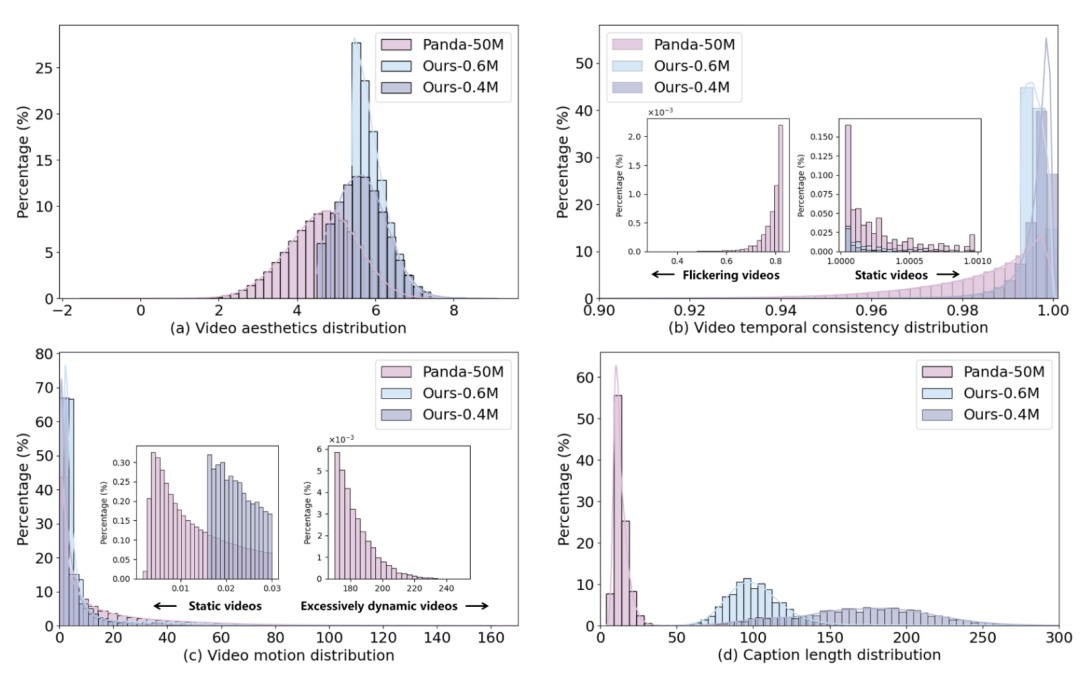
图中的abcd分别对应视频美学分布,视频运动分布,视频时间一致性分布和字幕长度分布,其中Ours-0.6M和Ours-0.4M分别是OpenVid-1M的两个从不同数据集中筛选出的子集。
多模态视频扩散Transformer(Multi-modal Video Diffusion Transformer,MVDiT)
如下图,MVDiT强调并行的视觉-文本结构,用于从视觉标记中提取结构信息和从文本标记中提取语义信息。每个MVDiT层包含四个步骤:视觉和语言特征的初步提取、集成新颖的多模态时间注意力模块以改善时间一致性、通过多模态自注意力和多头交叉注意力模块促进交互,然后传递到最终的前馈层。
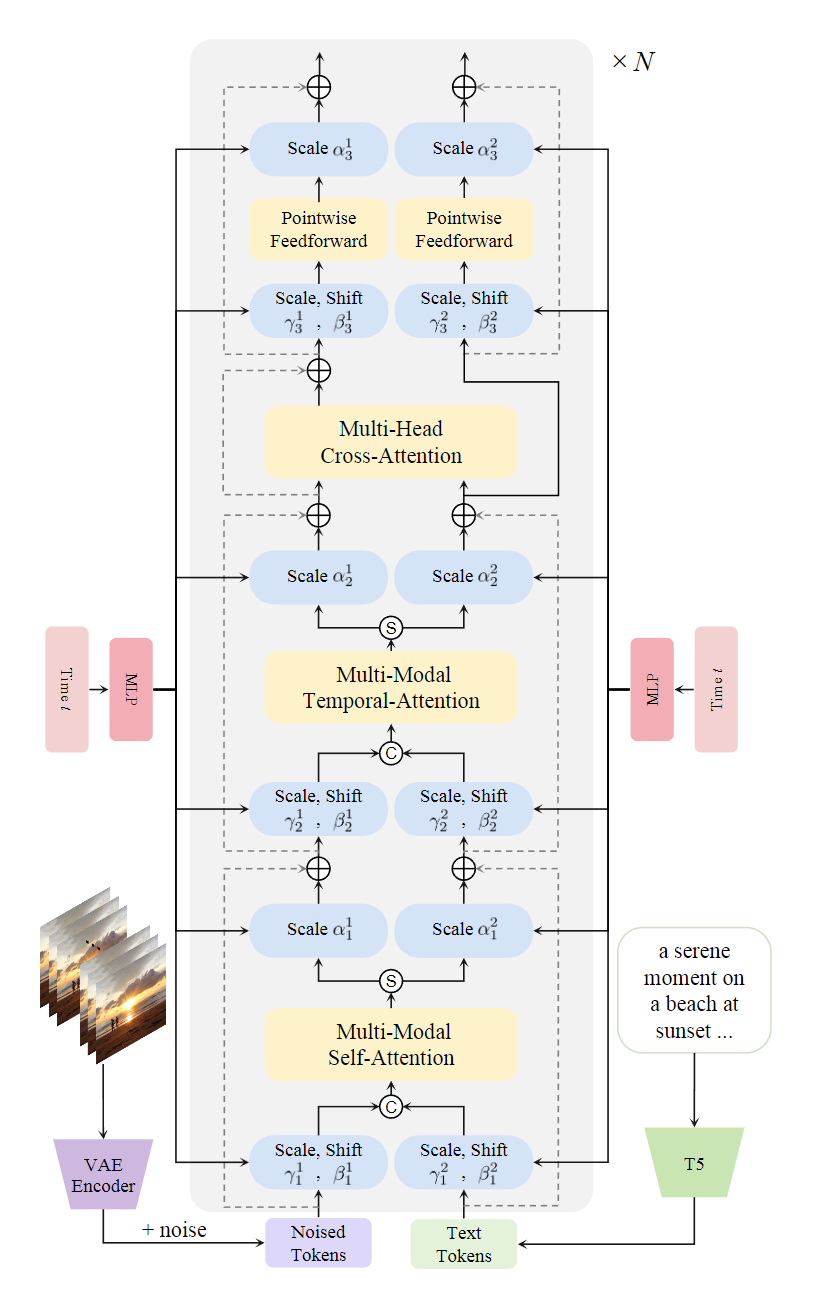
特征提取:给定一个视频片段,采用预训练的变分自编码器(VAE)将输入视频片段编码为潜在空间中的特征。在被噪声破坏后,获得的视频潜在特征输入到3D补丁嵌入器中以建模时间信息。然后,添加位置编码并将噪声视频潜在特征展平为补丁编码序列。将文本提示输入T5进行条件特征提取,并将文本编码嵌入到与视觉标记的通道维度匹配的文本标记中。最终,文本标记和噪声视觉标记作为MVDiT的输入。在训练过程中,文本编码器和视觉编码器均被冻结。
多模态自注意力模块:设计了一个多模态自注意力(MMSA)模块。文本标记在时间维度上重复多次以匹配视频帧。在文本和视觉分支中采用自适应层归一化,将时间步信息编码到模型中。然后,视觉标记与文本标记连接生成多模态特征,并输入到自注意力层中,促进每帧中视觉标记和文本标记之间的交互。分离出增强的视觉标记和文本标记,并应用维度缩放参数以优化Transformer块内的残差连接。
多模态时间注意力模块:在获得增强的视觉特征和文本特征后,构建多模态时间注意力(MMTA)模块,以高效捕捉时间信息。不同于先前的方法,此模块从文本和视觉特征中捕捉时间信息。将两个分支的标记连接起来,输入到时间注意力层中进行时间维度上的通信,使模型能够学习语义-结构的时间一致性,进一步提高视频质量。
多头交叉注意力模块:尽管多模态自注意力模块将视觉和文本标记结合在一起,文本生成视频(T2V)任务仍需要明确的过程将文本中的语义信息插入到视觉标记中。为此,采用交叉注意力层直接建立文本标记和视觉标记之间的通信。通过将视觉标记作为Query,文本标记作为Key和值Value,实现两者之间的交互,增强生成视频的语义信息。视觉标记和文本标记随后输入到前馈层中。由于一个MVDiT层能够同时更新视觉和文本标记,因此可以多次迭代这一过程,以实现更好的视频生成性能。经过多次迭代后,最终的视觉特征用于预测时间步的噪声和协方差。
实验效果显著
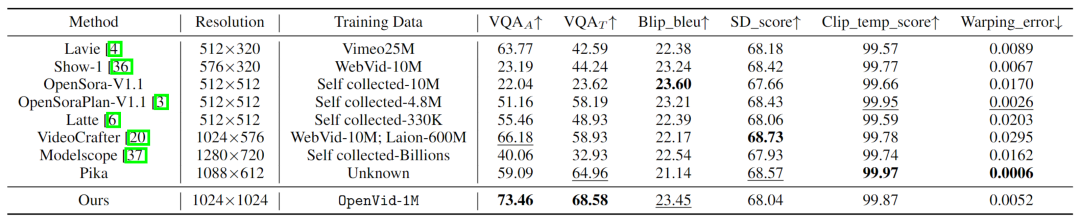
采用提出的OpenVid-1M数据集训练MVDiT模型与其他模型和数据集进行对比。评估模型基于视觉质量、文本与视频的对齐度及时间一致性,具体采用美学评分(VQAA)和技术评分(VQAT)评估视频质量。在输入文本和生成视频的一致性方面,采用图像-视频一致性(SD_score)和文本-文本一致性(Blip_bleu)进行评估。此外,还通过变形误差和语义一致性(Clip_temp_score)评估生成视频的时间一致性。
如表所示,OpenVid-1M和MVDiT显著优于其他方法。
从定性的角度分析以上结果,从下面的视频截图中可以看到,OpenVid-1M和MVDiT生成的图像更好看且符合文本描述。

此外,为了公平地比较不同的数据集,使用不同数据集训练OpenSora模型,在相同算力下,OpenVidHD-0.4M取得了最好的效果。

此外,如表所示的消融实验,在不同的模型、分辨率、训练数据以及不同的数据筛选方式下,证明了模型以及数据集每个步骤的必要性。


结语
通过对OpenVid-1M数据集和MVDiT模型的分析和评估,可以看出此项工作在文生视频领域做出的贡献:OpenVid-1M数据集为研究者提供了一个大规模且高质量的数据集,而MVDiT模型则提升了视频生成的质量和文本一致性。这回,不仅“巧妇有米下锅”,还把佳肴端回了餐桌。



