
- 1k8s核心知识总结
- 2【估计与数据融合】同步定位与地图构建 (SLAM)(Matlab代码实现)_slam matlab
- 3高等数学第一讲:函数极限与连续
- 4Hive 与 SQL 标准和主流 SQL DB 的语法区别_hive语言和sql
- 5node 生成随机头像_用这 13 个 App 做个一眼就能被人记住的头像
- 6策略梯度与ProximalPolicyOptimization_proximal policy optimization
- 7sheng的学习笔记-hive框架原理
- 8中国AI大比拼:盘点国内顶尖大模型,谁能称霸未来?_国内ai大模型哪个最好
- 9恭喜! 中移动智家中心入选2020年度ICT行业龙虎榜
- 10基于OPENCV的OCR身份证号识别技术_基于opencv的身份证号码识别
最全Windows环境单节点部署kafka最新版本3(1),终局之战_windows配置单节点kafka
赞
踩

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
zookeeper配置
zookeeper配置文件为zookeeper.properties,只需修改一处:
dataDir:zookeeper存储数据的路径,Windows环境路径要用D:\\kafka3.2.1\\datas这种形式
我遇到了Kafka异常重启后提示错误:The Cluster ID XXXXX doesn‘t match stored clusterId Some(XXXXX) in meta.properties.
但我没有找到这个meta.properties文件,查了半天原因是log.dirs路径配置的不对
测试
接下来进入测试阶段:
1. 启动zookeeper
先启动zookeeper,进入kafka安装根目录下,地址栏输入cmd,然后回车,注意启动之后不要关闭窗口。启动命令如下:
本地:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
服务器要用绝对路径: start cmd /k D:\kafka3.2.1\bin\windows\zookeeper-server-start.bat D:\kafka3.2.1\config\zookeeper.properties
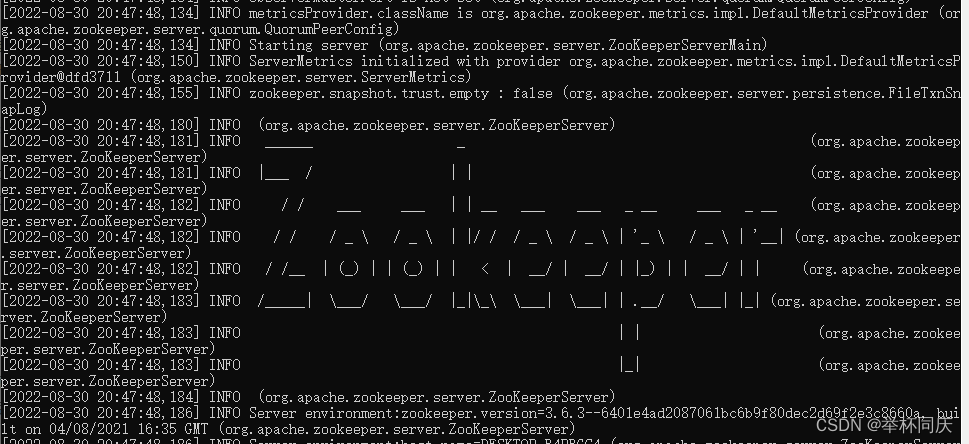
没有报错就可以了
2. 启动kafka服务端
同样进入kafka安装根目录下,地址栏输入cmd,然后回车,启动之后不要关闭窗口。启动命令如下:
启动kafka-server
本地:
.\bin\windows\kafka-server-start.bat .\config\server.properties
服务端:
start cmd /k “C:\EAMServer\kafka3.2.1\bin\windows\kafka-server-start.bat C:\EAMServer\kafka3.2.1\config\server.properties”
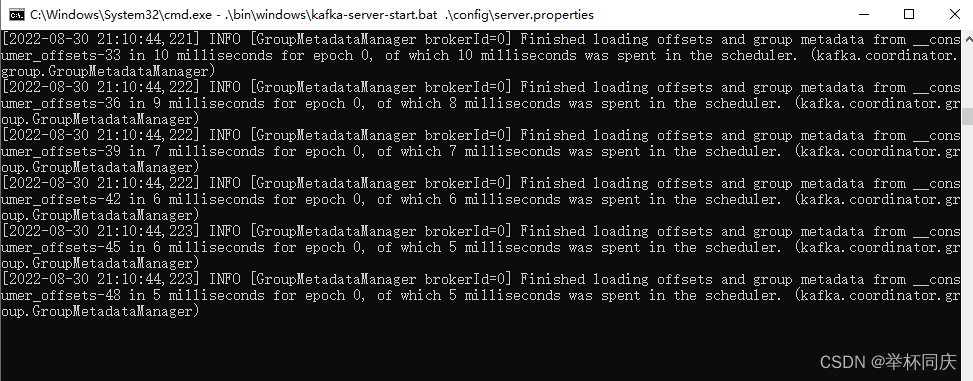
也是没有报错就算启动成功了,如果启动kafka失败,并出现以下异常,删除logs文件夹下的meta.properties文件即可。
The Cluster ID xxxx doesn’t match stored clusterId Some(finN2zUTRWaXMomXCknRew) in meta.properties. The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.
3. 创建kafka-topics
启动zookeeper和kafka服务端这两个命令窗口是必需的,这里通过脚本创建topic通常是用于本地测试kafka服务是否能正常发布和接收消息(新手可以用脚本创建一下测测,用Java实现发送消息可自动创建topic)
同样进入kafka安装根目录下,地址栏输入cmd,然后回车,启动之后不要关闭窗口。假设创建一个名字为test的topic命令如下:
start cmd /k .\bin\windows\kafka-topics.bat --create --bootstrap-server 10.0.102.132:9092 --replication-factor 1 --partitions 1 --topic test
- 1
- 2
这里有坑:新版的主题通过kafka服务端创建即可,也就是 --bootstrap-server这个地址,网上好多资料都是旧版的连接zookeeper创建的,在新版可能报错
–partitions 1意思是建立一个分区,–replication-factor 1是配置一个副本,因为本文讲的是单节点服务所以默认一个分区,集群可设置多个。启动之后,kafka-topics处于等待创建topic状态,一段时间内如果不createTopic,kafka-topics将自动断开
- 启动生产者
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
启动生产者之后就可以发送消息了
- 启动消费者
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test
启动消费者之后生产者发送的消息,消费者端就能收到了。
至此,消息队列kafka就安装完毕,完全可以通过命令行测试服务是否正常。
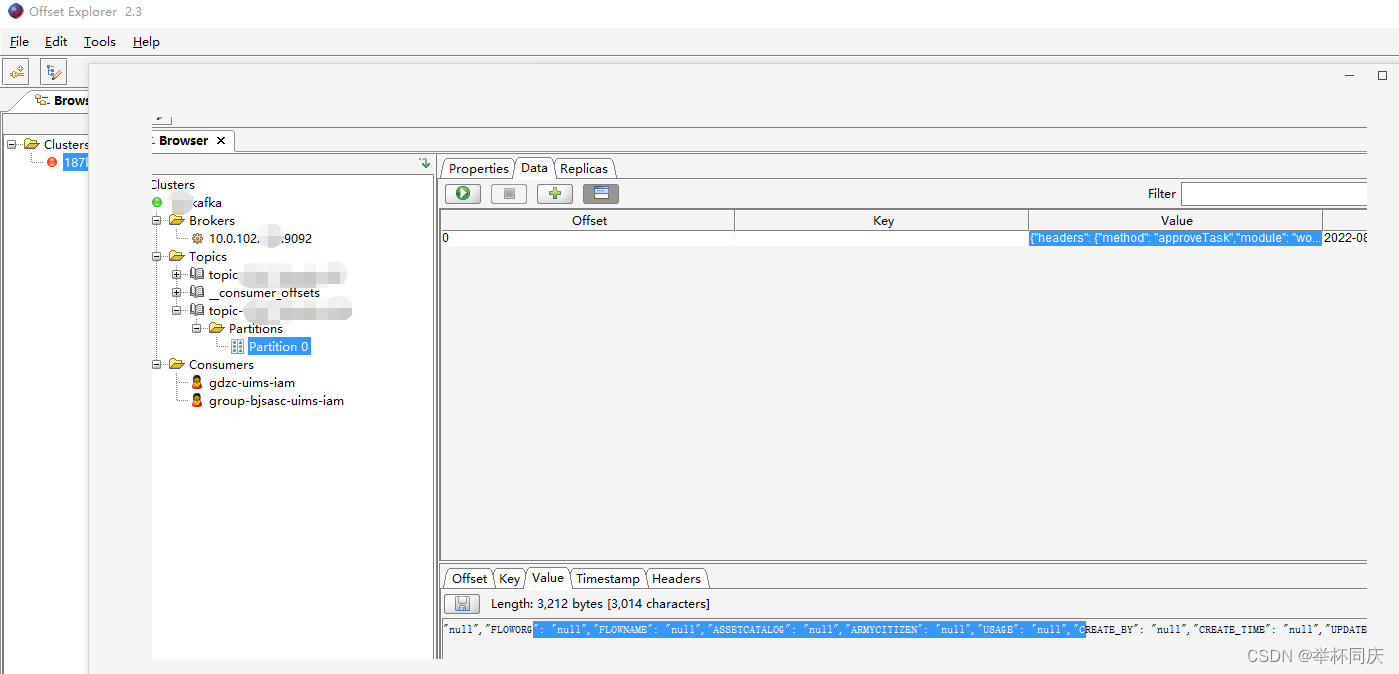
3 客户端工具 kafka Tool
我用的是kafka Tool,下载下来的软件名字是Offset Explorer 2.3
用客户端工具看所有的Topic和接收的消息内容非常直观,实乃开发利器。
4 项目实战
4.1 maven依赖
<!-- kafka 消息队列 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.2.1</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.2 配置文件
spring: kafka: bootstrap-servers: 10.0.102.132:9092 #指定kafka server的地址,集群配多个,中间,逗号隔开 producer: key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer consumer: group-id: am #群组ID # 指定默认消费者group id --> 由于在kafka中,同一组中的consumer不会读取到同一个消息,依靠groud.id设置组名 auto-offset-reset: earliest enable-auto-commit: true #如果'enable.auto.commit'为true,则消费者偏移自动提交给Kafka的频率(以毫秒为单位),默认值为5000。 auto-commit-interval: 1000 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4.3 生产者推送数据
发送数据代码非常简单,开发人员基本上就关注怎么组装消息报文就行了,消息发送就一行代码:
@Autowired KafkaTemplate kafkaTemplate; // 上面注入一个KafkaTemplate对象 ... // 组装JSONData kafkaTemplate.send(“test”, JSONData); // 直接用send方法,参数是topic名称和JSON报文数据,这行代码加到任何需要发送kafka消息的方法中    **既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!** **由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新** **[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)** 阶课程,涵盖了95%以上大数据知识点,真正体系化!** **由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新** **[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

