
- 1微信云开发基础_微信云开发技术
- 2密集检索:我们应该使用什么样的检索粒度?(如何提升召回率)_基于字符串长度和基于段落的切片需要搭配检索策略才能提升召回率
- 3git远程仓库使用方法/本地文件中的git仓库和远程git仓库(gitee中的)连接步骤_怎么设置本地文件链接git仓库
- 4Linux入门:Linux历史介绍_linux最早是由芬兰的一位研究生
- 5基于Python的旅游网站数据爬虫分析_爬取旅游网站数据并进行分析
- 6Inpaint如何去水印?Inpaint图片去水印教程_inpaint可以去除水印吗
- 7Unity XR Interaction Toolkit 踩坑记录
- 8【微信小程序知识点】获取微信昵称_微信小程序获取用户昵称
- 9Python项目-微信消息自动回复【附源码】_python自动回复微信消息
- 10【云原生】Docker部署Bitwarden
浙江大学发布全能多模态大模型OmniBind,刷榜13大benchmark
赞
踩
在人工智能快速发展的今天,多模态大模型成为了研究的热点。近日,浙江大学的研究团队在这一领域取得了重大突破,发布了名为OmniBind的全能多模态大模型。这个模型不仅支持3D、音频、图像和文本等多种模态的输入,还在13个主要评测基准上取得了领先成绩,展现出了强大的综合能力。
OmniBind的创新之处在于它采用了"空间绑定"的方法,巧妙地整合了14个现有的专业模型的知识,使得模型参数规模达到了70亿到300亿不等。研究团队还设计了独特的权重路由策略,有效地融合了不同来源的知识。这种方法不仅大大提高了模型的性能,还极大地降低了训练成本。
值得注意的是,OmniBind展现出了多项新颖的应用可能,包括跨模态检索、目标定位和音频分离等。这些成果为多模态人工智能的未来发展开辟了新的方向,也为各种实际应用提供了可能性。
接下来,让我们一起深入了解这个突破性的研究,看看OmniBind是如何改变多模态大模型领域的格局的吧。

论文标题:
OmniBind: Large-scale Omni Multimodal Representation via Binding Spaces
论文链接:
https://arxiv.org/pdf/2407.11895
多模态大模型界的"全能学霸"
在人工智能的世界里,我们一直在追求一个"全能选手"的梦想。想象一下,如果有一个AI系统,它能同时理解文字、图像、声音,甚至3D物体,那会是多么令人兴奋的事情!这就是多模态AI的终极目标。然而,现实情况却不那么理想。目前,大多数多模态模型都是"双模态专家",它们只擅长处理两种类型的数据,比如图像-文本、音频-文本或3D-图像-文本的组合。这些模型就像是各个领域的专家,在自己的专长领域表现出色,但很难应对更复杂的场景。
一些研究者开始尝试将三种模态结合起来,比如音频-图像-文本模型。这些模型迈出了重要的一步,但仍然无法覆盖所有可能的模态组合。即使是那些支持多种模态的模型,其规模也往往相对较小,这限制了它们处理复杂任务的能力。面对这种情况,研究者们不禁要问:我们能不能打造一个真正的"全能选手"?一个能够灵活处理3D、音频、图像和文本等多种模态,并且在各种任务中都表现出色的多模态大模型?
这正是浙江大学研究团队提出OmniBind的初衷。OmniBind的目标是成为一个大规模的全能多模态表示模型,它不仅要支持多种模态的输入,还要在各种跨模态任务中都能表现出色。研究团队面临的主要挑战包括如何有效整合不同模态的知识,如何在保证性能的同时控制训练成本,以及如何确保模型在各种模态组合中都能表现出色。
OmniBind通过创新的"空间绑定"和"权重路由"方法,巧妙地解决了这些问题。它就像是一个多模态世界的"学霸",不仅吸收了各个领域专家的知识,还能灵活运用这些知识来解决各种复杂问题。从专业模型到通用模型,从双模态到多模态,OmniBind展示了大模型从专家到通才的进化过程。
OmniBind不仅在13个主要评测基准上取得了领先成绩,还展现出了许多令人惊喜的新应用可能,为多模态大模型的未来发展开辟了新的方向。接下来,让我们一起深入了解OmniBind是如何实现这一"全能梦想"的,以及它在实际应用中展现出的惊人能力。
空间绑定与权重路由
OmniBind的核心创新在于其独特的空间绑定和权重路由方法。这种方法巧妙地整合了多个专业模型的知识,形成了一个真正的全能型多模态系统。
下图展示了OmniBind的整体概览。这张图清晰地展示了OmniBind如何整合来自不同预训练模型的多样化知识,形成大规模的全能表示。OmniBind能够处理3D、音频、图像和文本等多种输入模态,并在各种下游任务中展现出色的性能。
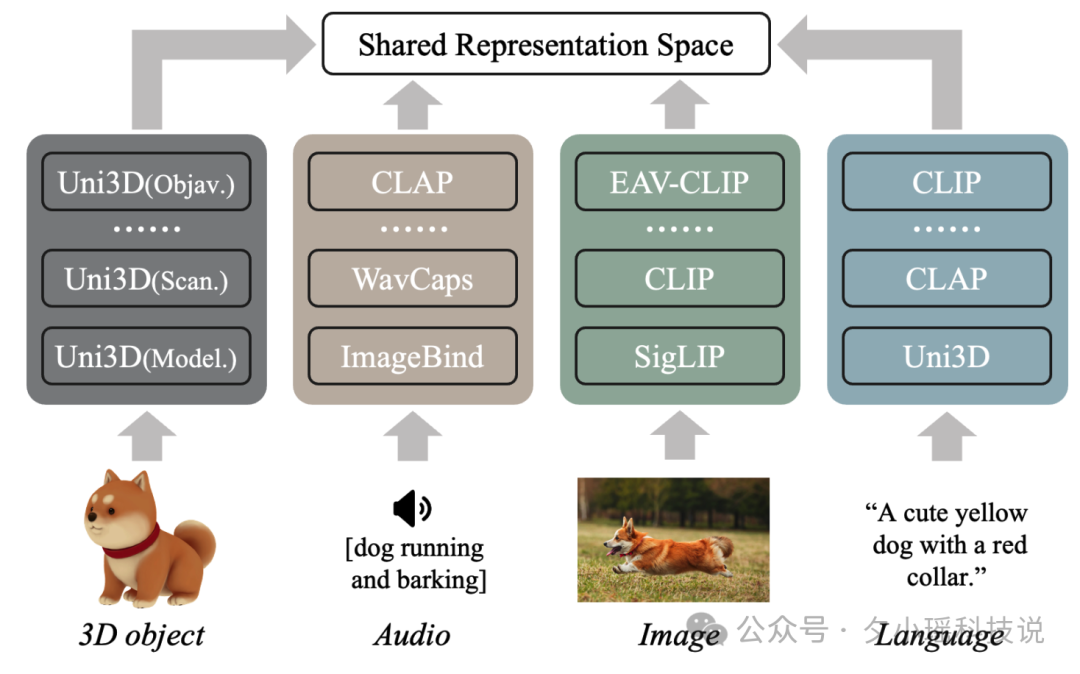
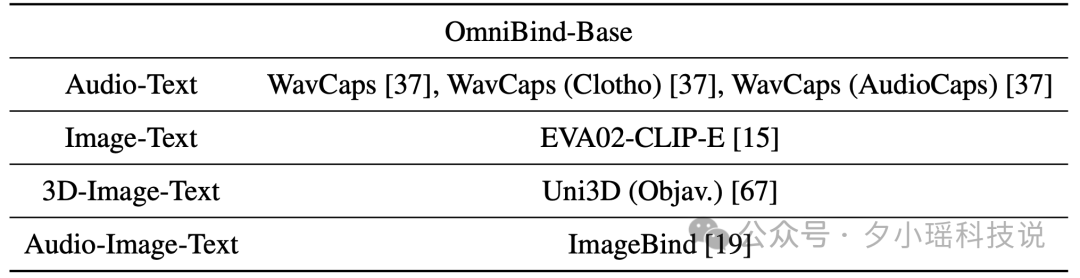
OmniBind采用了"空间绑定"的策略。研究团队精心选择了14个在不同模态组合中表现优秀的预训练模型,包括5个音频-文本模型、5个图像-文本模型、3个3D-图像-文本模型和1个音频-图像-文本模型。文章中详细列出了用于构建OmniBind-Base、OmniBind-Large和OmniBind-Full的源空间,研究人员使用更多的预训练模型构建出更大的多模态模型。


空间绑定的过程可以想象成一场大型的"知识融合派对"。研究团队首先收集了大量未配对的3D点云、音频、图像和文本数据,然后使用最先进的检索模型为这些数据建立伪配对关系。通过训练简单的投影器,研究团队将每个专业模型的知识空间"绑定"到一个统一的表示空间中。
然而,仅仅将不同模型的知识空间简单组合还不够。下图展示了OmniBind的核心架构,其中包括了创新性的权重路由策略。这个策略的核心是为每个模态设计一个"路由器",它能够根据当前的问题动态决定应该让哪些专家发言,以及每个专家的发言应该占多大的权重。这种路由机制和混合专家模型(MoE)极其相似,通过设置简单的路由机制从而提升整体模型的表现。
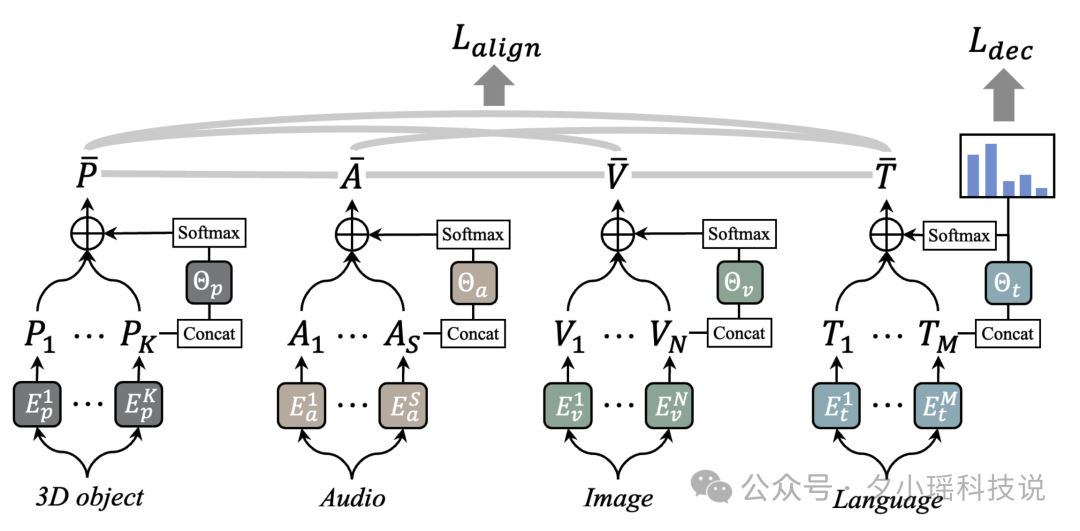
具体而言,OmniBind的输入由3D点云、音频、图像和文本四种不同的数据类型组成。每种数据类型首先通过各自专门的编码器进行处理,随后经过相应的路由器进行权重分配。最终,所有处理后的信息汇聚到一个统一的表示空间中。这个过程堪比一个高效的团队合作,其中每个专业模型都贡献自己的专长,而路由器则扮演着协调者的角色,确保每个"专家"的意见都能得到恰当的重视。这种设计不仅实现了多模态信息的有效融合,还保证了在处理不同类型任务时能够灵活调整各个模态的重要性。
空间绑定过程首先涉及到伪配对数据的构建。研究团队使用最先进的检索模型为未配对的单模态数据建立伪配对关系,形成 的数据结构,其中 、、、 分别代表3D点云、音频、图像和文本数据。
接下来,通过训练简单的投影器将每个专业模型的知识空间"绑定"到统一表示空间中。以CLAP模型绑定到EVA-CLIP-18B为例,其目标函数公式为:
其中, 和 是CLAP的音频和文本嵌入, 和 是EVA-CLIP-18B的图像和文本嵌入, 是多层感知机投影器。 是多模态对比损失函数:
绑定所有不同空间后,形成了一个包含 个3D点编码器、 个音频编码器、 个图像编码器和 个文本编码器的混合模型。最终表示的计算公式为:
其中 、、、 是每个编码器的组合因子。
为了智能融合不同来源的知识,研究团队创新性地提出了权重路由策略。具体而言,每个模态都有一个路由器,用于预测该模态编码器的组合因子:
其中 、、、 分别是3D点、音频、图像和语言的路由器。
路由器的训练有两个主要目标:跨模态整体对齐和语言表示解耦。跨模态整体对齐的损失函数平均了所有模态对之间的对比损失:
语言表示解耦的损失函数鼓励语言路由器识别输入文本最可能描述的模态,并优先选择相应的专门文本编码器:
最终的损失函数由以上两个损失函数的线性组合构成:
通过这种方法,OmniBind不仅成功地整合了不同模型的知识,还大大降低了训练成本,OmniBind的三个变体(Base、Large和Full)的参数规模分别达到了7.2B、12.3B和30.6B,展示了模型的强大容量。
这种创新方法开创了一种新的思路:通过智能整合现有的专业知识,我们可以构建出更加强大、更加通用的多模态大模型。
实验结果
OmniBind在多项实验中展现出了卓越的性能,证明了其作为全能多模态模型的实力。研究团队设计了一系列全面的实验,涵盖了跨模态检索和零样本分类等多个任务,以评估模型的性能。
下表详细列出了评估任务和基准数据集的统计信息。这些任务包括音频、图像和3D的零样本分类,以及音频-文本、音频-图像、图像-文本和3D-图像的跨模态检索。评估使用了13个不同的基准数据集,涵盖了7个下游任务,充分展示了OmniBind的多样化能力。

在跨模态检索任务中,OmniBind-Full和OmniBind-Large在所有基准测试中始终优于之前的方法。特别值得注意的是,OmniBind在音频-图像和3D-图像对齐方面甚至超越了专门针对这些任务训练的模型,展现出了强大的知识迁移能力。例如,在VGG-SS数据集上的音频-图像检索任务中,OmniBind-Full的R@1指标达到了15.64%,超过了之前最好的结果14.82%。
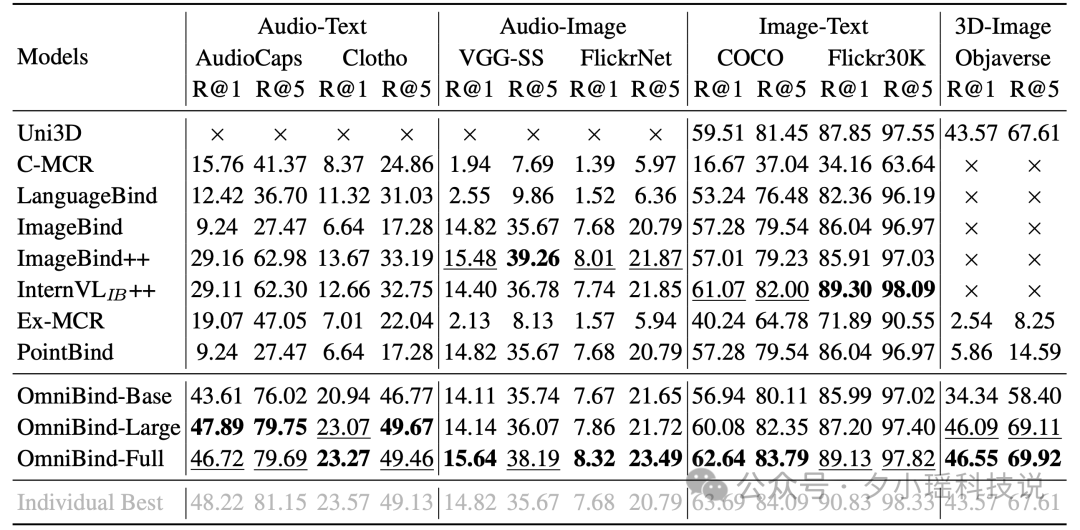
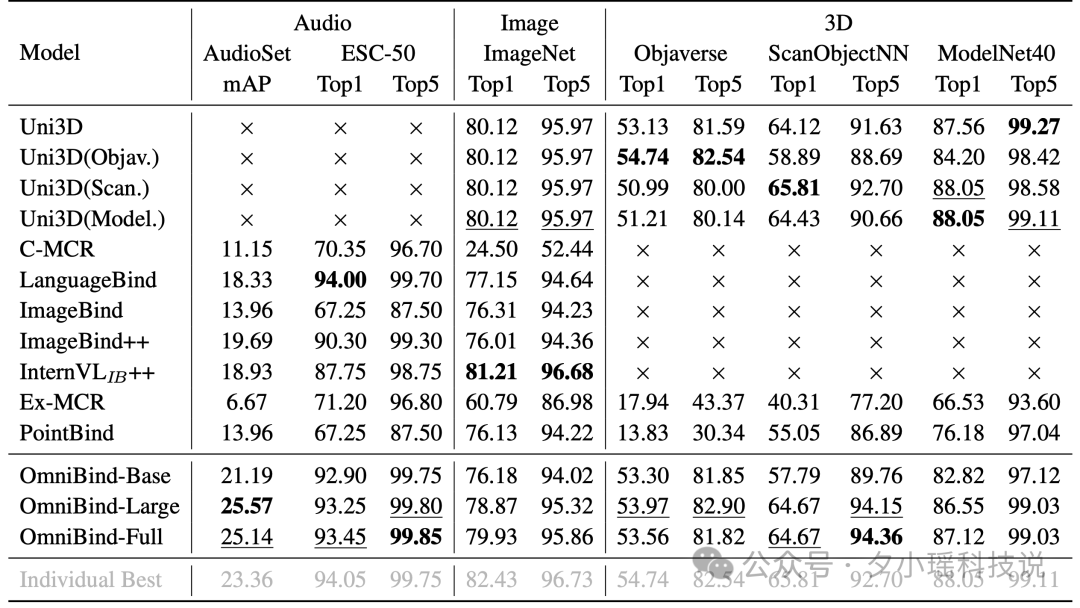
OmniBind在音频分类任务中表现尤为出色,在AudioSet数据集上的mAP达到了25.14%,远超其他多模态模型。在图像分类任务中,尽管有专门的模型表现略好,但OmniBind-Full在ImageNet上仍然取得了79.93%的Top1准确率,展现了强大的竞争力。在3D物体分类任务中,OmniBind-Large和OmniBind-Full展现出了优秀的泛化能力,在多个数据集上都取得了接近或超过专门模型的性能。
下图展示了OmniBind在音频到3D物体检索任务中的表现。这些可视化结果清晰地展示了OmniBind对不同模态之间语义关系的深刻理解。例如,OmniBind能准确地将"猫咪呼噜声"的音频与3D猫咪模型对应起来,而在"时钟滴答声"的案例中,OmniBind成功识别出机械钟的3D模型,而其他模型如PointBind和Ex-MCR则难以区分盘状的3D模型。


除此之外,文章中还展示了OmniBind的多项新颖应用,包括任意模态查询的目标定位、任意模态查询的音频分离,以及复杂的组合理解。这些应用充分展示了OmniBind作为统一多模态表示模型的潜力。例如,在任意模态查询的目标定位任务中,OmniBind可以使用声音或3D模型来定位图像中的物体,展现了其跨模态理解能力。

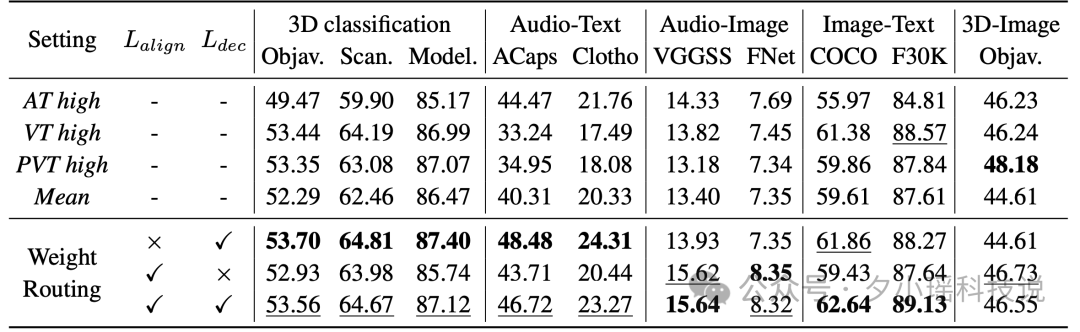
研究人员同时还进行了权重路由策略的消融实验。结果表明,与手动设置权重相比,使用权重路由策略能够在各种任务中取得更全面的性能提升。特别是结合跨模态对齐目标(L_align)和语言表示解耦目标(L_dec)时,模型在各个模态组合中都表现出最佳性能。
这些实验结果充分展示了OmniBind在标准评估任务和创新应用场景中的卓越表现。通过成功实现多种模态的统一表示,OmniBind不仅在复杂的跨模态任务中提供了强大支持,还为多模态大模型领域开辟了新的研究方向。
总结与展望
浙江大学研究团队发布的全能多模态大模型OmniBind在多模态大模型领域取得了重大突破。通过创新的空间绑定和权重路由方法,OmniBind成功整合了14个现有专业模型的知识,构建了一个真正的全能型多模态大模型。这个模型不仅支持3D、音频、图像和文本等多种模态的输入,还在13个主要评测基准上取得了领先成绩,展现出了强大的综合能力。
OmniBind展示了许多令人兴奋的应用潜力,包括音频到3D物体的检索、任意模态查询的目标定位、任意模态查询的音频分离,以及复杂的组合理解。这些应用不仅展示了OmniBind的多样性,也为未来的多模态大模型应用开辟了新的可能性。未来的研究可能会聚焦于进一步扩大模型规模,增加支持的模态类型,以及探索OmniBind在更多下游任务中的应用。

