
- 1Canvas详解(android自定义view,onDraw()绘制各种图形)_canvas draw
- 2MCU实现I2C通信_新唐mcu的i2c总线
- 3openai DALL-E 3 论文 提升图像生成的关键:更好的图像描述_dall-e3论文解读
- 4《数据库系统概论》知识整理——第1章 绪论_数据库系统概述系统篇
- 5【Python】堆(heap)的基本操作_heapreplace
- 611个问题,帮你彻底搞懂工业互联网
- 7搭建Hadoop报错汇总(那些曾经踩过的坑)_hdfs namenode -format bash: hdfs: command not foun
- 8鸿蒙轻内核A核源码分析系列七 进程管理 (1)
- 9android studio修改项目包名_android studio 更换包名
- 10hdfs基础操作(命令行和java代码)_头哥hdfs基本操作代码
昇思25天学习打卡营第六天|函数式自动微分
赞
踩
昇思25天学习打卡营第六天,继续坚持。今天的学习内容是函数式微分,记录一下:
学习内容
神经网络的训练主要使用反向传播算法,模型预测值(logits)与正确标签(label)送入损失函数(loss function)获得loss,然后进行反向传播计算,求得梯度(gradients),最终更新至模型参数(parameters)。自动微分能够计算可导函数在某点处的导数值,是反向传播算法的一般化。自动微分主要解决的问题是将一个复杂的数学运算分解为一系列简单的基本运算,该功能对用户屏蔽了大量的求导细节和过程,大大降低了框架的使用门槛。
MindSpore使用函数式自动微分的设计理念,提供更接近于数学语义的自动微分接口grad和value_and_grad。下面我们使用一个简单的单层线性变换模型进行介绍。
函数与计算图
计算图是用图论语言表示数学函数的一种方式,也是深度学习框架表达神经网络模型的统一方法。我们将根据下面的计算图构造计算函数和神经网络。
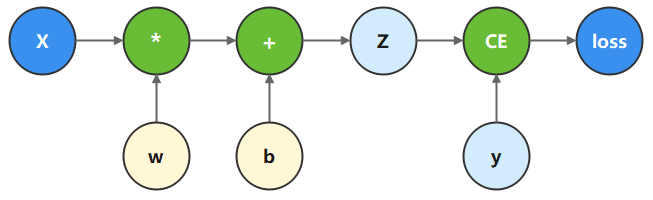
微分函数与梯度计算
为了优化模型参数,需要求参数对loss的导数:
∂
loss
∂
w
\frac{\partial \operatorname{loss}}{\partial w}
∂w∂loss和
∂
loss
∂
b
\frac{\partial \operatorname{loss}}{\partial b}
∂b∂loss,此时我们调用mindspore.grad函数,来获得function的微分函数。
这里使用了grad函数的两个入参,分别为:
fn:待求导的函数。grad_position:指定求导输入位置的索引。
由于我们对
w
w
w和
b
b
b求导,因此配置其在function入参对应的位置(2, 3)。
使用
grad获得微分函数是一种函数变换,即输入为函数,输出也为函数。
Stop Gradient
通常情况下,求导时会求loss对参数的导数,因此函数的输出只有loss一项。当我们希望函数输出多项时,微分函数会求所有输出项对参数的导数。此时如果想实现对某个输出项的梯度截断,或消除某个Tensor对梯度的影响,需要用到Stop Gradient操作。
这里我们将function改为同时输出loss和z的function_with_logits,获得微分函数并执行。
Auxiliary data
Auxiliary data意为辅助数据,是函数除第一个输出项外的其他输出。通常我们会将函数的loss设置为函数的第一个输出,其他的输出即为辅助数据。
grad和value_and_grad提供has_aux参数,当其设置为True时,可以自动实现前文手动添加stop_gradient的功能,满足返回辅助数据的同时不影响梯度计算的效果。
下面仍使用function_with_logits,配置has_aux=True,并执行。
神经网络梯度计算
前述章节主要根据计算图对应的函数介绍了MindSpore的函数式自动微分,但我们的神经网络构造是继承自面向对象编程范式的nn.Cell。接下来我们通过Cell构造同样的神经网络,利用函数式自动微分来实现反向传播。
首先我们继承nn.Cell构造单层线性变换神经网络。这里我们直接使用前文的
w
w
w、
b
b
b作为模型参数,使用mindspore.Parameter进行包装后,作为内部属性,并在construct内实现相同的Tensor操作。
总结
为了理解这一节,我复习了大学的微积分课程。大家也要一起加油啊


