
- 1【最全合集】2022、2023年全国青少年信息素养大赛Python初赛、省赛、国赛详细解析_2023信息素养大赛决赛题
- 2跋山涉水 —— 深入 Redis 字典遍历_redis iterator
- 3微信小程序|小程序的构成(初识小程序详细简介)_微信小程序的组成
- 4MySql多条件查询包含or,and条件会失效_mysql and 和or 一起用不起作用
- 5堆建立的不同方式的时间复杂度_建堆时间复杂度怎么推导
- 6web前端常用命令
- 7区块链 之 默克尔树_区块链中的moketree
- 8从零开始学数据结构系列之第三章《二叉树链式结构及实现4》
- 9开发者分享:20个关于Unity使用建议和技巧
- 10HDFS介绍及基本命令操作_第1关:hdfs的基本操作 csdn
2024年最全Python爬虫实战 爬取网络中的小说_手机怎么爬虫晋江做txt_python爬小说
赞
踩
■ 图5-2ChromeDriver的下载页面
之后,使用**selenium.webdriver.Chrome(path_of_chromedriver)**语句可创建Chrome浏览器对象,其中path_of_chromedriver就是下载的ChromeDriver的路径。
在脚本中,用户可以定义一个名为NovelSpider的爬虫类,使用小说的“全部章节”页面URL进行初始化(类似于C语言中的“构造”),同时它还拥有一个list属性,其中将会存放各个章节的URL。类方法如下。
- get_page_urls():从全部章节页面抓取各个章节的URL。
- get_novel_name():从全部章节页面抓取当前小说的书名。
- text_to_txt():将各个章节中的文字内容保存到TXT文件中。
- looping_crawl():循环抓取。
思路梳理完毕后就可以着手编写程序了,最终的爬虫代码见例5-1。
**【例5-1】**网络小说的爬取程序。

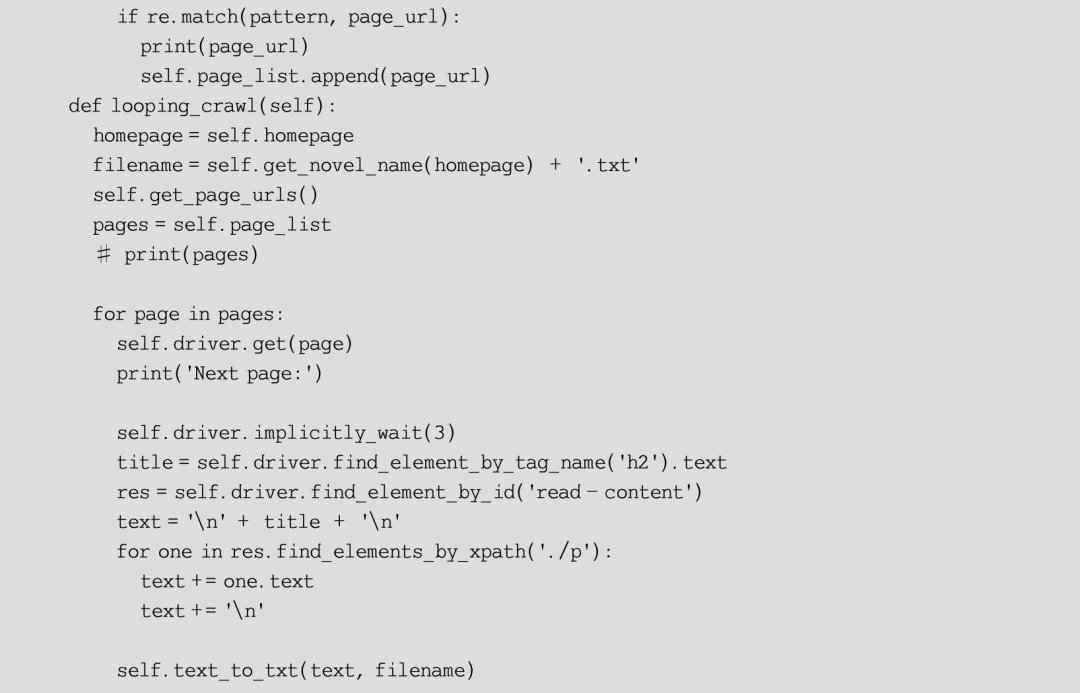


__init__()和__del__()方法可以视为构造函数和析构函数,分别在对象被创建和被销毁时执行。在__init__()中使用一个URL字符串进行了初始化,而在__del__()方法中退出了Selenium浏览器。
try-except语句执行主体部分并尝试捕获WebDriverException异常(这也是Selenium运行时最常见的异常类型)。在lopping_crawl()方法中则分别调用了上述其他几个方法。
driver.save_screenshot()方法是selenium.webdriver中保存浏览器当前窗口截图的方法。
driver.implicitly_wait()方法是Selenium中的隐式等待,它设置了一个最长等待时间,如果在规定的时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后再执行下一步。
提示
显式等待会等待一个确定的条件触发然后才进行下一步,可以结合ExpectedCondition共同使用,支持自定义各种判定条件。隐式等待在编写时只需要一行,所以编写十分方便,其作用范围是WebDriver对象实例的整个生命周期,会让一个正常响应的应用的测试变慢,导致整个测试执行的时间变长。
**driver.find_elements_by_tag_name()**是Selenium用来定位元素的诸多方法之一,所有定位单个元素的方法如下。
- find_element_by_id():根据元素的id属性来定位,返回第一个id属性匹配的元素;如果没有元素匹配,会抛出NoSuchElementException异常。
- find_element_by_name():根据元素的name属性来定位,返回第一个name属性匹配的元素;如果没有元素匹配,则抛出NoSuchElementException异常。
- find_element_by_xpath():根据XPath表达式定位。
- find_element_by_link_text():用链接文本定位超链接。该方法还有子串匹配版本find_element_by_partial_link_text()。
- find_element_by_tag_name():使用HTML标签名来定位。
- find_element_by_class_name():使用class定位。
- find_element_by_css_selector():根据CSS选择器定位。
寻找多个元素的方法名只是将element变为复数elements,并返回一个寻找的结果(列表),其余和上述方法一致。在定位到元素之后,可以使用text()和get_attribute()方法获取其中的文本或各个属性。

这行代码使用get_attribute()方法来获取定位到的各章节的URL地址。在以上程序中还使用了re(Python的正则模块)中的re.match()方法,根据正则表达式来匹配page_url。形如:
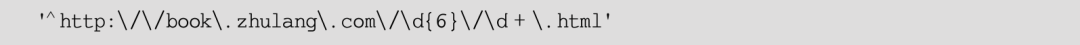
这样的正则表达式所匹配的是下面这样一种字符串:

其中,A部分必须是6个数字,B部分必须是一个以上的数字。这也正好是小说各个章节页面的URL形式,只有符合这个形式的URL链接才会被加入page_list中。
re模块的常用函数如下。
- compile():编译正则表达式,生成一个Pattern对象。之后就可以利用Pattern的一系列方法对文本进行匹配/查找(当然,匹配/查找函数也支持直接将Pattern表达式作为参数)。
- match():用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回。
- search():用于查找字符串的任何位置,只要找到了一个匹配的结果就返回。
- findall():以列表形式返回能匹配的全部子串,如果没有匹配,则返回一个空列表。
- finditer():搜索整个字符串,获得所有匹配的结果。与findall()的一大区别是,它返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
- split():按照能够匹配的子串将字符串分割后返回一个结果列表。
- sub():用于替换,将母串中被匹配的部分使用特定的字符串替换掉。
提示
正则表达式在计算机领域中应用广泛,读者有必要好好了解一下它的语法
在looping_crawl()方法中分别使用了get_novel_name()获取书名并转换为TXT文件名,get_page_urls()获取章节页面的列表,text_to_txt()保存抓取到的正文内容。在这之间还大量使用了各类元素定位方法(如上文所述)。
03 运行并查看TXT文件
这里选取一个小说——逐浪小说网的《绝世神通》,运行脚本并输入其章节列表页面的URL,可以看到控制台中程序成功运行时的输出,如图5-3所示。

■ 图5-3小说爬虫的输出
抓取结束后,用户可以发现目录下多出一个名为“screenshot.png”的图片(见图5-4)和一个“绝世神通.txt”文件(见图5-5),小说《绝世神通》的正文内容(按章节顺序)已经成功保存。
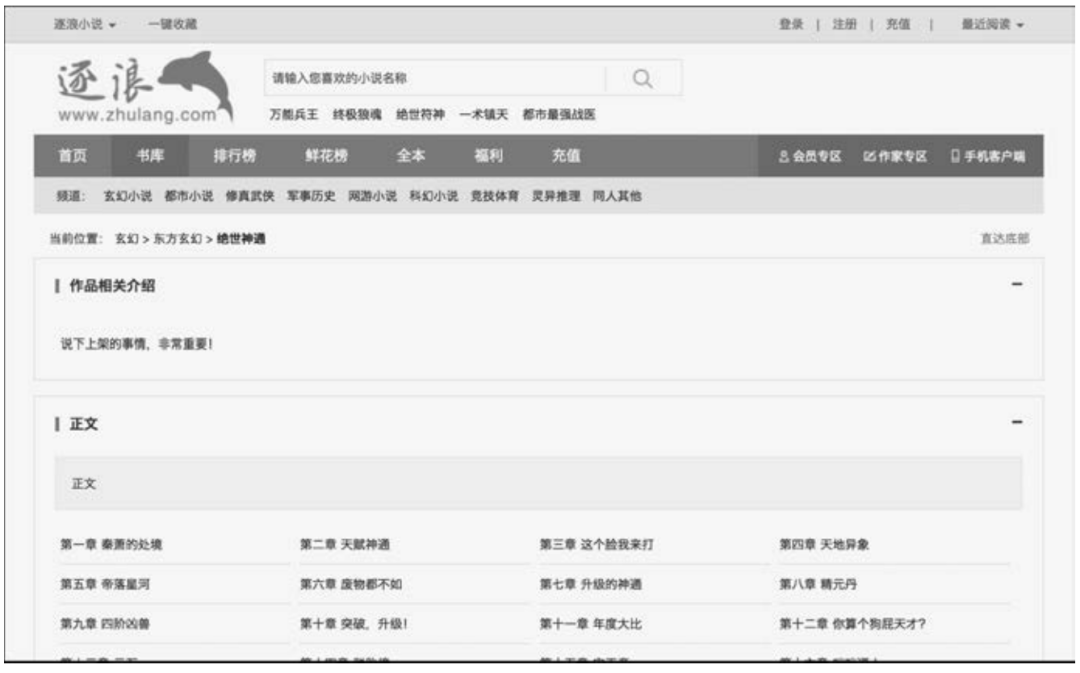
■ 图5-4逐浪小说网的屏幕截图

■ 图5-5小说的部分内容
程序圆满地完成了下载小说的任务,缺点是耗时有些久,而且Chrome占用了大量的硬件资源。对于动态网页,其实不一定必须使用浏览器模拟的方式来爬取,可以尝试用浏览器开发者工具分析网页的请求,获取到接口后通过请求接口的方式请求数据,不再需要Selenium作为“中介”。另外,对于获得的屏幕截图而言,图片是窗口截图,而不是整个页面的截图(长图),为了获得整个页面的截图或者部分页面元素的截图,用户需要使用其他方法,如注入JavaScript脚本等,本文就不再展开介绍。
我这里准备了详细的Python资料,除了为你提供一条清晰的学习路径,我甄选了最实用的学习资源以及庞大的实例库。短时间的学习,你就能够很好地掌握爬虫这个技能,获取你想得到的数据。
01 专为0基础设置,小白也能轻松学会
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

