
热门标签
热门文章
- 1Alpha系统联结大数据、GPT两大功能,助力律所管理降本增效_alpha gpt操作入口
- 2NLP——Transformer结构分析_nlp中的transformer网络结构
- 3SOA-面向服务架构_soa两个经典实现方式
- 4综合布线实训室建设方案(完整版)_网络工程设计与实施综合实训
- 5虚拟机配置Hadoop_虚拟机修改hadoop环境变量
- 6Elasticsearch学习---聚合查询之Pipeline aggregations_es 查询能否使用pipeline
- 7一文彻底搞懂 Transformer(图解+手撕)
- 8TortoiseGit-下载安装汉语语言包(汉化-方法)_git汉化包
- 9我的flutter学习路线,带你一步步进阶成flutter开发工程师
- 10Gitee教程2(完整流程)_gitee创建分支
当前位置: article > 正文
【Kafka生产者发消息流程】_kafka发送数据流程
作者:Li_阴宅 | 2024-07-09 16:47:46
赞
踩
kafka发送数据流程
发送流程
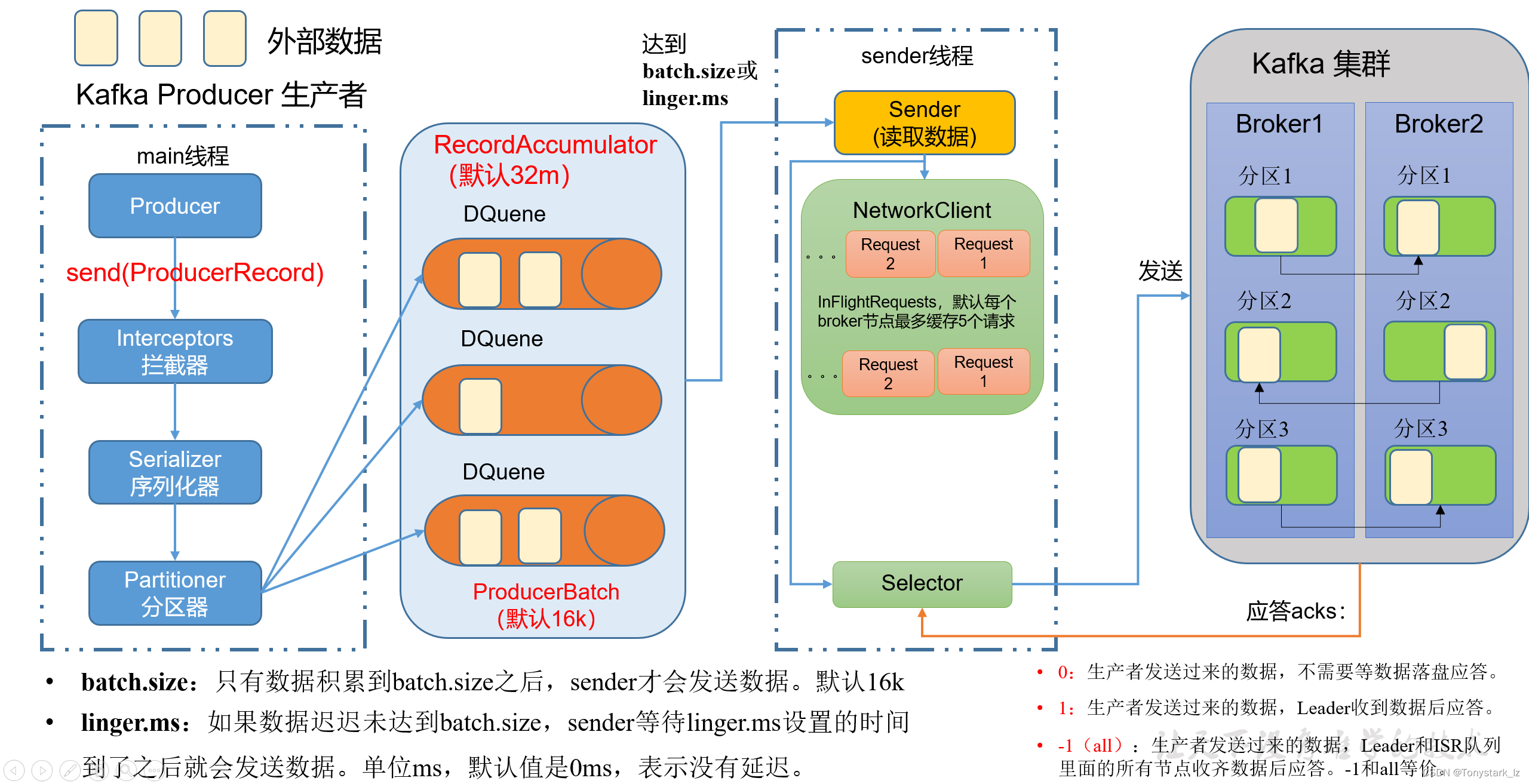
- 首先生产者调用send方法发送消息后,会先经过拦截器,接着进入序列化器。序列化器主要用于对消息的Key和Value进行序列化。接着进入分区器选择消息的分区。
- 上面这几步完成之后,消息会进入到一个名为RecordAccumulator的缓冲队列,这个队列默认32M。当满足以下两个条件的任意一个之后,消息由sender线程发送。
条件一:消息累计达到batch.size,默认是16kb。
条件二:等待时间达到linger.ms,默认是0毫秒。
所以在默认情况下,由于等待时间是0毫秒,所以只要消息来一条就会发送一条。 - Sender线程首先会通过sender读取数据,并创建发送的请求,针对Kafka集群里的每一个Broker,都会有一个InFlightRequests请求队列存放在NetWorkClient中,默认每个InFlightRequests请求队列中缓存5个请求。接着这些请求就会通过Selector发送到Kafka集群中。
- 当请求发送到Kafka集群后,Kafka集群会返回对应的acks信息。生产者可以根据具体的情况选择处理acks信息。
0:生产者发送过来的数据,不需要等数据落盘应答。
1:生产者发送过来的数据,Leader收到数据后应答。
-1(all):生产者发送过来的数据,Leader+和isr队列里面的所有节点收齐数据后应答。默认值是-1,-1和all是等价的。
生产者重要参数列表
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 生产者连接集群所需的broker地址清单。例如hadoop102:9092,hadoop103:9092,hadoop104:9092,可以设置1个或者多个,中间用逗号隔开。注意这里并非需要所有的broker地址,因为生产者从给定的broker里查找到其他broker信息。 |
| key.serializer和value.serializer | 指定发送消息的key和value的序列化类型。一定要写全类名。 |
| buffer.memory | RecordAccumulator缓冲区总大小,默认32m。 |
| batch.size | 缓冲区一批数据最大值,默认16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。 |
| linger.ms | 如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。单位ms,默认值是0ms,表示没有延迟。生产环境建议该值大小为5-100ms之间。 |
| acks | 0:生产者发送过来的数据,不需要等数据落盘应答。1:生产者发送过来的数据,Leader收到数据后应答-1(all):生产者发送过来的数据,Leader+和isr队列里面的所有节点收齐数据后应答。默认值是-1,-1和all是等价的。 |
| max.in.flight.requests.per.connection | 允许最多没有返回ack的次数,默认为5,开启幂等性要保证该值是 1-5的数字。 |
| retries | 当消息发送出现错误的时候,系统会重发消息。retries表示重试次数。默认是int最大值,2147483647。如果设置了重试,还想保证消息的有序性,需要设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1否则在重试此失败消息的时候,其他的消息可能发送成功了。 |
| retry.backoff.ms | 两次重试之间的时间间隔,默认是100ms。 |
| enable.idempotence | 是否开启幂等性,默认true,开启幂等性。 |
| compression.type | 生产者发送的所有数据的压缩方式。默认是none,也就是不压缩。 支持压缩类型:none、gzip、snappy、lz4和zstd。 |
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
推荐阅读
相关标签

