
- 1Linux(kali)永恒之蓝(ms17-010)漏洞实验_linux里有ms17-010漏洞吗
- 2使用 Python 实现一个简单的智能聊天机器人_python 英语人机语音对话代码
- 3Seata安装与使用以及部分常见问题(保姆级教程)_seata安装教程
- 4【LangChain系列 2】LangChain核心模块简介(一)_大白爱爬山 langchain 系列
- 5怎样在 PostgreSQL 中优化对大表的索引创建和维护的性能开销?_postpresql 表数据量大如何创建索引
- 6工作流引擎--vue3+bpmnjs_vue工作流插件
- 7【Linux】虚拟机安装 openEuler 24.03 X86_64_openeuler支持x86
- 8解决 No module named ‘torchvision‘_no module named 'torchvision
- 9Google Android for Cars的整理Android Automotive OS(一)_automotive os移植
- 10【大数据】学习笔记 1 Java SE 第1章 Java概述 1.3 Java语言概述
基于Hue,Dolphinscheduler,HIVE分析数据仓库层级实现及项目需求案例实践分析_dolphinscheduler hive
赞
踩
目录
1,ODS层(Operation Data Store-源数据层)
(1)DWD(Data Warehouse Detail-明细数据层)
(2)DWM(Data Warehouse Middle-明细数据层)
(3)DWS(Data Warehouse Service服务数据层)
3,ADS层(Application Data Store-数据应用层)
2,DIM层-对用户的详情作为维度(多个left join)
前言:
最近因公司业务调整开始涉及大数据方面知识,现开始学习数据仓库等技术知识。本章主要是用来分析根据业务数仓的各个层级及工具的运用。核心:HIVE。
一、数仓各个层级及作用
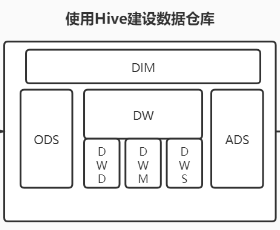
1,ODS层(Operation Data Store-源数据层)
这层一般不需要做任何的清洗工作,只需要把源数据中的数据插入到数仓中。
2,DW层(Data Warehouse-数据仓库层)
(1)DWD(Data Warehouse Detail-明细数据层)
对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据)、维度退化、脱敏等
(2)DWM(Data Warehouse Middle-数据中间层)
该层会在DWD层的数据基础上,对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。一般而言,针对DWM层的设计开发是建立在,积累一定数量DM和相关需求后,将设计到重复的指标和维度下沉到DWM的表中,因此在数仓建立初期,可能会有直接跳过DWM来开发的情况(本文就是跳过此层设计),但是随着相似的需求不断的增加,DWM的开发势在必行,而到了这种时候,我们可以以历史需求为参考,思考那些指标和维度是业务真正需要的,从而设计相应的表,避免开发大量无用的表,消耗不必要的存储和计算资源。在该层中的汇总表根据维度数量不同分为2种,一种是单一维度轻度汇总表,另一种是多维度轻度汇总表。
(3)DWS(Data Warehouse Service服务数据层)
以DWD为基础,按天,主题等进行轻度汇总。
3,ADS层(Application Data Store-数据应用层)
在DW层处理完成的数据通过工具进行可视化加工,当数据处理完成存储在Hive中,处理完成的数据可以通过ETL(Extract-Transform-Load)工具推送到关系型数据库中(例如Mysql),一般情况下,数据都有一个储存周期,400天左右,我们使用的可视化-工具平台(Dolphinscheduler),可以进行同比(年)、环比(月),这些数据形成一个数据集(结果),最后一步就是根据业务需求来配置报表
4,DIM层(Dimension-维度层)
以维度作为建模驱动,基于每个维度的业务含义,通过添加维度属性、关联维度等定义计算逻辑,完成属性定义的过程并建立一致的数据分析维表。为了避免在维度模型中冗余关联维度的属性,基于雪花模型构建维度表。维度层的表通常也被称为维度逻辑表。
-
高基数维度数据
一般是用户资料表、商品资料表等类似的资料表。数据量可能是千万级或者上亿级别。
-
低基数维度数据
一般是配置表,比如枚举值对应的中文含义,比如国家、城市、县市、街道等维表。数据量可能是个位数或者几千几万。
二、基于项目需求案例实践分析
需求:对接第三方系统并统计用户组成,并对用户类型进行分析占比等。
首先拿到需求先确定数据来源,确定好数据来源再对需求进行一步步的拆解。
(建表需要手动在HIVE里创建,dolphinscheduler中主要是负责数据插入)
1,ODS层-拉取数据并导入hive
在dolphinscheduler-资源中心创建脚本,主要是把源数据(涉及到所有用户的信息)从对方数据库(Oracle,MySQL等)导入hive中(脚本文件百度上有,只要修改连接信息就行)。
在项目管理中创建shell并执行脚本就可以同步数据。
2,DIM层-对用户的详情作为维度(多个left join)
主要是用来把所有ODS层中只要涉及到用户信息一并存入本表中,主要为了下面DWS层及DWD层中对用户数据的左连接。

3,DW层-对数据进行清洗操作
(1)DWD层
对ODS层中用户的数据进行清洗主要把异常用户(id重复及月份空值等)数据清除,并插入hive中。
(2)DWS层
主要是对DWD层的用户数据做一个扩展,能细尽细的原则,统计每天,每月,每日的用户数据,及各个类型用户数据分析等。

4,ADS层
对DWS层中(新增维度,业务预期)的数据 插入到SQL文件中,利用脚本导入。

补充:Hue-可视化hive工具(类似于Navicat)


