
- 1【 香橙派 AIpro评测】烧系统运行部署LLMS大模型跑开源yolov5物体检测并体验Jupyter Lab AI 应用样例(新手入门)
- 2linux的重要知识点_linux中的重要知识点
- 3深度学习:05 卷积神经网络介绍(CNN)_tride 池化
- 4sequoiadb java使用_Java开发基础_Java驱动_开发_JSON实例_文档中心_SequoiaDB巨杉数据库...
- 5AI时代,人工智能是开发者的助手还是替代者?
- 6大模型之SORA技术学习_sora模型csdn
- 7风险评估:IIS的安全配置,IIS安全基线检查加固
- 8pytorch之torch基础学习_torch 学习
- 9heic图片转换_heic-convert
- 10SpringCloud实战【九】: SpringCloud服务间调用_springcloud服务与服务之间的调用
客户案例:电商平台大数据上云实践_电商案例大数据开发
赞
踩
某知名电商平台成立于 2004 年,是领先的 B2B 跨境电子商务交易平台,其在品牌优势、技术优势、运营优势、用户优势四大维度上,已建立起竞争优势。截至 2022 年 12 月 31 日, 为来自 225 个国家和地区的 5960 万名注册买家提供服务,将他们与中国和其他国家的 254 万卖家联系起来,平台每年有超过 3400 万个在线商品,拥有 100 多条物流线路和 10 多个海外仓,71 个币种支付能力,在北美、拉美、欧洲等地设有全球业务办事机构。
挑战与目标
面临的挑战
- 随着跨境电商的日趋成熟,经营范围持续扩大、品类和渠道的增加,以及 AIGC 等行业新技术在运营提效场景下的广泛应用,对沉淀近 20 年的大数据进行深度挖掘、洞察和使用,给其带来成本、算力、效率、安全的挑战。
- 之前传统 IDC 大数据集群,维护成本高、无法实现弹性伸缩、计算存储耦合、算力瓶颈扩容周期长等问题越发严重,无法响应业务快速发展,具体表现在以下几个方面:
- 1) 硬件设备、软件许可及运行维护成本高:自建大数据集群需要大量的硬件设备,包括服务器、存储设备、网络设备、机柜等等,CDH 有 100 个节点数免费上限,软件许可费用高昂,需要持续不断投入大量人力和物力来进行系统维护和升级以确保正常运行。
- 2) 弹性伸缩:IDC 资源从采购到部署上线周期漫长,通常以月为单位,无法及时应对突发的业务高峰资源需求。受软件许可限制,无法横向扩容算力和存储。
- 3) 计算存储耦合:由于计算节点和存储节点共享同一物理节点的资源,如 CPU、内存、磁盘等,可能会出现资源竞争的问题。如果一个计算任务占用了大量的资源,可能会影响其他任务的执行效率。数据的读写和计算都需要通过网络进行传输,随着集群规模的扩大,网络带宽可能会成为瓶颈,影响计算性能。
- 4) 算力瓶颈:主要计算引擎使用 Hive On Spark(2.4 版本)和 Hive on MR,计算效率比最新的 Spark/Tez 引擎有明显差距,通过横向扩容集群或纵向升级节点配置无法很好提升计算效率。
预期上云实现目标
- 智能湖仓架构
建设智能湖仓架构,将数据的采集、传输、存储、分析、应用全流程各环节无缝衔接,实现数据的集中存储和管理,提高数据的流转效率、数据质量、可靠性和安全性。对数据进行深度挖掘、智能分层和热力分析,提高数据的价值和利用率。
- 精细化运营成本管控
建立云资源的精细化运营和成本管控制度,提高资源利用率并降低成本。实现资源随业务灵活扩缩,提高业务的灵活性和响应速度。利用云原生的智能分层、自动化管理和运维能力,提高运维效率和质量。
- 一站式数据平台底座
打造集数据集成、数据开发、数据资产管理、数据服务等一站式大数据平台,实现“快、准、全、稳”的数仓体系,达到数据驱动决策,算法增长业务的目标。平台提供数据可视化和报表分析工具,帮助业务人员更好地理解和利用数据,提高业务决策的准确性和效率。
数据架构及技术方案
本地大数据的技术组件及架构(IDC)
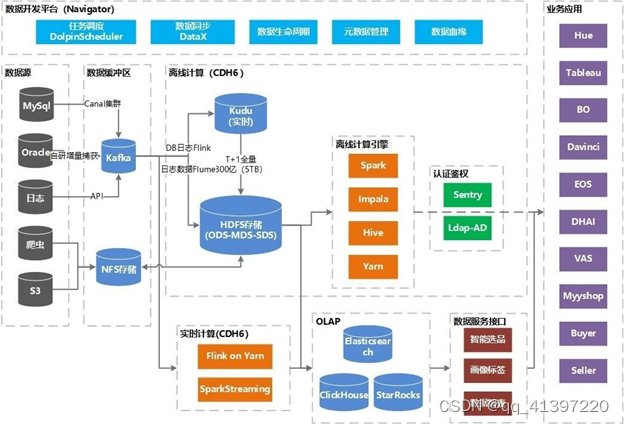
IDC 大数据环境基于 CDH、大数据开源生态组件、商业及自研工具构建。
数据源:包含上百个 MySQL、Oracle 以及 NoSQL 数据库实例,数万张源表(分库分表),数十 TB 数据。
数据缓冲区:每天数十亿条数据库增量数据,用户行为日志数据实时发送到 Kafka 集群,保证了数据高可用的同时,满足了离线和实时大规模数据分析处理的需求。
离线计算和实时计算集群:使用 CDH 6.x 搭建大数据集群,借助于 Cloudera Manager 可方便地管理和部署 Hadoop 集群,并进行可视化监控和故障诊断。提供稳定可靠的离线、实时的计算引擎服务。
OLAP 引擎:按不同应用场景需求配置了 ElasticSearch、ClickHouse、StarRocks 查询引擎提供买卖家、业务运营的在线查询服务。
业务应用:常用的报表及可视化工具:Hue、Tableau、BO,自研的 EOS 系统和对接服务化接口等业务应用。
数据安全:集成了 Kerberos+Sentry+Ldap 提供统一用户认证与鉴权,保障了数据安全。其中,Kerberos 提供了身份验证协议的基础,Sentry 提供了细粒度的授权控制,LDAP 则提供了用户和组信息的管理功能。这些技术的结合极大提高大数据集群的安全性和管理效率。
数据开发平台:其数据开发平台采用了开源和自研技术相结合的方案。其中,任务调度部分采用 DolphinScheduler 实现,数据集成部分在 DataX 基础上进行二次开发,实现了可视化配置。此外,还注重数据血缘、元数据以及生命周期管理等方面,专门进行了针对性的研发。
本地大数据集群负载(IDC)
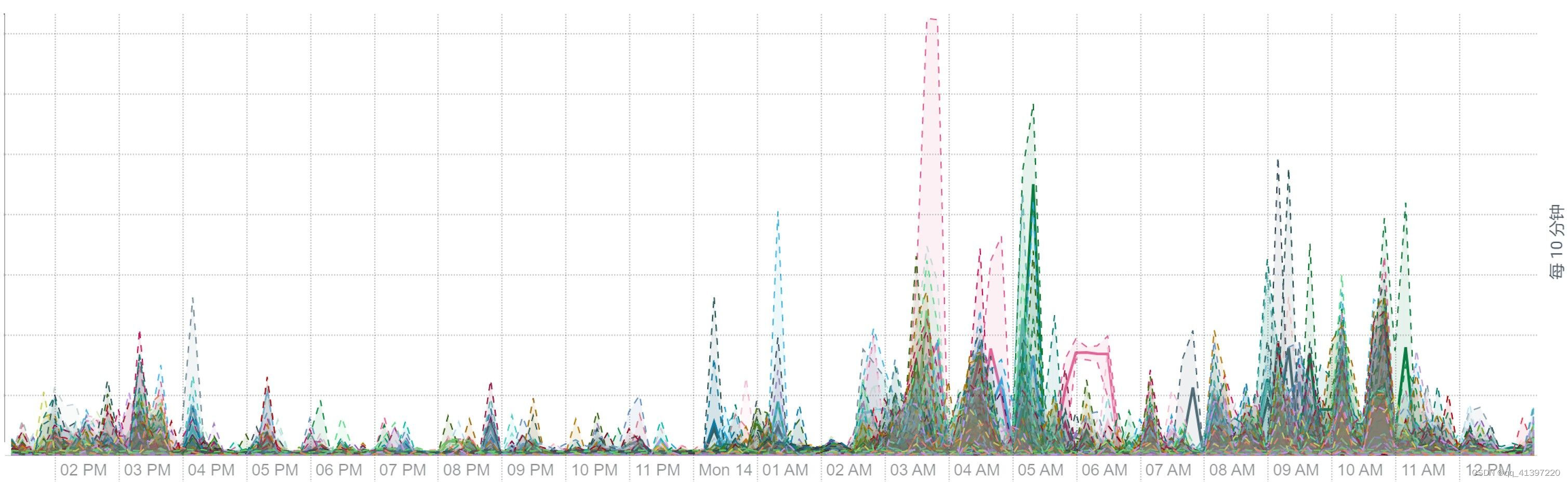
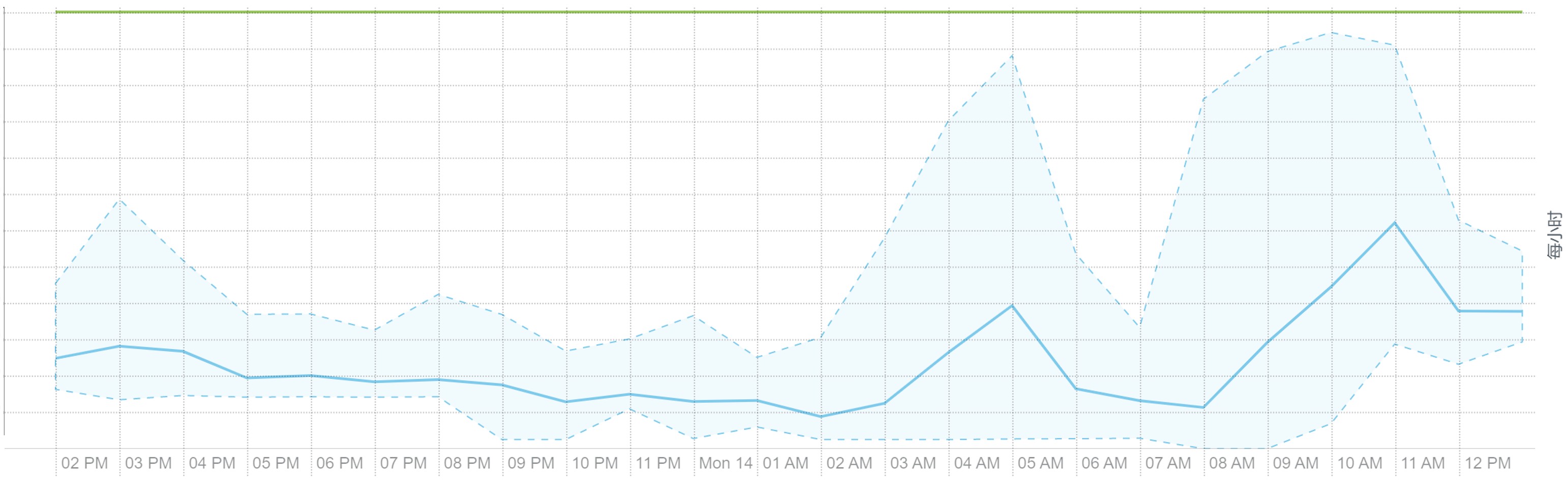
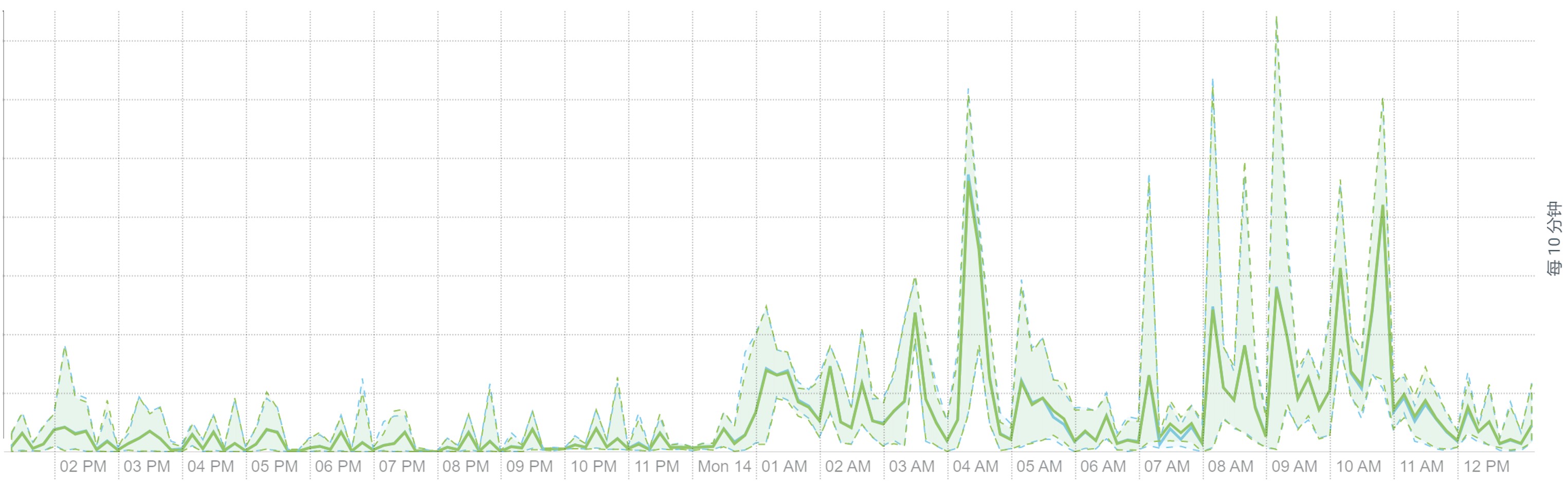
离线大集群计算的资源利用率包括 CPU、内存、磁盘与网络 IO 等均可看到明显的潮汐效应。每天波峰集中在三个时间段:2-5(每天定时离线计算任务)、9-11(工作时段业务常规报表查询),14-16(工作时段业务常规报表查询),平均资源利用率 30%。
下面是某个集群的工作负载截图:
CPU 负载:
Yarn 内存使用:

HDFS IO:

Network IO:

前期技术方案调研
前期调研阶段,云为科技花了大量时间和精力对 Amazon EMR、Redshift、S3 等进行多个维度深入评估测试并得到了超过预期的结果,最终选择亚马逊云科技作为大数据云底座。调研最终结论如下:
| 架构兼容性 |
技术先进性 |
算力 |
维护难易成本 |
开发平台 |
扩展性 |
成本 |
| 适配现有公司架构 |
技术先进且开放,更新迭代快 |
高-EMR Spark 效率是 CDH 的 2 倍 |
EMR-中 |
可集成第三方开发平台 |
组件全面 |
中 |
在调研过程中,云为主要对比亚马逊云科技和 IDC 自建的离线 Hadoop 集群和数据仓库服务,以下是核心组件版本和硬件资源配置和关键项目项对比结果:
| 项目 |
亚马逊云科技 |
DHgate |
||
| 离线集群 |
数据分析服务 |
EMR |
CDH |
|
| 主版本 |
6.3/5.34 |
CDH6.x |
||
| Hadoop |
3.2.1/2.10.1 |
3.x |
||
| Hive |
||||


{kind=link}
{kind=link}
{kind=link}
{kind=link}