
- 1GitHub 创始人资助的开源浏览器「GitHub 热点速览」
- 2WPF版的权限管理系统
- 3【面试精选】00后卷王带你三天刷完软件测试面试八股文
- 4jar包混淆和防反编译工具proguard使用简介
- 5Docker 部署kafka_docker kafka
- 6python3IDE下载手机安卓版,手机版python下载安装
- 7华为OD 技术综合面,手撕代码真题整理(七):字符串的不重复子串 | 二叉树的最大路径和_华为od面试手撕代码python
- 82024最详细Python安装教程(新手)
- 9阿里云网盘内测(附下载地址)_阿里云盘内测版官网
- 10C++数据结构 2.最简单的排序算法--冒泡排序_c++冒泡排序法代码数据结构
Rust与网络编程:同步网络I/O_rust网络编程
赞
踩
使用机器构建可以通过互联网相互通信的媒介是一项复杂的任务。这需要不同的设备通过互联网进行通信、运行不同的操作系统、不同版本的应用程序,并且它们需要一组约定的规则来相互交换信息。这些通信规则被称为网络协议,设备彼此之间发送的消息被称为网络数据包。
为了分离各方面的关注度,例如可靠性、可发现性及封装性,这些协议被分成若干层,其中较高层协议堆叠在较低层协议之上。每个网络数据包由来自这些层的信息组成。当前的操作系统已经附带了网络协议堆栈的实现。在此实现中,每层都为其上方的层提供支持。
在最底层,我们有物理层和数据链路层协议,用于指定数据包如何在互联网节点之间通过电缆进行传输,以及它们如何进出计算机网卡。在此之上,我们有IP层,它采用称为IP地址的唯一ID来识别互联网上的节点。在IP层之上,我们有传输层,它采用一种为互联网上的两个进程之间提供点对点传输的协议。此层存在传输控制协议(Transmission Control Protocol,TCP)和用户数据报协议(User Datagram Protocol,UDP)等协议。在传输层之上,我们有应用层,它采用例如HTTP和文件传输协议(File Transfer Protocol,FTP)的协议,这两者用于构建大量的应用程序。它允许更高级别的通信,例如在移动设备上运行的聊天应用程序。整个协议栈协同工作,以促进在计算机上运行的应用程序之间的复杂交互,从而在互联网上传播。
随着越来越多的设备通过互联网连接和共享信息,分布式应用程序架构开始激增,并诞生了两种模型:分散模型,通常也称对等模型;以及集中模型,它也被称为客户端-服务端模型。其中后者更常见。本章的重点将放在构建网络应用程序的客户端-服务端模型上,特别是传输层。
在主流操作系统中,网络堆栈的传输层为开发者提供了一系列API,其名为套接字(socket)。它包括一组接口,用于在两个进程之间建立通信连接。套接字允许你在本地或远程两个进程之间传递数据,而无须开发者了解底层的网络协议。
Socket API源于伯克利软件发行版(Berkley Software Distribution,BSD)的Linux,这是第一个在1983年提供带有Socket API网络堆栈实现的操作系统。它作为当前主流操作系统中网络堆栈的参考实现。在类UNIX操作系统中,套接字遵循相同的理念,即一切都是文件,并公开文件描述符API。这意味着可以像文件一样从套接字中读取和写入数据。
注意
套接字是文件描述符(整数),它指向内核管理的进程描述符表。描述符表包含文件描述符到文件条目结构的映射,该文件条目结构包含发送到套接字的数据的实际缓冲区。
Socket API主要用于TCP/IP层。在这一层,我们创建的套接字按不同级别进行分类。
- 协议:根据协议,我们可以有TCP套接字或UDP套接字。TCP是一种包含状态的流协议,提供能够以可靠的方式传递消息的能力,而UDP是一种无状态且不可靠的协议。
- 通信类型:根据我们是与本地计算机还是远程计算机上的进程通信,可以使用互联网套接字或者UNIX域套接字。互联网套接字用于在远程计算机上的进程之间交换信息。它由 IP 地址和端口构成的元组表示。想要远程通信的两个进程必须使用IP套接字。UNIX域套接字用于本地计算机上运行的进程之间的通信。这里,它采用文件系统路径,而不是一对IP地址端口。例如,数据库会采用UNIX域套接字来公开连接端点。
- I/O模型:根据如何读取和写入套接字数据,我们可以创建两种套接字:阻塞套接字和非阻塞套接字。
现在我们已经了解了不少与套接字有关的信息,接下来让我们探讨一下客户端—服务端模型。在这种网络模型中,设置两台计算机互相通信一般会遵循如下流程:服务器创建套接字并在指定协议(可以是TCP或UDP)之前将其绑定到一对IP地址端口上;然后开始侦听来自客户端的连接。另外,客户端创建一个连接套接字并连接到给定的IP地址和端口。在UNIX中,进程可以使用套接字系统创建套接字。此调用返回一个文件描述符,程序可以使用该文件描述符对客户端或服务器进行读写调用。
Rust在标准库中为我们提供了net模块。这包含传输层的上述网络单元。对于TCP通信,我们有TcpStream和TcpListener类型。对于UDP通信,我们有UdpSocket类型。net模块还提供了用于正确表示v4和v6版本IP地址的数据类型。
构建可靠的网络应用程序需要考虑若干因素。如果你允许在消息交换时丢失少量数据包,则可以使用 UDP 套接字,但如果无法忍受丢包或希望按顺序传递消息,则必须使用TCP套接字。UDP传输速度很快但出现得较晚,能够满足需要最小延迟传输数据包,但允许丢失少量数据包的情况。例如视频聊天应用程序使用UDP,聊天过程中某些数据帧从视频流中丢失,其影响也不大。UDP适用于能够容忍无交付保证的情况。本章将重点讨论TCP套接字,因为它是大多数需要可靠交付的网络应用程序最常采用的协议。
另一个需要考虑的因素是,应用程序为客户提供的服务的质量和效率。从技术角度来看,这又转变为套接字I/O模型的选择问题。
注意
I/O是Input/Output的首字母缩写,是一个表意宽泛的短语,在这种情况下,它仅表示在套接字上读取和写入字节。
在阻塞和非阻塞套接字之间进行选择会改变其体系结构、编写代码的方式,以及如何扩展到客户端。阻塞套接字为用户提供的是同步I/O模型,而非阻塞套接字为用户提供的是异步I/O模型。在实现Socket API的平台上,例如UNIX,默认情况下会在阻塞模式下创建套接字。这要求主流的网络堆栈上默认的I/O模型是同步模型。接下来,让我们探讨一下这两种模型。
12.2 同步网络I/O
如前所述,默认情况下会在阻塞模式创建套接字。处于阻塞模式的服务器是同步的,因为套接字上的每个读写调用都会阻塞,并等它完成相关操作。如果另一个客户端尝试连接到服务器,则需等到服务器完成前一个客户端的请求之后才能响应。也就是说,在TCP读取和写入缓冲区已满之前,应用程序会阻止相应的I/O操作,并且任何新的客户端连接必须等到缓冲区为空并再次填满为止。
注意
除了应用程序维护其自身的任何缓冲区以外,TCP 实现在内核级别包含它自己的读写缓冲区。
Rust的标准库网络原语为套接字提供相同的同步API。要了解这个模型的实际应用,我们将不局限于实现一个echo服务器,接下来我们会构建一个Redis的精简版本。Redis是一种数据结构服务器,通常用作内存数据存储。Redis客户端和服务器使用Redis序列化协议(REdis Serialization Protocol,RESP),这是一种简单的基于行的协议。虽然该协议与TCP或UDP无关,但Redis实现主要采用TCP。TCP是一种基于流的有状态协议,服务器和客户端无法识别从套接字读取多少字节以构造协议消息。为了说明这一点,大多数协议都遵循这种模式,即采用长度字节,然后使用相同长度的有效载荷字节。
RESP中的消息类似于TCP中大多数基于行的协议,初始字节是标记字节,后跟有效载荷的长度,然后是有效载荷自身。消息以终止标记字节结束。RESP支持各种消息,包括简单字符串、整数、数组及批量字符串等。RESP中的消息以\r\n字节序列结束。例如,从服务器到客户端的成功消息被编码并发送为+OK\r\n。+表示成功回复,然后是字符串。该命令以\r\n结尾。要指示查询失败,Redis服务器将回复-Nil\r\n。
get和set之类的命令会作为批量字符串数组发送。例如,get foo命令将按如下方式发送:
*2\r\n$3\r\nget\r\n$3\r\nfoo\r\n在上述消息中,*2表示我们有一个包含两个命令的数组,并且由\r\n 分隔。接下来,$3表示我们有一个长度为3的字符串,例如get命令后的字符串foo,该命令以\r\n结尾。这是RESP的基础知识。不必担心解析RESP消息的底层细节,因为我们将使用一个名为resp的软件包分支来将客户端传入的字节流解析为有效的RESP消息。
构建同步Redis服务器
为了让这个例子浅显易懂,我们的Redis 复制版将是一个非常小的RESP协议子集,并且只能处理SET和GET调用。我们将使用Redis官方软件包附带的官方redis-cli对我们的服务器进行查询。要使用redis-cli,我们可以通过运行apt-get install redis-server命令在Ubuntu系统上安装它。
让我们通过运行cargo new rudis_sync命令创建一个新项目,并在我们的Cargo.toml文件中添加如下依赖项:
- rudis_sync/Cargo.toml
-
- [dependencies]
- lazy_static = "1.2.0"
- resp = { git = "https://github.com/creativcoder/resp" }
我们将项目命名为rudis_sync,并且会用到以下两个软件包。
- lazy_static:将使用它来存储我们的内存数据库。
- resp:这是托管在我们的GitHub版本库上的resp的复刻。我们将使用它来解析来自客户端的字节流。
为了让实现更容易理解,rudis_sync包含非常少的错误处理集成。完成代码测试后,我们鼓励你集成更好的错误处理策略。
让我们先从main.rs文件中的内容开始:
- // rudis_sync/src/main.rs
-
- use lazy_static::lazy_static;
- use resp::Decoder;
- use std::collections::HashMap;
- use std::env;
- use std::io::{BufReader, Write};
- use std::net::Shutdown;
- use std::net::{TcpListener, TcpStream};
- use std::sync::Mutex;
- use std::thread;
-
- mod commands;
- use crate::commands::process_client_request;
-
- type STORE = Mutex<HashMap<String, String>>;
- lazy_static! {
- static ref RUDIS_DB: STORE = Mutex::new(HashMap::new());
- }
-
- fn main() {
- let addr = env::args()
- .skip(1)
- .next()
- .unwrap_or("127.0.0.1:6378".to_owned());
- let listener = TcpListener::bind(&addr).unwrap();
- println!("rudis_sync listening on {} ...", addr);
-
- for stream in listener.incoming() {
- let stream = stream.unwrap();
- println!("New connection from: {:?}", stream);
- handle_client(stream);
- }
- }

我们有一堆导入代码,然后是一个在lazy_static!宏中声明的内存RUDIS_DB,其类型为HashMap。我们使用它作为内存数据库来存储客户端发送的键/值对。在main函数中,我们使用用户提供的参数在addr中创建一个监听地址,或者使用127.0.0.0:6378作为默认值。然后,通过调用关联的bind方法创建一个TcpListener实例,并传递addr。
这将创建一个TCP侦听套接字。稍后,我们在listener上调用incoming方法,然后返回新客户端连接的迭代器。针对TcpStream类型(客户端套接字)的每个客户端连接steam,我们调用handle_client方法传入stream。
在同一文件中,handle_client函数负责解析从客户端发送的查询,这些查询将是GET或SET查询之一:
- // rudis_sync/src/main.rs
-
- fn handle_client(stream: TcpStream) {
- let mut stream = BufReader::new(stream);
- let decoder = Decoder::new(&mut stream).decode();
- match decoder {
- Ok(v) => {
- let reply = process_client_request(v);
- stream.get_mut().write_all(&reply).unwrap();
- }
- Err(e) => {
- println!("Invalid command: {:?}", e);
- let _ = stream.get_mut().shutdown(Shutdown::Both);
- }
- };
- }
handle_client函数在steam变量中接收客户端TcpStream套接字。我们将客户端stream包装到BufReader中,然后将其作为可变引用传递给resp软件包的Decoder::new方法。Decoder会从stream中读取字节以创建RESP的Value类型。然后有一个匹配代码块来检查我们的解码是否成功。如果失败,将输出一条错误提示信息,并通过调用shutdown()关闭套接字,然后使用Shutdown::Both值关闭客户端套接字连接的读取和写入部分。shutdown方法需要一个可变引用,所以在此之前调用get_mut()。在实际的实现中,用户显然需要优雅地处理此错误。
如果解码成功,将会调用process_client_request,它会返回reply来响应客户端的请求。
我们通过在客户端stream上调用write_all将reply写入客户端。process_client_request函数在command.rs中的定义如下所示:
- // rudis_sync/src/commands.rs
-
- use crate::RUDIS_DB;
- use resp::Value;
-
- pub fn process_client_request(decoded_msg: Value) -> Vec<u8> {
- let reply = if let Value::Array(v) = decoded_msg {
- match &v[0] {
- Value::Bulk(ref s) if s == "GET" || s == "get" =>
- handle_get(v),
- Value::Bulk(ref s) if s == "SET" || s == "set" =>
- handle_set(v),
- other => unimplemented!("{:?} is not supported as of now",
- other),
- }
- } else {
- Err(Value::Error("Invalid Command".to_string()))
- };
-
- match reply {
- Ok(r) | Err(r) => r.encode(),
- }
- }
此函数获取已解码的Value,并将其与已解析的查询进行匹配。在上述的实现中,我们希望客户端发送一系列字符串数字,以便我们能够适配Value的变体Value::Array,使用if let语句并将数组存储到v中。如果在if分支中对Array值进行匹配,那么将获取该数组并匹配v中的第一个条目,这将是我们的命令类型,即GET或SET。这也是一个Value::Bulk变体,它将命令包装成字符串。
我们将对内部字符串的引用视为s,并且仅当字符串包含的值为GET或SET时才匹配。在值为GET的情况下,我们调用handle_get,传递数组v;在值为SET的情况下,我们调用handle_set。在else分支中,我们只使用Invalid Command作为描述信息向客户端发送Value::Error作为回复。
两个分支返回的值将分配给变量reply,然后匹配内部类型r,并通过调用其上的encode方法转换为Vec<u8>,最后从函数返回。
我们的handle_set和handle_get函数在同一文件中定义如下:
- // rudis_sync/src/commands.rs
-
- use crate::RUDIS_DB;
- use resp::Value;
-
- pub fn handle_get(v: Vec<Value>) -> Result<Value, Value> {
- let v = v.iter().skip(1).collect::<Vec<_>>();
- if v.is_empty() {
- return Err(Value::Error("Expected 1 argument for GET
- command".to_string()))
- }
- let db_ref = RUDIS_DB.lock().unwrap();
- let reply = if let Value::Bulk(ref s) = &v[0] {
- db_ref.get(s).map(|e|
- Value::Bulk(e.to_string())).unwrap_or(Value::Null)
- } else {
- Value::Null
- };
- Ok(reply)
- }
-
- pub fn handle_set(v: Vec<Value>) -> Result<Value, Value> {
- let v = v.iter().skip(1).collect::<Vec<_>>();
- if v.is_empty() || v.len() < 2 {
- return Err(Value::Error("Expected 2 arguments for SET
- command".to_string()))
- }
- match (&v[0], &v[1]) {
- (Value::Bulk(k), Value::Bulk(v)) => {
- let _ = RUDIS_DB
- .lock()
- .unwrap()
- .insert(k.to_string(), v.to_string());
- }
- _ => unimplemented!("SET not implemented for {:?}", v),
- }
- Ok(Value::String("OK".to_string()))
- }
在handle_get()中,我们首先检查GET命令在查询中是否包含相应的键,并在查询失败时显示错误提示信息。接下来匹配v[0],这是GET命令的关键,并检查它是否存在于我们的数据库中。如果它存在,我们使用映射组合器将其包装到Value::Bulk,否则我们返回一个Value::NULL:
db_ref.get(s).map(|e| Value::Bulk(e.to_string())).unwrap_or(Value::Null)然后我们将它存储在变量reply中,并将其作为Result类型返回,即Ok(reply)。
类似的事情还会在handle_set中发生,如果没有为SET命令提供足够的参数,就会退出程序。接下来,我们使用&v[0]和&v[1]匹配相应的键和值,并将其插入RUDIS_DB中。作为SET查询的确认,我们用OK进行回复。
回到process_client_request函数,一旦我们创建了回复字节,就会匹配Result类型,并通过调用encode()将它们转换为Vec<u8>,然后将其写入客户端。经过上述解释,接下来该使用官方的redis-cli工具对客户端进行测试。我们将通过调用redis-cli -p 6378来运行它:
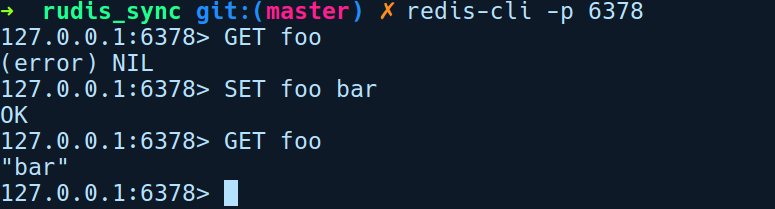
在上述会话中,我们使用rudis_sync的预期回复执行了一些GET和SET查询。另外,以下是rudis_server新连接的输出日志:

但我们服务器的问题在于,用户必须等待初始客户端完成服务。为了证明这一点,将在处理新客户端连接的for循环中引入一些延迟:
- for stream in listener.incoming() {
- let stream = stream.unwrap();
- println!("New connection from: {:?}", stream);
- handle_client(stream);
- thread::sleep(Duration::from_millis(3000));
- }
sleep调用用于模拟处理请求过程中的延迟。为了查看延迟,我们几乎同时启动两个客户端,其中一个客户端发送SET请求,另一个客户端使用同一密钥发送GET请求。这是我们的第1个客户端,它执行SET请求:

这是我们的第2个客户端,它使用同一密钥对foo执行GET请求:

如你所见,第2个客户端必须等待接近3秒才能获得第2个GET回复。
由于其性质,当需要同时处理超过10000个客户端请求时,同步模式会出现瓶颈,每个客户端会占用不同的处理时间。要解决这个问题,通常需要生成一个线程来处理每个客户端连接。每当建立新的客户端连接时,我们生成一个新线程从主线程转移handle_client调用,从而允许主线程接收其他客户端连接。我们可以通过在main函数中修改一行代码来实现这一点,如下所示:
- for stream in listener.incoming() {
- let stream = stream.unwrap();
- println!("New connection from: {:?}", stream);
- thread::spawn(|| handle_client(stream));
- }
这消除了服务器的阻塞性质,但每次收到新的客户端连接时会产生构造新线程的开销。首先,产生新线程需要一些开销,其次,线程之间的上下文切换增加了另外的开销。
如你所见,我们的rudid_sync服务器能够按照预期工作,但它很快就会遇到我们的硬件能够处理线程数量的瓶颈。这种处理连接的线程模型运作良好,直到互联网开始普及,越来越多的用户接入互联网成为常态。而今天的情况有所不同,我们需要能够处理数百万个请求的高效服务器。事实证明,我们可以在更基础的层面解决客户端日益增加的问题,即采用非阻塞套接字,接下来让我们探讨它们。本文摘自《精通Rust 第2版》
本书内容共17章,由浅入深地讲解Rust相关的知识,涉及基础语法、软件包管理器、测试工具、类型系统、内存管理、异常处理、高级类型、并发模型、宏、外部函数接口、网络编程、HTTP、数据库、WebAssembly、GTK+框架和GDB调试等重要知识点。
本书适合想学习Rust编程的读者阅读,希望读者能够对C、C++或者Python有一些了解。书中丰富的代码示例和详细的讲解能够帮助读者快速上手,高效率掌握Rust编程。

