
- 1Ubuntu-openssh 升级_ubuntu22.04升级ssh
- 256. UE5 RPG 给敌人添加AI实现跟随玩家_ue5 possessedby方法
- 3如何判断样本标注的靠谱程度?置信度学习(CL)简述
- 4python multiprocessing Queue踩坑_python multiprocessing queue 丢数据
- 5统计分析文章中英文单词出现次数及频率(C++实现)_输入一篇文章(文章以半角句号结束),统计其中出现的单词(连续的字母)及出现频率,若(1)_c++单词频率编写
- 6Mac安装YouCompleteMe出现Unexpected exit code -11的解决方案
- 7Activiti:开源流程引擎,Java语言开发的强大工具_activiti开源项目
- 8VMware安装CentOS 8系统_centos8iso映像文件
- 9通义千问Qwen-VL-Chat大模型本地部署(一)
- 10【16】Android基础知识之Window(二) - ViewRootImpl
JAVA:利用Redisson实现分布式应用的高效开发_java redisson
赞
踩
1、简述
随着分布式系统的广泛应用,解决分布式锁、分布式数据结构、分布式任务调度等问题变得尤为关键。Redisson,作为一个基于Redis的Java驻内存数据网格(In-Memory Data Grid)和操作库,提供了丰富的分布式服务和工具,能够极大地简化分布式应用的开发。本文将介绍Redisson的应用,探讨如何利用Redisson提高分布式系统的效率和可靠性。
2、Redis
Redis是一款内存高速缓存数据库;
-
数据模型为:key - value,非关系型数据库使用的存储数据的格式;
-
可持久化:将内存数据在写入之后按照一定格式存储在磁盘文件中,宕机、断电后可以重启redis时读取磁盘中文件恢复缓存数据;
-
分布式:当前任务被多个节点切分处理,叫做分布式处理一个任务。单个服务器内存,磁盘空间有限,无法处理海量的缓存数据,必须支持分布式的结构;
SpringBoot 2.x引入Redis缓存
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 1
- 2
- 3
- 4
样例:采用Redis缓存。
Map<Long, List<Catelog2Vo>> listMap = null;
String category= (String) redisUtils.get("Category");
if(StringUtils.isEmpty(category)){
listMap = getCategoryJsonFromDb();
String s = JSON.toJSONString(listMap);
redisUtils.set("Category", s);
}else {
listMap = JSON.parseObject(category, new TypeReference<Map<Long, List<Catelog2Vo>>>(){});
}
return listMap;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.1 缓存穿透
指查询一个一定不存在的数据,由于缓存是不命中,将查询数据库,但是数据库也无此记录。我们没有将查询的null写入缓存,导致不存在的数据每次请求数据存储层,失去缓存的意义。
风险:利用不存在的数据进行攻击,数据库压力瞬时增大,最终导致崩溃
解决方法:null结果缓存,并加入短暂过期时间 或者 采用布隆过滤器
对上诉样例改造:
if(listMap != null){
String s = JSON.toJSONString(listMap);
redisUtils.set("CatalogJson", s, 24*60*60);
}
else{
redisUtils.set("CatalogJson", null, 24*60*60);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
总结:通过设置过期时间和缓存null来解决缓存穿透问题,但是还是会遇到高并发导致服务器雪崩问题
2.2 缓存雪崩
指我们设置的缓存时key采用相同的过期时间,导致缓存在某一时刻同时失效,请求全部转换到存储层DB,存储层瞬间压力过重导致雪崩。
解决方法:原有的失效时间基础上增加一个随机值,比如1-10分钟随机,这样每一个缓存的过期时间的重复率就会降低,就能大概率避免集体失效的事件。
对上诉代码改造:
int randomTime = (int)(1+Math.random()*(10-1+1));//随机数要自己改造
if(listMap != null){
String s = JSON.toJSONString(listMap);
redisUtils.set("CatalogJson", s, 24*60*60 + randomTime);
}
else{
redisUtils.set("CatalogJson", null, 24*60*60 + randomTime);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
总结:解决了缓存穿透和缓存雪崩问题,但是还是存在某个时间点出现的缓存击穿问题
2.3、缓存击穿
缓存击穿:对于一些设置过期时间的key,如何这些key可能会在某些时间点被高并发访问,是一个非常热点的数据,如果这个key在大量请求同时进来钱正好失效,那么所有的key数据查询到落到存储层DB。我们称为缓存击穿。
解决方法: 加锁,大量并发只让一个去查,其他人等待,查到以后释放锁。其他人获取到锁,先查询缓存,就有数据了,不用去存储层查询。
- 本地锁
本地锁只锁当前进程,无法完全锁住高并发。
synchronized (this){
//保证锁的原子性
}
- 1
- 2
- 3

- 分布式锁
加锁保证原子性:
String uuid = UUID.randomUUID().toString();
boolean lock = redisTemplate.opsForValue().setIfAbsent("category_lock", uuid, 120, TimeUnit.SECONDS);
- 1
- 2
删锁保证原子性:采用lua脚本
String script ="if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Long lockInt = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("category_lock"), uuid);
- 1
- 2
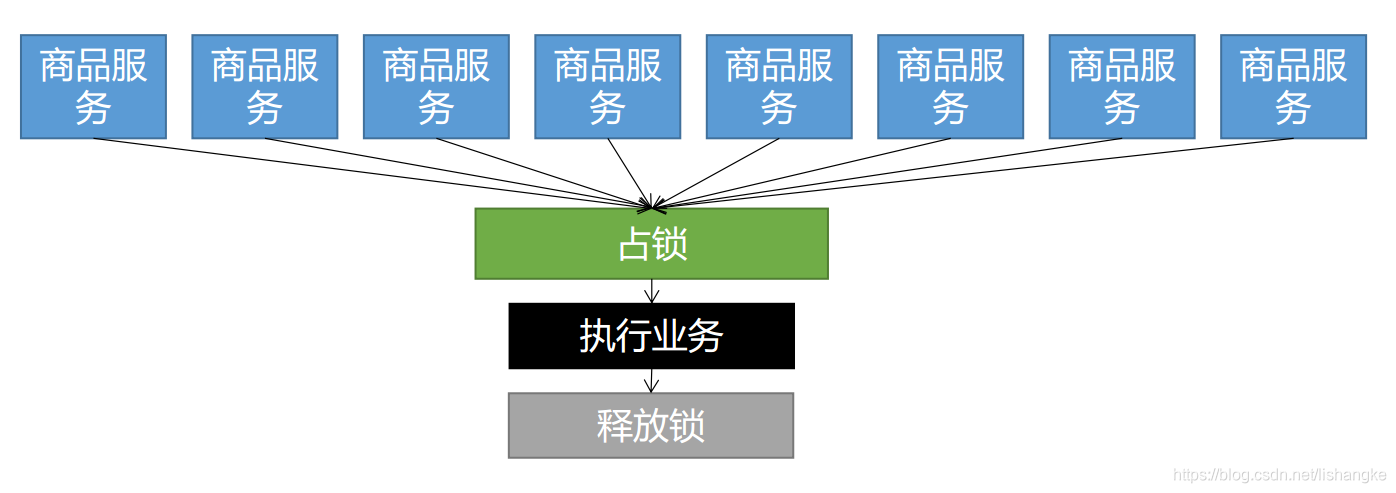
3、Redisson
通过以上redis在分布式操作的限制,我们可以通过Redission 来简化分布式应用的开发难度。
官网: https://redisson.org/
github: https://github.com/redisson/redisson#quick-start
3.1 引入依赖
首先,需要在项目中引入Redisson的依赖。可以通过Maven或Gradle等构建工具进行引入。以下是一个基本的Maven依赖配置:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.6</version> <!-- 请使用最新版本 -->
</dependency>
- 1
- 2
- 3
- 4
- 5
3.2 基本配置
在使用Redisson之前,需要配置Redisson的连接信息,包括Redis服务器地址、端口号等。通常,这些配置信息可以通过Config对象进行设置。以下是一个简单的配置示例:
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
- 1
- 2
- 3
- 4
3.3 分布式锁
分布式锁是在分布式环境中保障资源访问安全的关键。Redisson提供了简单易用的分布式锁实现。以下是一个简单的分布式锁的应用示例:
RLock lock = redisson.getLock("myLock");
try {
lock.lock();
// 执行临界区代码
} finally {
lock.unlock();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.4 分布式集合
Redisson支持多种分布式集合,如分布式List、Set、Map等。通过这些集合,可以方便地在分布式环境中进行数据共享和操作。以下是一个分布式Set的示例:
RSet<String> set = redisson.getSet("mySet");
set.add("element1");
set.add("element2");
- 1
- 2
- 3
3.5 任务调度
Redisson还提供了分布式任务调度的功能,可以方便地在分布式环境中调度任务。以下是一个简单的任务调度的示例:
RScheduledExecutorService executorService = redisson.getExecutorService("myExecutorService");
RFuture<Void> future = executorService.schedule(() -> {
// 执行任务逻辑
}, 10, TimeUnit.SECONDS);
- 1
- 2
- 3
- 4
3.6 对象操作
Redisson还支持分布式对象的操作,如分布式AtomicLong、CountDownLatch等。通过这些对象,可以实现更复杂的分布式场景。以下是一个分布式AtomicLong的示例:
RAtomicLong atomicLong = redisson.getAtomicLong("myAtomicLong");
atomicLong.incrementAndGet();
- 1
- 2
4、结论
通过以上简单的示例,我们可以看到Redisson提供了丰富而强大的API,极大地简化了分布式应用的开发难度。在实际应用中,还可以结合Redisson的监控和统计功能,更好地了解分布式系统的运行状况。然而,使用Redisson时需注意配置合理的Redis集群,以及合理设计分布式锁的范围,确保系统的性能和可靠性。Redisson的广泛应用为分布式系统的开发提供了便利,使得开发者可以更专注于业务逻辑的实现,而不用过多关注分布式环境的复杂性。

