
- 1有向图的邻接矩阵_邻接矩阵与可图化
- 2mybatis oracle批量update和insert
- 3Linux下Hook一个共享库函数_如果 hook 修改linux的 hookso
- 4OpenCV遍历和输出Mat矩阵中数据方法总结_opencv打印mat矩阵中的值
- 5关于修改Android.md后任然报undefined reference to XX‘异常的解决方法_md 文件 时间 undefined
- 6计算机应用基础 专 第四次,计算机应用基础第四次作业答案
- 7CVPR 2024 即插即用! CA:新注意力机制,2024年最新Linux运维彻底组件化方案实践方法_ca注意力
- 8【Hadoop】MapReduce Job Files_mapreduce.job.classpath.files
- 9全国产化异构加速GPU服务器_国产化gpu
- 10探索声音定位:Microphone-Sound-Source-Localization
【多模态融合】IS-Fusion: Instance-Scene Collaborative Fusion for Multimodal 3D Object Detection
赞
踩
论文链接:IS-Fusion: Instance-Scene Collaborative Fusion for Multimodal 3D Object Detection
代码链接:https://github.com/yinjunbo/IS-Fusion
作者:Junbo Yin, Jianbing Shen, Runnan Chen, Wei Li, Ruigang Yang, Pascal Frossard, Wenguan Wang
发表单位:北京理工大学、澳门大学、香港大学、嬴彻科技、洛桑联邦理工学院、浙江大学
会议/期刊:CVPR2024
一、研究背景
3D目标检测在自动驾驶和机器人等应用中是一个关键任务。尽管点云提供了关于3D空间的宝贵几何信息,但通常缺乏详细的纹理描述且分布稀疏,特别是在远距离场景中。为了克服这些限制,近期的趋势是通过融合点云和多视角图像的信息进行多模态3D目标检测。图像模态提供了详细的纹理和密集的语义信息,补充了稀疏的点云,从而增强了3D感知能力。
现有方法通常在统一的鸟瞰图(BEV)空间中进行特征对齐和融合,但这种全局场景级别的融合忽略了前景实例和背景区域之间的差异,可能会影响性能。例如,BEV中的对象实例通常比自然图像中的对象实例尺寸更小,且前景实例占据的网格单元显著少于背景样本,导致前景和背景样本之间的严重不平衡。因此,上述方法难以捕获对象实例周围的本地上下文(Deepinteraction),或者在解码阶段很大程度上依赖于额外的网络来迭代地细化检测(Transfusion)。
一些方法(如Sparsefusion)旨在执行对象级编码,但它们忽略了场景和实例特征之间的潜在协作。例如,场景中的漏报对象可以通过与共享相似语义信息的实例交互来增强其特征来潜在地纠正。因此,如何同时制定实例级和场景级上下文,并利用多模态融合来优雅地集成它们,仍然是一个悬而未决的问题。
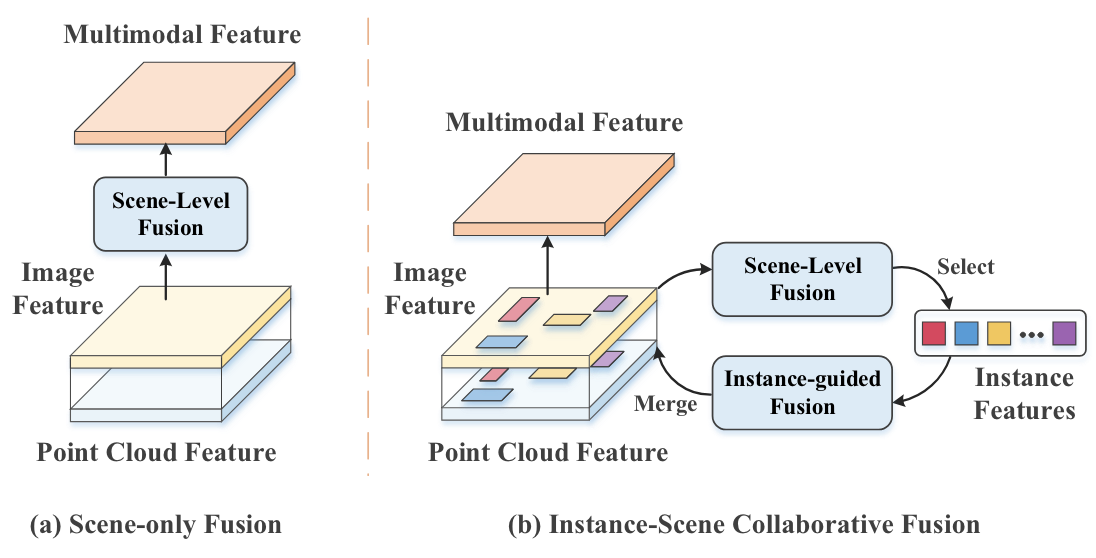
IS-Fusion 的动机: (a) 以前的方法通常侧重于多模态编码期间整个场景级别的融合。 (b)相比之下,IS-Fusion更加强调实例层面的融合,并探索实例到场景的协作以增强整体表征。
如图1所示,IS-Fusion探索了实例级和场景级融合,并鼓励实例和场景特征之间的交互以加强整体表示。它由两个关键组件组成:层次场景融合(HSF)模块和实例引导融合(IGF)模块。 HSF 旨在通过利用点到网格和网格到区域转换器来捕获各种粒度的场景特征。这还能够生成对 IGF 至关重要的高质量实例级特征。在IGF中,前景候选实例由场景特征的热图分数确定;同时,采用实例间自注意力来捕获实例关系。然后,这些实例通过可变形注意力从多模态上下文中聚合基本语义信息。此外,结合了实例到场景转换器的注意力,以强制局部实例特征与全局场景特征协作。这会产生增强的 BEV 表示,更适合 3D 对象检测等实例感知任务。
本文贡献:
-
提出IS-FUSION框架:本文提出了一种新的多模态融合框架IS-FUSION,旨在联合捕捉实例和场景级别的上下文信息,以提高3D目标检测性能。
-
设计分层场景融合(HSF)、实例引导融合(IGF)模块、实例到场景变压器注意机制:设计了点到网格和网格到区域的变压器,在不同粒度上捕捉多模态场景上下文,实现高质量的实例级特征生成。通过实例候选选择和自注意机制,挖掘实例关系,并聚合多模态上下文信息,增强场景特征。引入实例到场景的变压器注意机制,促进局部实例特征与全局场景特征的协作,生成更适合实例感知任务的BEV表示。
-
实验结果验证:在nuScenes基准测试中,IS-FUSION在所有已发布的多模态工作中表现最佳(它在 nuScenes 验证集上实现了 72.8% mAP,比现有技术 BEVFusion高出 4.3% mAP。它还比 CMT和 SparseFusion等同期工作分别高出 2.5% 和 1.8% mAP),显著提高了3D目标检测的性能,证明了所提方法的有效性和优越性。
二、整体框架
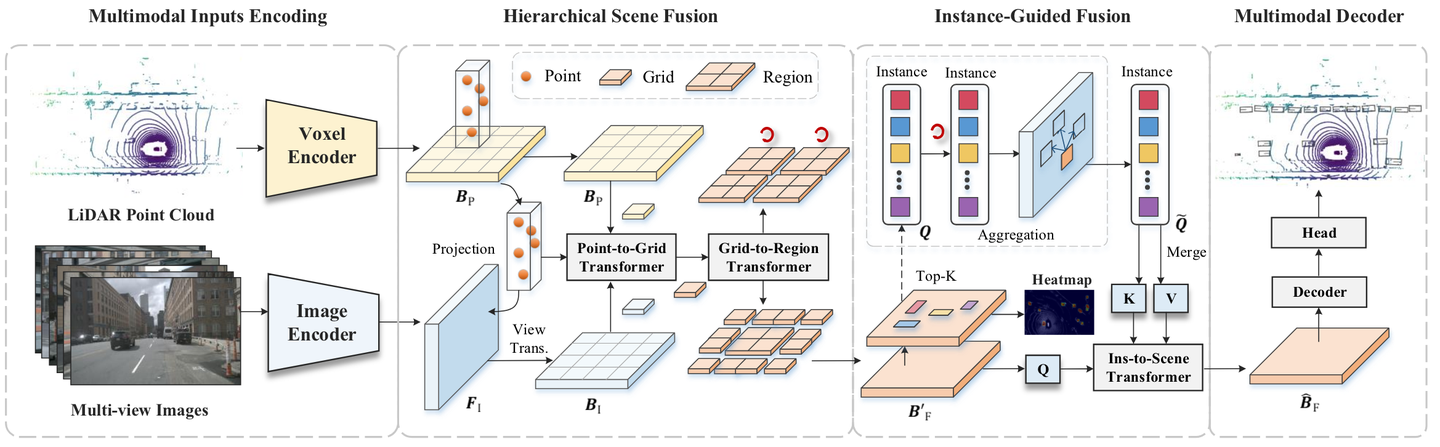
IS-Fusion 框架概述
上图包括点云和多视图图像的多模态输入,首先由模态特定的编码器处理以获得初始特征。然后,配备点到网格和网格到区域转换器的 HSF 模块利用这些特征生成具有分层上下文的场景级特征。此外,IGF 模块识别最显着的实例并聚合每个实例的多模式上下文。最后,实例到场景转换器使用这些实例将有价值的信息传播到场景,从而生成具有改进的实例感知的最终 BEV 表示。
如上图所示,每个场景都由 LiDAR 点云P表示,以及由N个相机捕获的同步 RGB 图像 这些图像使用 LiDAR 传感器进行校准。目标是设计一个能够在给定多模态输入(P, I)的情况下生成精确的 3D 边界框Y的检测模型。所提议的 IS-Fusion 模型定义为:
其中fpoint(⋅)和fimg(⋅)作为输入编码模块,fenc(⋅)表示多模态编码器(由HSF和IGF组成),fdec(⋅)是解码器。
多模态输入编码:为了处理来自异构模态的输入,首先利用模态特定的编码器来获取它们各自的初始表示,即 。对于点云数据,使用VoxelNet,对于图像数据使用Swin-Transformer。这会产生点云 BEV 特征B p和图像透视视图 (PV) 特征F I。特别地,
是通过压缩3D体素特征的高度尺寸获得的,其中W和H是BEV网格的数量沿x和y轴的单元格,C表示通道维度。
多模态编码器:多模态编码器f enc(⋅)在B p和F I之间进行跨模态特征融合,以产生融合的 BEV 特征 与之前仅关注整个场景级别的融合的多模态编码器相比,作者开发了实例级和场景级表示。为此,设计了使用两个模块的f enc(⋅),即HSF模块f HSF(⋅)和IGF模块f IGF(⋅):
其中f HSF(⋅)生成多粒度场景特征,而f IGF(⋅)进一步集成有关前景实例的关键信息。
多模态解码器:多模态解码器的目标是根据 给出的 BEV 表示
生成最终的 3D 检测Y。在本文工作中,f dec(⋅)是建立在Transformer架构的基础上的(参考DETR3D的工作),它包含几个注意力层和一个用作检测头的前馈网络。在训练过程中,应用匈牙利算法来匹配预测边界框和GT边界框。同时,Focal loss 和L1 loss 分别用于分类和 3D 边界框回归。
具体过程总结如下。
a. 输入编码:
-
点云编码:使用VoxelNet将LiDAR点云编码成鸟瞰图(BEV)特征。
-
图像编码:使用Swin Transformer将多视角图像编码成透视视角(PV)特征。
b. 分层场景融合(HSF)模块:
-
点到网格变压器:将点云特征投影到图像特征图上,并聚合成BEV网格特征。这一步通过多头自注意机制处理每个网格内的点特征。
-
网格到区域变压器:在网格和区域之间交换信息,捕捉全局场景上下文。通过分组的多头注意机制在不同的BEV网格区域间传递信息。
c. 实例引导融合(IGF)模块:
-
实例候选选择:通过热图分数确定前景实例候选,并用线性层嵌入每个实例特征。
-
上下文聚合:通过自注意机制探讨实例间关系,并通过变形注意机制聚合每个实例的多模态上下文信息。
-
实例到场景变压器:使用跨注意机制,将实例特征传递到BEV场景特征中,增强整体场景特征。
d. 多模态解码器:
-
最终的3D检测结果是基于增强后的BEV表示生成的。解码器使用了一系列注意力层和前馈网络来生成最终的3D边界框。
三、核心方法
3.1 Hierarchical Scene Fusion
给定的点云BEV特征Bp,和图像PV特征F1,使用分层场景融合HSF模块来融合得到场景表示 ,这个模块实际上包含了Point-to-Grid(点到网格) transformer f P2G(⋅)and Grid-to-Region(网格到区域) transformer f G2R(⋅):
这里,f P2G(⋅)考虑每个BEV网格中的点/像素间相关性,而f G2R(⋅)进一步挖掘网格间和区域间多模态场景上下文。直觉是不同的特征粒度捕获不同级别的场景上下文。例如,在点级别,每个元素提供有关对象的特定组件的详细信息。相比之下,网格/区域级别的特征能够捕获更广泛的场景结构和对象的分布。因此,HSF 充分利用了各种表示粒度。
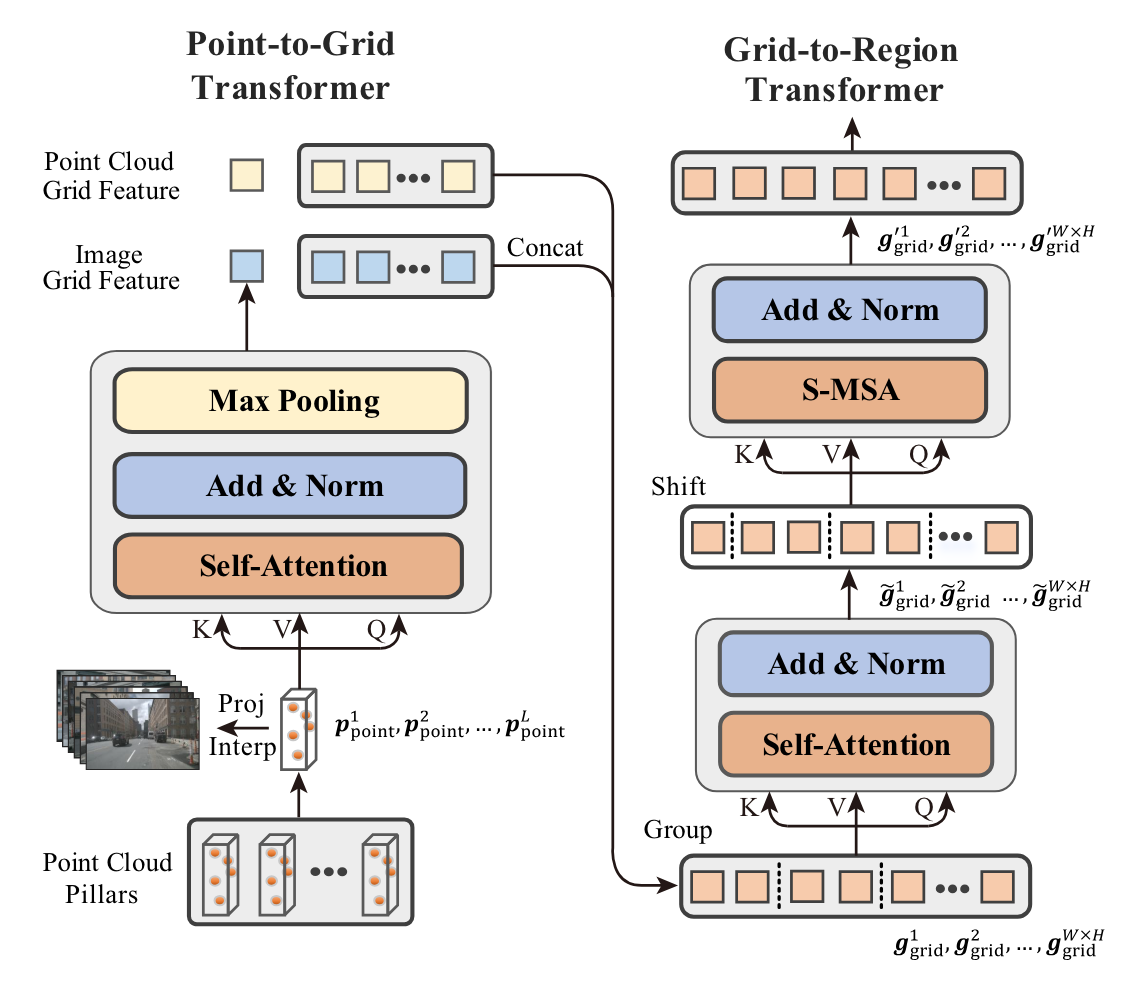
HSF 模块示意图。它首先使用点到网格变压器将点级特征聚合为网格级特征,然后通过网格到区域变压器探索网格间和区域间特征的交互。
点到网格Transformer:
首先, 表示将点云场景P离散化为voxel而获得的BEV网格,每个网格单元
都是一个包含L点
的柱子。点到网格Transformer为每个点分配其相应的图像特征,并聚合成BEV特征。
其实这里就是将 内的L点投影到图像特征F1上面,并检索其像素级特征。
其中,f proj(⋅)表示从点云到多视图像的投影过程,在图像平面产生二维坐标 ,f interp(⋅)是双线性插值函数计算非整数坐标处的特征。这样,就得到了逐点特征
。
为了处理激光雷达和相机之间潜在的校准噪声,会对网格Transformer会比较柱内的所有点。这使得每个点能够考虑更大的感受野并隐式地纠正噪声点。然后,将逐点信息与最大池化操作f max(⋅)合并:
其中f MSA(⋅)是多头自注意力,g grid是一个网格特征,将分配给图像BEV特征 。然后,通过将B I与点云 BEV 特征
相结合来计算多模态 BEV 特征B F:
其中[⋅,⋅]表示串联,f conv(⋅)由3个×3卷积层实现。
网格到区域Transformer:
除了对点间依赖关系进行建模的点到网格Transformer之外,还通过网格到区域转换器进一步探索网格间和区域间关系,以捕获全局场景上下文。这可以表示为 ,其中BF′是增强的 BEV 特征。
直观上,f G2R(⋅)可以通过将全局自注意力应用于所有网格特征 来实现。然而,由于网格单元数量众多,这在计算上可能会很昂贵。因此,选择将这些网格特征分组到不同的区域。每个区域都是由M×M网格单元
描述的子集。接下来,将每个区域视为一个整体,并通过网格间注意力在区域内的网格之间交换信息。这是通过在一组网格特征
上运行的多头注意力f MSA(⋅)来实现的:
是attention得到的网格单元。
通过,区域间注意力捕获不同区域之间的相互作用。为此,将每个区域移动(M/2,M/2)个网格单元,并对每个包含M×M网格特征的移动区域进行自注意力(如有必要,使用填充)。这是由下式给出的:
其中 f S-MSA(⋅) 表示滑动窗口自注意力, 表示移位后的新网格索引。这允许每个网格在滑动之前与来自不同区域的网格进行交互,从而捕获远程依赖关系。然后,重新排列所有注意网格特征
以获得丰富的 BEV 特征图
。
通过利用分层表示,HSF 能够将信息从各个点传播到不同的 BEV 区域。这有利于局部和全局多模式场景上下文的集成。
该模块总结如下:
a. 点到网格Transformer(Point-to-Grid Transformer)
功能:将点云特征投影到图像特征图上,并聚合成鸟瞰图(BEV)网格特征。
步骤:
-
点投影:将点云中的每个点投影到图像平面上,获取对应的图像像素特征。这一步通过一个投影函数来实现,将3D点坐标转换为图像上的2D坐标。
-
特征插值:使用双线性插值方法从图像特征图中提取对应点的特征,形成点特征矩阵。
-
多头自注意:在每个BEV网格内应用多头自注意机制,使每个点能够考虑其周围点的信息,增强特征表达。
-
特征聚合:通过最大池化操作将点特征聚合为网格特征,形成初步的BEV特征图。
b. 网格到区域Transformer(Grid-to-Region Transformer)
功能:捕捉网格之间和区域之间的全局场景上下文。
步骤:
-
网格分组:将BEV特征图划分为多个区域,每个区域包含一定数量的网格单元。
-
区域内自注意:在每个区域内应用多头自注意机制,捕捉区域内网格之间的关系,增强局部特征。
-
区域间自注意:通过偏移窗口操作,将每个区域向内偏移一个固定距离(例如M/2网格单元),并在偏移后的区域间应用自注意机制。这一步通过shifted-window自注意机制实现,使每个网格能够与更大范围内的其他网格交互,捕捉长距离依赖关系。
c. 特征融合
-
特征组合:将点到网格变压器生成的BEV网格特征与原始点云BEV特征进行通道维度上的连接(concat),形成一个多模态特征图。
-
卷积融合:通过3×3卷积操作,将连接后的多模态特征图进一步处理,生成融合后的BEV特征图。
3.2 Instance-Guided Fusion
IGF 的基本思想是挖掘每个对象实例周围的多模态上下文(例如车辆旁边的车道),同时将必要的实例级信息集成到场景特征中。例如,如果某个对象被错误地分类为场景特征中背景的一部分,可以通过将其与所有相关实例进行比较来纠正这一问题。形式上,给定 HSF 生成的场景特征B F′,式中的f IGF(⋅):
其中f sel(⋅)选择top-
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

