
- 1“智算”雄起 | 青云科技:智算中心建设、运营两不误
- 2万界星空科技MES系统:食品加工安全的实时监控与智能管理
- 3【PyTorch】解决 No module named ‘torchvision.models.utils‘_no module named 'torchvision.models.utils
- 4如何提交代码到github仓库(2022最新最详细)_github上传代码到仓库
- 5概念:四种基于模型的嵌入式软件开发、测试与验证方法_嵌入式软件建模技术
- 6vscode找不到git
- 7springboot+mysql网上书店管理系统的设计与实现—计算机毕业设计03780
- 8SVN的使用---Windows环境:概述、安装配置、使用详解、多仓库与权限控制、服务配置与管理、扩展程序_svn配置
- 9Antd Form 表单实现单项自定义请求校验_antd form自定义校验
- 10<12>基础知识——进一步了解路由表_路由表和子网
MaskedConv2d实现_masked convolution
赞
踩
PixelCNN
PixelCNN是DeepMind团队在论文Pixel Recurrent Neural Networks提出的一种生成模型,实际上这篇论文共提出了两种架构:PixelRNN和PixelCNN,两者的主要区别是前者用LSTM来建模,而PixelCNN是基于CNN的,相比RNN,CNN计算更高效,所以这里只讨论PixelCNN。前面已经说过PixelCNN也属于自回归生成模型,相比NADE,PixelCNN只是采用了更先进的CNN网络来进行建模。对于一张大小为[公式]的图像[公式],可以将其看成一个一维的序列:[公式](按行展开),那么[公式]可以分解成:

这里[公式]指的就是根据之前的像素值来计算[公式]的概率分布。对于RGB图像,每个像素包含red,green和blue三个颜色通道值,这里可以进一步按照通道来拆解条件分布:

这里认为三个通道值是按照red->green->blue的顺序产生的。
对于PixelCNN,最关键的问题是如何用CNN来对条件分布[公式]建模,如下图所示,这里采用3x3卷积,红色的pixel为要预测的pixel,它的输入应该是位于其左上部分的所有像素(这里的左上指的是当前pixel上面所有的pixels以及所在行的左边pixels,蓝色的pixel属于这个范围),但是标准的3x3卷积输入为以当前像素所在位置为中心的3x3区域(共9个像素),此时需要对卷积核做mask处理:生成一个3x3大小的mask,左上位置的元素置为1,而右下位置的元素置为0。这种卷积我们称之为masked convolution。3x3 masked conv的感受野比较小,只包含左上的4个pixel,但当我们堆积很多masked conv层之后,其感受野就可以扩展到左上全部像素范围(实际上会存在问题,后面会讲述这个问题以及处理方法)。
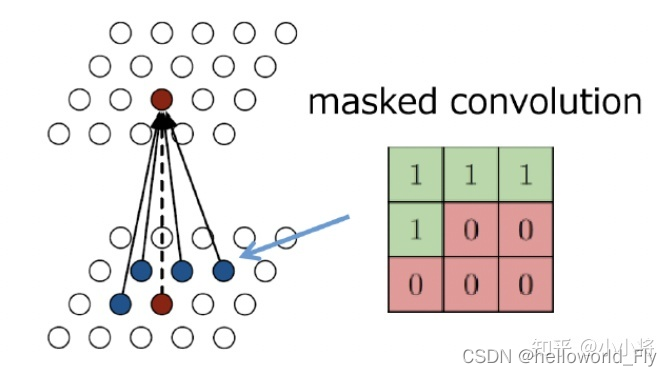
对于masked convolution,有两种类型,第一种就如上面所示,我们除了mask掉右下位置的pixel外还mask掉当前的pixel,这种处理对于输入图像是必须的,毕竟这里要预测的是当前pixel,我们不希望提前让网络知道它。这种mask掉中心pixel的masked conv记为Mask A,它用在网络的第一层。第二种类型是不mask掉中心pixel,这种方式称为Mask B,它用在网络第一层之后的所有层,因为一旦我们对输入图像做了Mask A之后,后面的masked conv需要看到之前已经提取的特征,否则网络的表征能力就大大降低了。下图展示了两种masked conv,区别就是是否连接当前的blue通道。
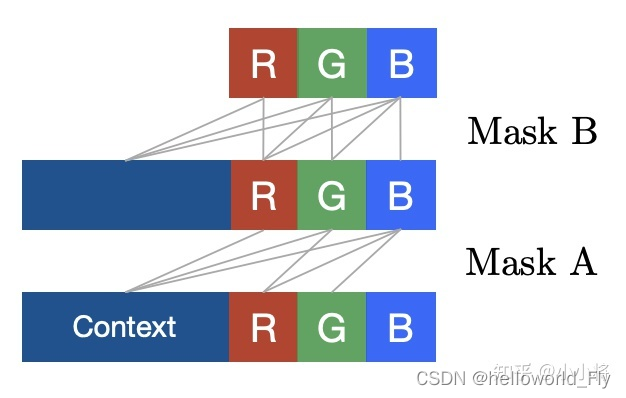
对于RGB三个通道,我们可以将每层的特征在channel维度分成三个部分,每个部分对应其中一个通道,然后可以通过对卷积核的输入通道做mask处理来限制连接:比如要预测green通道,此时输入应该只包括之前所有的pixels特征以及当前pixel的red通道对应的特征。对于PixelCNN,训练过程是并行的,即可以通过一次前向处理得到所有pixel的条件分布,因为对于训练数据我们已知图像的所有像素值,但是在生成过程(推理过程)是序列处理的,此时需要逐个pixel进行预测,共需要[公式]次前向预测。
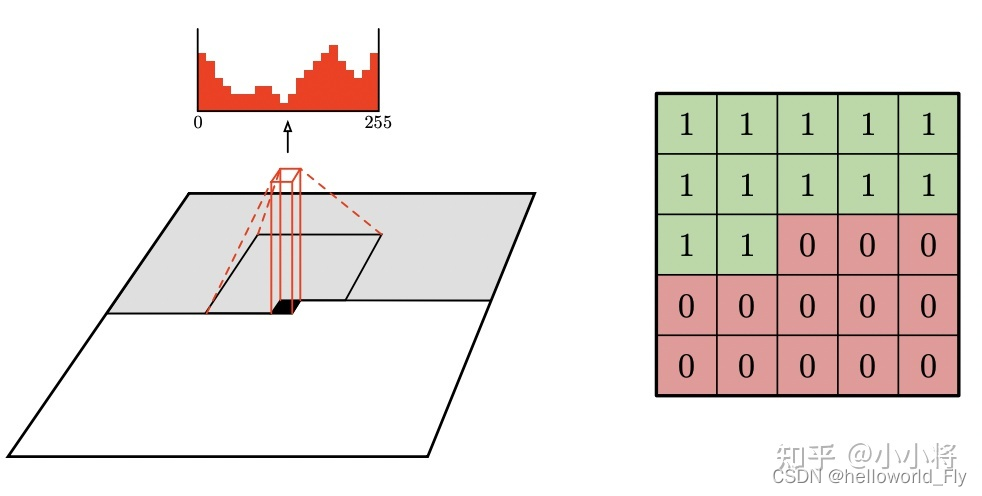
PixelCNN不采用下采样的操作(如stride>1的pooling或conv),所有的卷积层都是padding=same模式,最后模型的输出和原始图像大小一致,分别预测各个位置的pixel。如果要采用下采样,可以像PixelCNN++那样设计成encoder-decoder架构。对于自然图像,每个像素值的取值范围为0~255,共256个离散值,此时条件分布就是多项分布(multinomial distribution),实际处理时我们用基于softmax的多分类预测概率值;对于MNIST这样的数据,每个像素值取值是0或者255,只有2个值,可以认为条件分布是伯努利分布,可以用基于sigmoid的二分类来预测概率。
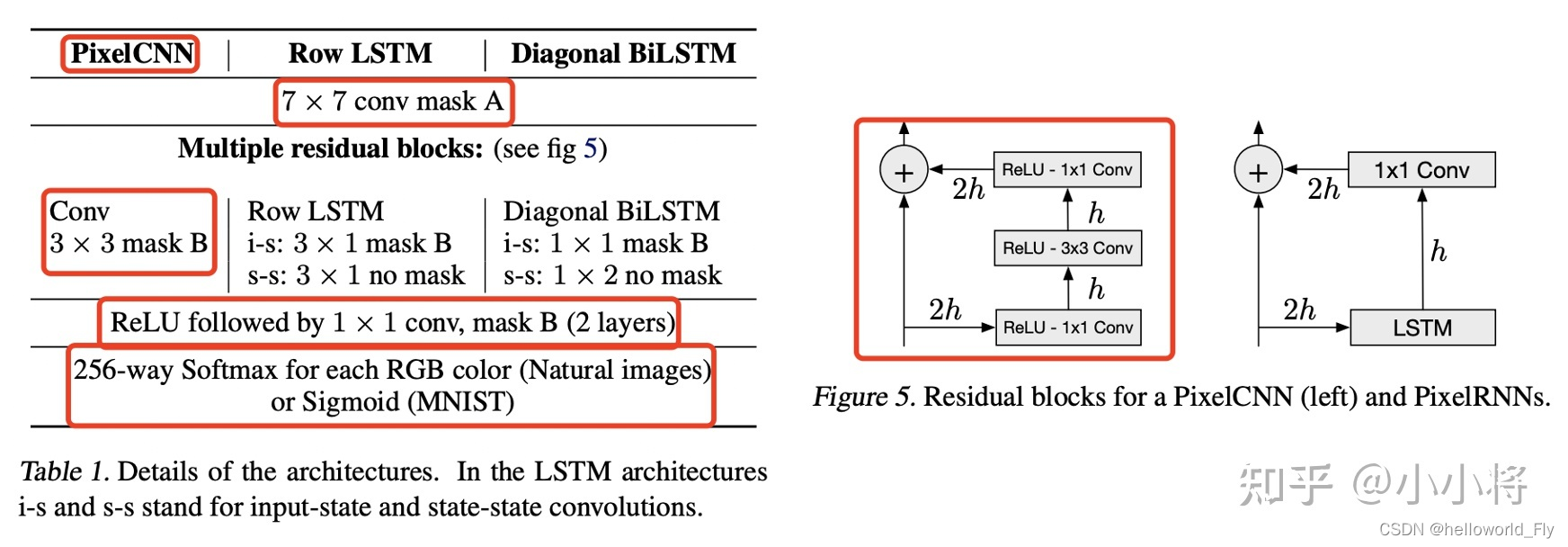
PixelCNN的网络结构如下图所示,首先第一层是一个7x7的conv mask A,前面说过,第一层要mask掉conv中心位置的pixel;然后是多个residual blocks,residual block的具体结构如右图所示:1x1 conv -> 3x3 conv mask B->1x1 conv+shortcut;residual blocks之后是2个1x1 conv mask B;最后是预测层(采用1x1 conv)+256-softmax或者sigmoid。这里注意的是对于1x1 conv是不需要mask的,此时就等价于mask B。
下面我们基于MNIST数据来实现PixelCNN,MNIST数据集相对简单,一方面图像只有单通道,另外一方面图像像素值只有2种取值,这里参考了keras的实现,全部的代码见:https://github.com/xiaohu2015/nngen。首先要实现的是MaskedConv2d:
class MaskedConv2d(nn.Conv2d): """ Implements a conv2d with mask applied on its weights. Args: mask_type (str): the mask type, 'A' or 'B'. in_channels (int) – Number of channels in the input image. out_channels (int) – Number of channels produced by the convolution. kernel_size (int or tuple) – Size of the convolving kernel """ def __init__(self, mask_type, in_channels, out_channels, kernel_size, **kwargs): super().__init__(in_channels, out_channels, kernel_size, **kwargs) self.mask_type = mask_type if isinstance(kernel_size, int): kernel_size = (kernel_size, kernel_size) mask = torch.zeros(kernel_size) mask[:kernel_size[0]//2, :] = 1.0 mask[kernel_size[0]//2, :kernel_size[1]//2] = 1.0 if self.mask_type == "B": mask[kernel_size[0]//2, kernel_size[1]//2] = 1.0 self.register_buffer('mask', mask[None, None]) def forward(self, x): self.weight.data *= self.mask # mask weights return super().forward(x)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
然后根据MaskedConv2d来构建ResidualBlock,注意这里的3x3 conv采用mask B:
class ResidualBlock(nn.Module): """ Residual Block: conv1x1 -> conv3x3 -> conv1x1 """ def __init__(self, in_channels): super().__init__() self.conv1 = nn.Sequential( nn.Conv2d(in_channels, in_channels // 2, 1), nn.ReLU(inplace=True) ) # masked conv2d self.conv2 = nn.Sequential( MaskedConv2d("B", in_channels // 2, in_channels // 2, 3, padding=1), nn.ReLU(inplace=True) ) self.conv3 = nn.Sequential( nn.Conv2d(in_channels // 2, in_channels, 1), nn.ReLU(inplace=True) ) def forward(self, x): inputs = x x = self.conv1(x) x = self.conv2(x) x = self.conv3(x) return inputs + x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
最后基于MaskedConv2d和ResidualBlock来构建PixelCNN:
class PixelCNN(nn.Module): """ PixelCNN model """ def __init__(self, in_channels=1, channels=128, out_channels=1, n_residual_blocks=5): super().__init__() # we use maskedconv "A" for the first layer self.stem = nn.Sequential( MaskedConv2d("A", in_channels, channels, 7, padding=3), nn.ReLU(inplace=True) ) self.res_blocks = nn.Sequential( *[ResidualBlock(channels) for _ in range(n_residual_blocks)] ) # 这里我采用了两个3x3 conv,论文采用的是1x1 conv self.head = nn.Sequential( MaskedConv2d("B", channels, channels, 3, padding=1), nn.ReLU(inplace=True), MaskedConv2d("B", channels, channels, 3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(channels, out_channels, 1) ) def forward(self, x): x = self.stem(x) x = self.res_blocks(x) x = self.head(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
PixelCNN的训练和生成过程的实现如下所示:
训练
for epoch in range(epochs):
print("Start training epoch {}".format(epoch,))
for i, (images, labels) in enumerate(train_loader):
images = (images > 0.33).float() # convert to 0, 1
images = images.cuda()
logits = model(images)
loss = F.binary_cross_entropy_with_logits(logits, images)
optimizer.zero_grad()
loss.backward()
optimizer.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
生成
逐个pixel生成
with torch.no_grad():
# Iterate over the pixels because generation has to be done sequentially pixel by pixel.
for h in range(H):
for w in range(W):
for c in range(C):
# Feed the whole array and retrieving the pixel value probabilities for the next pixel.
logits = model(pixels)[:, c, h, w]
probs = logits.sigmoid()
# Use the probabilities to pick pixel values and append the values to the image frame.
pixels[:, c, h, w] = torch.bernoulli(probs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
部分生成的数据如下所示,这个效果并不是太好,部分可能看不出来是手写数字,一方面是我们没有进行太多的优化,另外原始的PixelCNN确实比较难优化,未来讲述的GatedPixelCNN将大大改善这个生成效果。

