
- 1Hadoop集群安装部署详细过程_安装集群时,第一步需要进行什么操作a执行安装
- 2大数据与产业发展之干货辑录(下篇)
- 3CUDA error: device-side assert triggered Assertion t 」= 0 && t n classes failed_cuda error assert 0
- 4将远控融入业务,向日葵SDK和API服务有何区别?
- 5Oracle NoSQL Database 的集成与开发者工具
- 6机器学习指南_机器学习-快速指南
- 7NLP(nature language processing)自然语言处理学习_jiagu natural language processing
- 8【产品经理修炼之道】- 开启敏捷流程
- 9docker基础超详细教程,一篇文章帮助你从零开始学习docker,从入门到实战_docker教程
- 10用RLHF微调提升AI大语言模型的文本摘要与生成式摘要_大语言模型微调 摘要生成
大模型部署_书生浦语大模型 _作业1基本理论_上海人工智能实验室 书生浦语
赞
踩
书生·浦语大模型全链路开源体系
1 、简介:
上海人工智能实验室与商汤科技联合香港中文大学、复旦大学发布新一代大语言模型书生·浦语2.0(InternLM2)。这个大模型包含70亿和200亿两种参数规格,以及基座、对话等版本,向全社会开源并提供免费商用授权。
书生·浦语2.0(英文名:InternLM2)核心理念:回归语言建模的本质,致力于通过提高语料质量及信息密度,实现模型基座语言建模能力获得质的提升,进而在数理、代码、对话、创作等各方面都取得长足进步,综合性能达到同量级开源模型的领先水平。InternLM2是在2.6万亿token的高质量语料上训练得到的。沿袭第一代书生·浦语(InternLM)的设定,InternLM2包含7B及20B两种参数规格及基座、对话等版本,满足不同复杂应用场景需求。秉持“以高质量开源赋能创新”理念,上海AI实验室继续提供InternLM2免费商用授权。2023年6月7日正式上线千亿大模型InternLM,2024年1月17日InternLM2开源
- 各个平台的开源地址
-
- GitHub:github.com/InternLM/InternLM
-
- HuggingFace:huggingface.co/internlm
-
- ModelScope:modelscope.cn/organization/Shanghai_AI_Laboratory
-
- OpenXLab:openxlab.org.cn/models/InternLM
-
2、 内容
官网:模型-OpenXLab
哔站:书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili
(1)书生浦语大模型发展历程

 (2)体系
(2)体系

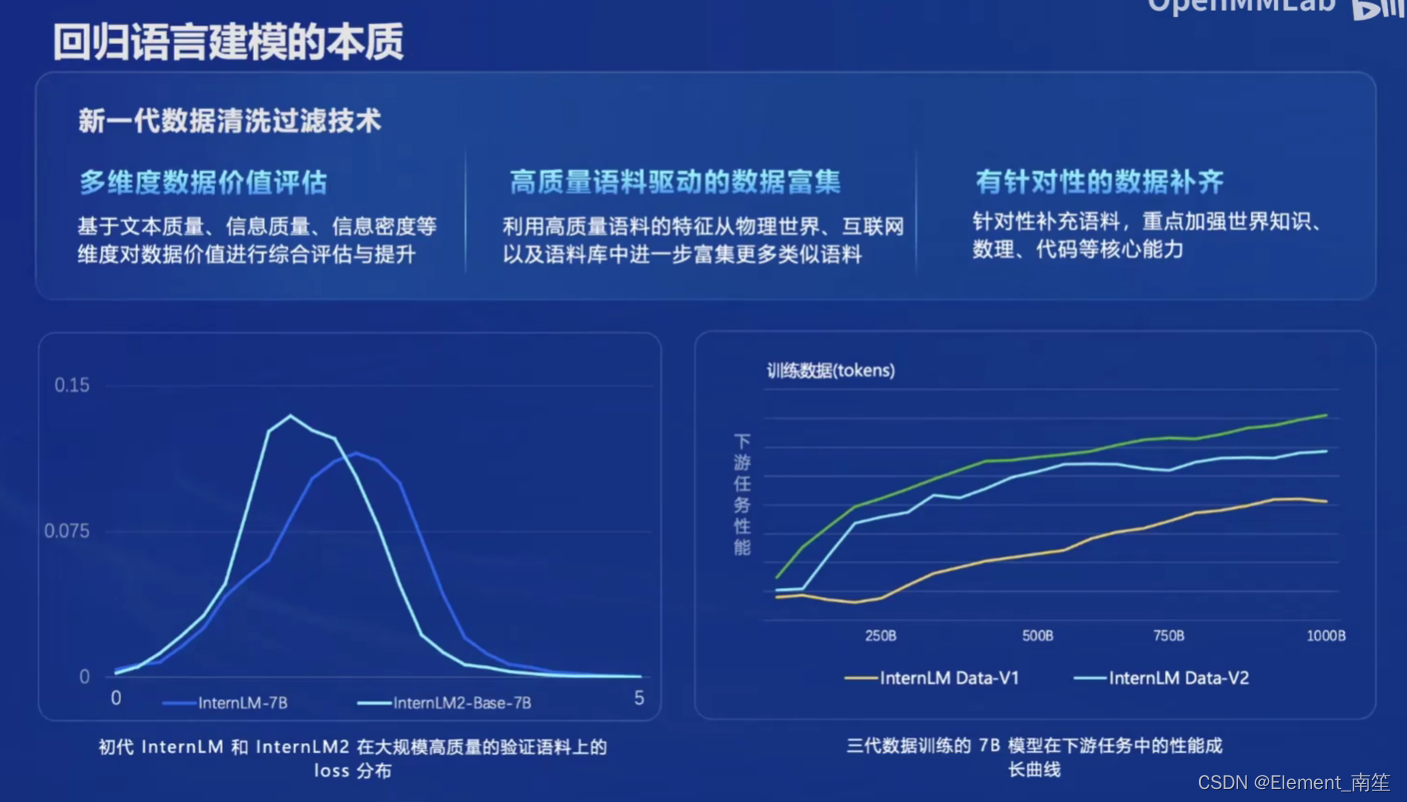
(3)亮点

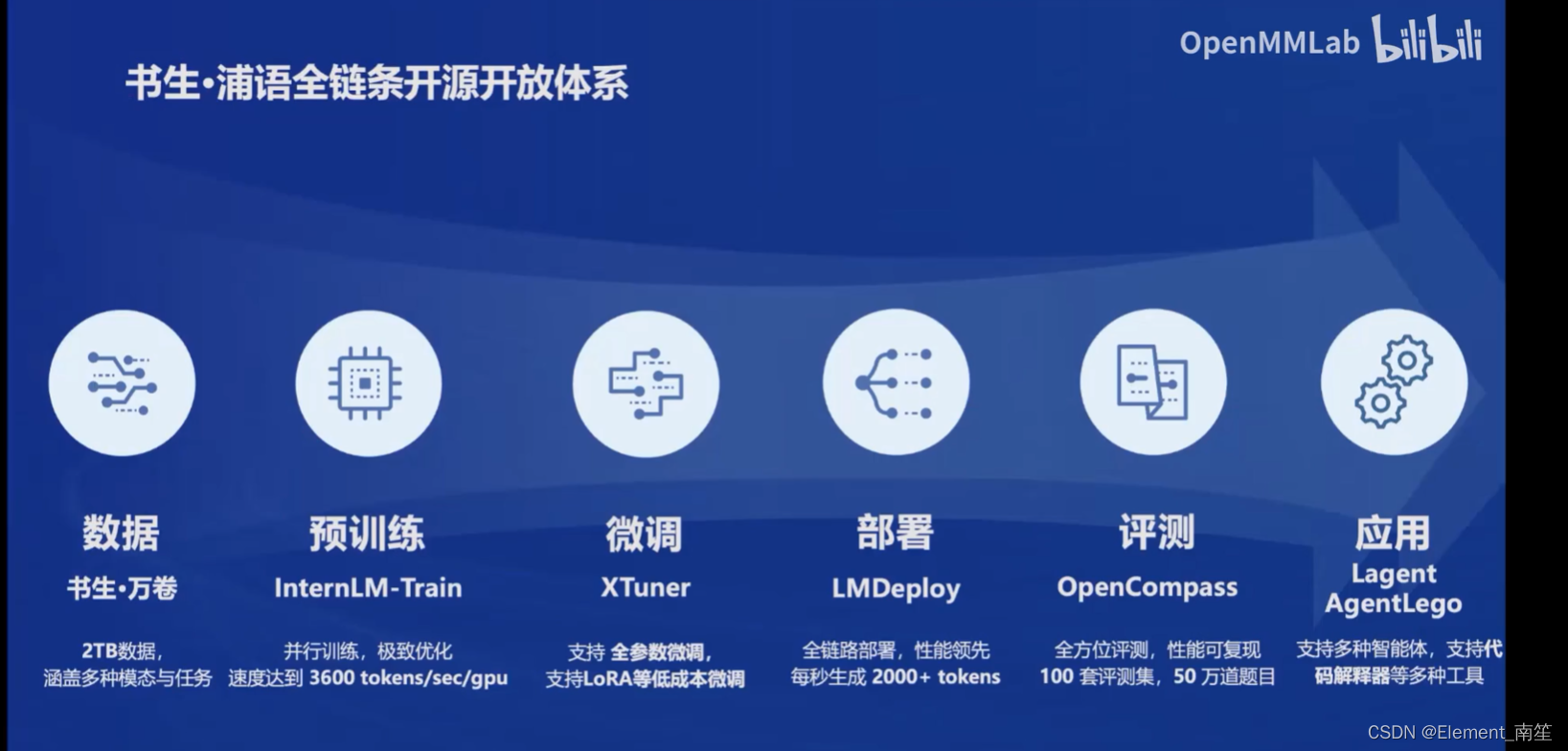
(4)全链路体系构建
数据集-OpenDataLab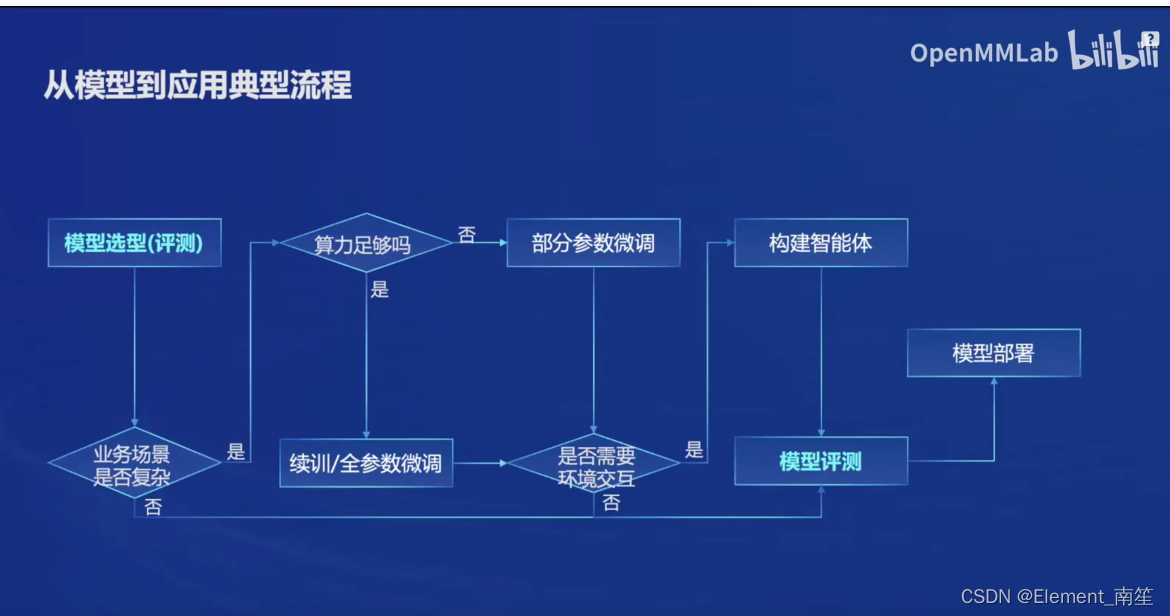 数据集-OpenDataLab:
数据集-OpenDataLab:
上海人工智能实验室(上海AI实验室)于2023年8月14日宣布开源发布“书生·万卷” 1.0多模态预训练语料。
据了解,“书生·万卷”的主要构建团队——OpenDataLab旨在建设面向人工智能开发者的超大规模、高质量、多模态开放数据服务平台,致力于打造国内公开数据资源的基础建设。
目前,该平台已建立共享的多模态数据集5500个,涵盖超过1万亿token文本语料、60亿张图像、8亿个视频片段和100万个3D模型。




 3、技术报告
3、技术报告
InternLM2 : https://arxiv.org/pdf/2403.17297.pdf
InternLM2是由上海人工智能实验室、商汤科技集团、香港中文大学和复旦大学共同开发的一款开源大型语言模型(LLM)。它在多个维度和基准测试中超越了前身模型,包括长文本建模和开放式主观评估。InternLM2的预训练过程非常注重多样化数据类型的准备,如文本、代码和长文本数据,并通过创新的预训练和优化技术实现了高效的长期依赖捕捉。
InternLM2在预训练阶段首先使用4k的上下文文本,然后过渡到高质量的32k文本进行进一步训练。它采用了Group Query Attention(GQA)以较小的内存占用推断长序列,并在预训练和微调阶段表现出色,特别是在200k的“针堆”测试中。此外,InternLM2还通过监督式微调(SFT)和一种新颖的条件在线强化学习(COOL RLHF)策略进一步对齐,以解决人类偏好冲突和奖励黑客问题。
InternLM2模型在不同训练阶段和不同模型大小的发布,为社区提供了对模型演化的洞察。它在多个下游任务上的表现经过了全面评估,包括语言和知识、推理和数学、编程、长文本建模和工具使用等方面。评估结果显示,InternLM2在多个任务上均取得了优异的性能。
在基础设施方面,InternLM2使用了InternEvo这一高效轻量级的预训练框架,该框架支持在数千个GPU上扩展模型训练。它通过数据、张量、序列和流水线并行性,以及各种Zero Redundancy Optimizer (ZeRO)策略,显著降低了训练所需的内存占用。
在模型结构方面,InternLM2采用了与LLaMA相似的Transformer架构,并进行了一些调整以提高效率和支持多样化的张量并行性变换。这些调整包括合并Wk、Wq和Wv矩阵,以及重新配置矩阵布局以适应不同的分布式计算环境。
在对齐方面,InternLM2采用了监督式微调和强化学习从人类反馈(RLHF)的两阶段方法。提出了COOL RLHF,它采用条件奖励模型来协调不同的偏好,并执行多轮PPO以减轻每个阶段出现的奖励黑客问题。
最后,在评估和分析方面,InternLM2在多个基准测试中展示了其卓越的性能,包括综合考试、语言和知识、推理和数学、编程、长文本建模和工具使用等。此外,还讨论了数据污染的问题,以及它对模型性能和可靠性的影响。


