
- 1彩色图像处理之彩色图像直方图处理的python实现——数字图像处理_颜色直方图 python detect
- 2手把手教你打造高精度STM32数字时钟,超详细步骤解析_stm32rtc实现数字钟
- 3java中Error与Exception的区别
- 4安装部署ofbiz 16.11.02
- 5为什么Python被称为“胶水语言”?它的特点有哪些?_python为什么被称为万能胶水语言
- 6网络协议学习---IPMI协议学习
- 7springboot的配置指南
- 8springboot搭建流式响应服务,SSE服务端实现_eventsources.createfactory
- 9SpringBoot 2.1.x微服务通过DockerMaven插件构建docker镜像部署_springboot2.1 docker
- 10IDEA开发Spark应用实战(Scala)_idea scala spark
17 种(高级)RAG 技术,将您的 RAG 应用原型转变为生产就绪型解决方案_rag最新综述
赞
踩
一系列 RAG 技术可帮助您将 RAG 应用开发成为稳健且持久的应用
如今,人们发展成为生成式人工智能专家的速度非常惊人。他们每个人都宣称生成式人工智能将带来下一场工业革命。
这是一个很大的承诺,但我同意,我认为这次是真的。人工智能最终将彻底改变我们的工作和生活方式。我无法想象我们会陷入下一个 人工智能寒冬。
LLM 和多模态模型非常有用,并且“相对”容易实施到现有流程中。一个向量数据库,几行代码来处理原始数据,以及一些 API 调用。
就是这样。—— 至少在理论上是这样。
虽然这听起来很简单,但 Matt Turck 最近的一篇 LinkedIn 帖子可能更好地描述了该行业的真正进展:
2023 年:“我希望生成式人工智能不会把我们都杀了!”
2024 年:“我希望生成式人工智能在我的公司从概念验证实验发展到小型生产部署,以便在未来 12-18 个月内阅读 PDF 文件!”
- Matt Turck
构建原型很容易。将其转化为生产就绪的东西很难。
以下帖子面向在过去一个月中构建了他们的第一个 LLM 应用并开始将其产品化的人。我们将研究 17 种技术,您可以尝试使用这些技术来缓解 RAG 流程中的一些陷阱,并逐步将您的应用程序开发成为一个强大而强大的解决方案。
为了了解我们有哪些机会来改进标准 RAG 流程,我将简要回顾一下创建简单 RAG 应用所需的组件。您可以随意跳过此部分,直接进入 “高级”技术。
目录
- 朴素 RAG – 简要回顾
- 如何应对 RAG 的潜在陷阱?
- \1. 原始数据创建/准备
- (1) 以文本块自解释的方式准备数据
- \2. 索引/分块 – 分块优化
- (2) 分块优化 – 滑动窗口、递归结构感知分割、结构感知分割、内容感知分割
- (3) 提高数据质量 – 缩写、技术术语、链接
- (4) 添加元数据
- (5) 优化索引结构 – 全搜索 vs. 近似最近邻,HNSW vs. IVFPQ
- (6) 选择合适的嵌入模型
- \3. 检索优化 – 查询翻译 / 查询重写 / 查询扩展
- (7) 使用生成答案进行查询扩展 – HyDE 等
- (8) 多个系统提示
- (9) 查询路由
- (10) 混合搜索
- \4. 检索后:如何改进检索步骤?
- (11) 句子窗口检索
- (12) 自动合并检索器(又称父文档检索器)
- \5. 生成 / 代理
- (13) 选择合适的 LLM 和提供商 - 开源与闭源、服务与自托管、小型模型与大型模型
- (14) 代理
- \6. 评估 – 评估我们的 RAG 系统
- (15) LLM 作为评判者
- (16) RAGAs
- (17) 持续从应用程序和用户那里收集数据
- 总结
朴素 RAG – 简要回顾
利用 RAG,我们站在巨人的肩膀上,利用现有的概念和技术,并以适当的方式将它们结合起来。
许多技术起源于搜索引擎领域。其目标是围绕大型语言模型 (LLM) 构建流程,为模型提供正确的数据,以做出决策或总结信息。
下图展示了我们在构建此类系统时使用的一系列技术。

RAG 背后的技术 – 作者图片
除了 Transformer 模型之外,我们还使用了一系列技术,例如:
- 语义搜索技术
- 准备和处理文本数据的技术
- 知识图谱、较小的分类/回归/NLP 模型等
所有这些技术都已经存在多年。向量搜索库 FAISS 于 2019 年发布。此外,文本向量化也不是什么新鲜事。[Ilin, 2024]
RAG 只是连接这些组件,以解决特定的问题。
例如,必应搜索将其传统的“BING”网络搜索与大型语言模型的功能相结合。这使得他们的聊天机器人能够回答“真实”生活数据的问题,例如:
- “今天谷歌的股价是多少?”
下图显示了标准的 RAG 流程。当用户提出问题时,朴素 RAG 会将用户的问题直接与我们向量数据库中的任何内容进行比较。
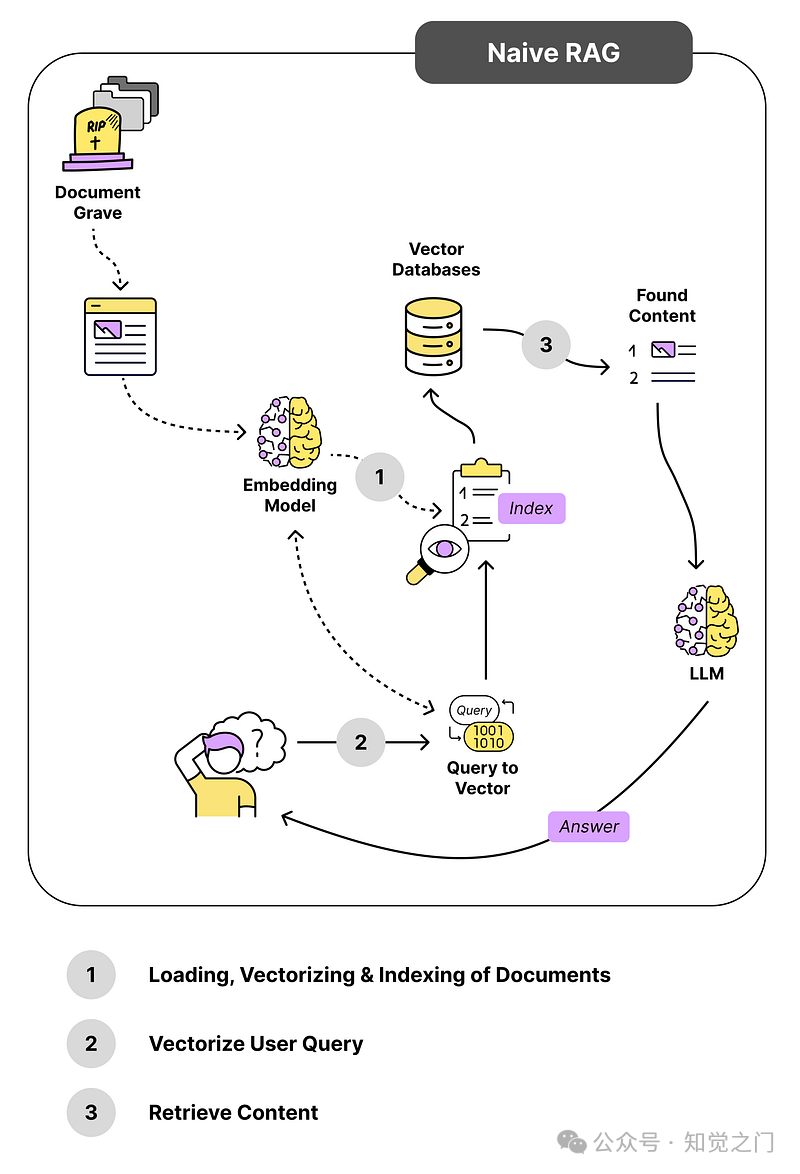
朴素 RAG 系统中的组件和步骤 – 作者图片
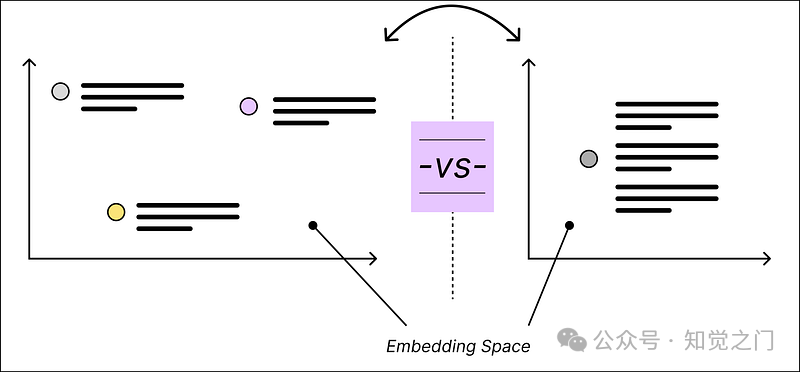
*我们感兴趣的是找到相似的内容。* 相似内容是指在我们的向量空间中彼此接近的内容。距离是通过计算 *余弦相似度* 来衡量的,例如。
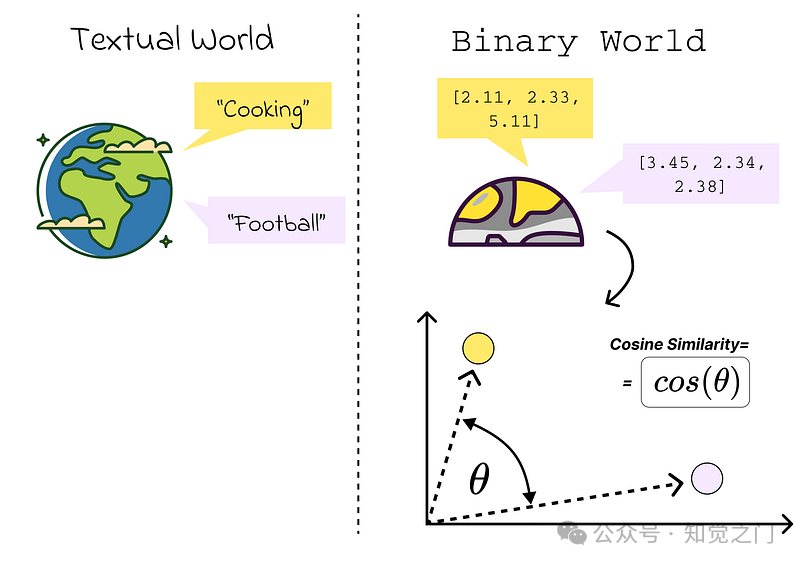
通过使用嵌入模型从文本到二进制世界 – 作者图片
示例:
问题:“汤姆·布雷迪打过什么位置?”
假设我们的向量数据库中有两个主要数据源:
- 汤姆·布雷迪的维基百科文章。
- 来自食谱的文章。
在下面的示例中,来自维基百科的内容应该更相关,因此更接近用户的问题。

向量空间示例 – 作者图片
但是“接近”到什么程度才算“足够接近”?
我们无法为相似度分数设置一个阈值,以便区分相关内容和不相关内容。您可以自己尝试一下,但您可能会意识到这样做是不切实际的。
找到内容了吗?让我们构建提示
现在我们找到了一些与用户问题相似的内容,我们需要将所有这些内容打包成一个有意义的提示。我们得到了一个至少包含 3 个构建块的提示。
- 系统提示,用于告诉大型语言模型如何表现
- 用户问题
- 上下文,执行相似性搜索后找到的相关文档
一个合适的提示模板可能如下所示:

(简化的)使用找到的上下文的提示模板 – 作者图片
系统提示中的 “… 仅使用提供的信息” 部分将大型语言模型变成了一个处理和解释信息的系统。在这种情况下,我们不会直接利用模型的知识来回答问题。
就是这样。—— 就是这么简单。一个向量存储、一个嵌入模型、一个大型语言模型、几行 Python 代码 —— 当然还有一些文档。
当我们扩展这些系统并将它们从原型转变为生产解决方案时,我们就会回到现实。
在这个过程中,我们很可能会遇到各种陷阱,例如:
- (有价值的内容与干扰因素)我们的最近邻搜索总是会找到相关内容,但 这些内容的相关性如何? 我们将与回答用户问题无关的数据点称为干扰因素。
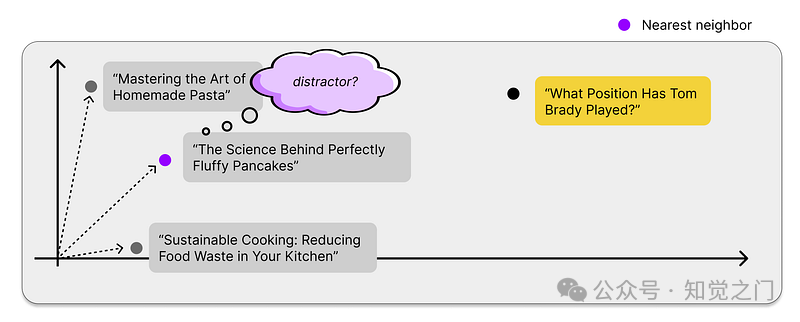
干扰因素还是有价值的内容?-- 作者图片
- (块优化)各个内容块应该是什么大小,才能既足够具体又包含足够的上下文信息?
- (监控/评估)我们如何在运营中监控我们的解决方案?(LLMOps)
- (代理/多重提示)我们如何处理更复杂的查询,这些查询无法通过单个提示解决?
如何应对 RAG 的潜在陷阱?
如上所述,我们有不同的组件相互交互。这为我们提供了一系列可能的方法来提高整个系统的性能。
基本上,我们可以尝试改进以下 5 个流程步骤:
- 检索前:将嵌入内容摄取到向量存储中
- 检索:找到相关内容
- 检索后:在将结果发送到大型语言模型之前对其进行预处理?
- 生成:使用提供的上下文来解决用户的问题
- 路由:请求的总体路由,例如代理方法将问题分解,并在模型之间来回发送
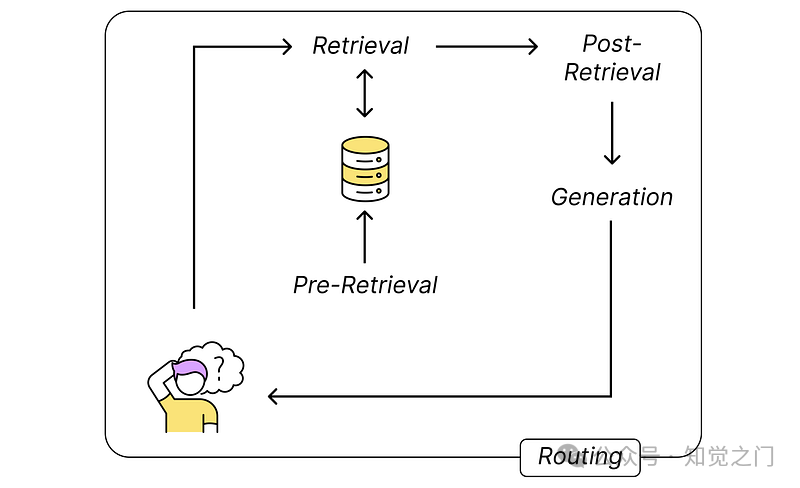
RAG 组件的高级分解 – 作者图片
如果我们更仔细地观察它们,就会得到下图。
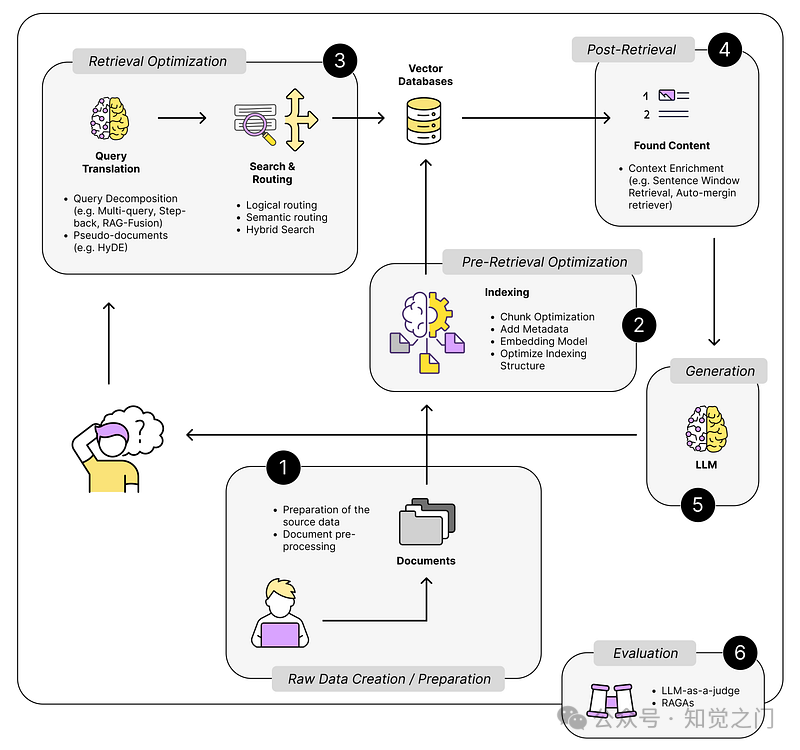
高级 RAG 技术 – 作者图片
让我们来看看它们中的每一个。
我们从最明显和最简单的方法开始 – 数据质量。对于大多数 RAG 用例,它是文本数据,例如一些维基文章。
1. 原始数据创建/准备
我们并非总是需要使用现有的数据。我们通常可以影响文档的创建过程。
通过大型语言模型和 RAG 应用程序,我们突然被迫构建我们的知识库。在朴素 RAG 中,我们搜索信息片段,这些片段在某种程度上与用户的问题相似。
这样,模型永远不会看到维基的整个上下文,而只会看到单个文本片段。当文档包含以下内容时,就会出现问题,例如:
- 特定领域甚至特定文档的缩写
- 链接到维基百科其他部分的文本段落
如果一个没有背景知识的人很难理解文本片段背后的全部含义,那么大型语言模型也会遇到困难。
在本文的后面部分,您将找到一些技术,这些技术试图在检索步骤之后或期间解决这些问题。
在理想的世界中,我们不需要它们。
我们维基百科中的每个部分都应该尽可能易于理解,这对我们人类来说也更容易理解。这样,我们就可以同时提高维基百科的可读性和 RAG 应用程序的性能。双赢。
以下示例展示了我们如何通过以正确的方式设置内容来简化 RAG 应用程序的工作。
(1) 以文本块自解释的方式准备数据
在下图中,你可以看到一个类似于你在教程和技术文档中经常看到的例子。如果我们没有纯LLM,而是一个多模态模型,LLM将很难完全理解左侧版本 1 中的内容。版本 2 至少给了它更好的机会去理解。
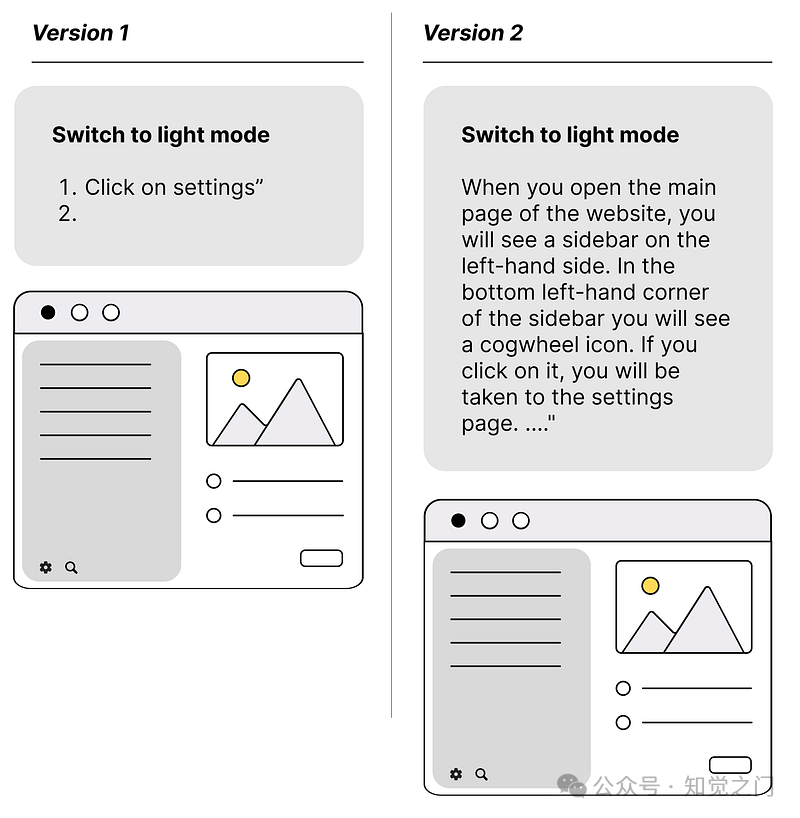
文档的结构方式会影响 RAG 系统的性能 – 图片由作者提供
RAG流程的下一步是以有意义的方式对数据进行分块,将其转换为嵌入,并对其进行索引。
2. 索引/分块 – 分块优化
Transformer 模型具有固定的输入序列长度。因此,我们发送到LLM和嵌入模型的提示的标记大小是有限的。
但我认为,这不是一个限制。
考虑文本片段和提示的最佳长度是有意义的,因为这对性能有重大影响,例如:
- 响应时间(+成本)
- 相似性搜索准确性
- 等等
有各种可用的文本分割器来对文本进行分块。
(2) 分块优化 – 滑动窗口、递归结构感知分割、结构感知分割、内容感知分割
分块的大小是一个需要考虑的参数,它取决于你使用的嵌入模型及其在标记方面的能力,像基于 BERT 的句子转换器这样的标准转换器编码器模型最多接受 512 个标记,一些嵌入模型能够处理更长的序列,8191 个标记甚至更多。
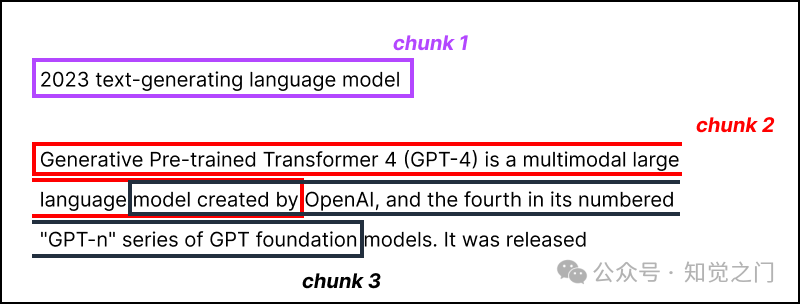
但更大并不总是更好。我宁愿在一本书中找到包含两条最重要信息的两个句子,也不愿找到 5 页包含答案的页面。
大块 vs. 小块,一个数据点 vs. 多个数据点 – 图片由作者提供
这里的折衷方案是:
足够的上下文供LLM进行推理 vs. 足够具体的文本嵌入以便有效地执行搜索
有多种方法可以解决这些块大小选择问题。在 LlamaIndex 中,这由 NodeParser 类涵盖,该类具有一些高级选项,例如定义自己的文本分割器、元数据、节点/块关系等。
确保正确捕获所有信息并且没有任何部分被遗漏的最简单方法是使用滑动窗口将整个文本严格分成几部分。
这很简单,文本部分重叠 – 就是这样。
使用滑动窗口进行分块 – 图片由作者提供
除此之外,你还可以尝试许多其他分块技术来改进分块过程,例如:
- 递归结构感知分割
- 结构感知分割(按句子、段落)
- 内容感知分割(Markdown、LaTeX、HTML)
- 使用 NLP 进行分块:跟踪主题变化
(3) 提高数据质量 – 缩写、技术术语、链接
数据清理技术可以去除不相关的信息,或者将文本片段放入上下文中,使其更容易理解。
有时,如果你知道这本书的上下文,那么较长文本中特定段落的含义就非常清楚了。如果缺少上下文,就很难理解。
缩写、特定的技术术语或公司内部术语会使模型难以理解其全部含义。
下图显示了一些示例。
- 如果你对篮球一无所知,你就永远不会将 MJ 与“迈克尔·乔丹”联系在一起。
- 如果你不知道这句话描述的是供应链环境中的某些内容,你可能会认为 PO 的意思是“邮局”或任何其他以 P 和 O 开头的词语组合。

缩写可能会让人感到困惑 – 图片由作者提供
为了缓解这个问题,我们可以尝试在处理数据时获取必要的额外上下文,例如,使用缩写翻译表将缩写替换为全文。
当你围绕文本到 SQL 的用例工作时,你肯定需要这样做。许多数据库中的字段名称通常都很奇怪。通常只有开发者和上帝才知道某个特定字段名称背后的含义。
SAP(企业资源规划解决方案)经常使用德语单词的缩写形式来标记其字段。字段“WERKS”是德语单词“Werkstoff”的缩写,它描述了零件的原材料。
当然,这对定义数据库结构的团队来说可能是有意义的。其他人将很难理解,包括我们的模型。
(4) 添加元数据
你可以在所有向量数据库中向向量数据添加元数据。元数据可以在我们执行向量搜索之前帮助(预先)过滤整个向量数据库。
假设我们向量存储中的一半数据是针对欧洲用户的,另一半是针对美国用户的。如果我们知道用户的地理位置,我们就不想搜索整个数据库,我们希望能够直接搜索相关位。如果我们将此信息作为元数据字段,大多数向量存储允许我们在执行相似性搜索之前预先过滤数据库。
(5) 优化索引结构 – 全搜索 vs. 近似最近邻,HNSW vs. IVFPQ
我不认为相似性搜索是大多数 RAG 系统的弱点 – 至少当我们查看响应时间时不是 – 但我还是想提一下。
大多数向量分数中的相似性搜索速度非常快,即使我们有数百万个条目,因为它使用了近似最近邻技术 – 例如 FAISS、NMSLIB、ANNOY ……
FAISS、NMSLIB 或 ANNOY 使用一些近似最近邻使之成为可能。

向量索引技术 – 图片由作者提供
对于只有几千个条目的用例来说,这通常是多余的。如果我们执行 ANN 或完全最近邻搜索,只会稍微影响 RAG 系统的响应时间。
但是,如果你想建立一个可扩展的系统,你当然可以加快速度。
(6) 选择合适的嵌入模型
在对文本块进行嵌入时,有多种选择。如果不确定使用哪些模型,可以查看现有的文本嵌入模型性能基准测试,例如 MTEB(大规模文本嵌入基准测试)。
在嵌入方面,我们通常需要决定嵌入的维度数。更高的维度可以捕捉和存储句子更多的语义方面,但另一方面,它需要更多的存储空间和计算时间。
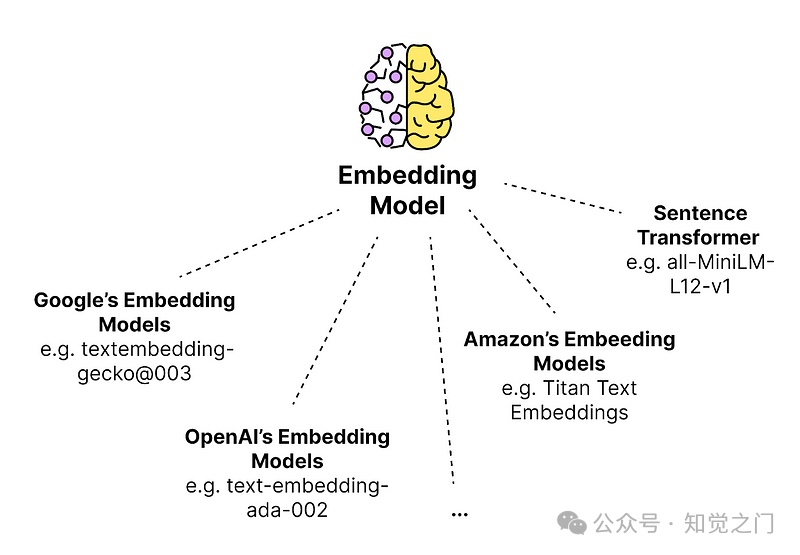
一些可用的文本嵌入模型集合 – 图片由作者提供
我们将所有内容转换为嵌入向量,并将它们添加到向量数据库中。现在有来自不同提供商的多种模型可用。如果想了解可以使用哪些模型,可以查看***langchain.embeddings***模块支持的模型。在模块的源代码中,你会发现一个相当长的支持模型列表:

3. 检索优化 – 查询翻译 / 查询重写 / 查询扩展
查询扩展、查询重写或查询翻译,所有这些方法都必须修改发送给 LLM 的原始查询。
基本上,我们正在利用 LLM 的力量来增强和优化我们发送到向量搜索的查询。
有多种方法,例如:
- 通过针对用户问题生成 LLM 生成的文档来扩展用户的查询。
- 或者,我们可以使用 LLM 对用户的查询进行稍微的改写,并将不同的提示发送给模型,然后解释来自模型的不同反馈。
让我们从第一个开始。
(7) 使用生成答案进行查询扩展 – HyDE 等
在执行相似性搜索之前,我们使用 LLM 生成答案。如果这是一个只能使用我们的内部知识才能回答的问题,我们会间接地要求模型进行幻觉,并使用幻觉的答案来搜索与答案相似的内容,而不是用户查询本身。
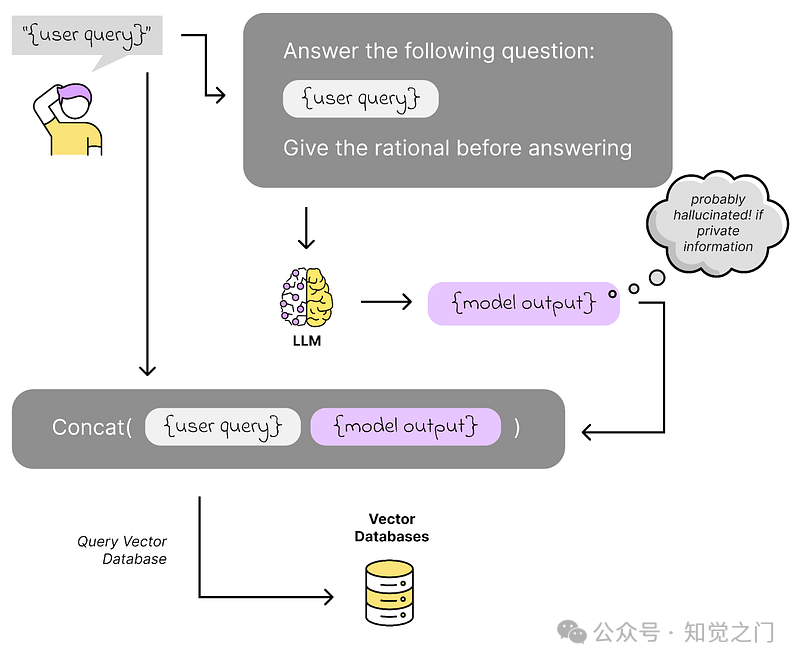
使用生成答案进行扩展 – 图片由作者提供(灵感来自 [Gao, 2022])
有几种技术,例如 HyDE(假设文档嵌入)、重写-检索-读取、后退提示、Query2Doc、ITER-RETGEN 等。
在 HyDE 中,我们让 LLM 首先在没有上下文的情况下为用户的查询创建一个答案,并使用该答案在我们的向量数据库中搜索相关信息。
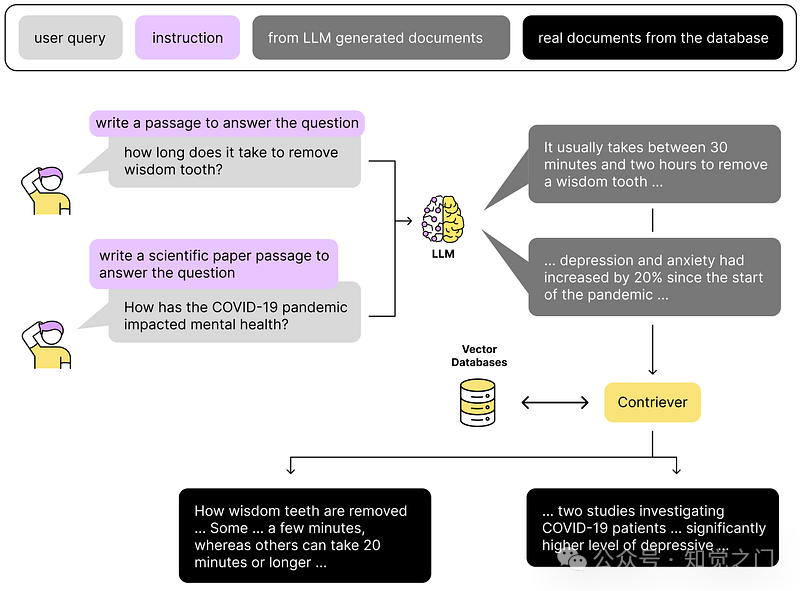
HyDE 是如何工作的?-- 图片由作者提供(灵感来自 [Gao, 2022])
作为 HyDE 等方法的替代方法,我们可以使用多个系统提示来扩展用户的查询。
(8) 多个系统提示
这个想法很简单:我们生成例如 4 个不同的提示,这些提示将提供 4 个不同的响应。
你可以发挥创造力。提示之间的区别可以是任何东西。
- 如果我们有一个很长的文本,我们想对其进行总结,我们可以使用不同的提示在文本中寻找某些方面,并在最终答案中总结这些发现。
- 或者我们有 4 个或多或少相同的提示,具有相同的上下文,但系统提示略有不同。因此,我们以稍微不同的方式告诉 LLM 4 次要对它做什么或如何表达答案。
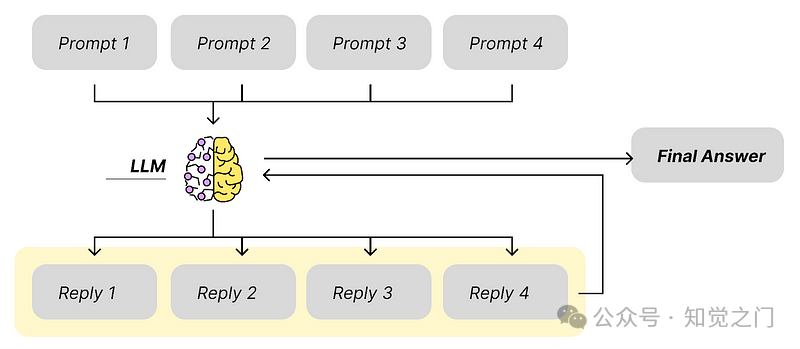
多个系统提示 – 图片由作者提供
这个想法在数据科学中随处可见。在 Boosting 算法中,我们通常有简单的模型,每个模型略有不同,做出一个小的决策。最后,我们以某种方式整合结果。这个概念非常强大。
我们在这里做的是一样的,只是再次使用模型来整合不同的预测。缺点当然是计算时间和/或响应时间更长。
(9) 查询路由
在查询路由中,我们使用 LLM 的决策能力来决定下一步做什么。
假设我们的向量存储中有来自不同领域的数据。为了更有针对性地搜索相关内容,让模型在第一步中决定我们应该使用哪个数据池来回答问题是有意义的。
下图中的示例向量存储包含来自世界各地的新闻。有关体育和足球的新闻、烹饪趋势和政治新闻。当用户查询我们的聊天机器人时,我们不想混合这些数据。
国家之间的体育竞争不应该与政治混为一谈。如果用户正在寻找有关政治的新闻,那么有关烹饪的内容可能没有帮助。

查询路由示例:在查询数据之前决定要使用哪些数据 – 图片由作者提供
通过这种方式,我们可以显著提高性能。我们还可以让最终用户选择用于回答问题的主题。
(10) 混合搜索
基本上,RAG 管道的检索步骤就是一个搜索引擎。这可能是我们 RAG 系统中最重要的部分。
当我们想要改进相似性搜索时,值得关注一下搜索领域。混合搜索方法就是一个例子。我们执行向量搜索和词汇(关键字)搜索,并以某种方式将这些结果结合在一起。
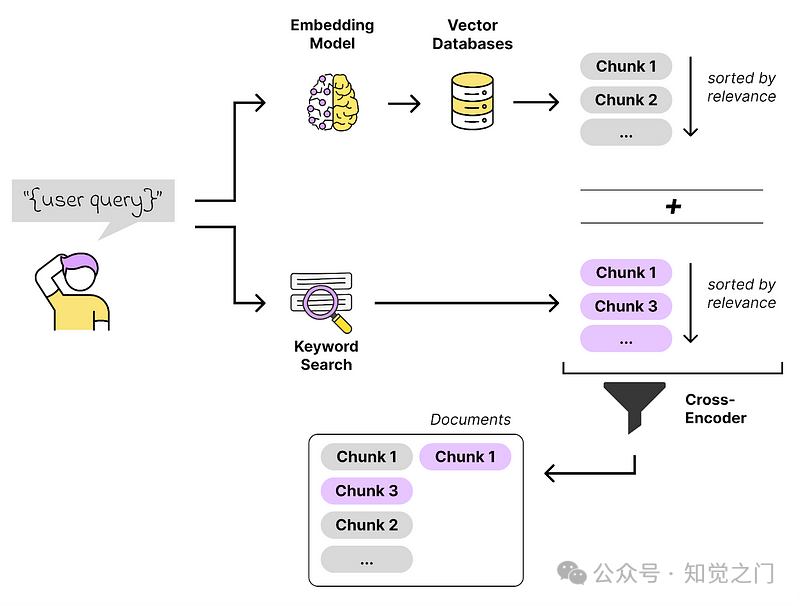
混合搜索解释 – 图片由作者提供
在机器学习中,这是一种常见的方法。拥有不同的技术、不同的模型,预测相同的输出,并汇总结果。其思想始终是一致的。
一群专家试图找到解决方案并做出妥协,这比一个独立的专家做出更好的决策。
4. 检索后:如何改进检索步骤?
上下文丰富 - 例如句子窗口检索
我们通常会尽量保持文本块较小,以便找到我们想要的内容并保持较高的搜索质量。
另一方面,如果不仅能看到最匹配的句子,还能看到它周围的上下文,通常会更容易给出正确的答案。
让我们看一下下图中的例子:
我们有一堆文本块,来自一篇关于德国足球俱乐部拜仁慕尼黑的维基百科文章。我还没有测试过,但我可以想象第一个文本片段会带来最高的相似度得分。
尽管如此,第二个块中的信息可能更相关。我们也希望捕捉到那一个。这就是上下文丰富发挥作用的地方。

适当的文本块划分是一门科学 – 图片由作者提供
有各种方法可以丰富上下文,下面我将简要描述其中两种:
- 句子窗口检索器
- 自动合并检索器
(11) 句子窗口检索
相似度得分最高的文本块表示找到的最匹配的内容。在将内容发送到 LLM 之前,我们在找到的文本块前后添加 k 个句子。这是有意义的,因为这些信息很可能与中间部分相关联,而且中间文本块中的信息可能不完整。
自动合并检索器也是这样做的,只是这一次,每个块都附加了一些“父”块,这些父块不一定是找到的块之前和之后的块。
(12) 自动合并检索器(又称父文档检索器)
自动合并检索器的工作原理类似,只是这一次每个小的文本块都被分配了某些“父”块,这些父块不一定是找到的文本块之前和之后的块。
您可以发挥您的所有创造力,定义和识别文本块之间的相关关系。
例如,当我们查看技术文档或法律合同时,段落或章节通常会引用合同的其他部分。挑战在于用其他段落中的相关信息来丰富段落。因此,我们需要能够识别文本中引用文档其他部分的链接。

自动合并检索器:父节点和子节点-- 图片由作者提供
我们可以在此概念的基础上构建一个完整的层次结构,就像一个决策树,具有不同级别的父节点、子节点和叶节点。例如,我们可以有 3 个级别,具有不同的块大小 [LlamaIndex, 2024]:
- 第 1 层:块大小 2048
- 第 2 层:块大小 512
- 第 3 层:块大小 128(叶节点)
当我们对数据进行索引并执行相似性搜索时,我们使用的是最小的块,即叶节点。在此步骤之后,我们找到叶的匹配父节点。
在检索步骤之后,我们必须解释找到的内容并使用它来解决用户查询。为此,我们使用大型语言模型 (LLM)。但是哪种模型适合我们的用例呢?
5. 生成 / 代理
(13) 选择合适的 LLM 和提供商 - 开源与闭源、服务与自托管、小型模型与大型模型
为您的应用程序选择合适的模型并不像您想象的那么容易。这取决于具体的应用和您的流程是什么样的。
有些人会说,最明显的解决方案是:
直接使用最强大的那个
然而,使用更小、更便宜、更快的模型有一些不可否认的优势。
在 RAG 流程的某些部分,准确性可以低一些,但响应时间应该很快,例如:当我们使用基于代理的方法时,我们需要沿着管道不断做出简单的决策。

工具允许代理始终选择最匹配的可用工具 – 图片由作者提供
此外,如果较小模型的响应和决策能力足以满足我们的用例,那么就没有必要去追求最强大的模型。您将降低解决方案的运营成本,用户也会感谢您改进系统的响应时间。
但是我们如何选择模型呢?
有几个基准测试,从不同的角度比较了 LLM。但最终,我们只需要为我们的 RAG 解决方案尝试一下它们。
(14) 代理
代理结合了一些组件,并根据一定的规则迭代地执行它们。
代理使用所谓的“思维链推理”概念,它描述了以下迭代过程:
- 发送请求,
- 使用 LLM 解释响应,
- 决定下一步行动,以及
- 再次行动。
下图中的问题显示了一个通常过于复杂而无法一次性回答的示例,因为答案很可能没有写在任何地方。
我们人类会把它分解成我们可以回答的更简单的子问题,然后计算出我们想要的答案。代理在这种情况下也是这样做的。
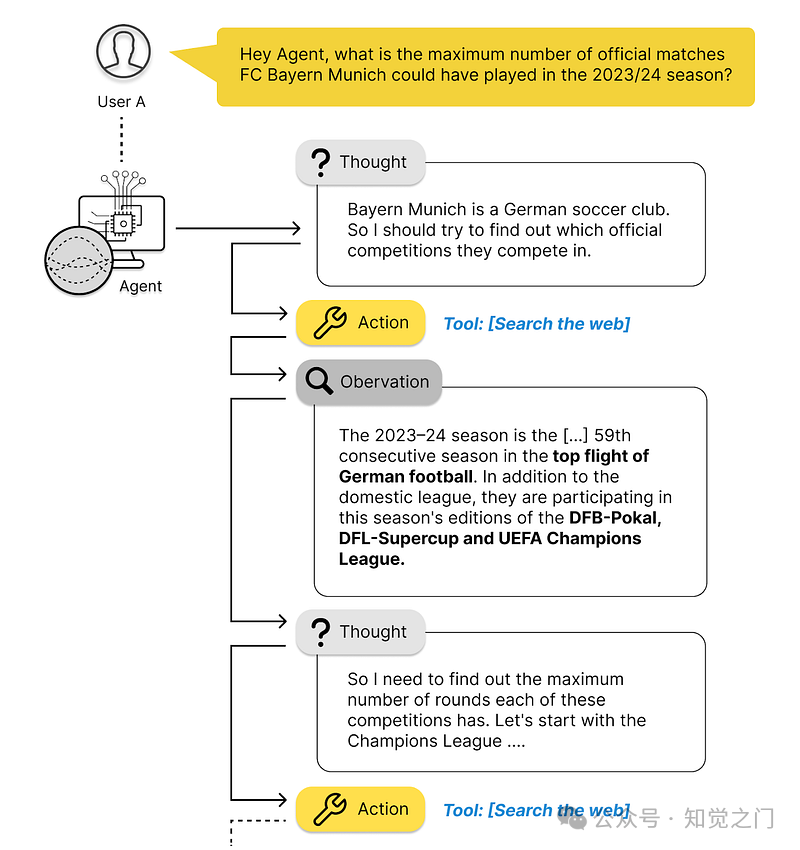
代理是如何工作的?-- 图片由作者提供
使用基于代理的方法,我们可以显著提高准确性。当然,总会有一个权衡。与一次性提示相比,我们增加了所需的计算能力和响应时间。但提高了准确性。
尽管如此,使用这种方法,我们可以用更小、更快的模型超越更大模型的准确性。最终,这对您的解决方案来说可能是更好的方法。
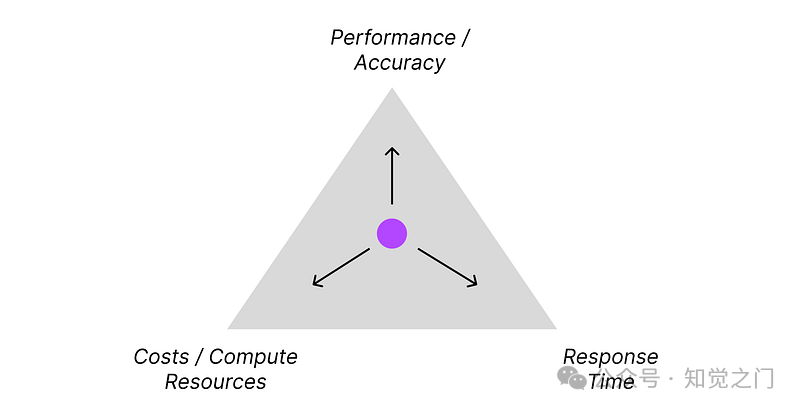
性能与成本与响应时间 – 图片由作者提供
这始终取决于您的具体用例 – 当我们构建一个用于纯粹信息检索的机器人时,我们一直在与搜索引擎的超短响应时间竞争。
响应时间是关键。
等待几秒甚至几分钟的结果很糟糕。
6. 评估 – 评估我们的 RAG 系统
基于 RAG 的系统的性能高度依赖于提供的数据和 LLM 提取有用信息的能力。为此,我们需要几个组件协同工作。当我们想要评估整个系统时,我们通常不仅要跟踪整体性能,还要了解各个组件是如何完成其应尽职责的。
和以前一样,我们可以将其分为检索器组件和生成器组件的评估。
我们可以使用典型的搜索指标(如 DCG 和 nDCG)来评估搜索部分,这些指标用于评估排名质量。它们检查真正相关的内容在相似性搜索中是否确实被归类为此类。[EvidentlyAI, 2024][Leonie Monigatti, 2023]
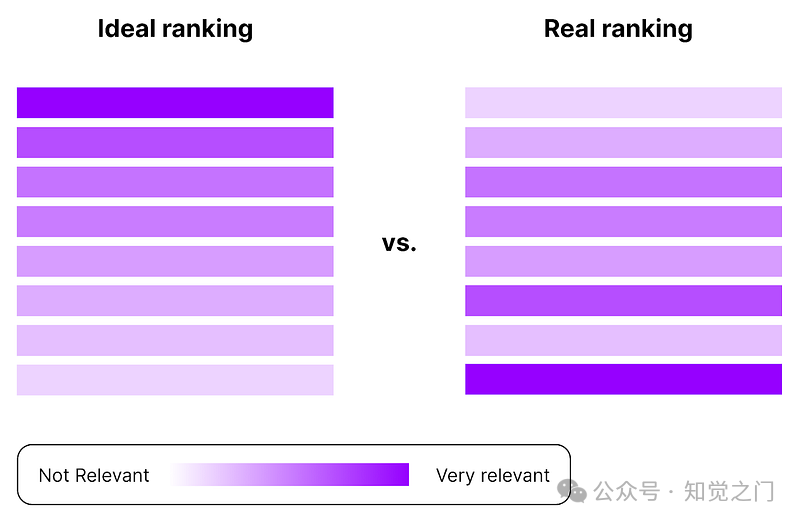
“理想排名”与真实排名:NDCG 作为一种帮助评估排名质量的指标 – 图片由作者提供 [EvidentlyAI, 2024]
评估模型本身的响应非常棘手。
我们如何评估响应?语言是模棱两可的,所以我们如何给输出一个类似于评级的评价呢?
最简单的方法是询问很多人他们是否认为答案有帮助——假设我们让 1000 个人对 LLM 的答案进行评分。这将使您很好地了解它的工作情况。但对于一个高效的解决方案来说,这是不切实际的。
每次稍微更改 RAG 过程时,都会影响结果。我知道说服领域专家测试您的解决方案是多么困难。我们可以做一两次,但不是每次我们更改管道中的某些内容时都这样做。
所以我们需要想出一个更好的办法。一种方法是,我们不使用人工,而是使用其他 LLM 来评估结果——所以我们使用模型“作为评判者”的方法。
(15) LLM 作为评判者
可以使用 LLM 作为评判者的方法来评估生成部分。这个概念很简单。
- 我们生成一个评估数据集
- 然后使用我们想要评估的合适标准定义一个所谓的“批评代理”,
- 最后建立一个测试流程,根据定义的标准自动评估 LLM 的响应
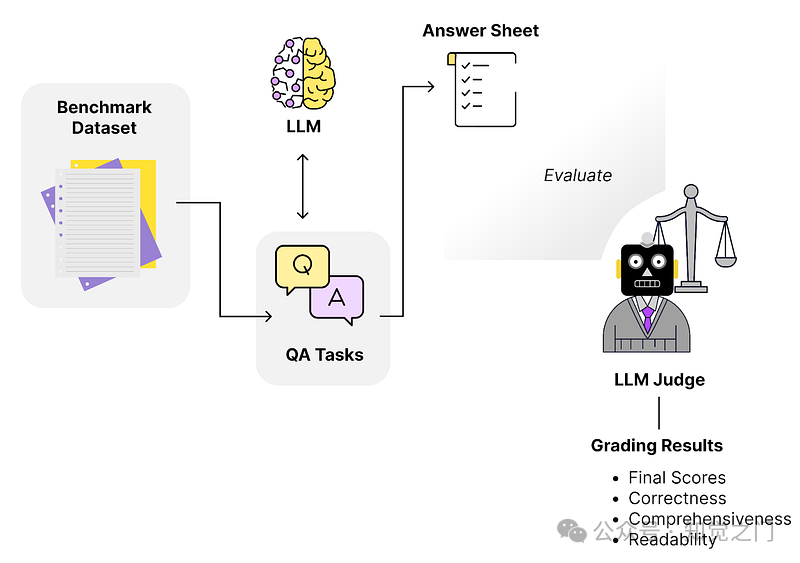
LLM 作为评判者的方法 – 受 [Databricks, 2023] 启发
步骤 (1) – 生成一个合成评估数据集
通常是一组(1)上下文、(2)问题和(3)答案。我们不一定有一个完整的数据集。我们可以通过向 LLM 提供上下文并让它猜测可能提出的问题来自己创建它。一步一步地建立一个合成数据集。
步骤 (2) – 建立一个所谓的“批评代理”
“批评代理”是另一个 LLM(通常是一个强大的 LLM),我们使用它根据一些标准来评估系统的响应,例如:
- 专业性:答案是否以专业的语气写成
一个示例指标定义可能如下所示 [Databricks, 2023]:
definition=( "Professionalism refers to the use of a formal, respectful, and appropriate style of communication that is " "tailored to the context and audience. It often involves avoiding overly casual language, slang, or " "colloquialisms, and instead using clear, concise, and respectful language." ), grading_prompt=( "Professionalism: If the answer is written using a professional tone, below are the details for different scores: " "- Score 1: Language is extremely casual, informal, and may include slang or colloquialisms. Not suitable for " "professional contexts." "- Score 2: Language is casual but generally respectful and avoids strong informality or slang. Acceptable in " "some informal professional settings." "- Score 3: Language is overall formal but still have casual words/phrases. Borderline for professional contexts." "- Score 4: Language is balanced and avoids extreme informality or formality. Suitable for most professional contexts. " "- Score 5: Language is noticeably formal, respectful, and avoids casual elements. Appropriate for formal " "business or academic settings. " ),

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
步骤 (3) – 测试 RAG 系统:使用刚刚创建的评估数据集,我们开始测试系统
对于我们要测试的每个指标/标准,我们定义一个详细的描述(例如,在 1-5 的范围内),然后让模型做出决定。这不是一门精确的科学,模型的答案会有所不同,但它让我们了解系统运行情况。
您可以在 Prometheus 的提示模板 或 Databricks 的 MLFlow 教程 中找到此评分提示外观的一些示例。
(16) RAGAs
RAGAs(检索增强生成评估) 是一个框架,允许您评估 RAG 系统的每个组件。
一个核心概念仍然是“LLM 作为评判者”/“LLM 辅助评估”背后的理念。但 Ragas 提供的远不止这些。它还提供了不同的工具和技术来实现 RAG 应用程序的持续学习。
值得一提的是一个核心概念,“组件式评估”。Ragas 提供预定义的指标来分别评估 RAG 流水线的每个组件,例如 [Ragas, 2024]:
生成:
- 忠实度:生成的答案在事实上有多准确?
- 答案相关性:生成的答案与问题的相关性如何?
检索:
- 上下文精度:检索到的上下文的信噪比
- 上下文召回率:它是否可以检索回答问题所需的所有相关信息
其他指标侧重于端到端评估 RAG 流水线,例如:
- 答案语义相似性
- 答案正确性
(17) 持续从应用程序和用户那里收集数据
收集数据是具体识别和填补流程中空白的关键。通常,知识库中提供给系统的数据本身不够好。为了意识到这一点,我们需要引入一些方法,让用户能够尽可能轻松地提供反馈。
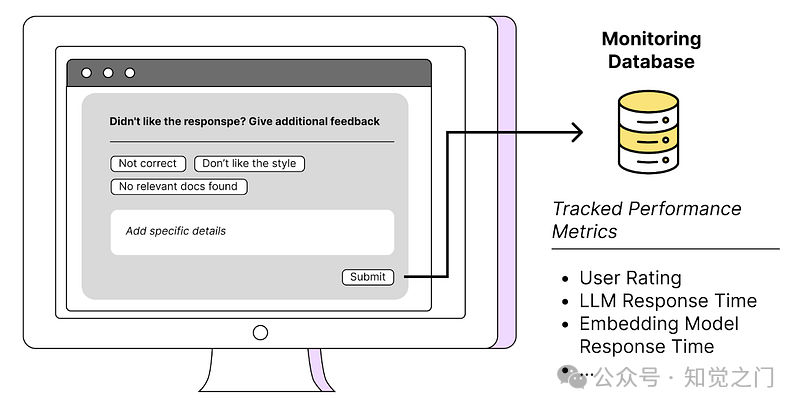
监控您的 RAG 系统 - 作者图片
其他有趣的指标有
- 时间戳、RAG 管道中每个步骤的响应时间(向量化、相似性搜索、LLM 响应等)
- 使用的提示模板
- 找到的相关文档,文档版本
- LLM 响应
- ……
RAG 系统是一个包含不同步骤的概念。为了优化性能和响应时间,我们需要知道瓶颈在哪里。这就是为什么我们要监控这些步骤,以便我们能够在最大的杠杆上努力。

收集 RAG 过程中的数据 - 作者图片
总结
没有明确的道路可循。这是一个不断试错的过程。与任何其他数据科学用例一样,我们有一套特定的工具,可以使用这些工具来尝试找到针对特定问题的解决方案。
这就是这些项目一开始就很有趣的原因。如果有一本静态的食谱可以遵循,那不是很无聊吗?
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

