
- 1基于SSM+Jsp+Mysql的医院预约挂号系统
- 2使用LSTM和GAN预测亚马逊股票价格的时空序列模型
- 36000字长文,带你用Python完成 “Excel合并(拆分)” 的各种操作!_python excel拆分与合并
- 4电源设计的BUCK-BOOST电路_buck-boost csdn
- 5iphone计算机显示过程,如何将视频从iPhone传输到计算机(PC和Mac)
- 6Python 下载 图片、音乐、视频(requests、you-get、pycurl、wget、ffmpeg)_python request 下载图片
- 7大模型和数据要素赋能智慧环保大数据平台解决方案_环保领域的数据资源目录系统的数据指标有哪些
- 8mysql连接池的设计与实现
- 9导致程序员写出烂代码的35个恶习,看看你染上了几个?
- 10ue4 运行禁用鼠标_[UE4] VS code使用LuaPanda断点调试
私有化部署 Llama3 大模型, 支持 API 访问_ollama如何通过api访问
赞
踩
通过 ollama 本地运行 Llama3 大模型其实对我们开发来说很有意义,你可以私有化放服务上了。
然后通过 api 访问,来处理我们的业务,比如翻译多语言、总结文章、提取关键字等等。
你也可以安装 enchanted 客户端去直接访问这个服务 api 使用。
参考
https://llama.meta.com/llama3/
https://ollama.com/
https://github.com/ollama/ollama
https://github.com/ollama/ollama/blob/main/docs/api.md
https://github.com/sugarforever/chat-ollama
https://github.com/AugustDev/enchanted
Llama3
https://llama.meta.com/llama3/
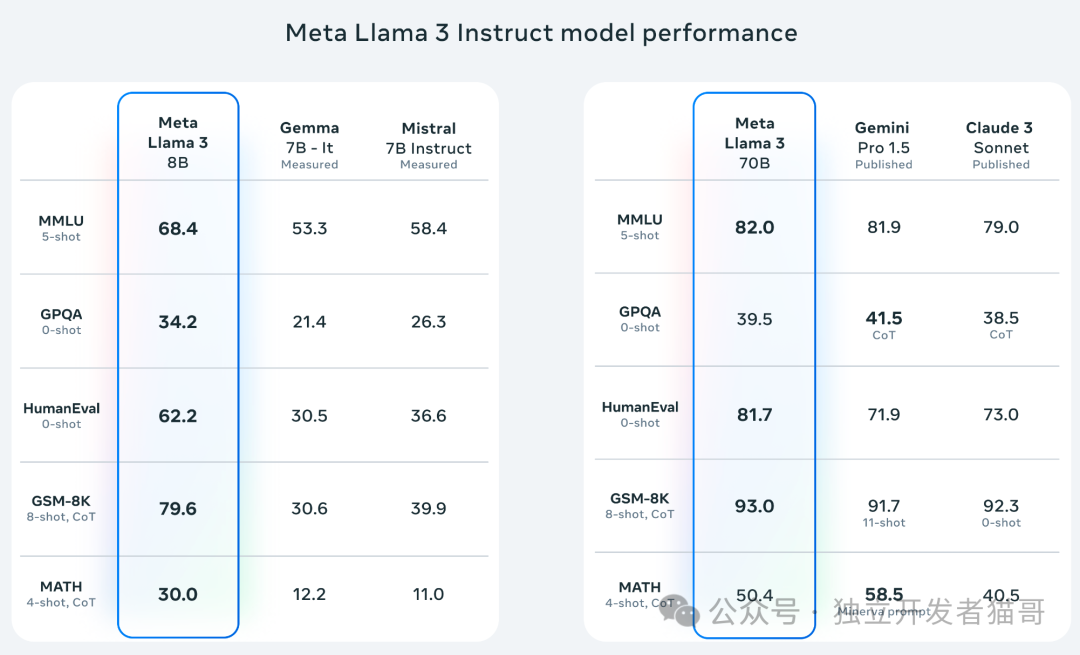
llama3
https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md
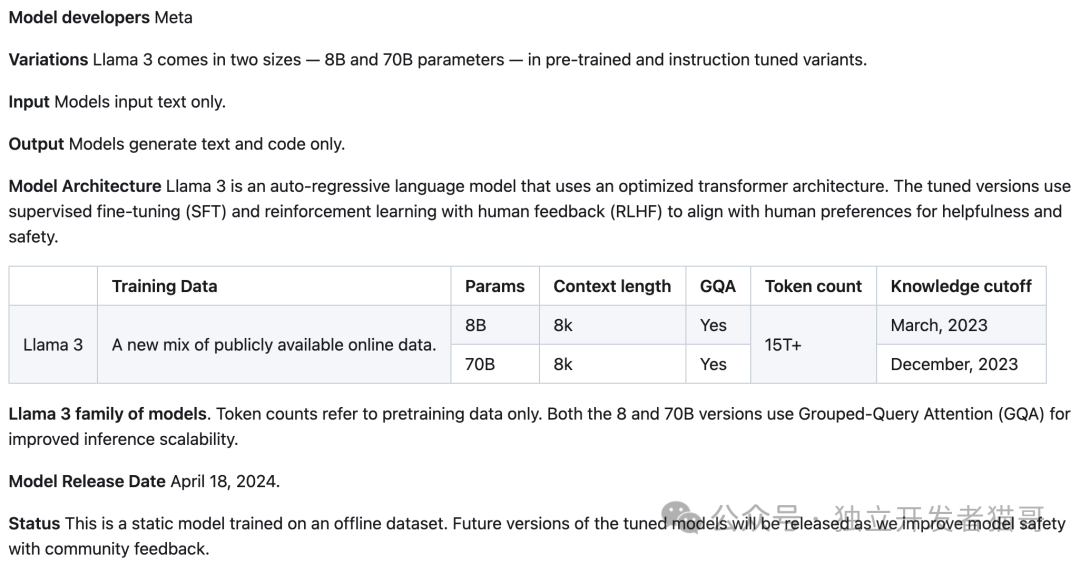
Model Architecture
安全性
https://llama.meta.com/trust-and-safety/
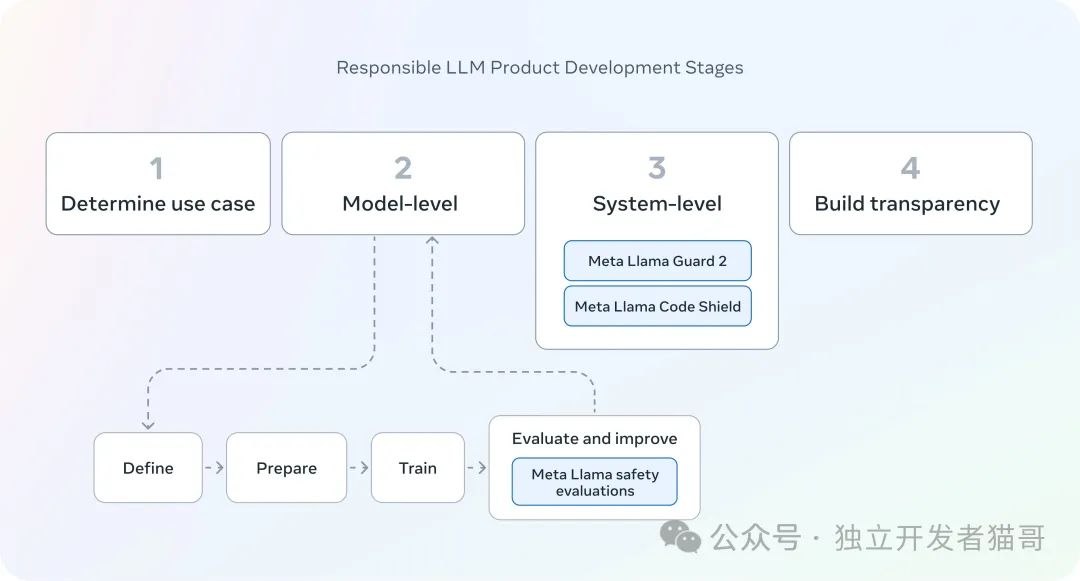
Responsible LLM Product Development Stages graphic
https://www.meta.ai/
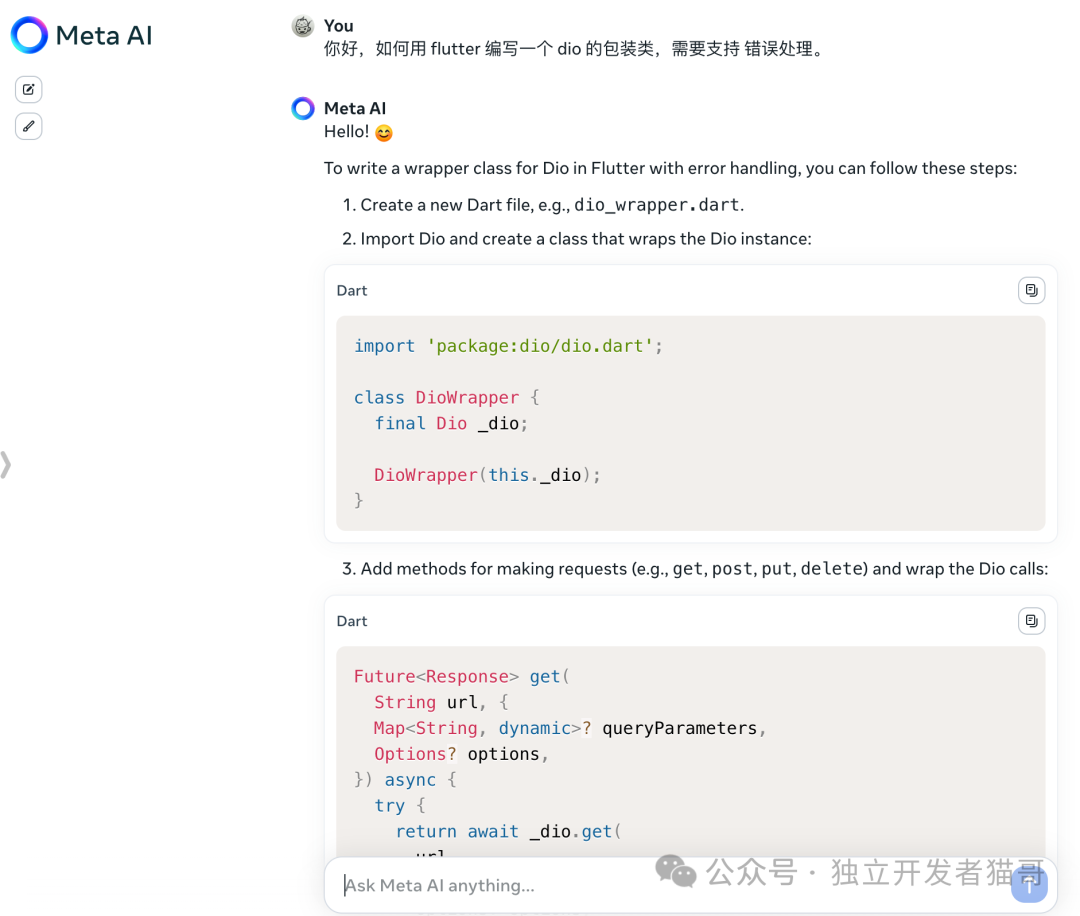
meta ai chat
步骤
安装 ollama
https://ollama.com/
ollama
安装 Llama3 8b 模型
https://ollama.com/library
https://ollama.com/library/llama3
模型选择
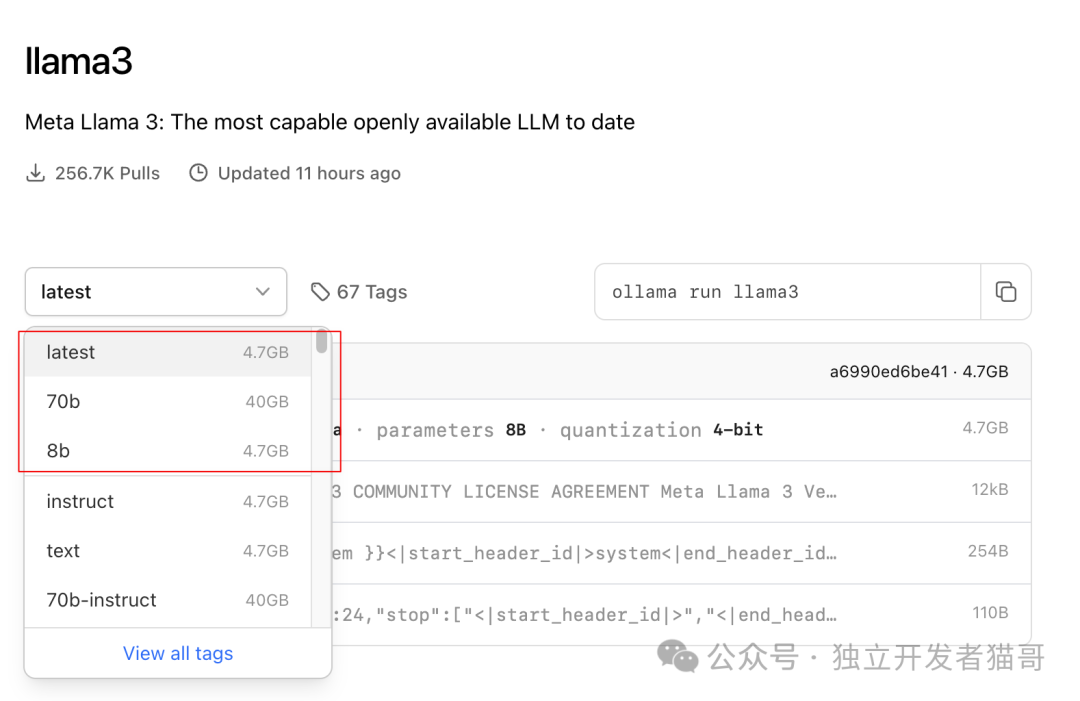
llama3
安装命令
$ ollama run llama3
- 1
访问 api 服务
https://github.com/ollama/ollama/blob/main/docs/api.md
curl http://localhost:11434/api/generate -d '{ "model":"llama3", "prompt": "请分别翻译成中文、韩文、日文 -> Meta Llama 3: The most capable openly available LLM to date", "stream": false }'
- 1
参数解释如下:
-
model(必需):模型名称。
-
prompt:用于生成响应的提示文本。
-
images(可选):包含多媒体模型(如llava)的图像的base64编码列表。
高级参数(可选):
-
format:返回响应的格式。目前仅支持json格式。
-
options:模型文件文档中列出的其他模型参数,如温度(temperature)。
-
system:系统消息,用于覆盖模型文件中定义的系统消息。
-
template:要使用的提示模板,覆盖模型文件中定义的模板。
-
context:从先前的/generate请求返回的上下文参数,可以用于保持简短的对话记忆。
-
stream:如果为false,则响应将作为单个响应对象返回,而不是一系列对象流。
-
raw:如果为true,则不会对提示文本应用任何格式。如果在请求API时指定了完整的模板化提示文本,则可以使用raw参数。
-
keep_alive:控制模型在请求后保持加载到内存中的时间(默认为5分钟)。
返回 json 数据
{ "model": "llama3", "created_at": "2024-04-23T08:05:11.020314Z", "response": "Here are the translations:\n\n**Chinese:** 《Meta Llama 3》:迄今最强大的公开可用的LLM\n\n**Korean:** 《Meta Llama 3》:현재 가장 강력한 공개 사용 가능한 LLM\n\n**Japanese:**\n\n《Meta Llama 3》:現在最強の公開使用可能なLLM\n\n\n\nNote: (Meta Llama 3) is a literal translation, as there is no direct equivalent for \"Meta\" in Japanese. In Japan, it's common to use the English term \"\" or \"\" when referring to Meta.", "done": true, "context": [ ... ], "total_duration": 30786629492, "load_duration": 3000782, "prompt_eval_count": 32, "prompt_eval_duration": 6142245000, "eval_count": 122, "eval_duration": 24639975000 }
- 1
返回值的解释如下:
-
total_duration:生成响应所花费的总时间。
-
load_duration:以纳秒为单位加载模型所花费的时间。
-
prompt_eval_count:提示文本中的标记(tokens)数量。
-
prompt_eval_duration:以纳秒为单位评估提示文本所花费的时间。
-
eval_count:生成响应中的标记数量。
-
eval_duration:以纳秒为单位生成响应所花费的时间。
-
context:用于此响应中的对话编码,可以在下一个请求中发送,以保持对话记忆。
-
response:如果响应是以流的形式返回的,则为空;如果不是以流的形式返回,则包含完整的响应。
要计算生成响应的速度,以标记数每秒(tokens per second,token/s)为单位,可以将 eval_count / eval_duration 进行计算。
ollama 生态
https://github.com/ollama/ollama
-
客户端 桌面、Web
-
命令行工具
-
数据库工具
-
包管理工具
-
类库
桌面 enchanted 客户端
https://github.com/AugustDev/enchanted
enchanted
设置服务器地址
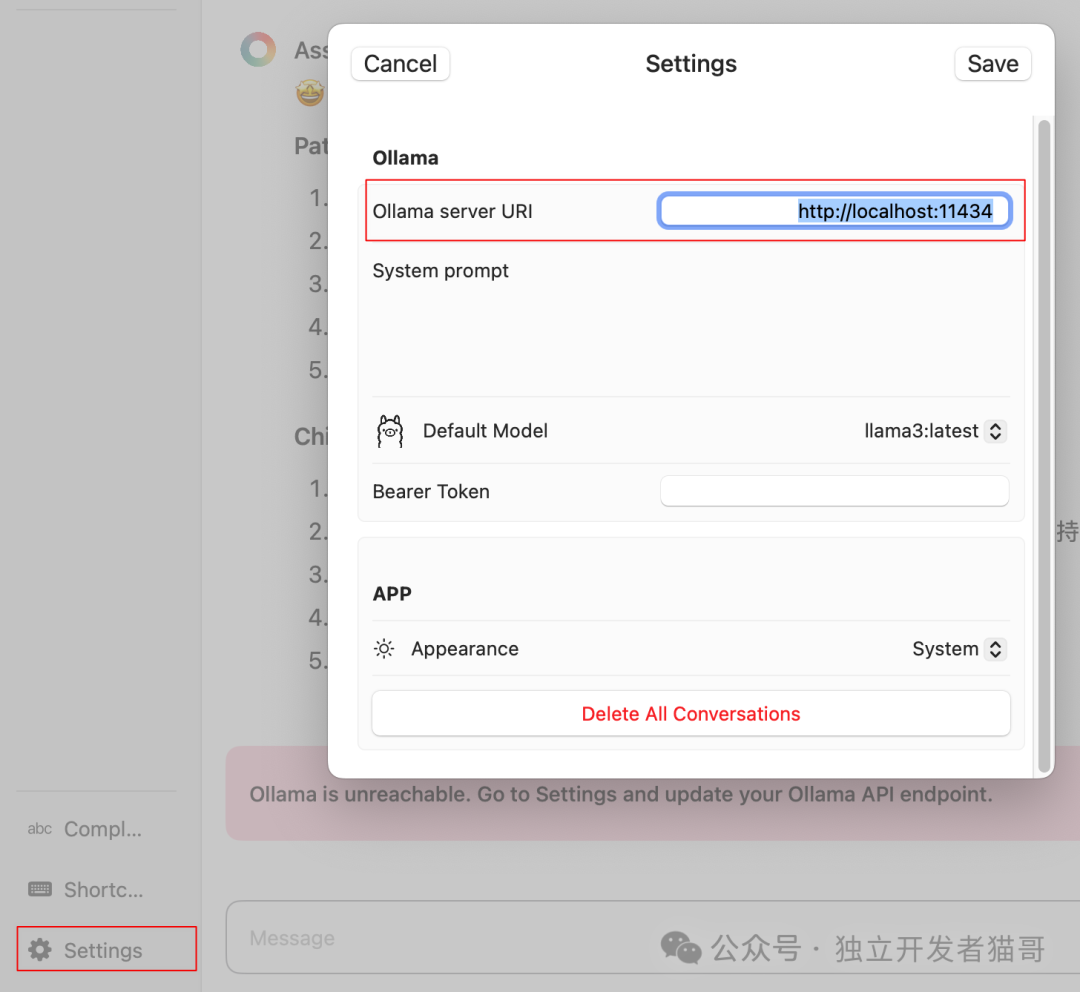
ollama server url
提问使用
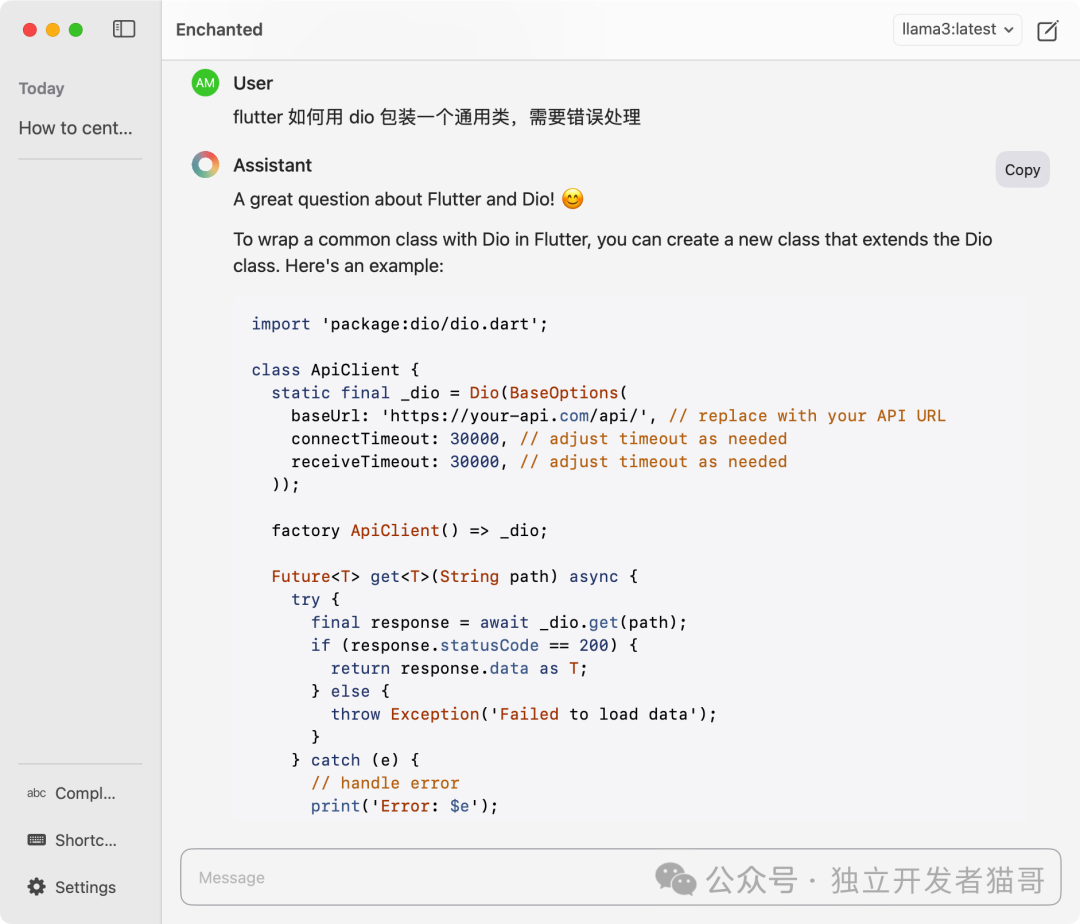
enchanted
代码
https://github.com/ollama/ollama
小结
感谢阅读本文
如果有什么建议,请在评论中让我知道。我很乐意改进。
flutter 学习路径
-
Flutter 优秀插件推荐 https://flutter.ducafecat.com
-
Flutter 基础篇1 - Dart 语言学习 https://ducafecat.com/course/dart-learn
-
Flutter 基础篇2 - 快速上手 https://ducafecat.com/course/flutter-quickstart-learn
-
Flutter 实战1 - Getx Woo 电商APP https://ducafecat.com/course/flutter-woo
-
Flutter 实战2 - 上架指南 Apple Store、Google Play https://ducafecat.com/course/flutter-upload-apple-google
-
Flutter 基础篇3 - 仿微信朋友圈 https://ducafecat.com/course/flutter-wechat
-
Flutter 实战3 - 腾讯 tim 即时通讯开发 https://ducafecat.com/course/flutter-tim
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

篇幅有限,部分资料如下:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Li_阴宅/article/detail/910351
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

