
- 1Git 配置gitignore忽略文件无效_.gitignore添加 .iml文件识别不了
- 2设置最新版Chrome 3.4 中间搜索栏不跳转到标签栏 设置搜索不跳转到hk_replace new tab page
- 3第一篇【传奇开心果系列】我和AI面对面聊编程:深度比较PyQt5和tkinter.ttk_tkinter和pyqt5
- 4python BM25_python 中的 bm25okapi使用方法
- 5【LeetCode刷题】1.两数之和
- 6(2)SpringBoot学习——芋道源码_芋道源码垃圾
- 7Vivado使用技巧(33):时序异常_vivado时序违例解决
- 8一句话概括 —— ML(机器学习)_ml算法是什么意思
- 9Spring Tools 4 安装与配置指南_spring tools 4 (sts4) 使用入门
- 10人工智能行业就业前景怎么样?真实薪资待遇如何?_人工智能专业就业前景和薪水怎么样
第一章、CS231N课程简介
赞
踩
一、计算机视觉研究范围

二、计算机视觉与深度学习的历史
1.计算机视觉的发展历史
(1)早期探索(20世纪50年代至70年代)
-
20世纪50年代:研究生物视觉的工作原理,如Hubel和Wiesel对猫咪视觉皮层系统的研究,揭示了信息分层处理机制。
-
20世纪60年代:计算机视觉萌芽,Larry Roberts发行了Block World作品,提出了基于几何形状的物体识别方法。
-
20世纪70年代:开创性提出识别流程,Marr将视觉识别过程划分为三个阶段,包括简单结构处理、深度信息和层级信息处理、以及基于表面和体积图元的3D模型。
(2)特征提取与图像分割(20世纪80年代至90年代)
-
20世纪80年代:着眼于提取特征,人们试图建立专家系统来存储先验知识,并与实际项目中提取的特征进行规则匹配。
-
20世纪90年代:图像分割成为研究热点,Paul Viola和Michael Johns等人利用Adaboost算法完成了人脸的实时检测。
(3)深度学习时代(2010年至今)
-
计算机运算能力指数级增长,深度学习相关算法得到应用与革新。
-
大型数据库如ImageNet、PASCAL等超大型图片数据库使得深度学习训练成为可能。
-
ImageNet挑战赛上,深度学习技术取得了显著突破,错误率大幅下降。
2.深度学习的发展历史
(1)早期研究(20世纪40年代至80年代)
-
深度学习的概念起源于20世纪40年代,Warren McCulloch和Walter Pitts提出了神经网络的概念。
-
20世纪50年代,Frank Rosenblatt提出了感知机,这是最早的深度学习模型之一。
-
20世纪80年代,随着计算机性能的提高和BP算法的发明,神经网络再次成为热门话题。
(2)理论研究与应用扩展(20世纪90年代至21世纪初)
-
深度学习理论和应用开始发展,主要集中在单层感知机和多层感知机上。
-
Yann LeCun等学者在1998年提出了卷积神经网络(CNN),并在手写字符识别任务上取得重大突破。
(3)快速发展与广泛应用(2010年至今)
-
深度学习的研究和应用进入快速发展阶段,神经网络的深度和宽度不断增加。
-
Geoffrey Hinton等学者在2006年提出了深度信念网络(DBN),为深度学习的发展打下了基础。
-
出现了循环神经网络(RNN)、长短时记忆网络(LSTM)等新的神经网络结构,可以处理更加复杂的任务。
-
深度学习被广泛应用于计算机视觉、语音识别、自然语言处理、智能推荐等领域,取得了显著进展。
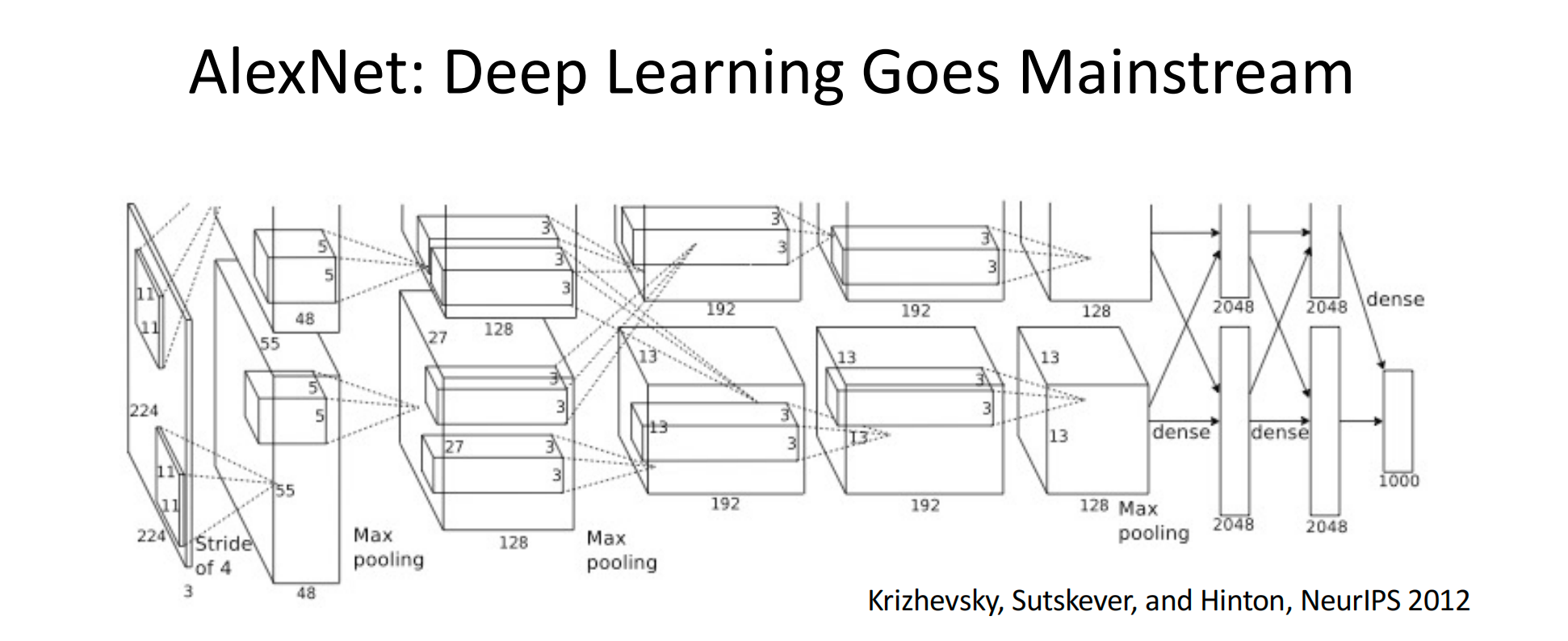
3.举例:AlexNet网络
这里对AlexNet进行简要的介绍,在这里只是提前感受一下深度学习网络的连接,具体需要学习的知识后面会慢慢完善。
- # AlexNet基于PyTorch实现
- import torch
- import torch.nn as nn
-
- class AlexNet(nn.Module):
- def __init__(self, num_classes=1000):
- super(AlexNet, self).__init__()
- self.features = nn.Sequential(
- nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
- nn.ReLU(inplace=True),
- nn.MaxPool2d(kernel_size=3, stride=2),
- nn.Conv2d(96, 256, kernel_size=5, padding=2),
- nn.ReLU(inplace=True),
- nn.MaxPool2d(kernel_size=3, stride=2),
- nn.Conv2d(256, 384, kernel_size=3, padding=1),
- nn.ReLU(inplace=True),
- nn.Conv2d(384, 384, kernel_size=3, padding=1),
- nn.ReLU(inplace=True),
- nn.Conv2d(384, 256, kernel_size=3, padding=1),
- nn.ReLU(inplace=True),
- nn.MaxPool2d(kernel_size=3, stride=2),
- )
- self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
- self.classifier = nn.Sequential(
- nn.Dropout(),
- nn.Linear(256 * 6 * 6, 4096),
- nn.ReLU(inplace=True),
- nn.Dropout(),
- nn.Linear(4096, 4096),
- nn.ReLU(inplace=True),
- nn.Linear(4096, num_classes),
- )
-
- def forward(self, x):
- x = self.features(x)
- x = self.avgpool(x)
- x = torch.flatten(x, 1)
- x = self.classifier(x)
- return x
简要说明
(1)结构
AlexNet模型由8个层次组成,包括5个卷积层和3个全连接层(通常所说的全连接层在AlexNet中指的是分类器部分)。模型设计用于处理224x224像素的RGB图像(即3通道)。
(2)卷积层
-
第一个卷积层使用96个11x11的卷积核,步长为4,边界填充为2,输出特征图大小为55x55x96。
-
随后的卷积层使用更小的卷积核和不同的步长及填充,逐步提取图像的高级特征。
(3)池化层
-
在卷积层之间,AlexNet使用了最大池化(Max Pooling)来降低特征图的维度和计算量。通常,池化层的池化窗口大小为3x3,步长为2。
(4)全连接层
-
全连接层将池化层的输出展平为一维向量,并通过多个线性变换和激活函数(ReLU)进行特征提取和分类。
-
第一个全连接层有4096个神经元,后两个全连接层配置相同。
-
最后一层全连接层用于分类,神经元数量等于分类的类别数(例如,在ImageNet数据集上是1000)
(5)Dropout
-
在全连接层中使用了Dropout技术,以随机失活部分神经元,减少过拟合现象,提高模型的泛化能力。
(6)其他技术
-
AlexNet使用了ReLU激活函数,相比于传统的Sigmoid或tanh激活函数,ReLU在训练过程中能更快地收敛,并且减少了梯度消失的问题。
-
AlexNet是首个在GPU上使用并行计算的深度学习模型,这大大加速了模型的训练过程。
(7)输入与输出
-
输入为224x224的RGB图像,输出为一个长度等于类别数的向量,通过Softmax函数转化为概率分布,用于多分类任务。
4.总结
计算机视觉与深度学习的发展历程相辅相成,相互促进。计算机视觉领域的发展推动了深度学习技术的不断革新,而深度学习技术的进步又极大地推动了计算机视觉领域的发展。随着技术的不断进步和应用场景的不断扩展,计算机视觉与深度学习将会在更多的领域中得到应用和发展。
三、对象识别比较权威的数据集
在计算机视觉领域,存在多个权威且广泛使用的数据集,它们为各种计算机视觉任务提供了丰富的图像和标注数据。以下是其中一些比较权威的数据集及其简要介绍:
1.ImageNet
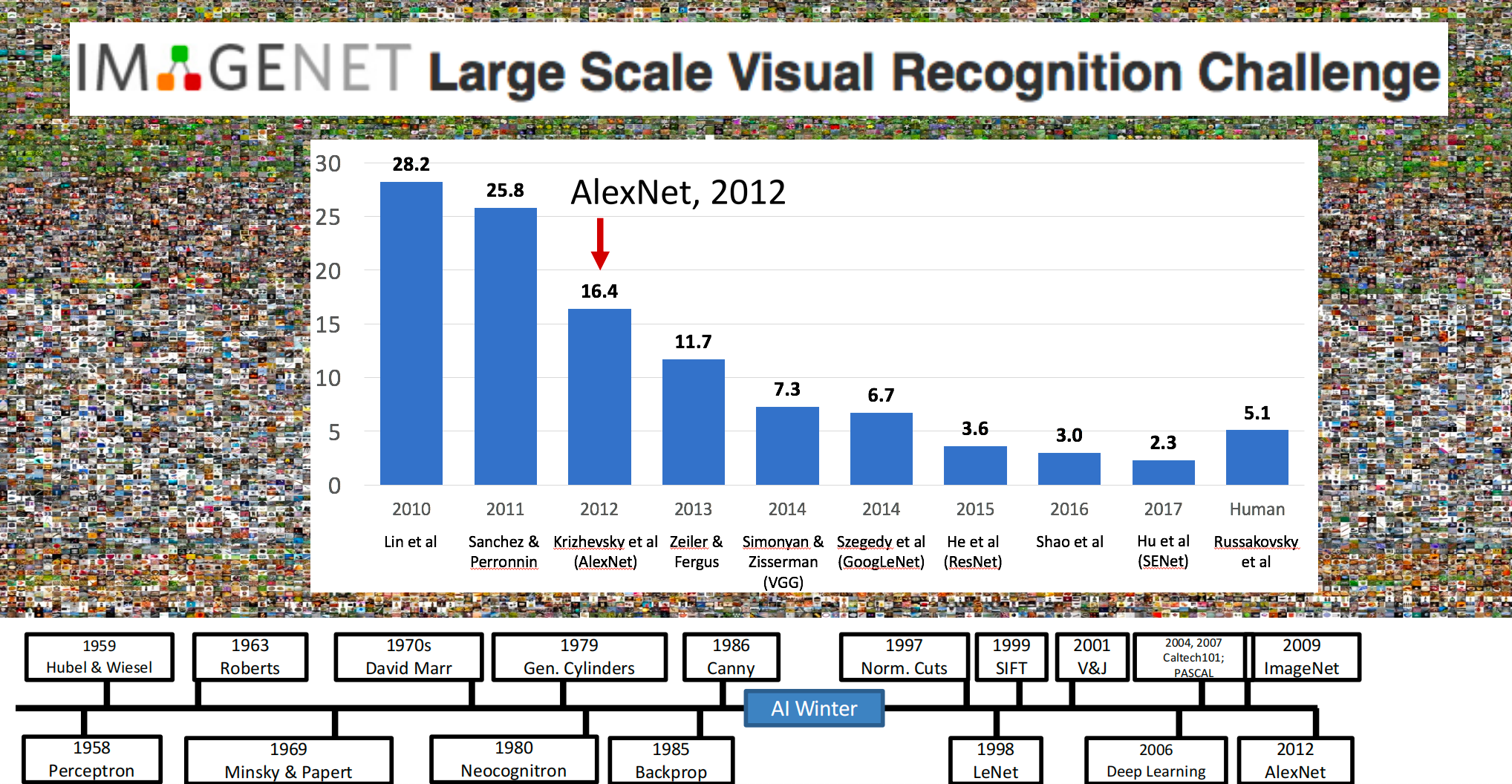
- ImageNet是计算机视觉领域最受欢迎的数据集之一,拥有超过1400万张已手动标注的图像。
- 它按照WordNet层次结构进行组织,提供了数千万个干净排序的图像来描述WordNet中的每个同义词集。
- ImageNet主要用于图像分类、目标检测等任务。
2.MS COCO (Microsoft Common Objects in Context)
- COCO是一个大规模的对象检测、分割和说明的数据集,包含超过200,000张图像和91个对象类别的标注。
- 除了目标检测外,COCO还提供了关键点检测、全景分割、素材图像分割、字幕和密集人体姿态估计的注释。
3.PASCAL VOC (Pattern Analysis, Statistical Modelling and Computational Learning Visual Object Classes)
- PASCAL VOC是一个用于图像识别和分类的数据集,包含了多个类别的对象(如人、汽车、自行车等)的图像和标注。
- 它提供了用于目标检测、图像分割等任务的标注数据。
4.CIFAR-10 和 CIFAR-100
- CIFAR-10和CIFAR-100是两个用于对象识别的数据集,由60,000张32×32彩色图像组成。
- CIFAR-10包含10个类别,而CIFAR-100包含100个类别。
- 这些数据集主要用于图像分类任务。
5.Cityscapes
- Cityscapes是一个专注于城市街道场景解析的数据集,包含了来自50个不同城市的街道场景中的立体视频序列。
- 它提供了像素级和实例级的语义标注,主要用于自动驾驶、城市环境理解等任务。
6.Kinetics
- Kinetics是一个大规模的人类动作视频数据集,包含了大约650,000个视频剪辑,涵盖700个人类动作类。
- 这些视频剪辑包括人与物、人与人之间的互动,每个剪辑都标注了一个持续约10秒的动作类。
- Kinetics主要用于动作识别等任务。
7.Fashion-MNIST
- Fashion-MNIST是一个用于服装图像分类的数据集,包含了60,000个训练样本和10,000个测试样本。
- 每个样本都是一个28×28的灰度图像,属于10个不同的服装类别。
这些数据集不仅为计算机视觉领域的研究提供了重要的基准测试平台,还推动了各种计算机视觉算法和技术的发展。通过在这些数据集上进行训练和测试,研究人员可以评估其算法的性能,并与其他算法进行比较。
四、计算资源
五、课程安排
Course website [Stanford University CS231n: Deep Learning for Computer Vision]

六、CS231N课程主要的内容
1.深度学习基础知识
2.感知和理解视觉世界的应用场景
(1)任务
图像分类、图像检索、目标检测、图像分割、视频分类、动作识别、姿态检测、医疗图像、银河识别等


(2)模型
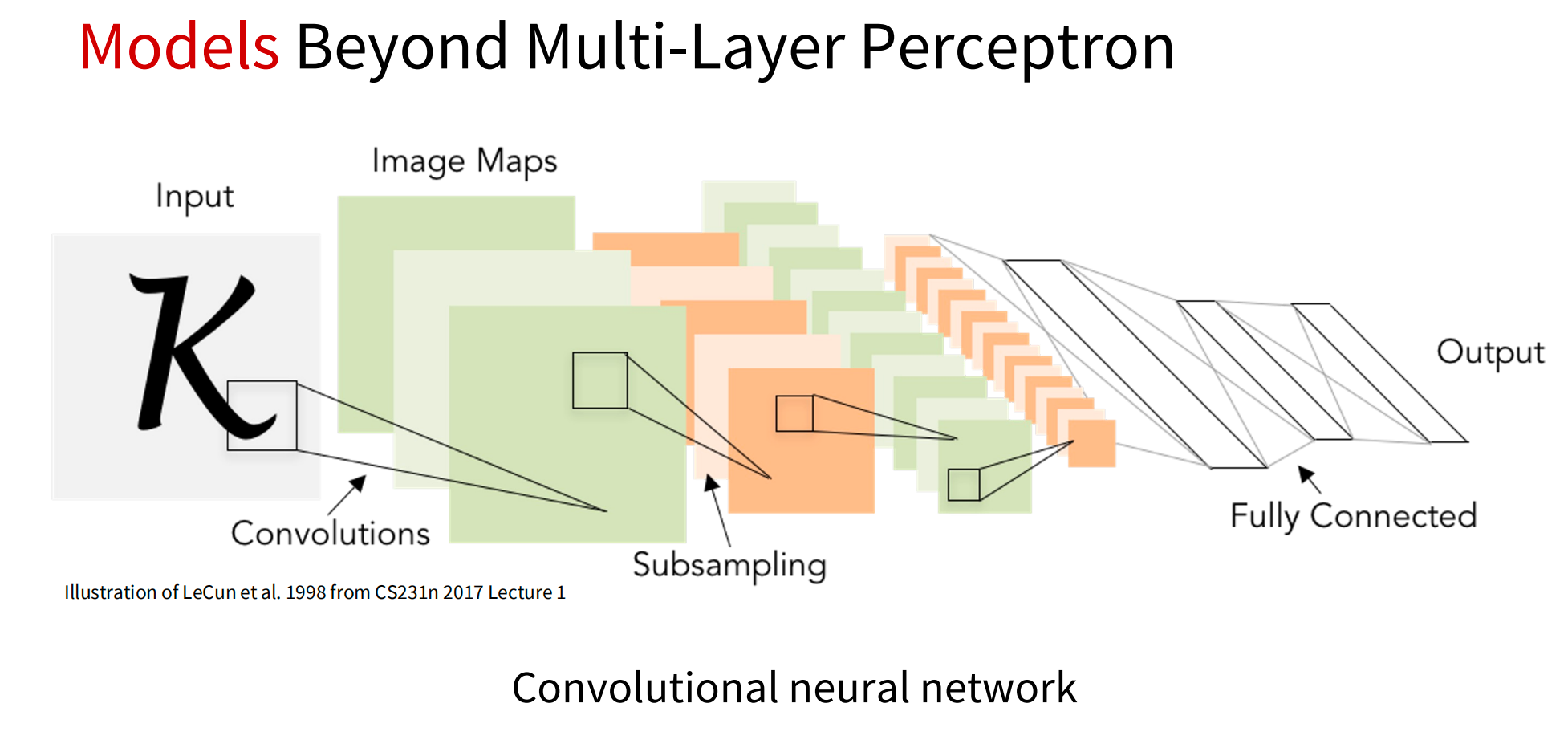
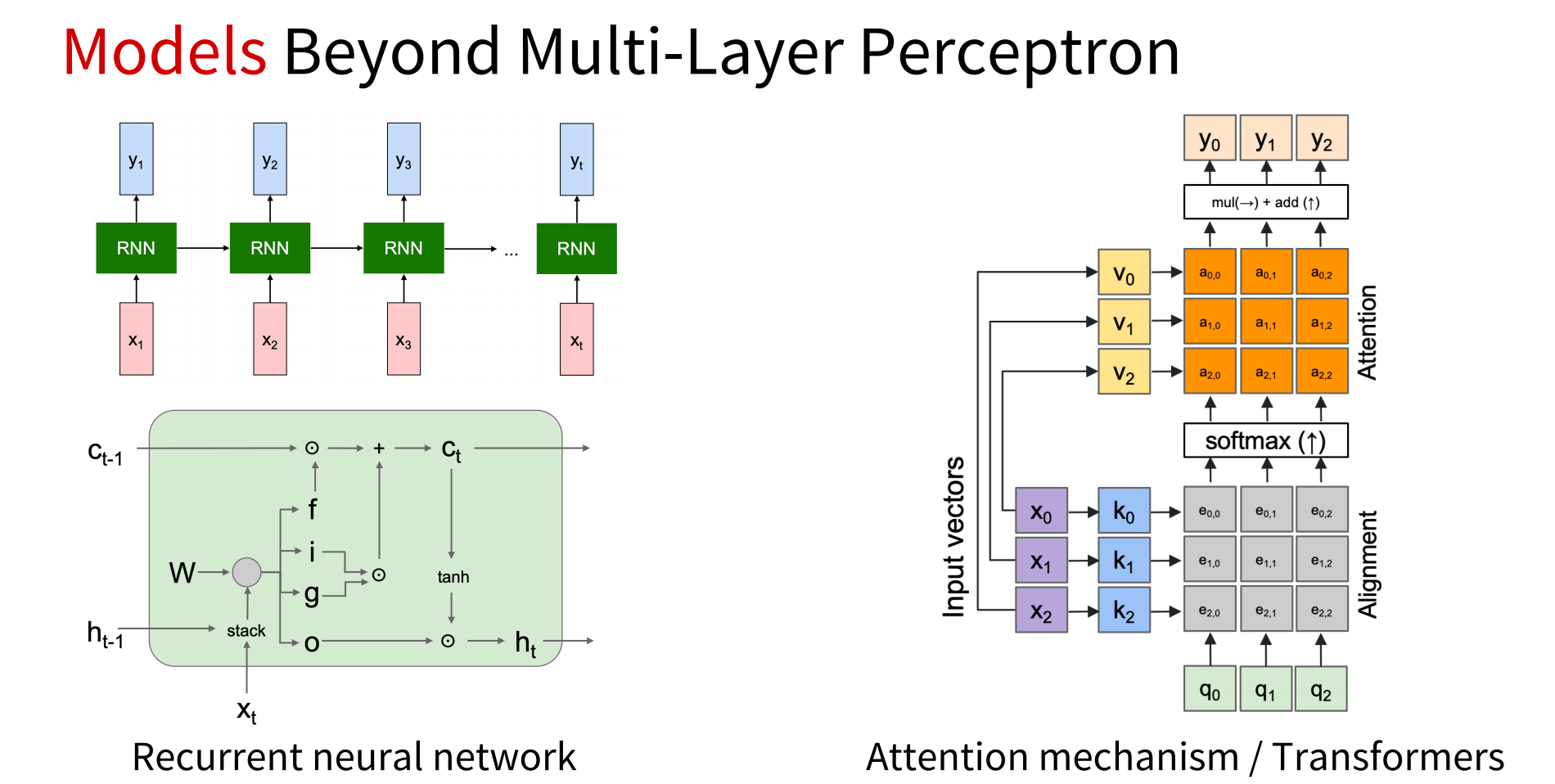
3.了解生成式和交互式视觉智能
(1)自监督学习
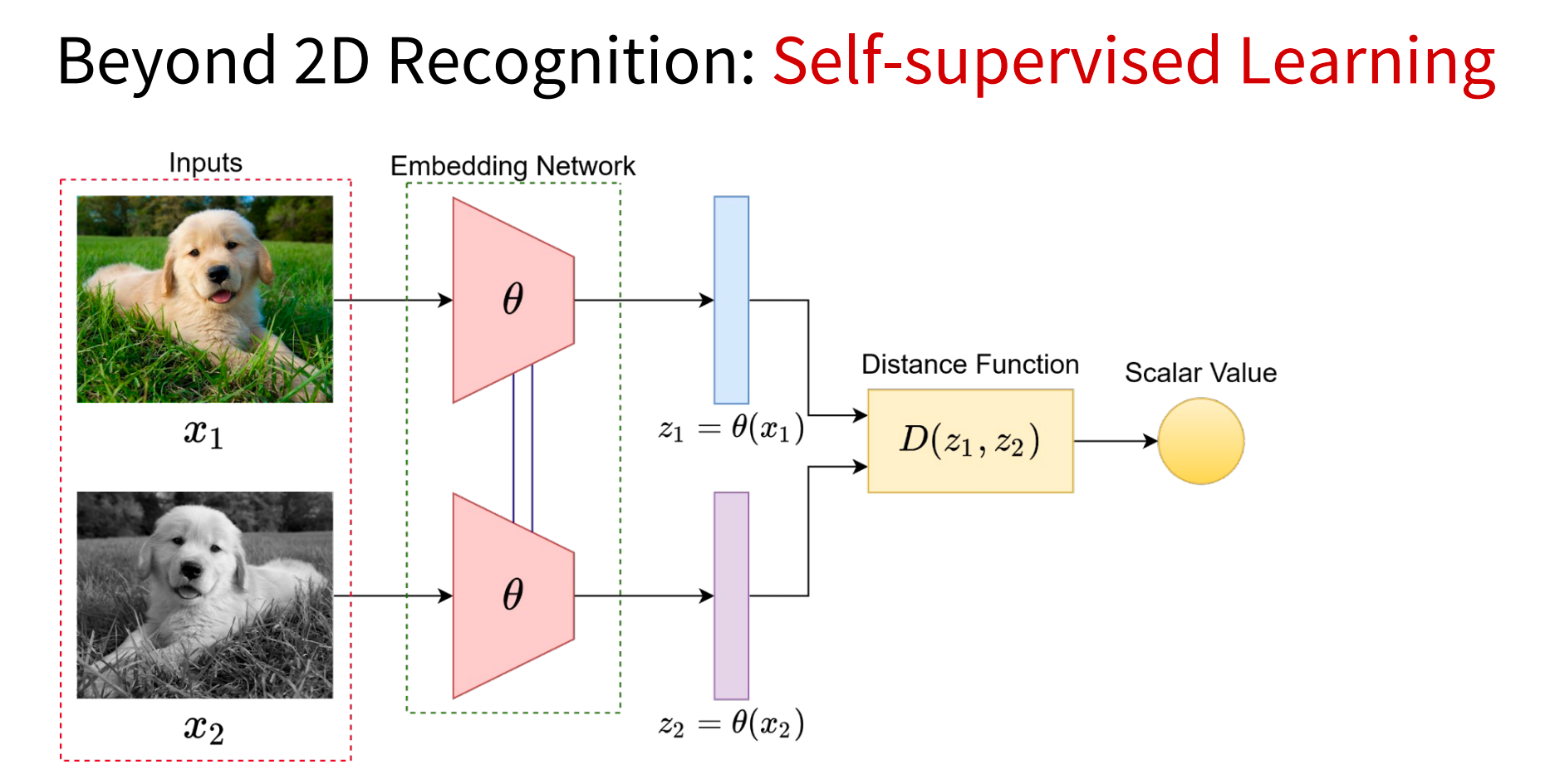
(2)生成式建模


(3)视觉语言模型
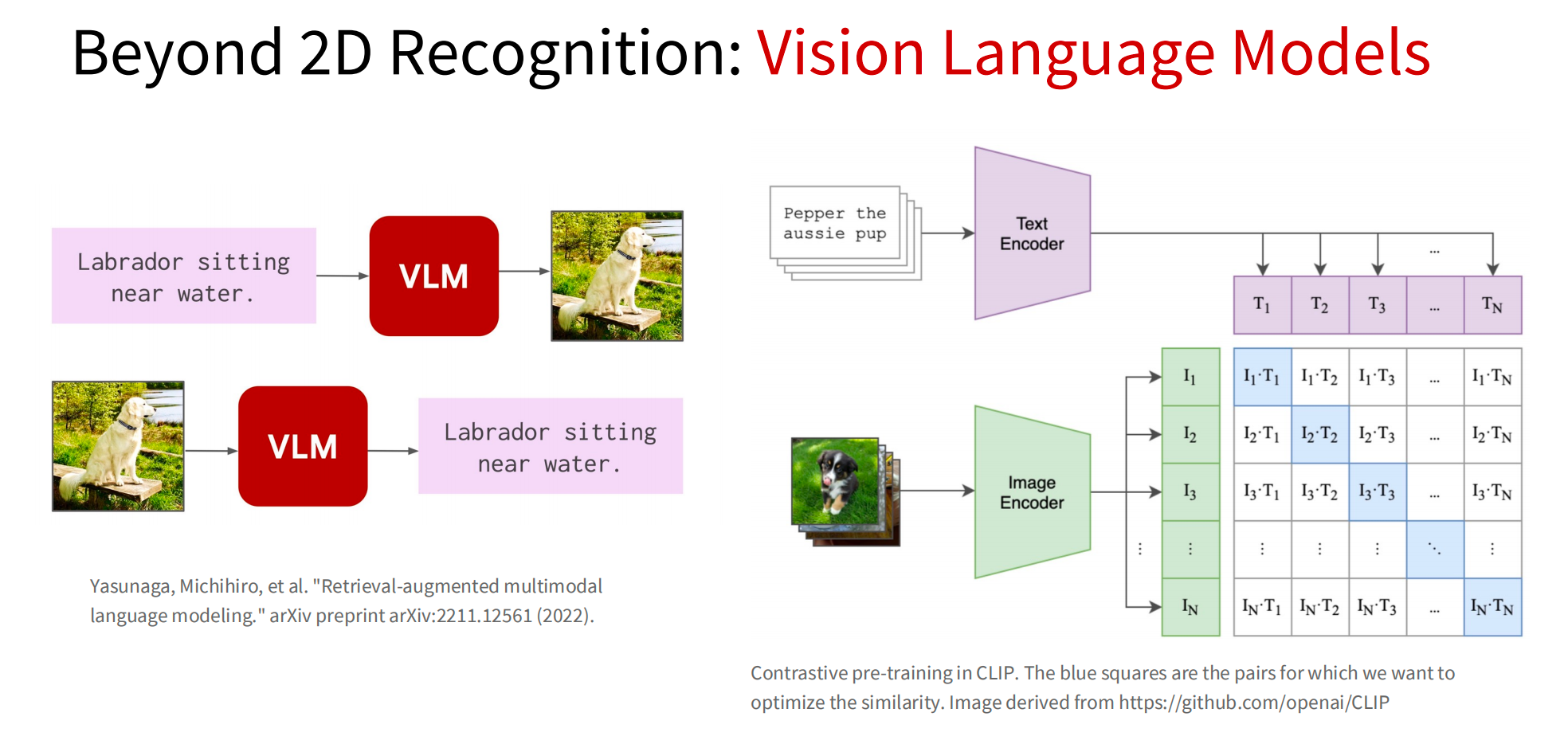
(4)三维视觉

(5)具身智能
指一种智能系统或机器能够通过感知和交互与环境进行实时互动的能力。可以简单理解为各种不同形态的机器人,让它们在真实的物理环境下执行各种各样的任务,来完成人工智能的进化过程。

4.以人为本的应用和产生的影响(Human-Centered Applications and Implications)

七、总结
本文主要从计算机视觉、深度学习发展历史入门,介绍了一些比较权威的视觉领域数据集,介绍了CS231n课程的主要内容,包括计算机视觉和深度学习的基础知识、视觉应用领域和生成式视觉模型等内容。


