
热门标签
热门文章
- 1solana共识设计理解_solona poh 共识
- 215 种最受欢迎的数据可视化流程图及模板_简单的数据流程图
- 3【kubernetes】K8S常见的发布方式
- 4fastjson之——@JSONField_fastjson jsonfield
- 5数仓之事实表和维度表(一)_聚集事实表
- 6一文带你玩转全新采集配置 CRD:AliyunPipelineConfig_数据采集自定义配置
- 7Spring Tool Suite 4(STS)的下载安装_sts下载
- 8CentOS7 使用yum安装Docker_centos7 yum 安装docker
- 9Vue项目部署上线全过程(保姆级教程)_vue项目怎么部署
- 10Thinking in Java——笔记(21)
当前位置: article > 正文
如何构建Python中的分布式爬虫系统:结合Scrapy与分布式任务队列的实践与优化_2024年第二届国际高校数学建模竞赛
作者:Li_阴宅 | 2024-08-06 02:12:20
赞
踩
2024年第二届国际高校数学建模竞赛
如何构建Python中的分布式爬虫系统:结合Scrapy与分布式任务队列的实践与优化
随着互联网的不断发展,网络爬虫在数据采集和信息挖掘中发挥着重要作用。然而,单机爬虫往往难以应对大规模数据抓取的需求,因此,构建分布式爬虫系统成为了一种必然选择。本文将介绍如何利用 Python 中的 Scrapy 框架和分布式任务队列来构建一个高效的分布式爬虫系统。
Scrapy 简介
Scrapy 是一个强大的 Python 爬虫框架,它提供了强大的抓取能力和灵活的数据提取功能。通过 Scrapy,我们可以轻松地定义爬虫的流程、规则和数据处理方式,从而快速地构建一个高效的单机爬虫系统。
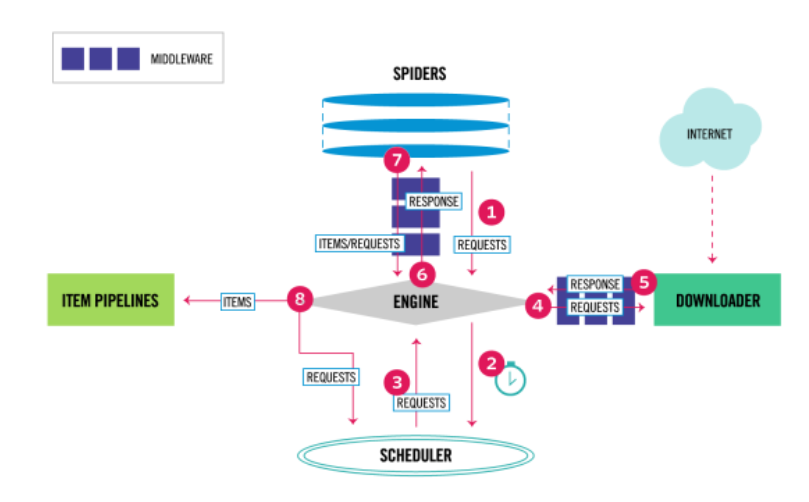
分布式任务队列简介
分布式任务队列是一种用于分发任务并协调多个节点之间工作的系统。它通常由任务生产者、任务队列和多个任务消费者组成。任务生产者负责生成任务并将其放入队列中,而任务消费者则从队列中获取任务并执行。
结合 Scrapy 和分布式任务队列
要构建一个分布式爬虫系统,我们可以将 Scrapy 作为任务消费者,而分布式任务队列则负责分发任务给多个 Scrapy 节点。Celery 是一个流行的 Python 分布式任务队列框架,我们将使用 Celery 作为我们的任务队列。
下面是构建分布式爬虫系统的基本步骤:
步骤一:安装必要的库
推荐阅读
相关标签

