
热门标签
热门文章
- 1Ubuntu sudo apt update 过程中遇到的报错解决_sudo apt update报错
- 2常见的socket出错总结_socket 错误码 55
- 3理想的程序员与平庸的程序员_现实中的程序员和理想中的程序员
- 4slot是什么?有什么作用?原理是什么?_slot是什么?有什么作用?原理是什么?
- 5基于JAVA,SpringBoot,Vue,UniAPP外卖订餐点餐小程序设计
- 6wds option 60 linux dhcp,dhcp server option 60使用方法配置简介
- 7win32gui操作_win32gui教程
- 8标量,向量,矩阵与张量_印刷体表示的标量,矩阵
- 9开源三维引擎OpenSceneGraph介绍_openscenegraph三维渲染
- 10Redis在有哨兵的情况下出现 Server closed the connection 或者 broken pipe的情况_redis error: broken pipe
当前位置: article > 正文
GAN生成MNIST数据集(pytorch版)_gan网络mnist pytorch
作者:Monodyee | 2024-02-18 00:59:37
赞
踩
gan网络mnist pytorch
前言
最近准备研究关于用GAN神经网络实现图片超分辨的项目,为了理解GAN神经网络的内涵和更熟悉的掌握pytorch框架的用法,写了这个小demo熟悉手感
思想
GAN的思想是是一种二人零和博弈思想,网上比较流行的一种比喻就是生成模型(G)是印假钞的人,而判别模型(D)就是判断是否是假钞的警察。
- 判别网络的目的:就是能判别输入的数据(如图片)它是来自真实样本集还是假样本集。假如输入的是真样本,网络输出就接近1,输入的是假样本,网络输出接近0,那么很完美,达到了很好判别的目的。
- 生成网络的目的:生成网络是造样本的,它的目的就是使得自己造样本的能力尽可能强,强到判别网络没法判断我是真样本还是假样本。

代码实现
talk is cheap,show me your code
# coding=utf-8 import torch.autograd import torch.nn as nn from torch.autograd import Variable from torchvision import transforms from torchvision import datasets from torchvision.utils import save_image import os # 创建文件夹 if not os.path.exists('./img2'): os.mkdir('./img2') def to_img(x): out = 0.5 * (x + 1) out = out.clamp(0, 1) # Clamp函数可以将随机变化的数值限制在一个给定的区间[min, max]内: out = out.view(-1, 1, 28, 28) # view()函数作用是将一个多行的Tensor,拼接成一行 return out batch_size = 128 num_epoch = 1000 z_dimension = 50 # 图像预处理 img_transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1,), (0.5,)) ]) # mnist dataset mnist数据集下载,没有下载的将download改成True mnist = datasets.MNIST( root='./mnist/', train=True, transform=img_transform, download=False ) # data loader 数据载入 dataloader = torch.utils.data.DataLoader( dataset=mnist, batch_size=batch_size, shuffle=True ) # 定义判别器 #####Discriminator######使用多层网络来作为判别器 # 将图片28x28展开成784,然后通过多层感知器,中间经过斜率设置为0.2的LeakyReLU激活函数, # 最后接sigmoid激活函数得到一个0到1之间的概率进行二分类。 class discriminator(nn.Module): def __init__(self): super(discriminator, self).__init__() self.dis = nn.Sequential( nn.Linear(784, 512), # 输入特征数为784,输出为512 nn.BatchNorm1d(512), nn.LeakyReLU(0.2), # 进行非线性映射 nn.Linear(512, 256), # 进行一个线性映射 nn.BatchNorm1d(256), nn.LeakyReLU(0.2), nn.Linear(256, 1), nn.Sigmoid() # 也是一个激活函数,二分类问题中, # sigmoid可以班实数映射到【0,1】,作为概率值, # 多分类用softmax函数 ) def forward(self, x): x = self.dis(x) return x ####### 定义生成器 Generator ##### # 输入一个50维的0~1之间的高斯分布,然后通过第一层线性变换将其映射到256维, # 然后通过LeakyReLU激活函数,接着进行一个线性变换,再经过一个LeakyReLU激活函数, # 然后经过线性变换将其变成784维,最后经过Tanh激活函数是希望生成的假的图片数据分布 # 能够在-1~1之间。 class generator(nn.Module): def __init__(self): super(generator, self).__init__() self.gen = nn.Sequential( nn.Linear(50, 128), nn.LeakyReLU(0.2), nn.Linear(128, 256), nn.BatchNorm1d(256), nn.LeakyReLU(0.2), nn.Linear(256, 512), nn.BatchNorm1d(512), nn.LeakyReLU(0.2), nn.Linear(512, 1024), nn.BatchNorm1d(1024), nn.LeakyReLU(0.2), nn.Linear(1024, 784), nn.Tanh() ) def forward(self, x): x = self.gen(x) return x # 创建对象 D = discriminator() G = generator() if torch.cuda.is_available(): D = D.cuda() G = G.cuda() #########判别器训练train##################### # 分为两部分:1、真的图像判别为真;2、假的图像判别为假 # 此过程中,生成器参数不断更新 # 首先需要定义loss的度量方式 (二分类的交叉熵) # 其次定义 优化函数,优化函数的学习率为0.0003 criterion = nn.BCELoss() # 是单目标二分类交叉熵函数 d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003) g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003) ###########################进入训练##判别器的判断过程##################### for epoch in range(num_epoch): # 进行多个epoch的训练 for i, (img, _) in enumerate(dataloader): num_img = img.size(0) # view()函数作用是将一个多行的Tensor,拼接成一行 # 第一个参数是要拼接的tensor,第二个参数是-1 # =============================训练判别器================== img = img.view(num_img, -1) # 将图片展开为28*28=784 real_img = Variable(img).cuda() # 将tensor变成Variable放入计算图中 real_label = Variable(torch.ones(num_img)).cuda() # 定义真实的图片label为1 fake_label = Variable(torch.zeros(num_img)).cuda() # 定义假的图片的label为0 # 计算真实图片的损失 real_out = D(real_img) # 将真实图片放入判别器中 d_loss_real = criterion(real_out, real_label) # 得到真实图片的loss real_scores = real_out # 得到真实图片的判别值,输出的值越接近1越好 # 计算假的图片的损失 z = Variable(torch.randn(num_img, z_dimension)).cuda() # 随机生成一些噪声 fake_img = G(z) # 随机噪声放入生成网络中,生成一张假的图片 fake_out = D(fake_img) # 判别器判断假的图片 d_loss_fake = criterion(fake_out, fake_label) # 得到假的图片的loss fake_scores = fake_out # 得到假图片的判别值,对于判别器来说,假图片的损失越接近0越好 # 损失函数和优化 d_loss = d_loss_real + d_loss_fake # 损失包括判真损失和判假损失 d_optimizer.zero_grad() # 在反向传播之前,先将梯度归0 d_loss.backward() # 将误差反向传播 d_optimizer.step() # 更新参数 # ==================训练生成器============================ ################################生成网络的训练############################### # 原理:目的是希望生成的假的图片被判别器判断为真的图片, # 在此过程中,将判别器固定,将假的图片传入判别器的结果与真实的label对应, # 反向传播更新的参数是生成网络里面的参数, # 这样可以通过更新生成网络里面的参数,来训练网络,使得生成的图片让判别器以为是真的 # 这样就达到了对抗的目的 # 计算假的图片的损失 z = Variable(torch.randn(num_img, z_dimension)).cuda() # 得到随机噪声 fake_img = G(z) # 随机噪声输入到生成器中,得到一副假的图片 # output = D(fake_img) # 经过判别器得到的结果 g_loss = criterion(output, real_label) # 得到的假的图片与真实的图片的label的loss # bp and optimize g_optimizer.zero_grad() # 梯度归0 g_loss.backward() # 进行反向传播 g_optimizer.step() # .step()一般用在反向传播后面,用于更新生成网络的参数 # 打印中间的损失 if (i + 1) % 100 == 0: print('Epoch[{}/{}],d_loss:{:.6f},g_loss:{:.6f} ' 'D real: {:.6f},D fake: {:.6f}'.format( epoch, num_epoch, d_loss.data.item(), g_loss.data.item(), real_scores.data.mean(), fake_scores.data.mean() # 打印的是真实图片的损失均值 )) if epoch == 0 and i==len(dataloader)-1: real_images = to_img(real_img.cuda().data) save_image(real_images, './img2/real_images.png') if i==len(dataloader)-1: fake_images = to_img(fake_img.cuda().data) save_image(fake_images, './img2/fake_images-{}.png'.format(epoch + 1)) # 保存模型 torch.save(G.state_dict(), './generator.pth') torch.save(D.state_dict(), './discriminator.pth')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 迭代过程如下图,如果不能动的话保存下来应该就可以了:

- 迭代200次后的结果与原图对比如下:

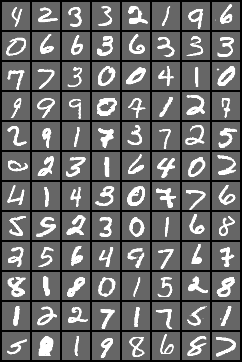
有一说一,MNIST数据集里面手写的数字也是够丑的,我反正没见过有几个人能把数字写成这样。。。难为计算机了
神经网络的结构只是普通的深层神经网络加入了batch-normal层,有时间的话可以尝试使用卷积神经网络实现,模拟效果应该会更好
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/103071
推荐阅读
相关标签

