
- 1golang生成供C调用的动态库_c调用golang动态库
- 2yolov8环境搭建_yolov8环境部署
- 3DeepSpeed实战系列篇1:RTX 3090服务器部署及训练过程详解
- 4幻兽帕鲁服务器怎么更新?如何快速在腾讯云更新幻兽帕鲁Palworld服务器,显示版本不兼容怎么解决_palserver更新
- 5Linux-软件包的安装和卸载_linux怎么删除安装包
- 6fastdfs单双节点搭建
- 7LeetCode中级算法之排序和搜索_一个直观的解决方案是使用计数排序的两趟扫描算法。 首先,迭代计算出0、1 和 2 元
- 82023年mathorcup数学建模大赛C题电商物流网络包裹应急调运与结构优化问题论文思路分析与代码
- 9YOLOv5源码逐行详细注释与解读 - detect.py推理部分_yolov5推理代码
- 10【无门槛】机器学习——Amazon SageMaker Canvas 【实验配置篇】
开启MongoDB更新文档操作的正确姿势_mongdb cursor 更新
赞
踩
将文档存入数据库中之后,可以使用以下几种更新方法之一对其进行更改:updateOne、updateMany 和 replaceOne。updateOne 和 updateMany 都将筛选文档作为第一个参数,将变更文档作为第二个参数,后者对要进行的更改进行描述。replaceOne 同样将筛选文档作为第一个参数,但第二个参数是一个用来替换所匹配的筛选文档的新文档。
更新文档是原子操作:如果两个更新同时发生,那么首先到达服务器的更新会先被执行,然后再执行下一个更新。因此,相互冲突的更新可以安全地迅速接连完成,而不会破坏任何文档:最后一次更新将“成功”。如果不想使用默认行为,则可以考虑使用文档版本控制模式
文档替换
replaceOne 会用新文档完全替换匹配的文档。这对于进行大规模模式迁移的场景非常有用。假设要对下面的用户文档进行比较大的更改:
// 定义文档
> var document = {
... "_id" : ObjectId("4b2b9f67a1f631733d917a7a"),
... "name" : "joe",
... "friends" : 32,
... "enemies" : 2
... }
// 向users集合插入文档
> db.users.insertOne(document)
{
"acknowledged" : true,
"insertedId" : ObjectId("4b2b9f67a1f631733d917a7a")
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
我们希望把 “friends” 和 “enemies” 两个字段移到 “relationships” 子文档中。可以在 shell 中更改文档的结构,然后使用 replaceOne 替换数据库中的当前文档:
> var joe = db.users.findOne({name: "joe"})
> joe.relationships = {friends: joe.friends, enemies: joe.enemies}
{ "friends" : 32, "enemies" : 2 }
> joe.username = joe.name
joe
> delete joe.friends
true
> delete joe.enemies
true
> delete joe.name
true
> db.users.replaceOne({name: "joe"}, joe)
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
现在用 findOne 查看更新后的文档结构:
> db.users.find().pretty()
{
"_id" : ObjectId("4b2b9f67a1f631733d917a7a"),
"relationships" : {
"friends" : 32,
"enemies" : 2
},
"username" : "joe"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
一个常见的错误是查询条件匹配到了多个文档,然后更新时由第二个参数产生了重复的"_id" 值。数据库会抛出错误,任何文档都不会被更新。
举例:
如果今天是第二个 joe 的生日,我们需要增加 “age” 的值,那么可能会这么做:
> db.users.find()
{ "_id" : ObjectId("4b2b9f67a1f631733d917a7b"), "name" : "joe", "age" : 65 }
{ "_id" : ObjectId("4b2b9f67a1f631733d917a7c"), "name" : "joe", "age" : 20 }
{ "_id" : ObjectId("4b2b9f67a1f631733d917a7d"), "name" : "joe", "age" : 49 }
> joe = db.users.findOne({name: "joe", age: 20})
{ "_id" : ObjectId("4b2b9f67a1f631733d917a7c"), "name" : "joe", "age" : 20 }
> joe.age++
20
> db.users.replaceOne({name: "joe"}, joe)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
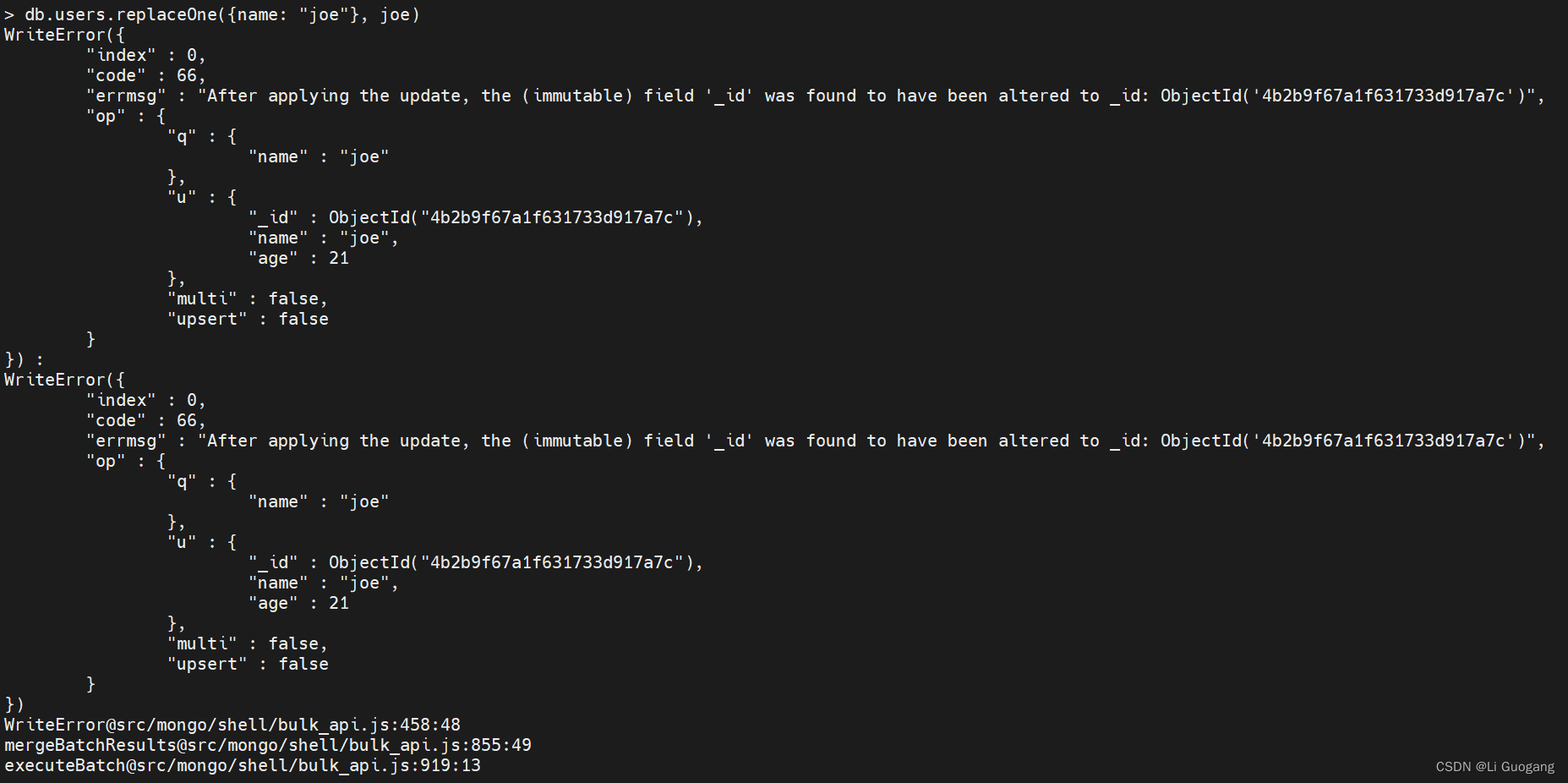
发生了什么?当执行更新操作时,数据库会搜索匹配 {“name” : “joe”} 条件的文档。第一个被找到的是 65 岁的 joe。然后数据库会尝试用变量 joe 中的内容替换找到的文档,但是在这个集合中已经有一个相同 “_id” 的文档存在,因此,更新操作会失败,因为 “_id"必须是唯一的。避免这种情况的最好方法是确保更新始终指定一个唯一的文档,例如使用”_id" 这样的键来匹配。对于上面的例子,下面才是正确的更新方法:
> db.users.replaceOne({_id: ObjectId("4b2b9f67a1f631733d917a7c")}, joe)
- 1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c2DRs5Xc-1666765777177)(images/image-20221026102346808.png)]](https://img-blog.csdnimg.cn/e399848a2704451ab62ddbfc7f387dbc.png)
使用 “_id” 作为筛选条件也会使查询更高效,因为 “_id” 值构成了集合主索引的基础。
使用更新运算符
通常文档只会有一部分需要更新。可以使用原子的更新运算符(update operator)更新文档中的特定字段。更新运算符是特殊的键,可用于指定复杂的更新操作,比如更改、添加或删除键,甚至可以操作数组和内嵌文档。
“$inc” 修饰符
假设我们要将网站分析数据保存在一个集合中,并且希望每次有人访问页面时都递增一个计数器。可以使用更新运算符原子地执行这个递增操作。每个 URL 及其对应的访问次数都以如下方式存储在文档中:
> var document = {
... "_id" : ObjectId("4b253b067525f35f94b60a31"),
... "url" : "example-domain",
... "pageviews" : 52
... }
- 1
- 2
- 3
- 4
- 5
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ynw9iiEP-1666765777178)(images/image-20221026102835605.png)]](https://img-blog.csdnimg.cn/79ea129b26f84db7ab55f3cf4d595810.png)
每次有人访问页面时,就通过 URL 找到该页面,并使用 “$inc” 修饰符增加 "pageviews"的值:
> db.views.updateOne({url: "example-domain"}, {$inc: {pageviews: 1}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
现在,执行 findOne 操作,会发现 “pageviews” 的值增加了 1:

使用更新运算符时,“_id” 的值是不能改变的。(注意,整个文档替换时是可以改变 "_id"的。)其他键值,包括其他唯一索引的键,都是可以更改的。
"$set"修饰符
“$set” 用来设置一个字段的值。如果这个字段不存在,则创建该字段。这对于更新模式或添加用户定义的键来说非常方便。假如你有一个简单的用户资料存储在下面这样的文档中:
> db.users.findOne()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"name" : "joe",
"age" : 30,
"sex" : "male",
"location" : "Wisconsin"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这是非常基本的用户信息。如果用户想将他喜欢的图书保存进去,可以使用 “$set”:
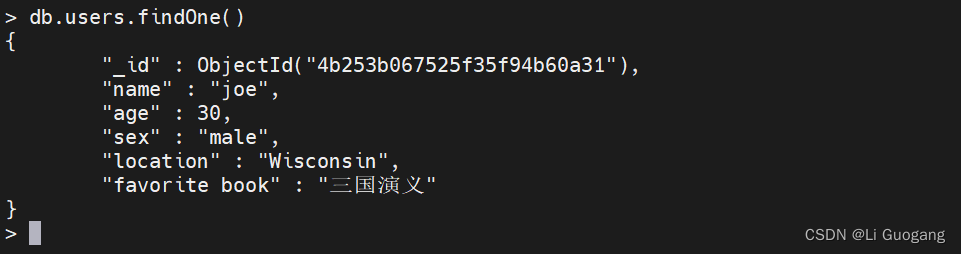
> db.users.updateOne({_id: ObjectId("4b253b067525f35f94b60a31")}, {$set: {"favorite book": "三国演义"}})
- 1
随后文档就有 “favorite book” 键了:
如果用户觉得其实喜欢的是另外一本书,则可以再次使用 “$set” 来修改这个值:
> db.users.updateOne({name: "joe"}, {$set: {"favorite book": "西游记"}})
- 1
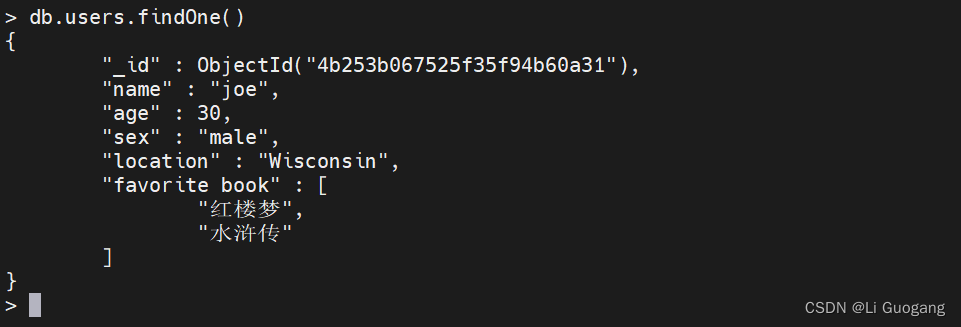
“$set” 甚至可以修改键的类型。如果用户觉得喜欢很多本书,那么可以将 “favorite book” 键的值更改为一个数组:
> db.users.updateOne({name: "joe"}, {$set: {"favorite book": ["红楼梦","水浒传"]}})
- 1
如果用户发现自己其实不爱读书,则可以用 “$unset” 将这个键完全删除:
> db.users.updateOne({name: "joe"},
... {$unset: {"favorite book": 1}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
- 3
现在这个文档就和刚开始时一样了。
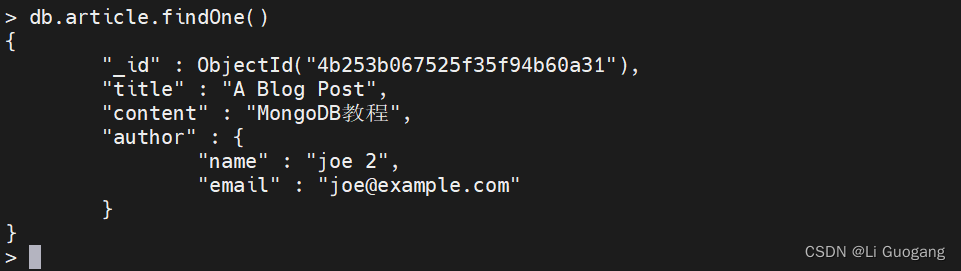
也可以使用 “$set” 来修改内嵌文档:
> db.article.findOne()
{
"_id" : ObjectId("4b253b067525f35f94b60a31"),
"title" : "A Blog Post",
"content" : "MongoDB教程",
"author" : {
"name" : "joe",
"email" : "joe@example.com"
}
}
> db.article.updateOne({"author.name": "joe"}, {$set: {"author.name": "joe 2"}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
应该始终使用 $ 修饰符来增加、修改或删除键。常见的错误做法是把键的值通过更新设置成其他值,如以下操作所示:
> db.article.updateOne({"author.name": "joe 2"}, {"author.name": "joe 3"} )
- 1
这会事与愿违。更新的文档必须包含更新运算符。之前版本的 CRUD API 无法捕捉这种类型的错误。早期的更新方法在这种情况下会简单地进行整个文档的替换。正是这种缺陷促成了新 CRUD API 的诞生。
递增操作和递减操作
“$inc” 运算符可以用来修改已存在的键值或者在该键不存在时创建它。对于更新分析数据、因果关系、投票或者其他有数值变化的地方,使用这个会非常方便。
和 “$set” 用法类似,“$inc” 是专门用来对数字进行递增和递减操作的。“$inc” 只能用于整型、长整型或双精度浮点型的值。如果用在其他任何类型(包括很多语言中会被自动转换为数值的类型,比如 null、布尔类型以及数字构成的字符串)的值上,则会导致操作失败:
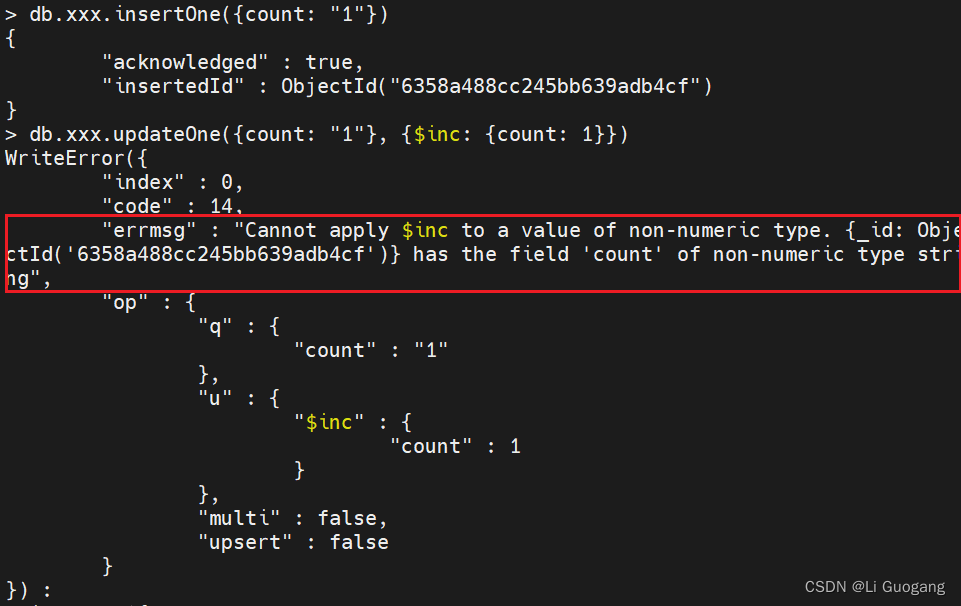
“$inc” 键的值必须为数字类型。不能使用字符串、数组或者其他非数字类型的值。
数组运算符
MongoDB 中有一大类更新运算符用于操作数组。数组是常用且功能强大的数据结构:它们不仅是可以通过索引进行引用的列表,而且可以作为集合来使用。
添加元素。如果数组已存在,“$push” 就会将元素添加到数组末尾;如果数组不存在,则会创建一个新的数组。假设我们要存储博客文章,并希望添加一个用于保存数组的"comments" 键。可以向还不存在的 “comments” 数组添加一条评论,这个数组会被自动创建并加入一条评论:
> var document = {
... "_id" : ObjectId("4b2d75476cc613d5ee930164"),
... "title" : "A blog post",
... "content" : "..."
... }
> db.blog.insertOne(document)
{
"acknowledged" : true,
"insertedId" : ObjectId("4b2d75476cc613d5ee930164")
}
> db.blog.updateOne({"title" : "A blog post"},
... {$push: {comments: {name: "joe", email: "joe@qq.com", content: "MongoDB教程"}}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
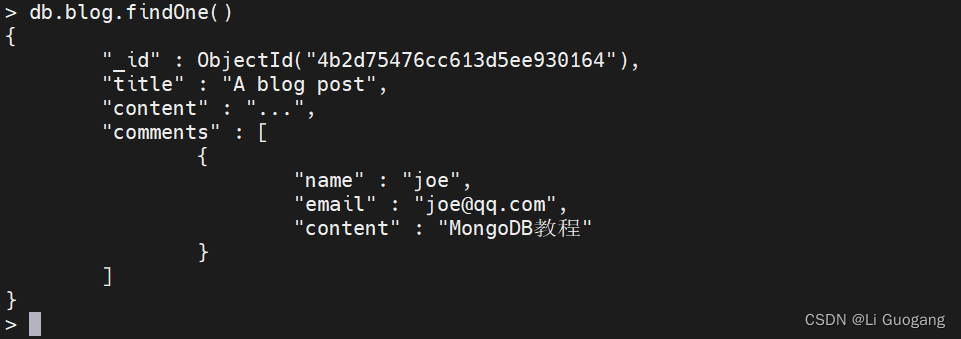
现在如果想添加另一条评论,可以再次使用 “$push”:
> db.blog.updateOne({"title" : "A blog post"},
... {$push: {comments: {name: "joe 2", email: "joe 2@qq.com", content: "MongoDBj教程"}}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
- 3
- 4
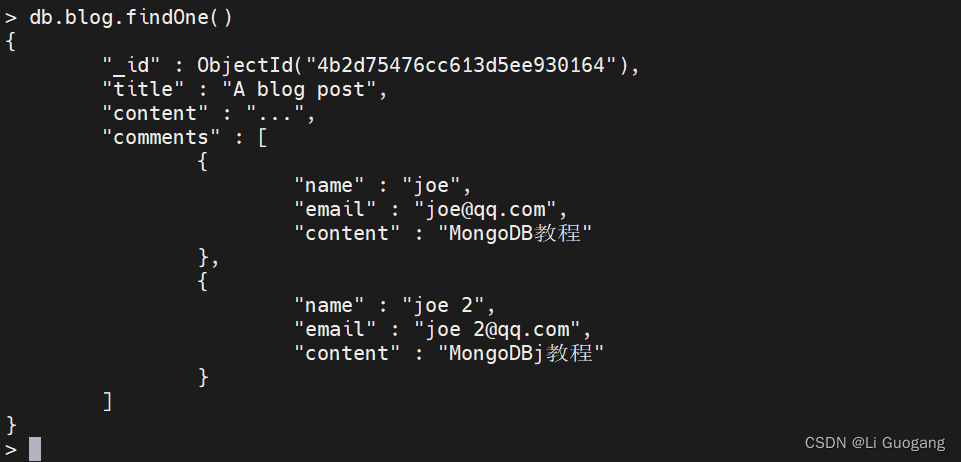
这是"$push" 的一种比较“简单”的使用方式,但也可以将它应用在更复杂的数组运算中。MongoDB 查询语言为一些运算符提供了修饰符,其中就包括 “$push”。可以对"$push" 使用 “$each” 修饰符,在一次操作中添加多个值:
> db.testArr.insertOne({_id: 1})
{ "acknowledged" : true, "insertedId" : 1 }
> db.testArr.updateOne({_id: 1},
... {$push: {subArr: {$each: [1,2,3,]}}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
- 3
- 4
- 5

这会将 3 个新元素添加到数组中。
如果只允许数组增长到某个长度,则可以使用 “$slice” 修饰符配合 $push 来防止数组的增长超过某个大小,从而有效地生成“top N ”列表:
> db.testArr.findOne()
{ "_id" : 1, "subArr" : [ 1, 2, 3 ] }
> db.testArr.updateOne({_id: 1},
... {$push: {top10: {$each: [4,5,6], $slice: -10}}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
- 3
- 4
- 5
这个例子限制了数组只包含最后加入的 10 个元素。
如果数组元素数量小于 10(在 “$push” 之后),就保留所有元素;如果数组元素数量大于 10,则只保留最后 10 个元素。因此,“$slice” 可用于在文档中创建一个队列。
最后,在截断之前可以将 “$sort” 修饰符应用于 “$push” 操作:
> db.testArr.updateOne({_id: 1}, {$push: {top10: {$each: [{name:"joe", age: 18},{name: "joe 2", age: 20},{name: "joe 3", age: 30}], $slice: -10, $sort: {age: -1}}}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
这样会根据 “age” 字段的值对数组中的所有对象进行排序,然后保留前 10 个。注意,不能只将 “$slice” 或 “$sort” 与 “$push” 配合使用,必须包含 “$each”。
将数组作为集合使用。你可能希望将数组视为集合,仅当一个值不存在时才进行添加。这可以在查询文档中使用 “$ne” 来实现。要是作者不在引文列表中,就将其添加进去。可以使用以下命令:
> db.authors.insertOne({_id: 1})
{ "acknowledged" : true, "insertedId" : 1 }
> db.authors.updateOne({"authors cited": {$ne: "Richie"}},
... {$push: {"authors cited": "Richie"}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
- 3
- 4
- 5

也可以用 “$addToSet” 来实现,因为有些情况下无法使用 “$ne”,或者 “$addToSet” 更适合。
假设你有一个表示用户的文档,现在已经添加了电子邮件地址的集合:
> db.users.findOne()
{ "_id" : 1, "name" : "joe", "emails" : [ "joe@qq.com" ] }
- 1
- 2
当添加新地址时,可以使用 “$addToSet” 来避免插入重复的邮件地址:
> db.users.updateOne({_id: 1},
... {$addToSet: {emails: "joe@qq.com"}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 0 }
- 1
- 2
- 3

还可以将 “$addToSet” 与 “$each” 结合使用,以添加多个不同的值,而这不能使用"$ne" 和 “$push” 的组合来实现。如果用户希望一次添加多个电子邮件地址,那么可以使用下面这些运算符。
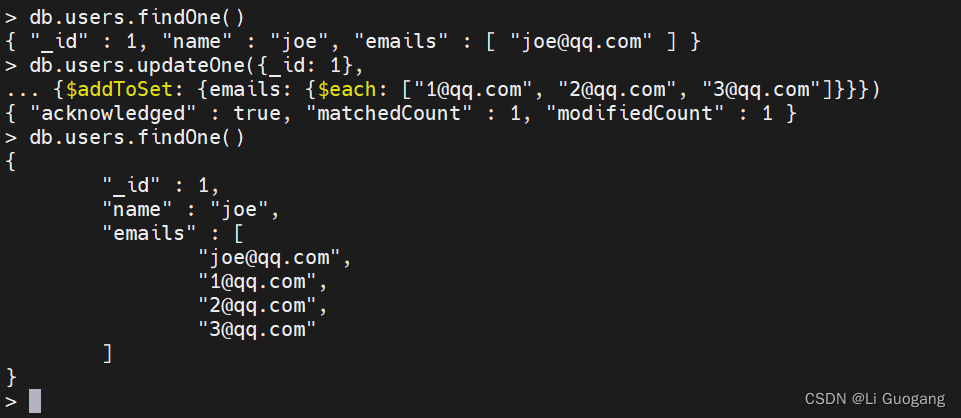
删除元素。有多种方法可以从数组中删除元素。如果将数组视为队列或者栈,那么可以使用 “KaTeX parse error: Expected '}', got 'EOF' at end of input: …p" 从任意一端删除元素。{"pop” : {“key” : 1}} 会从数组末尾删除一个元素,{“$pop” : {“key” : -1}} 则会从头部删除它。
有时需要根据特定条件而不是元素在数组中的位置删除元素。“$pull” 用于删除与给定条件匹配的数组元素。假设有一个待完成事项的列表,但没有任何特定的顺序:
> db.lists.findOne()
{
"_id" : ObjectId("6358c42acc245bb639adb4d0"),
"todo" : [
"dishes",
"laundry",
"dry cleaning"
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果想把洗衣服(laundry)放到第一位,那么可以使用以下方法把它从列表中删除:
> db.lists.updateOne({}, {$pull: {todo: "laundry"}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
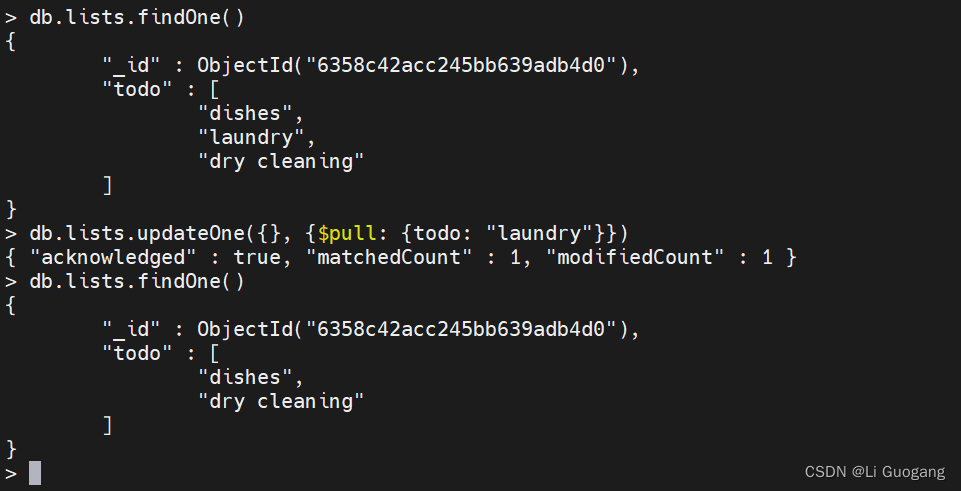
“$pull” 会删除所有匹配的文档,而不仅仅是一个匹配项。如果你有一个数组 [1, 1, 2, 1]并执行 pull 1,那么你将得到只有一个元素的数组 [2]。
数组运算符只能用于包含数组值的键。例如,不能将元素插入一个整数中,也不能从一个字符串中弹出元素。请使用 “$set” 或 “$inc” 来修改标量值。
基于位置的数组更改。当数组中有多个值,但我们只想修改其中的一部分时,在操作上就需要一些技巧了。有两种方法可以操作数组中的值:按位置或使用定位运算符($ 字符)。
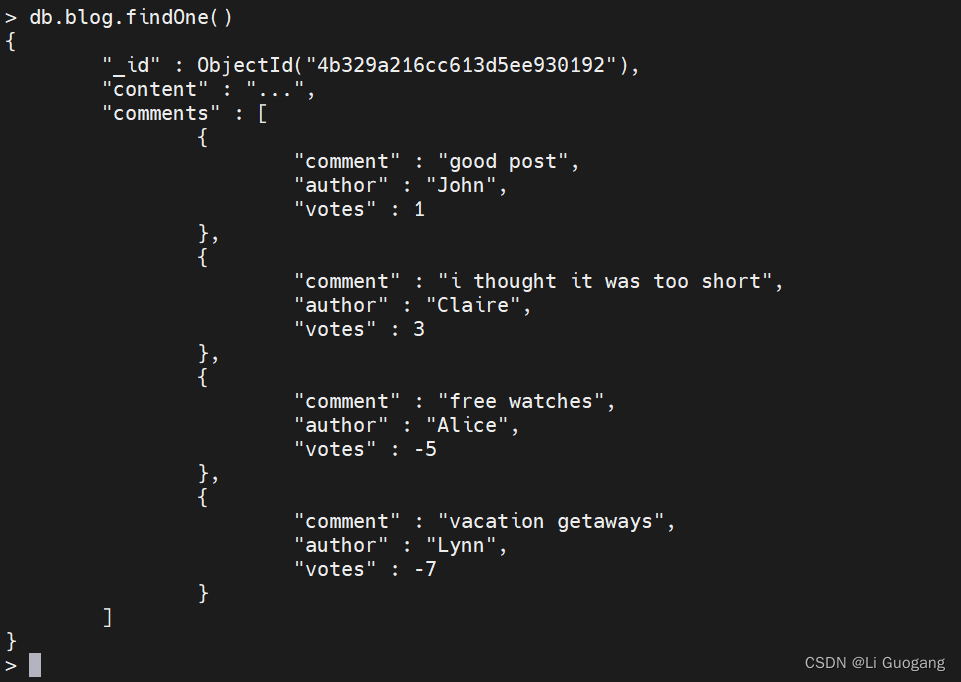
数组使用从 0 开始的下标,可以将下标当作文档的键来选择元素。假设我们有一个包含数组的文档,数组中又内嵌了一些文档,比如带有评论的博客文章:
> db.blog.findOne() { "_id" : ObjectId("4b329a216cc613d5ee930192"), "content" : "...", "comments" : [ { "comment" : "good post", "author" : "John", "votes" : 0 }, { "comment" : "i thought it was too short", "author" : "Claire", "votes" : 3 }, { "comment" : "free watches", "author" : "Alice", "votes" : -5 }, { "comment" : "vacation getaways", "author" : "Lynn", "votes" : -7 } ] }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
如果希望增加第一条评论的投票数量,可以像下面这样做:
> db.blog.updateOne({"_id": ObjectId("4b329a216cc613d5ee930192")}, {$inc: {"comments.0.votes": 1}} )
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
不过,在很多情况下,如果不预先查询文档并进行检查,就不知道要修改数组的下标。为了解决这个问题,MongoDB 提供了一个定位运算符 $,它可以计算出查询文档匹配的数组元素并更新该元素。如果有一个名为 John 的用户将其名字改为了 Jim,那么可以使用定位运算符在评论中进行替换:
> db.blog.updateOne({"comments.author": "John"}, {$set: {"comments.$.author": "Jim"}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
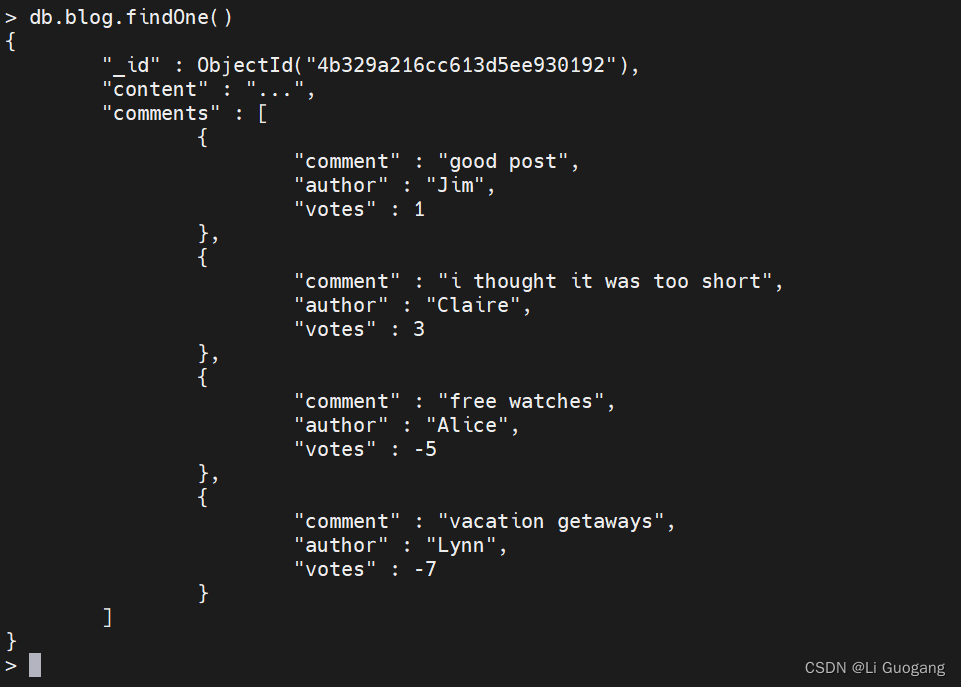
定位运算符只会更新第一个匹配到的元素。因此,如果 John 发表了多条评论,那么他的名字只会在第一条评论中被改变。
使用数组过滤器进行更新。MongoDB 3.6 引入了另一个用于更新单个数组元素的选项:arrayFilters。此选项使我们能够修改与特定条件匹配的数组元素。如果想隐藏所有拥有 5个或以上反对的评论,那么可以执行以下操作:
> db.blog.updateOne({_id: ObjectId("4b329a216cc613d5ee930192")}, {$set: {"comments.$[elem].hidden": true}}, {arrayFilters: [{"elem.votes": {$lte: -5}}]})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
- 1
- 2
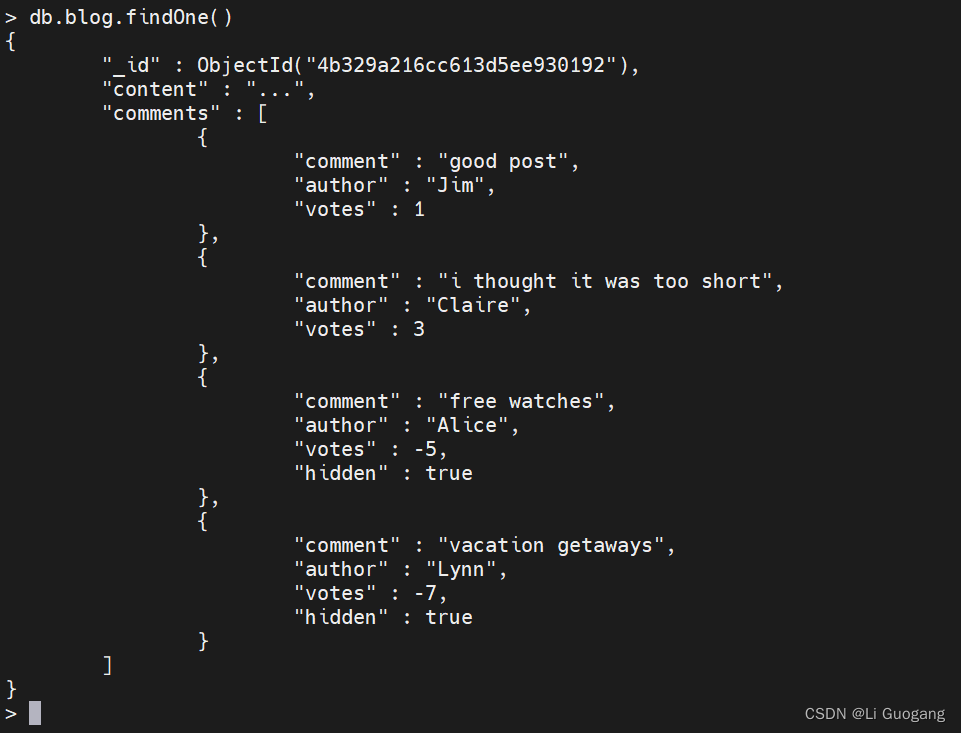
这个语句将 elem 定义为了 “comments” 数组中每个匹配元素的标识符。如果 elem 所标识的评论的 votes 值小于或等于 -5,那么就在 “comments” 文档中添加一个名为"hidden" 的字段,并将其值设置为 true。
upsert
upsert 是一种特殊类型的更新。如果找不到与筛选条件相匹配的文档,则会以这个条件和更新文档为基础来创建一个新文档;如果找到了匹配的文档,则进行正常的更新。upsert 用起来非常方便,有了它便不再需要“预置”集合:通常可以使用同一套代码创建和更新文档。
下面再回到那个记录每个网页访问次数的例子。如果没有 upsert,那么我们可能会尝试查找 URL 并增加访问次数,或者在 URL 不存在的情况下创建一个新文档。如果把它写成一个 JavaScript 程序,它可能看起来像下面这样:
// 检查这个页面是否有一个文档
blog = db.views.findOne({url : "/blog"})
// 如果有,就将访问次数加1并进行保存
if (blog) {
blog.pageviews++;
db.views.save(blog);
}
// 否则,为这个页面创建一个新文档
else {
db.views.insertOne({url : "/blog", pageviews : 1})
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这意味着每次有人访问一个页面时,我们都要先对数据库进行查询,然后选择更新或者插入。如果在多个进程中运行这段代码,则还会遇到竞争条件,可能对一个给定的 URL 会有多个文档被插入。
可以使用 upsert 来消除竞争条件并减少代码量(updateOne 和 updateMany 的第三个参数是一个选项文档,使我们能够对其进行指定):
> db.views.updateOne({"url" : "/blog"}, {"$inc" : {"pageviews" : 1}}, {"upsert" : true})
- 1
以上代码的作用与前面代码块完全一样,但是更高效,并且是原子性的!新文档是以条件文档作为基础,并对其应用修饰符文档进行创建的。
如果执行一个与键匹配,并且对该键的值进行递增的 upsert 操作,则这个递增会应用于所匹配的文档:
> db.users.updateOne({"rep" : 25}, {"$inc" : {"rep" : 3}}, {"upsert" : true})
WriteResult({
"acknowledged" : true,
"matchedCount" : 0,
"modifiedCount" : 0,
"upsertedId" : ObjectId("5a93b07aaea1cb8780a4cf72")
})
> db.users.findOne({"_id" : ObjectId("5727b2a7223502483c7f3acd")} )
{ "_id" : ObjectId("5727b2a7223502483c7f3acd"), "rep" : 28 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
upsert 创建了一个 “rep” 值为 25 的新文档,然后将其递增 3,从而得到一个 “rep” 值为28 的文档。如果未指定 upsert 选项,则 {“rep” : 25} 不会匹配任何文档,因此什么都不会发生。
如果再次运行 upsert(使用条件 {“rep” : 25}),它将创建另一个新文档。这是因为条件与集合中唯一的一个文档不匹配(它的 “rep” 值是 28)
有时候需要在创建文档时对字段进行设置,但在后续更新时不对其进行更改。这就是"$setOnInsert" 的作用。“$setOnInsert” 是一个运算符,它只会在插入文档时设置字段的值。因此,可以像下面这样做:
> db.users.updateOne({}, {"$setOnInsert" : {"createdAt" : new Date()}},{"upsert" : true})
{
"acknowledged" : true,
"matchedCount" : 0,
"modifiedCount" : 0,
"upsertedId" : ObjectId("5727b4ac223502483c7f3ace")
}
> db.users.findOne()
{
"_id" : ObjectId("5727b4ac223502483c7f3ace"),
"createdAt" : ISODate("2016-05-02T20:12:28.640Z")
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
如果再次运行这个更新,就会匹配到这个已经存在的文档,所以不会再进行插入,“createdAt” 字段的值也不会被改变:
> db.users.updateOne({}, {"$setOnInsert" : {"createdAt" : new Date()}},{"upsert" : true})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 0 }
> db.users.findOne()
{
"_id" : ObjectId("5727b4ac223502483c7f3ace"),
"createdAt" : ISODate("2016-05-02T20:12:28.640Z")
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
注意,通常不需要保留 “createdAt” 这样的字段,因为 ObjectId 中包含了文档创建时的时间戳。不过,在预置或初始化计数器时,以及对于不使用 ObjectId 的集合来说,“$setOnInsert” 是非常有用的。
save 辅助函数
save 是一个 shell 函数,它可以在文档不存在时插入文档,在文档存在时更新文档。它只将一个文档作为其唯一的参数。如果文档中包含 “_id” 键,save 就会执行一个upsert。否则,将执行插入操作。save 实际上只是一个为了方便而使用的函数,程序员可以在 shell 中对文档进行快速更改:
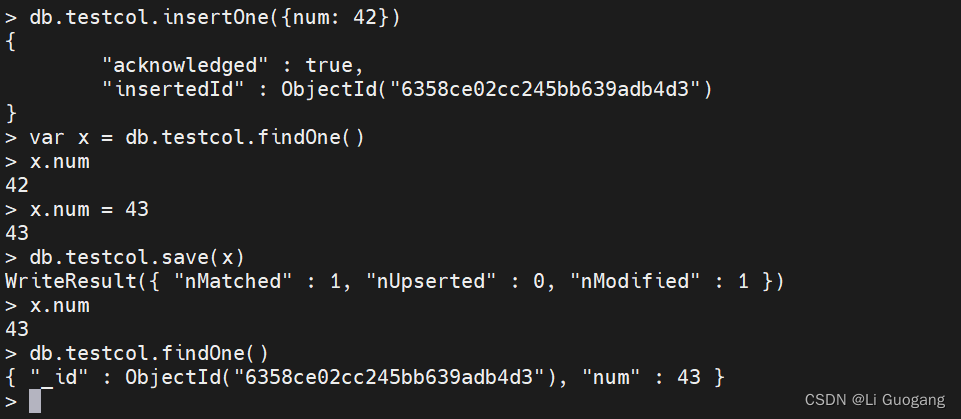
更新多个文档
updateOne 只会更新找到的与筛选条件匹配的第一个文档。如果匹配的文档有多个,它们将不会被更新。要修改与筛选器匹配的所有文档,请使用 updateMany。updateMany 遵循与 updateOne 同样的语义并接受相同的参数。关键的区别在于可能会被更改的文档数量。
updateMany 提供了一个强大的工具,用于执行模式迁移或向某些特定用户推出新功能。假设我们想给每个在某一天过生日的用户一份礼物,则可以使用 updateMany 向他们的账户添加一个 “gift” 字段,如下所示:
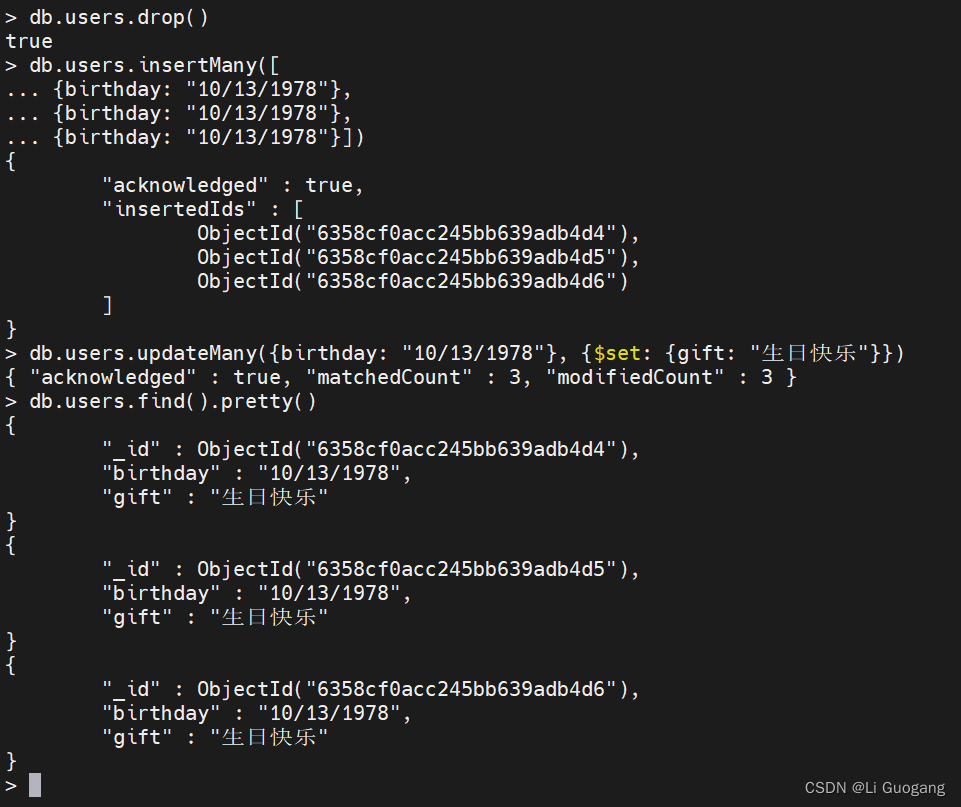
对 updateMany 的调用为之前插入 users 集合中的 3 个文档都添加了一个 “gift” 字段。
返回被更新的文档
在某些场景中,返回修改过的文档是很重要的。在 MongoDB 的早期版本中,findAndModify 是这种情况下的首选方法。它对于操作队列和执行其他需要取值、赋值的原子操作来说非常方便。不过,findAndModify 很容易出现用户错误,因为它非常复杂,结合了 3 种不同类型操作的功能:删除、替换和更新(包括 upsert)。
MongoDB 3.2 向 shell 中引入了 3 个新的集合方法来提供 findAndModify 的功能,但其语义更易于学习和记忆:findOneAndDelete、findOneAndReplace 和findOneAndUpdate。这些方法与 updateOne 之间的主要区别在于,它们可以原子地获取已修改文档的值。MongoDB 4.2 扩展了 findOneAndUpdate 以接受一个用来更新的聚合管道。管道可以包含以下阶段:$addFields 及其别名 s e t 、 set、 set、project 及其别名$unset,以及 $replaceRoot 及其别名 $replaceWith。
假设我们有一个集合,包含了以一定顺序运行的进程,其中每个进程都用如下形式的文档表示:
{
"_id" : ObjectId(),
"status" : "state",
"priority" : N
}
- 1
- 2
- 3
- 4
- 5
“status” 是一个字符串,其值可以是 “READY”、“RUNNING” 或 “DONE”。我们需要找到状态为 “READY” 的优先级最高的任务,运行相应的进程函数,然后将状态更新为"DONE"。可以尝试查询已经就绪的进程,按优先级排序,并将最高优先级进程的状态更新为 “RUNNING”。一旦处理完毕,就将状态更新为 “DONE”,如下所示:
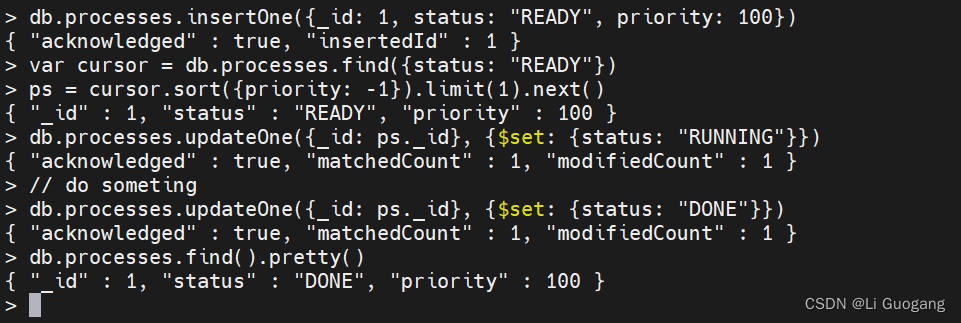
这个算法不太好,因为它可能会导致竞争条件。假设有两个线程在运行,如果一个线程(称为线程 A)读取了文档,而另一个线程(称为线程 B)在线程 A 将其状态更新为"RUNNING" 之前读取了同一个文档,则两个线程将运行同一个进程。虽然可以将结果作为更新查询的一部分进行检查以避免这种情况,但这会非常复杂。
var cursor = db.processes.find({"status" : "READY"}); cursor.sort({"priority" : -1}).limit(1); while (cursor.hasNext()) { let ps = cursor.next(); var result = db.processes.updateOne({"_id" : ps._id, "status" : "READY"}, {"$set" : {"status" : "RUNNING"}}); if (result.modifiedCount === 1) { // do something db.processes.updateOne({"_id" : ps._id}, {"$set" : {"status" : "DONE"}}); break; } cursor = db.processes.find({"status" : "READY"}); cursor.sort({"priority" : -1}).limit(1); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
另外,根据时间的不同,一个线程可能会完成所有的工作,另一个线程则毫无用处地一直在对其进行检查。线程 A 总是可以获取进程,然后线程 B 会尝试获取相同的进程,但其会失败,并让线程 A 完成所有工作。
这样的情况正是使用 findOneAndUpdate 的最佳时机。findOneAndUpdate 可以在一个操作中返回匹配的结果并进行更新。在本例中,处理过程如下:
> db.processes.findOneAndUpdate({"status" : "READY"}, {"$set" : {"status" : "RUNNING"}}, {"sort" : {"priority" : -1}})
{
"_id" : ObjectId("4b3e7a18005cab32be6291f7"),
"priority" : 1,
"status" : "READY"
}
- 1
- 2
- 3
- 4
- 5
- 6
注意,在返回的文档中,状态仍然是 “READY”,因为 findOneAndUpdate 方法默认返回文档修改之前的状态。如果将选项文档中的 “returnNewDocument” 字段设置为true,那么它将返回更新后的文档。选项文档是作为第三个参数被传入findOneAndUpdate 方法中的:
> db.processes.findOneAndUpdate({"status" : "READY"},
... {"$set" : {"status" : "RUNNING"}},
... {"sort" : {"priority" : -1},
... "returnNewDocument": true})
{
"_id" : ObjectId("4b3e7a18005cab32be6291f7"),
"priority" : 1,
"status" : "RUNNING"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这样的话,程序就变成了下面这样:
ps = db.processes.findOneAndUpdate({"status" : "READY"},
{"$set" : {"status" : "RUNNING"}},
{"sort" : {"priority" : -1},
"returnNewDocument": true})
// do something
db.process.updateOne({"_id" : ps._id}, {"$set" : {"status" : "DONE"}})
- 1
- 2
- 3
- 4
- 5
- 6
除此之外,还有另外两个方法需要注意。findOneAndReplace 方法会接受相同的参数,并根据 returnNewDocument 选项的值,返回替换之前或之后的文档。findOneAndDelete 方法与之类似,只是它不会接受更新文档作为参数,并且其拥有的选项也只是其他两个方法的一部分。findOneAndDelete 会返回被删除的文档。

