
- 1联邦学习FedAvg算法复现任务_fedavg复现
- 2OVF文件
- 3Centos7 mysql5.5升级为mysql5.7 非rpm 以 tar包的方式_mysql rpm升级到tar
- 4计算机网络层次划分及协议了解_协议与层次划分
- 5如何在无网的linux服务器上配置深度学习环境_在无网环境下给服务器配置环境
- 6htpp://bangbang.58.com/pc.html,new-website/package-lock.json at master · cdnjs/new-website · GitHub...
- 7java实现沙箱测试环境支付宝支付(demo)和整合微信支付和支付宝支付到springmvc+spring+mybatis环境全过程(支付宝和微信支付、附源码)...
- 8码云Gitee Clone仓库到本地失败(git did not exit cleanly(exit code 128))_本地无法clone gitea 仓库
- 9HarmonyOS-module.json5配置文件_device type in the module.json5/config.json file c
- 10实验四 交换机的Telnet远程登陆配置_交换机的telnet远程登陆配置心得体会
微服务流量治理之问题分析和解决方案_微服务入口流量治理
赞
踩
前言
1、当服务访问量达到一定程度,流量扛不住的时候,该如何处理?
2、服务之间相互依赖,当服务A出现响应时间过长,影响到服务B的响应,进而产生连锁反应,直至影响到整个依赖链上的所有服务,改如何处理?这是分布式、微服务开发不可以避免的问题。
一、分布式系统遇到的问题
在一个高度服务化的系统中,我们实现的一个业务逻辑通常会依赖多个服务,比如:商品详情展示服务会依赖商品服务、价格服务、商品评价服务。如图所示:
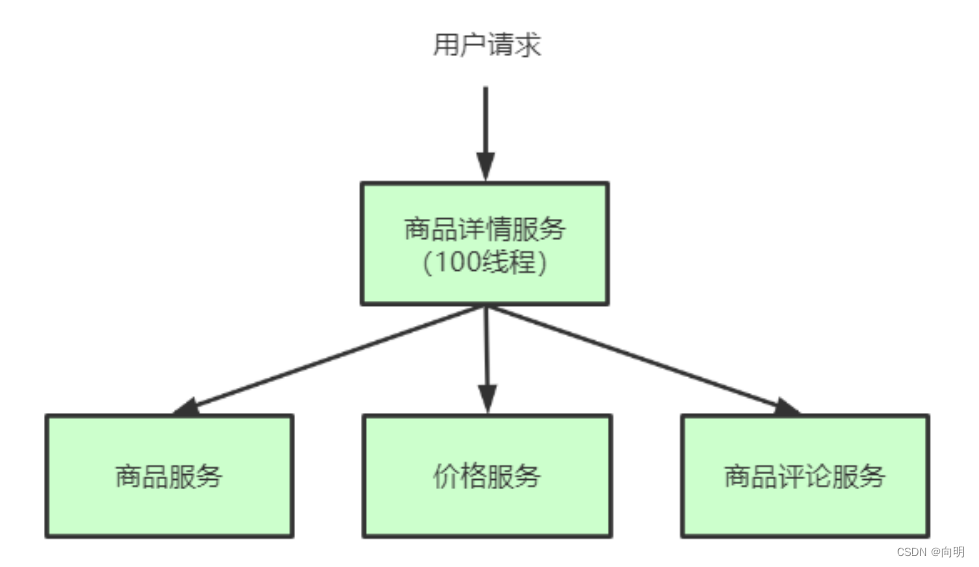
调用三个依赖服务会共享商品详情服务的线程池。如果其中的商品评论服务不可用,就回出现线程池里所有线程都因等待响应被阻塞,从而造成服务雪崩,如图所示:
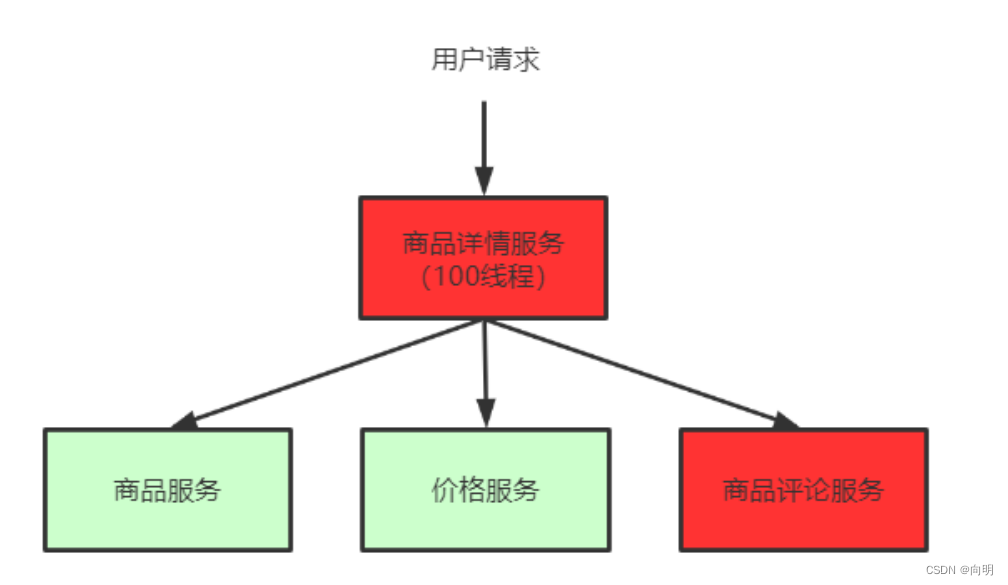
- 服务雪崩效应
因服务提供者的不可用导致服务调用者的不可用,并将不可用逐渐放大的过程,就叫服务雪崩效应
导致服务不可用的原因: 程序Bug,大流量请求,硬件故障,缓存击穿; - 大流量请求
在秒杀和大促开始前,如果准备不充分,瞬间大量请求会造成服务提供者的不可用; - 硬件故障
可能为硬件损坏造成的服务器主机宕机, 网络硬件故障造成的服务提供者的不可访问; - 缓存击穿
一般发生在缓存应用重启, 缓存失效时高并发,所有缓存被清空时,以及短时间内大量缓存失效时。 大量的缓存不命中, 使请求直击后端,造成服务提供者超负荷运行,引起服务不可用。
在服务提供者不可用的时候,会出现大量重试的情况:用户重试、代码逻辑重试,这些重试最终导致:进一步加大请求流量。所以归根结底导致雪崩效应的最根本原因是:大量请求线程同步等待造成的资源耗尽。当服务调用者使用同步调用时, 会产生大量的等待线程占用系统资源。一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态, 于是服务雪崩效应产生了。
二、解决方案
-
超时机制
在不做任何处理的情况下,服务提供者不可用会导致消费者请求线程强制等待,而造成系统资源耗尽。加入超时机制,一旦超时,就释放资源。由于释放资源速度较快,一定程度上可以抑制资源耗尽的问题。 -
服务限流【资源隔离】
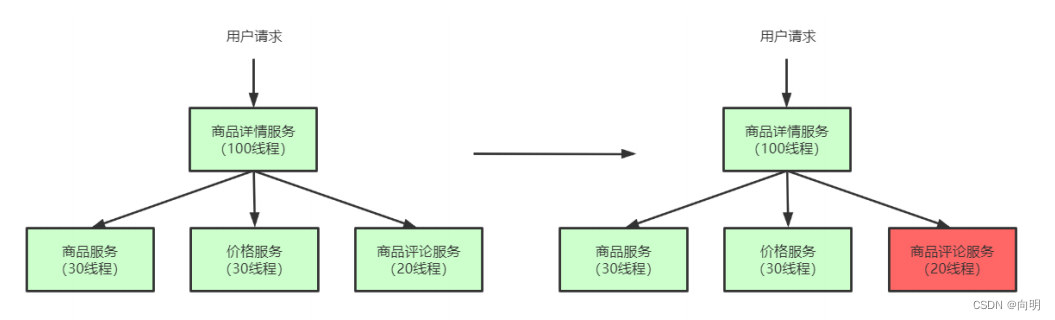
限制请求核心服务提供者的流量,使大流量拦截在核心服务之外,这样可以更好的保证核心服务提供者不出问题,对于一些出问题的服务可以限制流量访问,只分配固定线程资源访问,这样能使整体的资源不至于被出问题的服务耗尽,进而整个系统雪崩。那么服务之间怎么限流,怎么资源隔离?例如可以通过线程池+队列的方式,通过信号量的方式。
如下图所示, 当商品评论服务不可用时, 即使商品服务独立分配的20个线程全部处于同步等待状态,也不会影响其他依赖服务的调用。
-
服务熔断
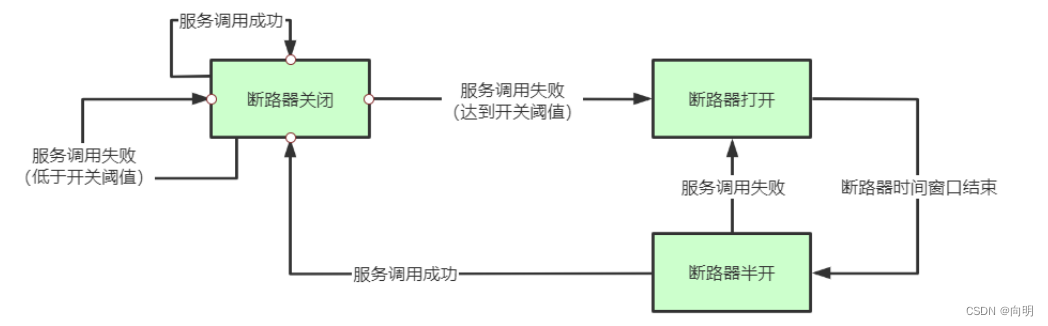
远程服务不稳定或网络抖动时暂时关闭,就叫服务熔断。
现实世界的断路器大家肯定都很了解,断路器实时监控电路的情况,如果发现电路电流异常,就会跳闸,从而防止电路被烧毁。软件世界的断路器可以这样理解:实时监测应用,如果发现在一定时间内失败次数/失败率达到一定阈值,就“跳闸”,断路器打开——此时,请求直接返回,而不去调用原本调用的逻辑。跳闸一段时间后(例如10秒),断路器会进入半开状态,这是一个瞬间态,此时允许一次请求调用该调的逻辑,如果成功,则断路器关闭,应用正常调用;如果调用依然不成功,断路器继续回到打开状态,过段时间再进入半开状态尝试——通过”跳闸“,应用可以保护自己,而且避免浪费资源;而通过半开的设计,可实现应用的“自我修复“。所以,同样的道理,当依赖的服务有大量超时时,在让新的请求去访问根本没有意义,只会无畏的消耗现有资源。比如我们设置了超时时间为1s,如果短时间内有大量请求在1s内都得不到响应,就意味着这个服务出现了异常,此时就没有必要再让其他的请求去访问这个依赖了,这个时候就应该使用断路器避免资源浪费。
-
服务降级
有服务熔断,必然要有服务降级。
所谓降级,就是当某个服务熔断之后,服务将不再被调用,此时客户端可以自己准备一个本地的fallback(回退)回调,返回一个缺省值。 例如:(备用接口/缓存/mock数据) 。这样做,虽然服务水平下降,但好歹可用,比直接挂掉要强,当然这也要
看适合的业务场景。

