- 1HarmonyOS鸿蒙学习笔记(4)Tabs模仿安卓ViewPager+Fragment的效果_harmony viewpager
- 2paging从使用到放弃,再到使用_pagingconfig pagingsource
- 3【免费】如何考取《鲸鸿动能广告初级优化师》认证(详细教程)
- 4Linux网络协议原理_linux、tcp/ip、http、dns等常用协议的传输原理
- 5AndroidStudio 4.1 阿里网盘下载_android studio 4.1. 下载
- 6【笔记】微信小程序组件swiper实现跑马灯(marquee)效果_swiper走马灯
- 7Android架构之Paging组件(一)_android paging
- 8AI读懂说话人情绪,语音情感识别数据等你Pick!_ai 语音情绪分类
- 9open,write,read函数总结_python 查看open 打开的文件数量
- 10vue中this.$router.push路由2种传参以及获取方法_vuethis.$router.push 接收参数
R语言怎么学_r语言head函数
赞
踩
R语言也是很火热的程序
在这里可以实现机器学习等
可以有效的进行数据处理 操作等
可以为有效的数据展示和分析典型较大的基础
---------------主要包含
R语言的数据预处理
数据特征提取
数据分类的工作
------------------
需要不断的进行更新
一 预处理操作
使用在书系列网站上的churn数据集进行下列练习:
基本的字段包含:
State,Account Length,Area Code,Phone,Int'l Plan,VMail Plan,VMail Message,Day Mins,Day Calls,Day Charge,Eve Mins,Eve Calls,Eve Charge,Night Mins,Night Calls,Night Charge,Intl Mins,Intl Calls,Intl Charge,CustServ Calls,Churn?
洲、帐号长度、区号、电话、国际计划、虚拟邮件计划、虚拟邮件信息、日分钟、日呼叫、日收费、夜分钟、夜呼叫、夜收费、国际分钟、国际呼叫、国际收费、客户服务电话、用户
33问. 探究是否有任何变量缺少值。
- 因为原始数据中包含的大部分原始数据都是未经预处理、不完整且存在大量噪声的。
- 存在过时、冗余的字段
- 存在缺失值
- 存在异常值
- 数据格式不适合进行数据挖掘
- 数据不符合政策或者常识
- 因此,在进行数据挖掘之前需要进行数据清洗
- sum(is.na(*))的指令可以查看是否存在缺失的变量,在R中,缺失值通常以"NA"表示,判断数据是否存在缺失值,通常使用函数is.na(),该函数是判断缺失值的最基本函数,可用于判断不同的数据对象,比如向量,列表和数据框。如果存在缺失值,返回TRUE,反正为FALSE。
- complete.cases()是某一行是否存在缺失值的代码
- is.na()判断数据集中是否存在缺失值,sum()函数将缺失值个数求和。complete.cases()函数也可以判断数据集的缺失值。与is.na()不同。该函数判断数据集的每一行中是否有缺失值,如果不存在反回TRUE,存在返回FALSE。sum()函数对complete.cases()函数输出结果中的FALSE求和。
- 当然除了老师讲述的内容,也可以利用函数summary()来判断数据集中分类变量是否含有缺失值。
- 常用的基础知识如下:
- R语言 head ()用法及代码示例 R 语言中的 head () 函数用于获取向量、矩阵、表、 DataFrame 或函数的第一部分。Dim代表获得向量的大小。tail () 函数用于获取向量、矩阵、表、 DataFrame 或函数的最后部分
- 在数据处理时,异常值的处理方法,需视具体情况而定。有时,异常值也可能是正常的值,只不过异常的大或小,所以,很多情况下,要先分析异常值出现的可能原因,再判断如何处理异常值。
- 处理的异常值的常用方法有:
- 删除含有异常值的记录;
- 插补,把异常值视为缺失值,使用缺失值的处理方法进行处理,好处是利用现有数据对异常值进行替换,或插补;
- 不处理,直接在含有异常值的数据集上进行数据分析;
34问. 比较区域代码和州字段。讨论任何明显的异常情况。
也可以结合利用函数summary()来判断数据集中分类变量是否含有缺失值和有关的情况,需要通过查看网站State Area Codes (50states.com)的具体情况,把相关的州和对应的地区区域代码查看是否有问题。
图2-34-1 代表的是州对应的代码对应的映射表
408对应的:Rock, Burbank, Cambrian Park, Campbell, Cupertino, East Foothills, Fruitdale, Gilroy, Lexington Hills, Los Gatos, Milpitas, Monte Sereno, Morgan Hill, Palo Alto, San Jose, San Martin, Santa Clara, Saratoga, Sunnyvale
415对应的:Alto, Belvedere, Black Point-Green Point, Bolinas, Brisbane, Corte Madera, Daly City, Fairfax, Inverness, Kentfield, Lagunitas-Forest Knolls, Larkspur, Lucas Valley-Marinwood, Marin City, Mill Valley, Muir Beach, Nicasio, Novato, Point Reyes Station, Ross, San Anselmo, San Francisco, San Geronimo, San Rafael, Santa Venetia, Sausalito, Sleepy Hollow, Stinson Beach, Strawberry, Tamalpais-Homestead Valley, Tiburon, Woodacre
510对应的:Alameda, Albany, Ashland, Bayview, Berkeley, Castro Valley, Cherryland, Crockett, East Richmond Heights, El Cerrito, El Sobrante, Emeryville, Fairview, Fremont, Hayward, Hercules, Kensington, Montalvin Manor, Newark, North Richmond, Oakland, Piedmont, Pinole, Port Costa, Richmond, Rodeo, Rollingwood, San Leandro, San Lorenzo, San Pablo, Sunol, Tara Hills, Union City
35问. 用图表直观地判断在乘客服务电话数量上是否有异常值。
可以通过图找一些离散点,参考老师给的讲义和资料。
从图中画出图,包含不限于曲线图和直方图的形式。主要的方法案例如下:
hist(churn$CustServ.Calls,breaks=30)#,xlim=c(0,5000))
plot(churn$CustServ.Calls,main='CustServ.Call',
ylab="CustServ.Calls",col=rainbow(2))
plot(churn$Day.Mins,churn$CustServ.Calls,main='CustServ.Call',
ylab="CustServ.Calls",col=rainbow(1))
36问. 确定属于异常值的客户服务电话范围,使用以下方法:
- Z-score法;b. IQR方法。
- 除此之外,检测离断点的方法,通常有Z-score 和 IQR。
- 1,Z-score方法
- 在介绍Z-score方法之前,先了解一下 3∂原则,
- 3σ原则
如果数据服从正态分布,在3σ原则下,异常值被定义为一组测定值中与平均值的偏差超过三倍标准差的值。在正态分布下,距离平均值3σ之外的值出现的概率为 P(|x-μ|>3σ)<=0.003,属于极个别的小概率事件。
如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。 - 这个原则有个前提条件:数据需要服从正态分布。
- 在3∂原则下,如果观测值与平均值的差值超过3倍标准差,那么可以将其视为异常值。正负3∂的概率是99.7%,那么距离平均值3∂之外的值出现的概率为P(|x-u| > 3∂) <= 0.003,属于极个别的小概率事件。
- 如果数据不服从正态分布,那么可以用远离平均值的多少倍标准差来描述,倍数就是Z-score。Z-score以标准差为单位去度量某一原始分数偏离平均数的距离,它回答了一个问题:"一个给定分数距离平均数多少个标准差?",Z-score的公式是:
- Z-score = (Observation — Mean)/Standard Deviation
z = (X — μ) / σ - Z-score需要根据经验和实际情况来决定,通常把远离标准差3倍距离以上的数据点视为离群点,也就是说,把Z-score大于3的数据点视作离群点
- IQR方法
- 四分位点内距(Inter-Quartile Range,IQR),是指在第75个百分点与第25个百分点的差值,或者说,上、下四分位数之间的差,计算IQR的公式是:
- IQR = Q3 − Q1
- IQR是统计分散程度的一个度量,分散程度通过需要借助箱线图来观察,通常把小于 Q1 - 1.5 * IQR 或者大于 Q3 + 1.5 * IQR的数据点视作离群点,探测离群点的公式是:
- outliers = value < ( Q1 - 1.5 * IQR ) or value > ( Q3 + 1.5 * IQR )
- 这种探测离群点的方法,是箱线图默认的方法,箱线图提供了识别异常值/离群点的一个标准:
- 异常值通常被定义为小于 QL - l.5 IQR 或者 大于 Qu + 1.5 IQR的值,QL称为下四分位数, Qu称为上四分位数,IQR称为四分位数间距,是Qu上四分位数和QL下四分位数之差,其间包括了全部观察值的一半。
- 箱线图的各个组成部分的名称及其位置如下图所示:
-
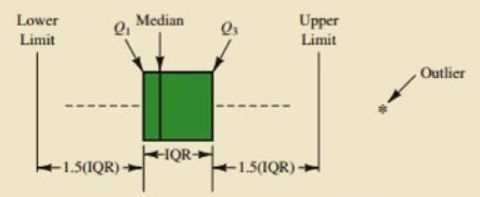
- 图2-36 箱图的示意图
- 箱线图可以直观地看出数据集的以下重要特性:
- 中心位置:中位数所在的位置就是数据集的中心,从中心位置向上或向下看,可以看出数据的倾斜程度。
- 散布程度:箱线图分为多个区间,区间较短时,表示落在该区间的点较集中;
- 对称性:如果中位数位于箱子的中间位置,那么数据分布较为对称;如果极值离中位数的距离较大,那么表示数据分布倾斜。
- 离群点:离群点分布在箱线图的上下边缘之外。
37问.使用z分数标准化来转换当天的分钟数。
根据课件的标准化方案来做
38问 工作与偏斜度如下:
a.计算日分钟的偏度
b.然后计算Z-score标准化日分钟的偏度。发表评论。
c.根据偏度值,你认为日分钟是偏还是接近完美对称的吗?
主要根据相关的ppt内容完善和编程实现
39问. 构建日分钟的正态概率图。对数据的正常性进行评论。
得到概率分布函数,主要采取的一些公式如下:
s =churn_min #产生样本
d <- density(s)
plot(d, col="green", ylim=c(0, 0.15))
dim(s)
参考的案例如下,其代表了如何进行正态分布的作图
函数density()估计核密度。 下面的程序作直方图, 并添加核密度曲线:
tmp.dens <- density(x)
hist(x, freq=FALSE,
ylim=c(0,max(tmp.dens$y)),
col=rainbow(15),
main='正态随机数',
xlab='', ylab='频数')
lines(tmp.dens, lwd=2, col='blue')
40问完成如下工作:
a.构建国际分钟的正态概率图。
b.是什么阻止了这个变量服从正态分布。
c.构造一个标志变量来处理(b)中的情况。
d.构造导出正态概率图。对派生变量的正规性进行评价。
根据正态分布的特点,找到不属于正态分布的数据,构造新的数据,得到分布函数即可
41问.使用Z-score标准化转换夜间分钟属性。使用一个图。描述标准化值的范围。
根据标准化的公式,然后找到summary的数值,得到标准化的最大和最小值。
33问. 探究是否有任何变量缺少值。
方法1 采取sum(is.na)的方法
图3-1 sum(is(na)的总结
方法2 采取summary的方法
图3-2 summuary的总结
通过summuary的总结,暂时没有发现有异常数值
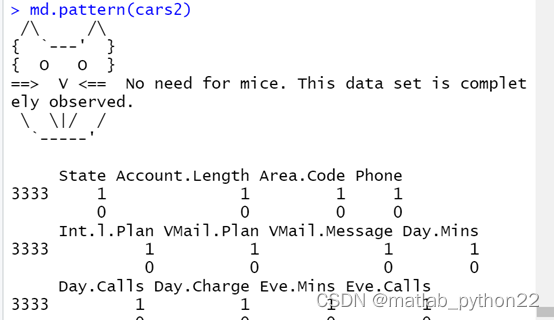
方法3:通过mice的方法检测
library(mice)
md.pattern(cars2)
print('zuoye')