- 1视频监控平台 liveweb国标gb28181视频融合监控汇聚云平台的方案实现及场景应用_liveweb下载
- 2解决问题:RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB
- 3java 工具类Base64工具_java base64util
- 4个人拥有云服务器能做什么?近20种主要用途介绍_云服务器能干什么
- 5windows下安装Docker,点击docker desktop后一直转圈圈,提示:docker is starting_docker desktop一直转圈
- 6Python面试题整理-牛客网_关于python内存管理错误的说法
- 7史上最详细的Windows10系统离线安装.NET Framework 3.5的方法(附离线安装包下载)_net framework 3.5离线安装
- 8Mysql的redolog和binlog_redlog
- 9Android Studio 最新版本首次下载和安装以及汉化教程【+第二次安装使用教程】_android studio下载
- 10css 实现丰富的序号效果_css 序号样式
【MySQL】表的增删改查——MySQL基本查询、数据库表的创建、表的读取、表的更新、表的删除_任务描述 创建好了数据表过后就该向里面添加数据了。本关你将: 学会对数据库表进
赞
踩
MySQL

表的增删查改
CURD是一个数据库技术中的缩写词,它代表Create(创建),Retrieve(读取),Update(更新),Delete(删除)操作。这四个基本操作是数据库管理的基础,用于处理数据的基本原子操作。
1. Create(创建)
在MySQL中,Create操作是十分重要的,它帮助用于创建数据库对象,如数据库、表、索引等并且允许用户定义新的数据结构和存储方式。我们常使用create databases [库名]; 创建数据库,create table [表名]; 创建数据表,insert into [表名] values(数据); 创建单条数据。
1.1 单行插入
insert 语句在 MySQL 中用于向数据库表中插入新的记录。
insert into 表名 (列1, 列2, 列3, ...)
values(值1, 值2, 值3, ...);
- 1
- 2
如果你想要为表中的每一列都插入值(即列的顺序与表中的定义一致),我们直接省略列名:
insert into 表名
values(值1, 值2, 值3, ...);
- 1
- 2
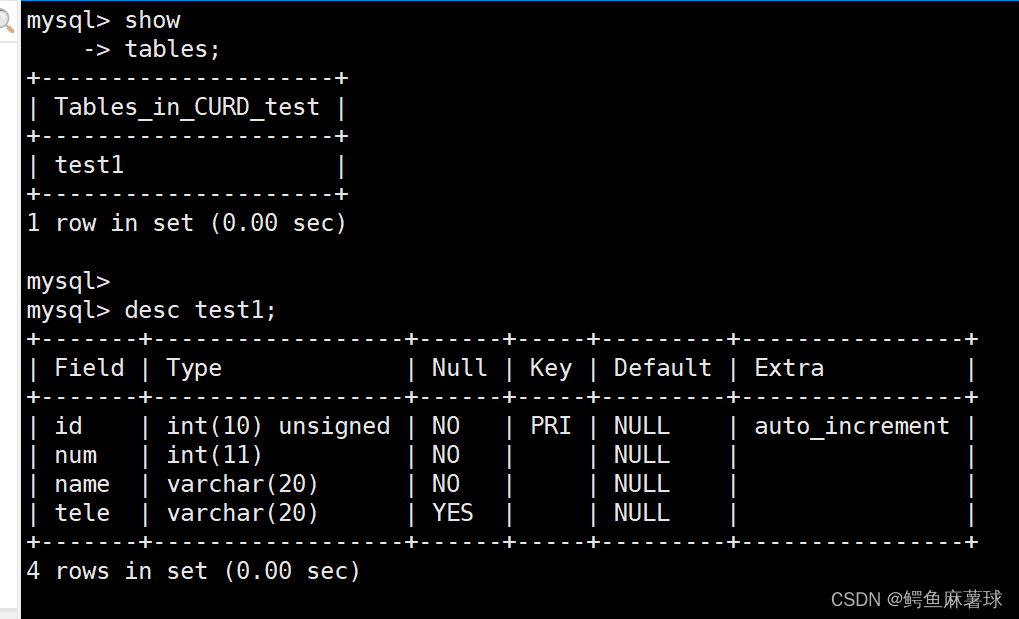
创建一张学生数据表,包括学号,姓名,电话等基本信息:
mysql> create table test1(
-> id int unsigned primary key auto_increment,
-> num int not null,
-> name varchar(20) not null,
-> tele varchar(20)
-> );
- 1
- 2
- 3
- 4
- 5
- 6
对于上面的表中,id代表学号,每一个学生有且只有唯一的一个,所以我们设计为主键,同时设置为自增长,下面的num和name设置为不为空类型。
查看表的结构:
desc test1;
- 1
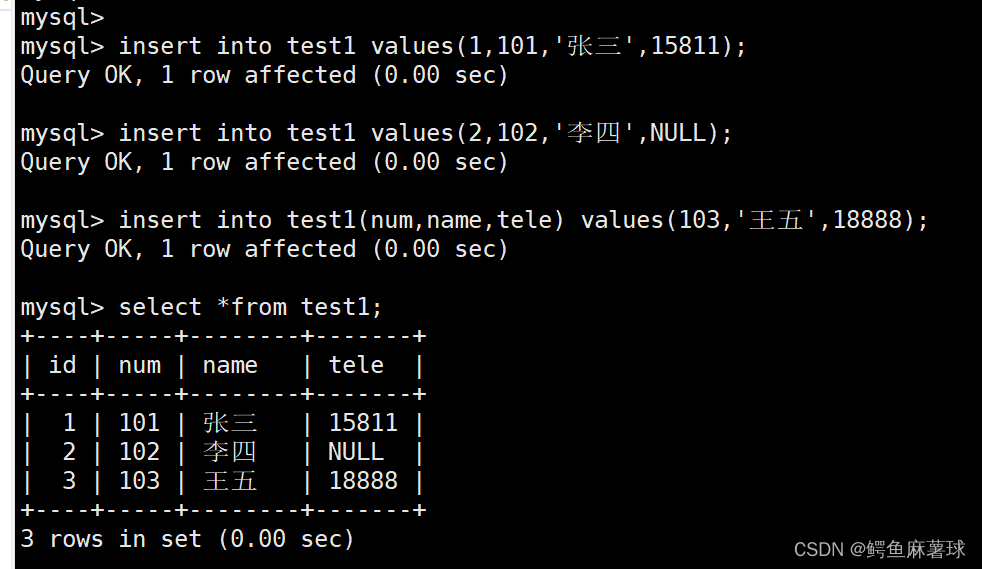
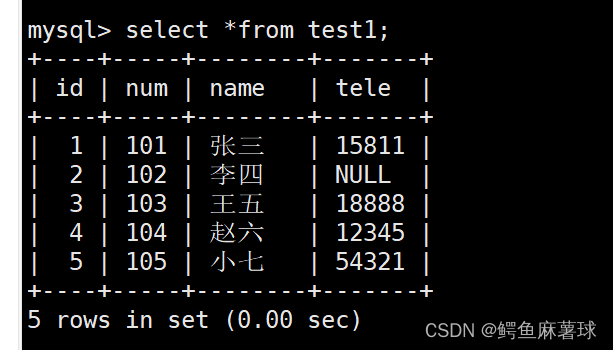
连续插入三个单条数据并且打印查看:
mysql> insert into test1 values(1,101,'张三',15811);
mysql> insert into test1 values(2,102,'李四',NULL);
mysql> insert into test1(num,name,tele) values(103,'王五',18888);
- 1
- 2
- 3
select * from test1;
- 1
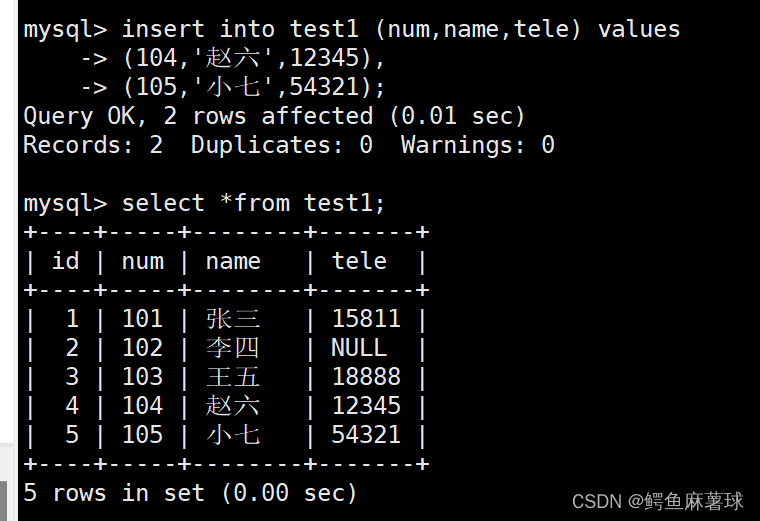
1.2 多行插入
insert语句可以一次性插入多行数据。通常我们只需要在values子句中列出多组值来实现的,每组值之间用逗号分隔。
insert多行插入并且打印:
mysql> insert into test1 (num,name,tele) values
-> (104,'赵六',12345),
-> (105,'小七',54321);
- 1
- 2
- 3
select *from test1;
- 1
确保我们插入的数据和列的数据匹配,如果列中not null,我们需要提供值,除非有默认值,我们要注意由于插入的数据是否会因为主键或者唯一键对应的值已经存在而导致插入失败。
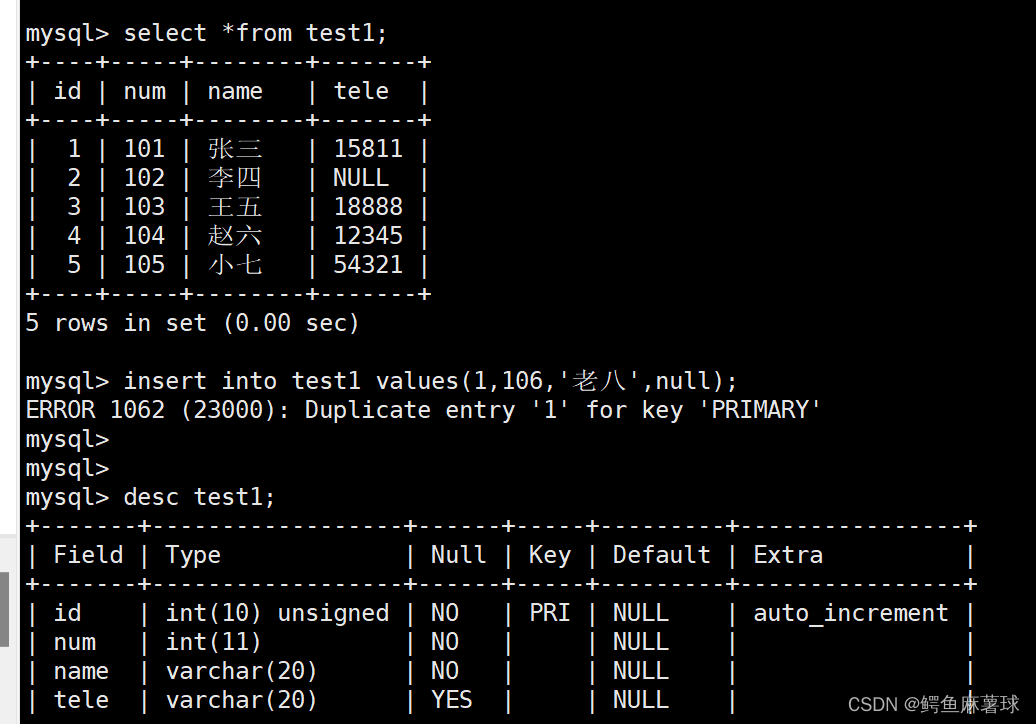
对应主键已经有唯一值导致插入失败:
mysql> insert into test1 values(1,106,'老八',null);
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
- 1
- 2
1.3 替换
replace 语句在 SQL 中是一个特殊的语句,它结合了 insert 和 update 的功能。既可以插入数据也可以替换数据。
插入数据:如果 replace 语句中指定的数据在表中不存在,它会执行一个插入操作,将数据添加到表中。
替换数据:如果数据已经存在于表中(通常是因为主键或唯一键冲突),replace 语句会先删除原有的数据行,然后插入新的数据行。
replace into 表名 (列1, 列2, 列3, ...)
values(值1, 值2, 值3, ...);
- 1
- 2
总而言之:主键或者唯一键没有冲突,则直接插入;主键或者唯一键如果冲突,则删除后再插入。
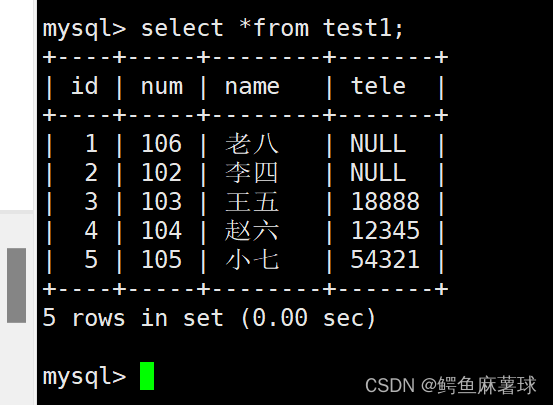
替换原有的主键数据并插入新的数据:
mysql> replace into test1 values(1,106,'老八',null);
- 1

2. Retrieve(读取)
Retrieve操作在数据库应用中主要用于从数据窗口或数据存储(Datastore)中检索数据。常用的有select进行数据的显示,或者其他如where等进行数据的筛选。
2.1 select查看
SELECT是SQL语言中的一个核心命令,用于从数据库表中检索数据。
[distinct]{* | {column[,column]...}
[from table_name]
[where...]
[order BY column[ASC|DESC],...]
limit...
- 1
- 2
- 3
- 4
- 5
distinct:这个关键字用于去重。
* 或 {column[,column]…}:这部分指定了要检索的列。* 表示选择所有列,而 {column[,column]…} 则允许您指定一个或多个列名。
from table_name:这部分指定了要从哪个表中检索数据。
where…:这是一个可选的子句,用于过滤结果集,只返回满足指定条件的行。
order BY column[ASC|DESC],…:这部分用于对结果集进行排序。 您可以指定一个或多个列,以及排序的方向(升序 ASC 或降序 DESC)。
limit…:这个子句用于限制返回的记录数。 它通常与分页查询一起使用。
创建学生成绩表:
mysql> create table test2(
-> id int unsigned primary key auto_increment,
-> name varchar(20) not null,
-> chinese float default 0.0 comment '语文成绩',
-> math float default 0.0 comment '数学成绩',
-> english float default 0.0 comment '英语成绩'
-> );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
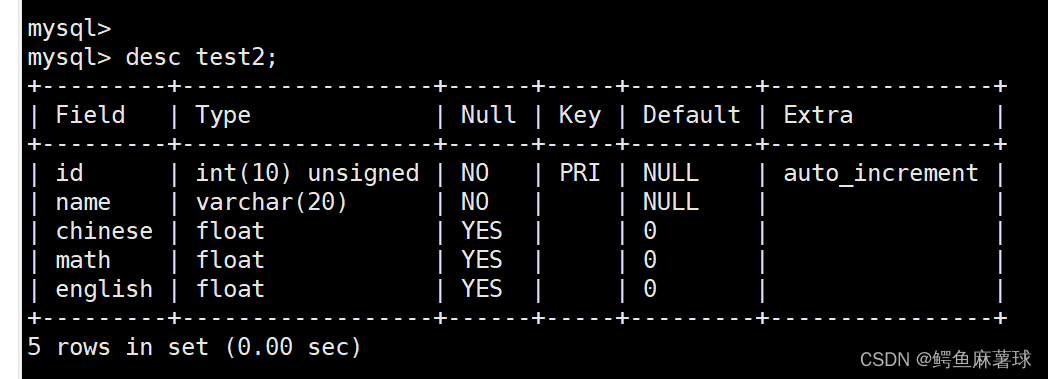
查看表结构:
desc test2;
- 1
向表中插入数据并且打印:
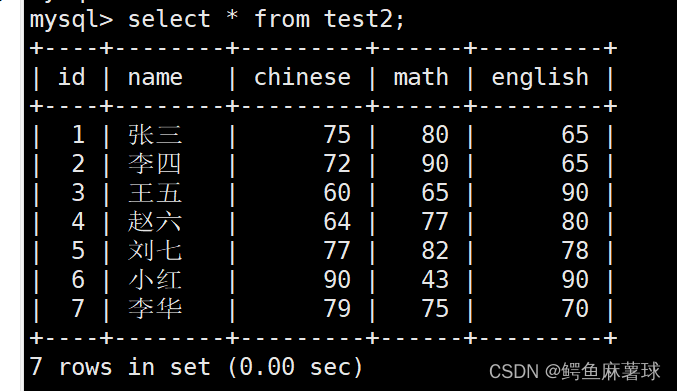
mysql> insert into test2(name,chinese,math,english) values
-> ('张三',70,80,59),
-> ('李四',72,90,65),
-> ('王五',60,65,90),
-> ('赵六',64,77,80),
-> ('刘七',77,82,78),
-> ('小红',90,43,90),
-> ('李华',79,75,52);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
通常情况下不建议使用 * 进行全列查询,查询的列越多,意味着需要传输的数据量越大;可能会影响到索引的使用。
select * from test2;
- 1
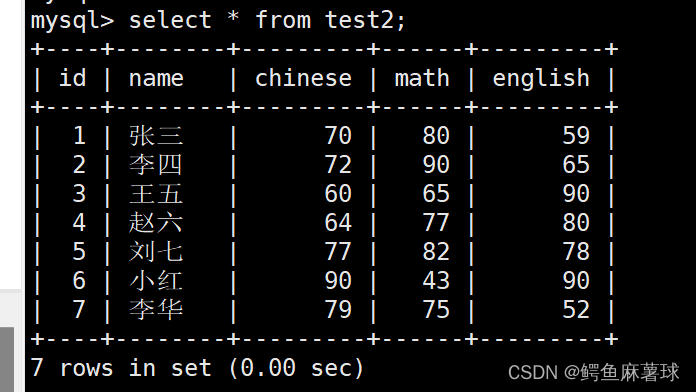
指定列打印信息(id,name,chinese):
select id,name,chinese from test2;
- 1

打印的字段可以是一个表达式:
select id,name,chinese+math+english from test2;
- 1
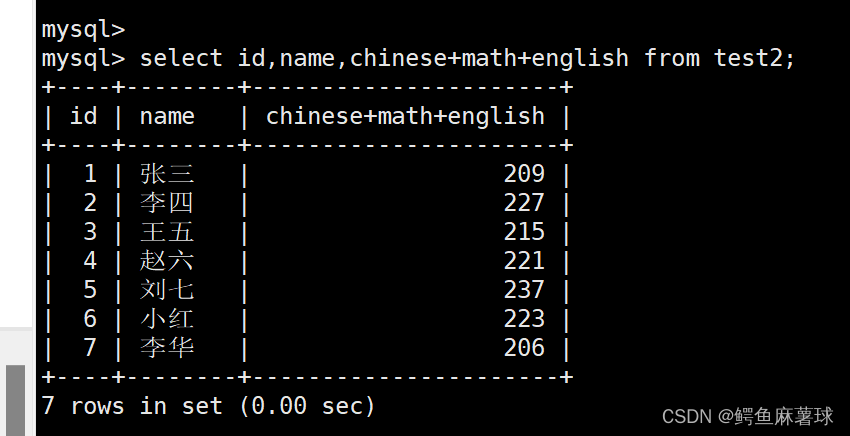
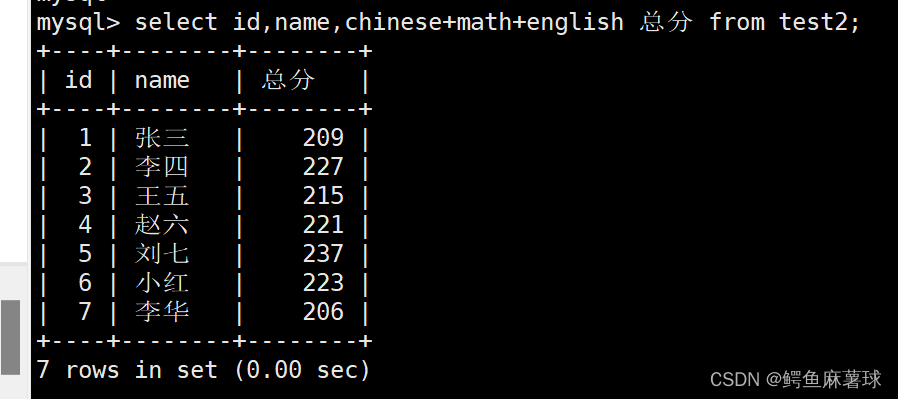
给打印字段的表达式重新命名:
select id,name,chinese+math+english 总分 from test2;
- 1
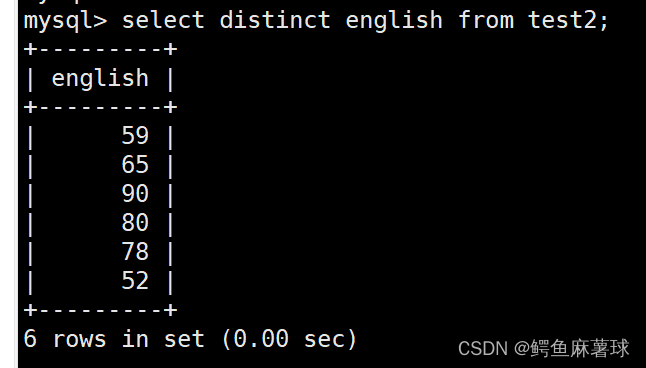
将打印出来的英文成绩去重:
select distinct english from test2;
- 1
2.2 where条件
在MySQL的select语句中,where子句用于指定查询条件,只有满足这些条件的记录才会出现在结果集中。where子句的主要目的是从数据表或查询结果中过滤出符合条件的行。
where子句后面可以跟随一个或多个条件,这些条件可以是算术表达式、逻辑表达式或比较运算符的组合。
比较运算符:
| 运算符 | 说明 |
|---|---|
| <,<=, >, >= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| between a0 and a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| in (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
| is null | 是 NULL |
| is not null | 不是 NULL |
| like | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| and | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| or | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| not | 条件为 TRUE(1),结果为 FALSE(0) |
输出所有英语成绩小于60分的信息:
select name,english from test2 where english<60;
- 1
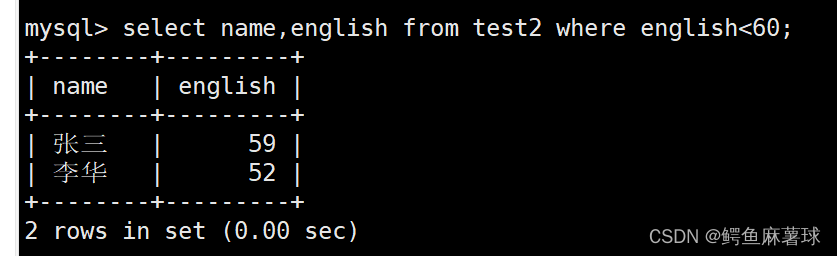
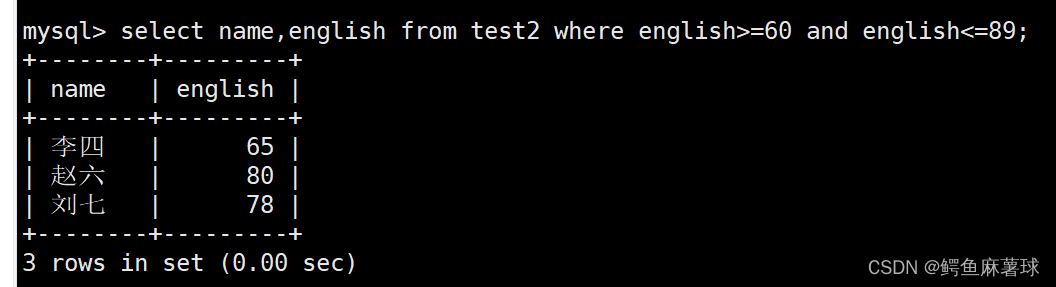
输出所有英语成绩大于等于60小于等于89的成绩:
select name,english from test2 where english>=60 and english<=89;
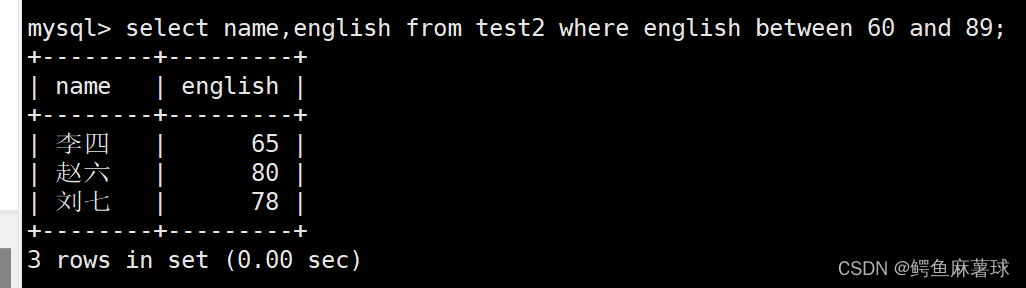
- 1
select name,english from test2 where english between 60 and 89;
- 1
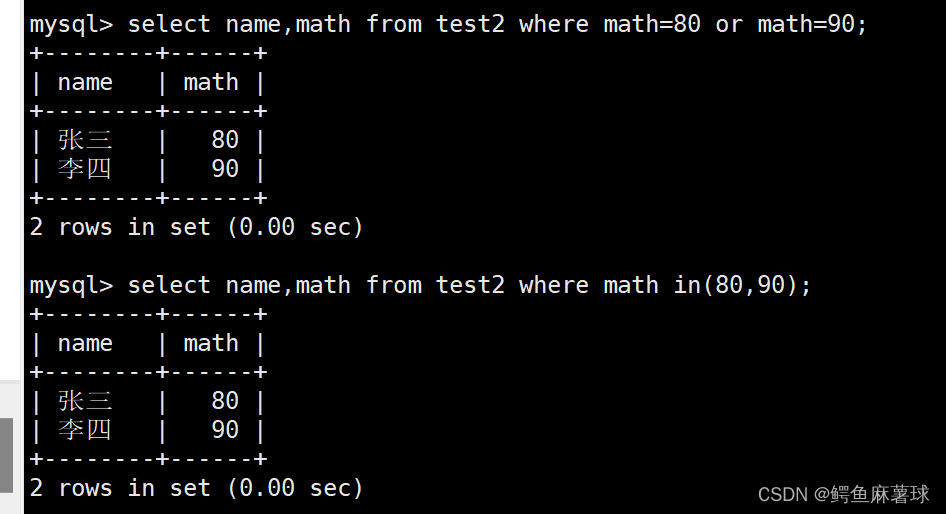
输出数学成绩为80或90分的信息:
select name,math from test2 where math=80 or math=90;
- 1
select name,math from test2 where math in(80,90);
- 1
找到所有的姓张的信息:
% 匹配任意多个(包括 0 个)任意字符,_ 匹配严格的一个任意字符。
select name,math from test2 where name like '张%';
- 1
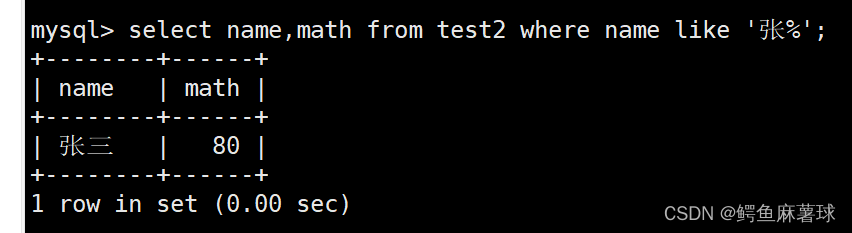
找叫 张、张X、张XX 的人员信息,
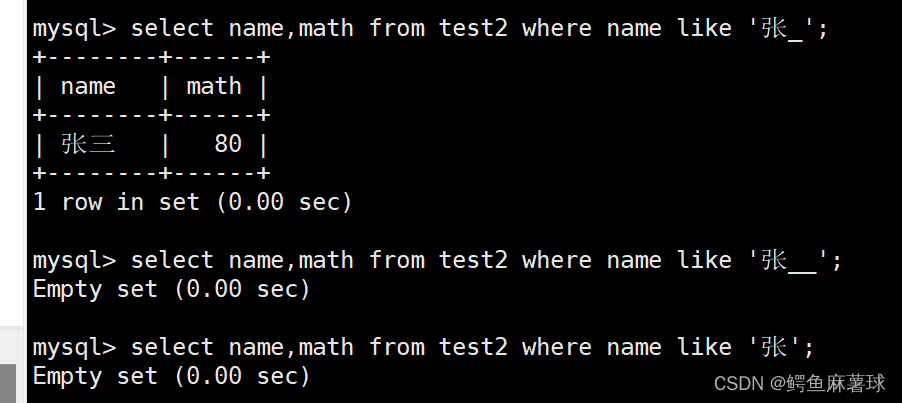
select name,math from test2 where name like '张';
- 1
select name,math from test2 where name like '张_';
- 1
select name,math from test2 where name like '张__';
- 1
找到所有总分小于210分的人员信息:
select name,math+chinese+english 总分
from test2
where chinese+math+english<210;
- 1
- 2
- 3

2.3 结果排序
结果排序通常使用SQL中的order by子句来实现,它允许用户指定一个或多个列作为排序依据,并可以选择升序(ASC)或降序(DESC)排序。
asc 为升序(从小到大)
desc 为降序(从大到小)
//默认为 ASC
select ... from table_name [where ...]
order by column [asc|desc], [...];
- 1
- 2
- 3
- 4
- 5
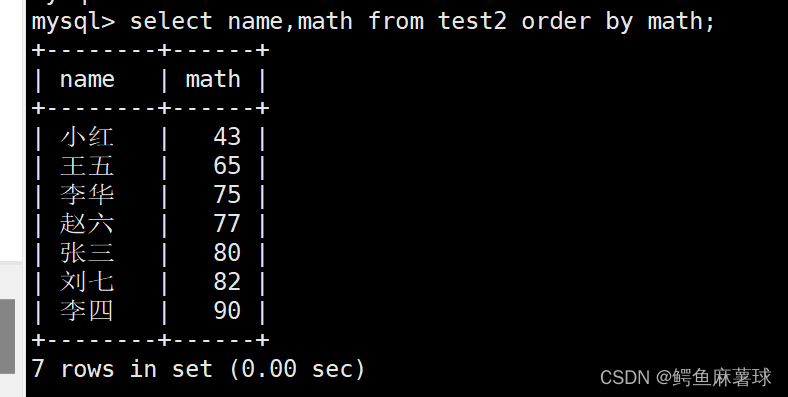
按照数学成绩的升序进行排序:
select name,math from test2 order by math;
- 1
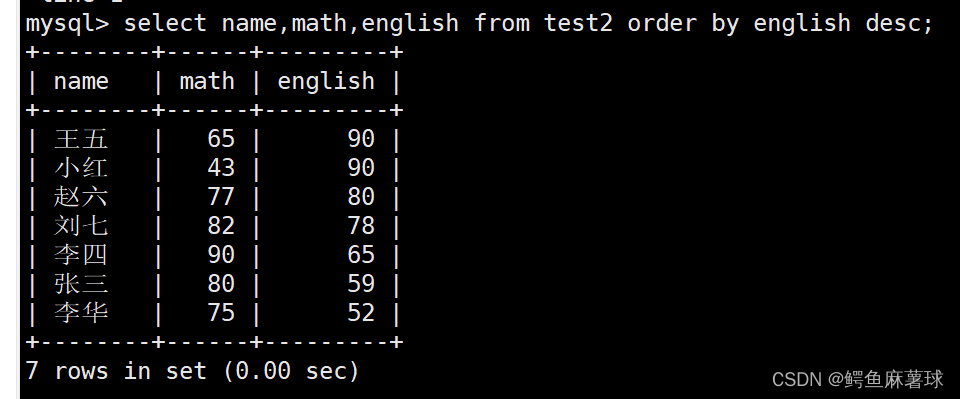
按照英语成绩的降序进行排序:
select name,math,english from test2 order by english desc
- 1
按照英语成绩的降序、数学成绩的升序进行排序:
select name,math,english from test2 order by english desc,math;
- 1
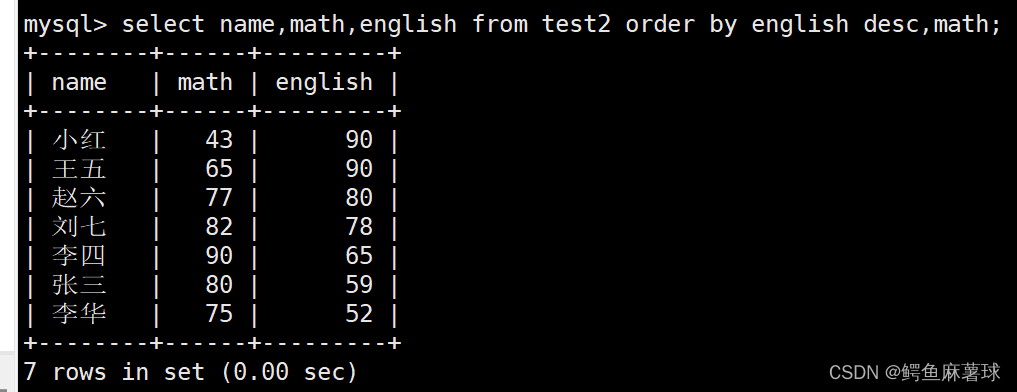
按照总分进行降序排序:
select name,chinese+english+math
from test2
order by chinese+english+math desc;
- 1
- 2
- 3
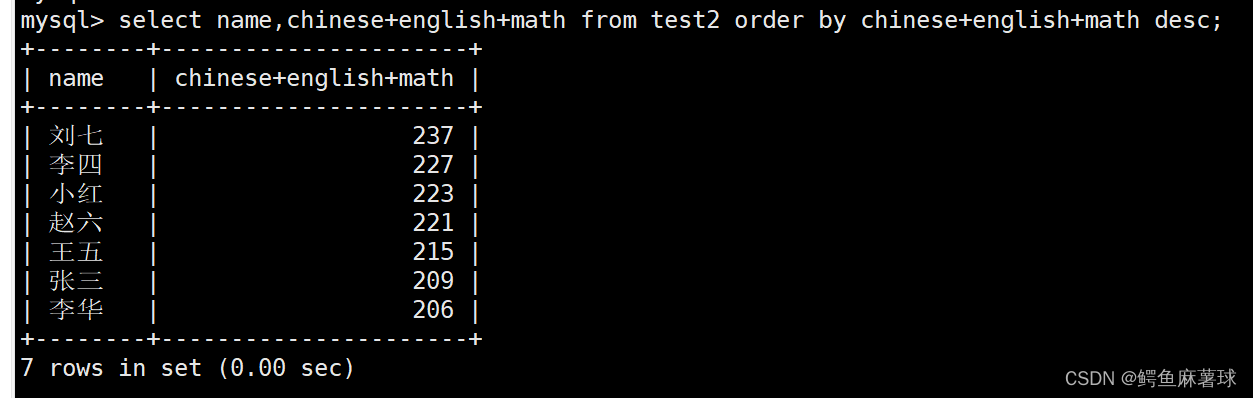
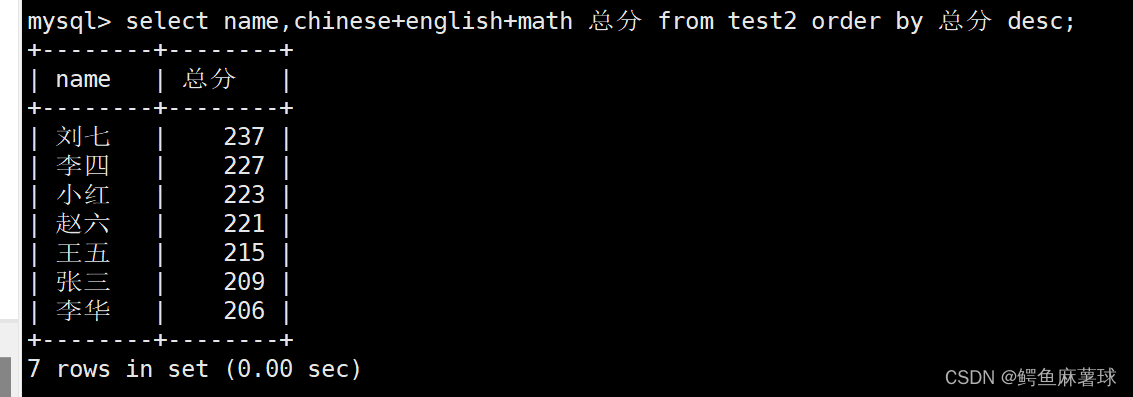
order by 子句中可以使用列别名:
select name,chinese+english+math 总分 from test2 order by 总分 desc;
- 1
2.4 筛选分页结果
MySQL对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死。
//起始下标为 0
//从 s 开始,筛选 n 条结果
select ... from table_name [where ...] [order by ...] limit s, n
//从 0 开始,筛选 n 条结果
select ... from table_name [where ...] [order by ...] limit n;
//从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
select ... from table_name [where ...] [order by ...] limit n offset s;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
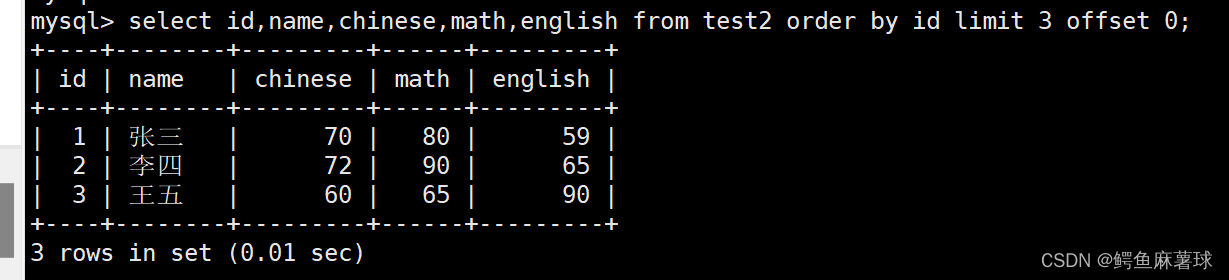
查看表中的信息从第0条数据开始,筛选3条数据:
select id,name,chinese,math,english
from test2
order by id
limit 3 offset 0;
- 1
- 2
- 3
- 4
3. Update(更新)
update是一个数据库SQL语法用语,主要用来更新表中原有的数据。
其基本的语法结构是:update 表名称 set 列名称 = 新值 where 列名称 = 某值。这意味着,当我们想要修改某个表中的特定数据时,可以使用update语句,并通过where子句来指定需要更新的行。
update table_name set column = expr [, column = expr ...]
[where ...] [order Bby ...] [limit ...]
- 1
- 2
3.1 更新单个数据
将李华的英语成绩更改为70:
select name,english from test2 where id=7;
- 1
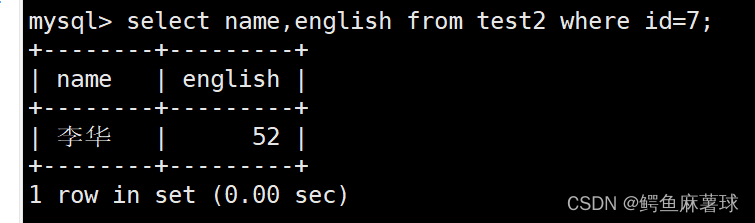
update test2 set english=70 where id=7;
- 1
select name,english from test2 where id=7;
- 1

3.2 更新多个数据
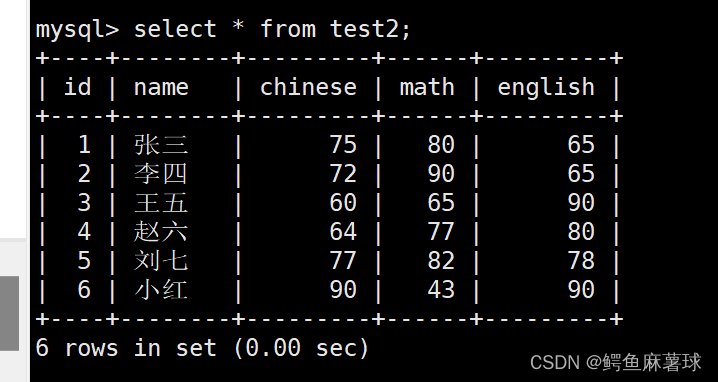
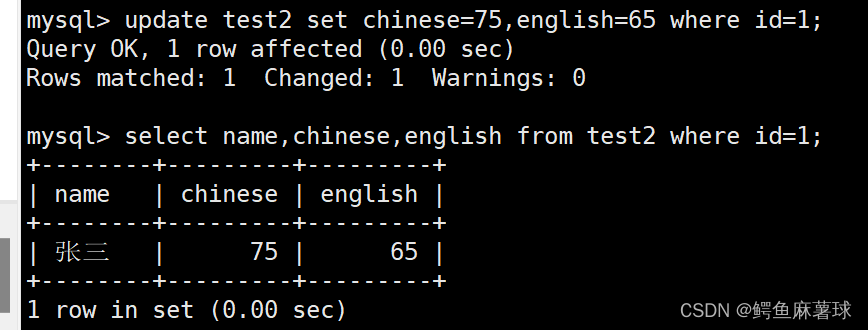
将张三的语文成绩更改为75,英语成绩更改为65:
select name,chinese,english from test2 where id=1;
- 1
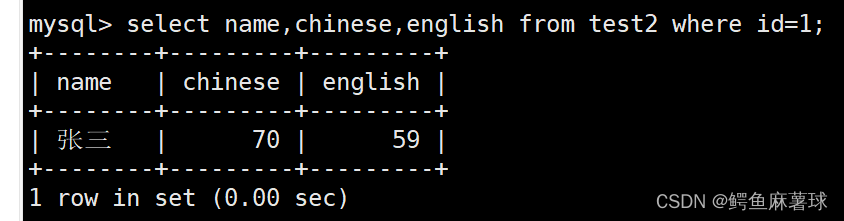
update test2 set chinese=75,english=65 where id=1;
- 1
select name,chinese,english from test2 where id=1;
- 1
4. Delete(删除)
DELETE操作是数据库中的一种重要操作,用于删除表中的记录。
delete from table_name [where ...] [order by ...] [limit ...]
- 1
删除李华的成绩信息:
delete from test2 where id=7 ;
- 1