- 1伺服电机(舵机)简单介绍_伺服舵机技术要求
- 2鸿蒙什么样?“微内核”篇_微内核rtos
- 31.网站页面及内容优化_网站页面内容优化
- 4MIUI13 无ROOT安装小黄鸟(HttpCanary)CA证书教程_安卓13无root安装小黄鸟证书
- 5tomcat执行shutdown报错Could not contact [localhost:8005] (base port [8005] and offset [0]). Tomcat may n
- 6【MySQL】5. 数据类型
- 7android学习三(Intent)_下面程序代码要实现以下功能:点击按钮,设置监听器从firstactivity跳转到secon
- 8【入门指南】2022年完整的 Python人工智能入门指南_learnpython
- 9JAVA如何在EXCEL中插入图片_java向excel写入图片
- 10python dpkt SSL 流tcp payload(从三次握手开始到application data)和证书提取
基于Tesseract模块Python实现提取图片中的文字信息(安装+使用教程)_tesseract python
赞
踩
Python实现提取图片中的文字可以使用Optical Character Recognition (OCR) 技术来解决。OCR是指将图像中的文本转换成可编辑的文本的过程。Python有许多OCR库,但最流行和最广泛使用的是Tesseract库。
下面是一个使用Python和Tesseract来提取图像中的文本的简单示例代码。
0. OCR技术介绍
OCR,即光学字符识别(Optical Character Recognition),是一种将印刷体字符转化为计算机可读文字的技术。OCR技术可以将纸质文档、扫描文档、照片等转化为可编辑的电子文件,方便用户进行编辑、存储和共享。
OCR技术的应用范围非常广泛。例如,银行和保险公司可以使用OCR技术来处理各种表格和文件,包括支票、发票、合同等,从而提高办公效率。医院可以使用OCR技术来处理病历、处方和医学报告,从而提高医疗质量和效率。政府机构可以使用OCR技术来处理各种表格和文件,例如税务申报表、选民登记表等,从而提高政府服务的效率和质量。
OCR技术的原理是利用光学扫描仪将纸质文档转化为数字图像,然后通过图像处理算法将图像中的字符识别出来,并转化为计算机可读的文字。OCR技术的核心是字符识别算法,这个算法需要考虑到各种字体、字号、字距、倾斜度、噪声等因素。
OCR技术的发展历史可以追溯到20世纪50年代,当时的OCR技术只能处理单一字体、字号、字距的文本。随着计算机技术的不断发展,OCR技术也不断进步,现在的OCR技术能够处理各种字体、字号、字距、倾斜度、噪声等复杂条件下的文本,并且具备高精度和高速度的特点。
总之,OCR技术是一种非常实用的技术,可以帮助用户将纸质文档转化为电子文件,从而提高办公效率和工作质量。随着计算机技术的不断进步,OCR技术也将不断发展,为用户提供更加高效和便捷的服务。
1. 安装模块
1、安装Tesseract、Tesseract、Pillow模块,可以使用以下命令:
pip install pytesseract
pip install pillow
pip install tesseract-ocr # 如果这个安装报错就用下面的手动安装方法
- 1
- 2
- 3
2、从网上找到相应的‘Tesseract-OCR’下载安装(自行寻找对应版本):https://digi.bib.uni-mannheim.de/tesseract/
3、无脑默认安装即可,安装后的默认文件路径为(这里使用的是Windows版本):C:\Program Files\Tesseract-OCR\
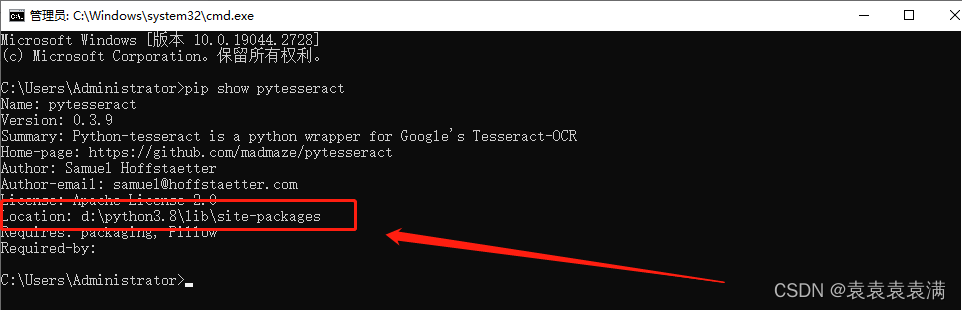
4、找到python的安装路径下的pytesseract,不知道在哪里的的在cmd控制执行:pip show pytesseract
例如我的就在D:\Python3.8\Lib\site-packages\pytesseract
5、进入上面的路径,打开pytesseract.py文件:
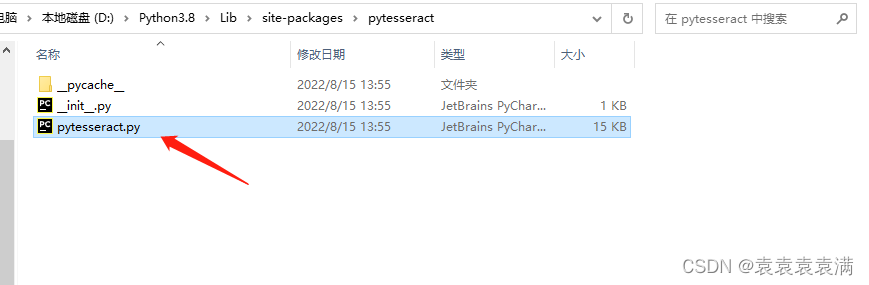
6、然后将源码中的tesseract_cmd = 'tesseract',更改为:
tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
- 1
2. 导包
然后,导入必要的库:
import cv2
import pytesseract
- 1
- 2
3. 读取图像
接下来,读取图像并将其转换为灰度:
img = cv2.imread('image.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
- 1
- 2
4. 提取字符串
然后调用pytesseract库的“image_to_string”函数,将图像转换为字符串:
text = pytesseract.image_to_string(gray)
- 1
5. 打印输出
print(text)
- 1
运行结果:
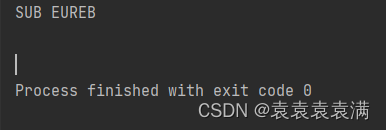
6. 完整代码
import cv2
import pytesseract
img = cv2.imread(r'image.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
text = pytesseract.image_to_string(gray)
print(text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
《100天精通Python》专栏推荐白嫖80g Python全栈视频
《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
- 优点:订阅限时9.9付费专栏进入千人全栈VIP答疑群,作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会)!
- 专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等