
说明:本篇以实践为主,理论部分会尽量给出参考链接
摘要:
1.分词
2.关键词提取
3.词的表示形式
4.主题模型(LDA/TWE)
5.几种常用的NLP工具简介
6.文本挖掘(文本分类,文本标签化)
6.1 数据预处理
6.2 关于文本的特征工程
6.3 关于文本的模型
7.NLP任务(词性标注,句法分析)
8.NLP应用(信息检索,情感分析,文章摘要,OCR,语音识别,图文描述,问答系统,知识图谱)
8.1 知识抽取
内容:
1.分词
分词是文本处理的第一步,词是语言的最基本单元,在后面的文本挖掘中无论是词袋表示还是词向量形式都是依赖于分词的,所以一个好的分词工具是非常重要的。
这里以python的jieba分词进行讲解分词的基本流程,在讲解之前还是想说一下jieba分词的整个工作流程:
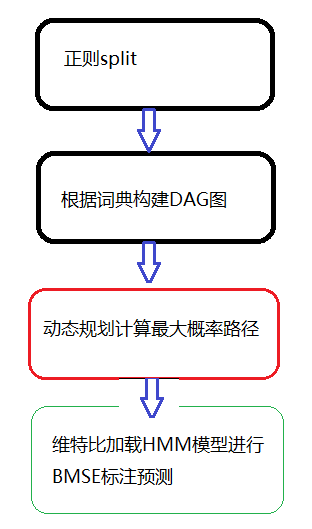
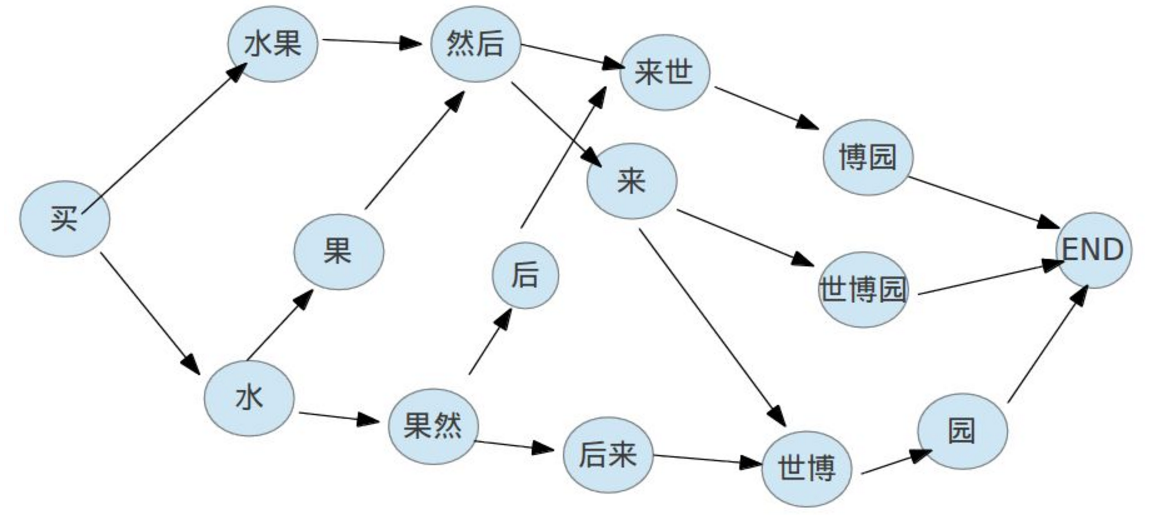
图1是jieba切词函数的4个可能过程,图2是一个根据DAG图计算最大概率路径,具体的代码走读请参考jieba cut源码
讲了这么多,我们还是要回归到实践中去,看下jieba的分词接口
1 # encoding=utf-8 2 import jieba 3 4 seg_list = jieba.cut("我来到北京清华大学", cut_all=True) 5 print("Full Mode: " + "/ ".join(seg_list)) # 全模式 9 10 seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式 11 print(", ".join(seg_list)) 12 13 seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式 14 print(", ".join(seg_list))
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学 【精确模式】: 他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了) 【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
其中全模式切词不会发生图1中的第3,4步,也不会发现新词,是一种完全依赖于词典的分词方式
精确模式是会全部计算最大概率路径和新词发现的。
我们都知道分词最重要的是字典,所以jieba也提供了若干方法对词典进行设置:
jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径 #词典文件举例: #创新办 3 i #云计算 5 #凱特琳 nz #台中 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来
2.关键词提取
文本被分词之后和数据处理一样,也会有如下两个问题:
其一,并不是所有的词都是有用的;其二,一个语料库的词量是非常大的,传统的文本挖掘方法又是基于向量空间模型表示的,所以这会造成数据过于稀疏。
为了解决这两个问题一般会进行停用词过滤和关键字提取,而后者现有基于频率的TF-IDF计算方法和基于图迭代的TextRank的计算方法两种。下面看看这两种方法是怎么工作的

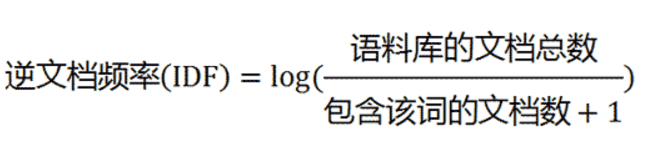
![]()
这里TF表示词在文章中的重要性,因为我们知道一个文章的主题一多次出现;IDF表示词的区分度,因为专业词汇在整个语料库中出现越少,越能关联文章主题。具体来说就是信息熵越低。
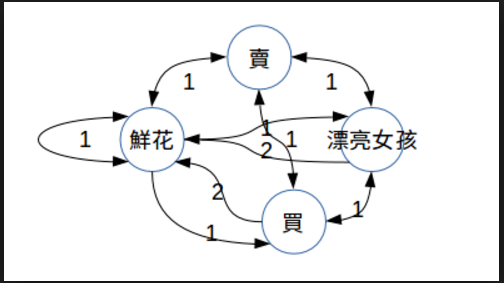
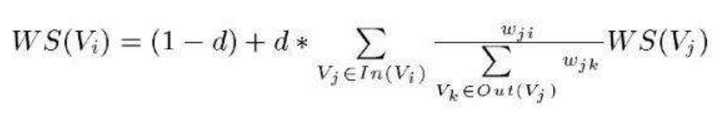
图1是一个文章的上下文词构造的无向加权图(UWG),图2是叶结点的权重迭代公式,其中d是阻尼系数。可见textRank认为一个节点如果入度多且权重大,那么这个节点越重要。
具体理论和代码走读参考: 关键词抽取源码,TextRank: Bringing Order into Texts;下面我们就动手试试吧!
import jieba.analyse #设置停词表路径 jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径 #默认tfidf提取关键词 jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=()) #sentence 为待提取的文本 #topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20 #withWeight 为是否一并返回关键词权重值,默认值为 False #allowPOS 仅包括指定词性的词,默认值为空,即不筛选 jieba.analyse.TFIDF(idf_path=None) #新建 TFIDF 实例,idf_path 为 IDF 频率文件 #textrank提取关键词 jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
上面jieba的TFIDF是通过需要指定IDF文件预先指定词的IDF值的,同时textrank中比较重要的参数有一个上下文窗口。jieba通过了这两个方法让我们筛选出前多少个关键词。然而sklearn提供了一种构建文档词矩阵(稀疏矩阵)的方法,可以让我们直接构建文本训练集。
>>> from sklearn.feature_extraction.text import TfidfVectorizer >>> vectorizer = TfidfVectorizer() >>> vectorizer.fit_transform(corpus) ... <4x9 sparse matrix of type '<... 'numpy.float64'>' with 19 stored elements in Compressed Sparse ... format>
3.词的表示形式
词不同于结构化数据和图像,词是符号,不能比较大小,所以无法在机器学习或者深度学习模型中使用;所以为了解决这个问题,历史上先后提出了词袋模型(bag of words)和词嵌入模型(wors embedding)。下面我会尽可能说清楚这两种思想,深入了解建议查阅出处论文。
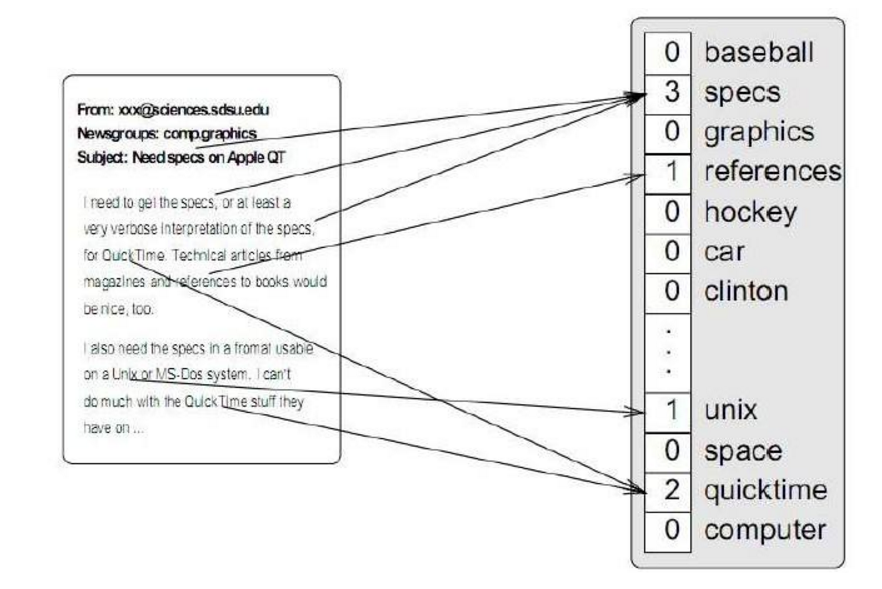
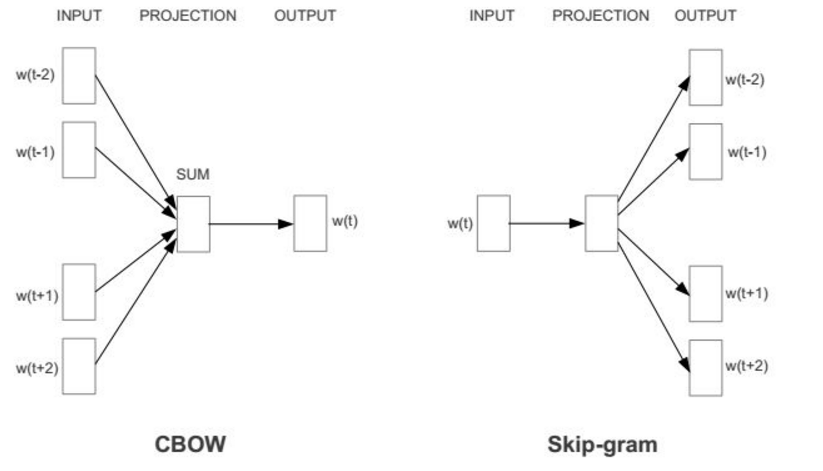
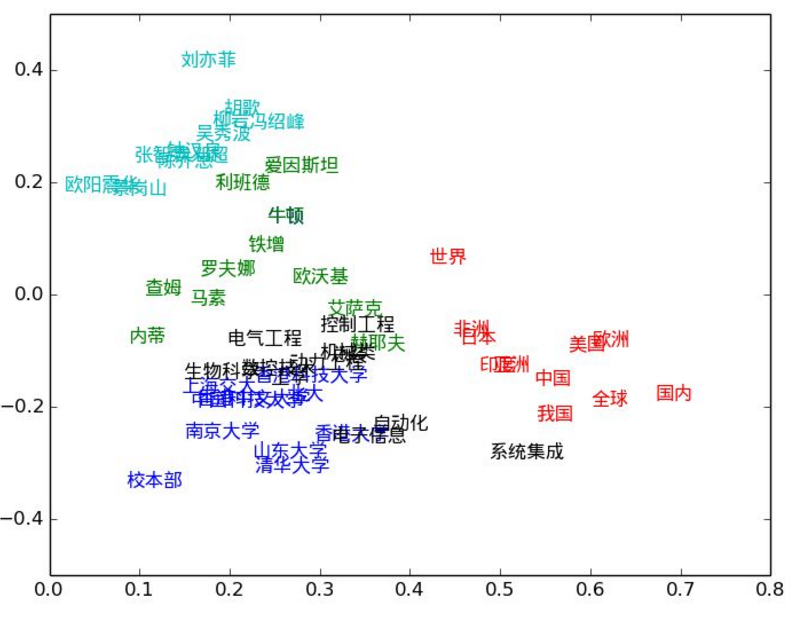
词袋模型的基本思想是假定一篇文档中的词之间是相互独立的,只需要将其视为是一组词的组合,就像一个袋子一样,无需考虑次序,句法,语法。如上面图1所示,词袋只是记录了词的出现次数,并没有先后关系,另外上文提到的TF-IDF一般作为一个词的特征表示;词嵌入模型的基本思想是词袋模型的改进版,其基本实现会根据中心词预测上下文词(Skip-gram)或者根据上下文词预测中心词(CBOW)。具体原理就不展开了,可以查看distributed-representations-of-words-and-phrases-and-their-compositionality。所以词嵌入(word2vec)模型训练出来的特征表示有一个特点就是语义相近的词其分布式向量距离也相似。如下图所示红色字体的国家名字的特征向量距离非常相近,所以根据利用词向量进行语义聚类成为了可能。如果所词聚类是单位向量的点乘运算,那右边这幅图就是词向量的加减运算喽。
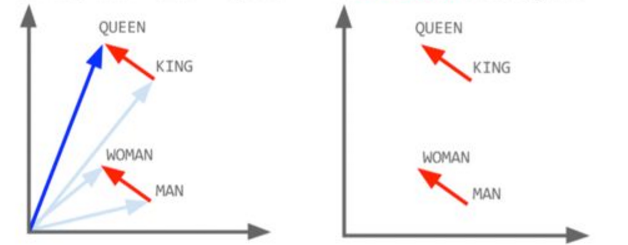
讲了这么多,那么我们用gensim练习一下word2vec吧!
1 import gensim 2 3 sentences = [['first', 'sentence'], ['second', 'sentence']] 4 # train word2vec on the two sentences 5 model = gensim.models.Word2Vec(sentences, min_count=1) 6 7 #如果给定的是一个文件可以这样训练奥 8 model = gensim.models.Word2Vec(iter=1) # an empty model, no training yet 9 model.build_vocab(some_sentences) # generator 10 model.train(other_sentences) # can be a non-repeatable, 1-pass generator 11 12 #这是some_sentences对应的生成器 13 class MySentences(object): 14 def __init__(self, dirname): 15 self.dirname = dirname 16 17 def __iter__(self): 18 for fname in os.listdir(self.dirname): 19 for line in open(os.path.join(self.dirname, fname)): 20 yield line.split() 21 22 sentences = MySentences('/some/directory') # a memory-friendly iterator 23 model = gensim.models.Word2Vec(sentences) 24 25 #使用模型 26 model['computer'] # raw NumPy vector of a word 27 array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32) 28 #向量加减 29 model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1) 30 [('queen', 0.50882536)] 31 #向量相似度 32 model.similarity('woman', 'man') 33 0.73723527 34 model.wv.wmdistance('woman', 'man')
本节到这里就结束了吗?不,还有一个叫做GloVe的词嵌入模型,其相对于为w2v又增加了一个词共现差异的假设:

-
- 如果ij很相关,ik不相关,那么
- 如果ij很相关,ik也相关,那么
关于损失函数推导请参看这篇文章:GloVe:另一种Word Embedding方法以及原论文glove,下面还是动起手来,跑一个词向量出来。
$ git clone http://github.com/stanfordnlp/glove $ cd glove && make $ ./demo.sh
那么运行结束后,就会生成vectors.txt文件,里面就是词的嵌入表达了。这里安利一篇w2v与GloVe的比较
4.主题模型
主题模型的基本假设是:文章和主题是多对多的关系,每一个主题又由一组词进行表示。
如图,我们输入一组文档作为语料库,并指定主题的个数,主题模型会自动学习出k个主题,并保存文档-主题,主题-词的映射关系(以多项概率分布表示)
5.几种常用的NLP工具简介
1.jieba分词
主要功能:
分词:seg_list = jieba.cut("我来到北京清华大学", cut_all=True,HMM=True)
提取关键词:jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
词性(POS)标注:words =posseg.cut("我爱北京天安门")
Tokenize:返回词语在原文的起止位置:result = jieba.tokenize(u'永和服装饰品有限公司')
主要功能:
分句:sents = SentenceSplitter.split('元芳你怎么看?我就趴窗口上看呗!')
分词:words = segmentor.segment('元芳你怎么看')
词性标注:postags = postagger.postag(words)
命名实体识别:netags = recognizer.recognize(words, postags)
句法依存分析
# -*- coding: utf-8 -*-
import os
LTP_DATA_DIR = '/path/to/your/ltp_data' # ltp模型目录的路径
par_model_path = os.path.join(LTP_DATA_DIR, 'parser.model') # 依存句法分析模型路径,模型名称为`parser.model`
from pyltp import Parser
parser = Parser() # 初始化实例
parser.load(par_model_path) # 加载模型
words = ['元芳', '你', '怎么', '看']
postags = ['nh', 'r', 'r', 'v']
arcs = parser.parse(words, postags) # 句法分析
print "\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs) parser.release() # 释放模型
语义角色标注
# -*- coding: utf-8 -*- import os LTP_DATA_DIR = '/path/to/your/ltp_data' # ltp模型目录的路径 srl_model_path = os.path.join(LTP_DATA_DIR, 'srl') # 语义角色标注模型目录路径,模型目录为`srl`。注意该模型路径是一个目录,而不是一个文件。 from pyltp import SementicRoleLabeller labeller = SementicRoleLabeller() # 初始化实例 labeller.load(srl_model_path) # 加载模型 words = ['元芳', '你', '怎么', '看'] postags = ['nh', 'r', 'r', 'v'] netags = ['S-Nh', 'O', 'O', 'O'] # arcs 使用依存句法分析的结果 roles = labeller.label(words, postags, netags, arcs) # 语义角色标注 # 打印结果 for role in roles: print role.index, "".join( ["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]) labeller.release() # 释放模型
3.SnowNLP:
主要功能:
中文分词(Character-Based Generative Model)
词性标注(TnT 3-gram 隐马)
情感分析:SnowNLP(u'这个东西真心很赞').sentiments
文本分类:
转换成拼音(Trie树实现的最大匹配)
繁体转简体(Trie树实现的最大匹配)
提取文本关键词(TextRank算法)
提取文本摘要:
text = u'''
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。
它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
自然语言处理是一门融语言学、计算机科学、数学于一体的科学。
因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,
所以它与语言学的研究有着密切的联系,但又有重要的区别。
自然语言处理并不是一般地研究自然语言,
而在于研制能有效地实现自然语言通信的计算机系统,
特别是其中的软件系统。因而它是计算机科学的一部分。
'''
s = SnowNLP(text)
s.summary(3) # [u'因而它是计算机科学的一部分',
# u'自然语言处理是一门融语言学、计算机科学、
# 数学于一体的科学',
# u'自然语言处理是计算机科学领域与人工智能
# 领域中的一个重要方向']
tf-idf
Tokenization(分割成句子)
文本相似(BM25)
4.gensim
LSI矩阵:https://radimrehurek.com/gensim/wiki.html#latent-semantic-analysis
LDA主题模型:https://radimrehurek.com/gensim/wiki.html#latent-dirichlet-allocation
Word2vec词向量:https://radimrehurek.com/gensim/models/word2vec.html
Doc2vec句/段向量:https://radimrehurek.com/gensim/models/doc2vec.html
Stemming词干提取:https://radimrehurek.com/gensim/parsing/porter.html
summarize摘要:https://rare-technologies.com/text-summarization-with-gensim/
6.文本挖掘(文本分类,文本标签化)
6.1 数据预处理:去停用词(虚词,标点符号等),英文大小写统一,英文提取词干(去掉前后缀)等等
6.1 关于文本的特征工程
词性标注:分别提取出名词,形容词,动词等实词。参考:哈工大ltp词性标注列表和ICTCLAS词性列表
功能字统计:说明其构词能力的强弱,构词越多,其构词能力越强,越小说明构词能力不强,可以剔除,这些字就是功能字。

根据每一种任务的不同,设计不同的特征,比如是文本重复/相似问题检测的可以设计如下特征:
句子的长度,词的个数,共现词的个数,jaccard相似度等等
6.3 关于文本的模型
TFIDF+朴素贝叶斯的方法:概率模型,通过学习训练集的每一个词对预测类别的条件概率进行预测
TFIDF+XGB的方法:树模型的每一个叶结点学习出一条判别路径,多个树模型一起对类别进行预测
fasttext:
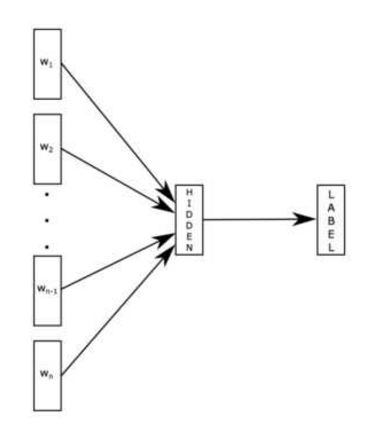
句子中所有的词向量进行平均,然后直接接 softmax 层。其实文章也加入了一些 n-gram 特征的 trick 来捕获局部序列信息。
textCNN:
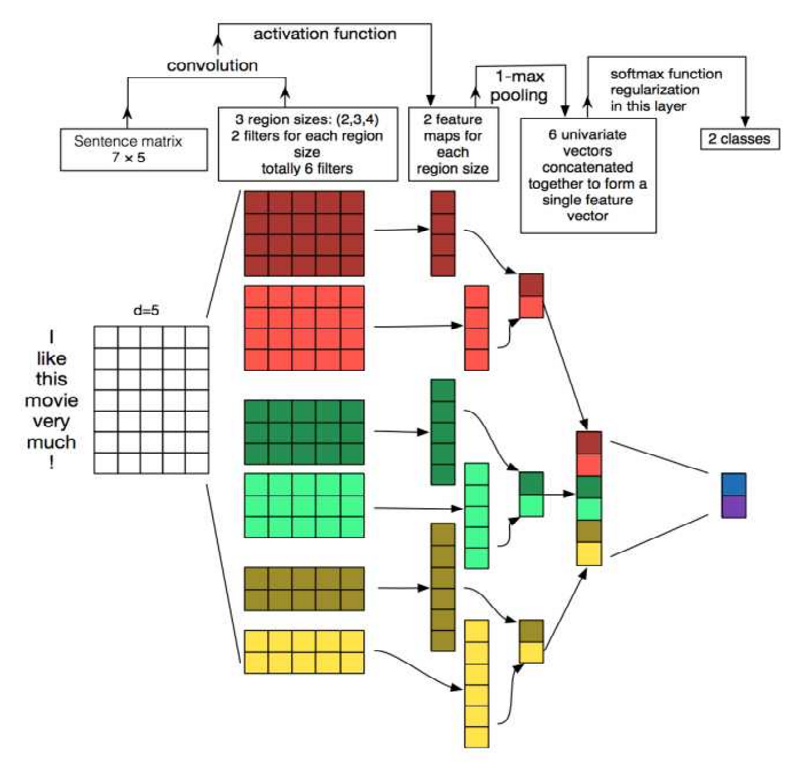
第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点了。然后经过有 filter_size=(2,3,4) 的一维卷积层,每个filter_size 有两个输出 channel。第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示了,最后接一层全连接的 softmax 层,输出每个类别的概率。
textRNN:
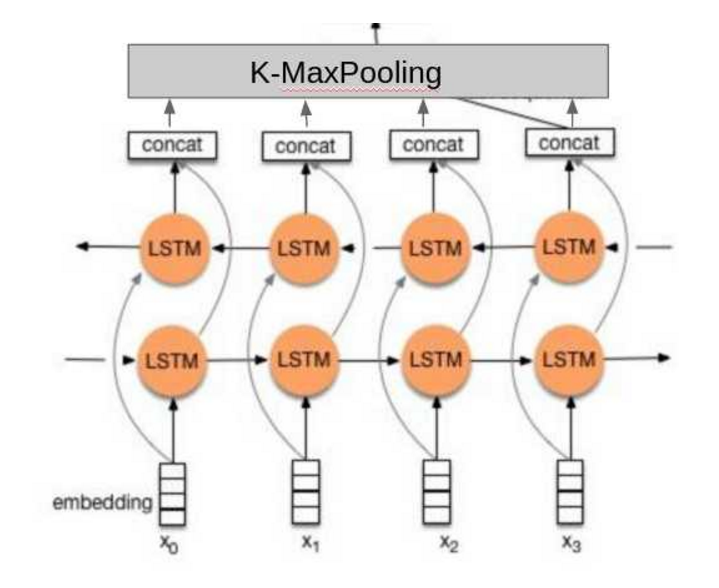
RNN的优点是可以捕获变长且双向的的 "n-gram" 信息。
TextRCNN:
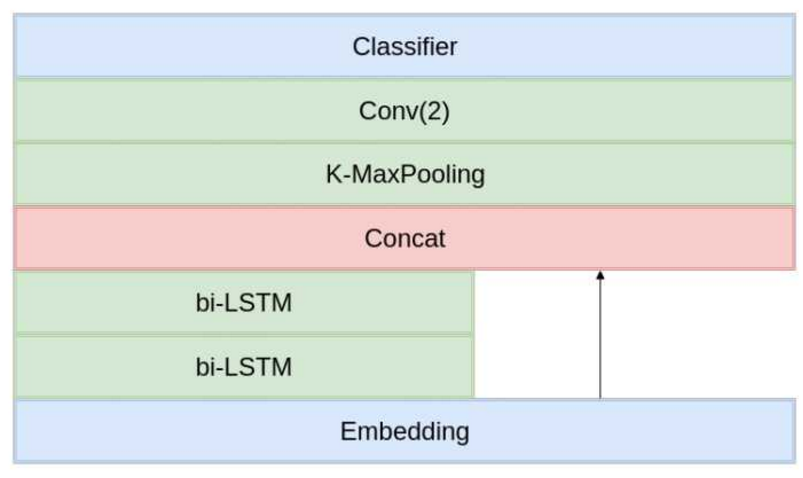
keras实现的深度学习文本分类(IMDB情感分类数据): cnn代码 rnn代码 rcnn代码
tensorflow实现的深度学习文本分类(THUCNews中文新闻分类):cnn代码 rnn代码
补充理论部分(出处):fasttext textCNN textRNN 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
7.NLP任务(词性标注,句法分析)
句法分析:
依存句法分析的目标是将输入的自然语言文本从序列形式转化为树状结构,从而刻画句子内部词语之间的句法关系。
依存语法的基本假设是:一个依存关系连接两个词,分别是核心词 (Head) 和修饰词 (Dependent)。依存关系可以细分为不同的类型,表示两个词之间的句法关系 (Dependency Relation Types)。
依存关系的5条公理:
- 一个句子中只有一个成分是独立的;
- 其它成分直接依存于某一成分;
- 任何一个成分都不能依存与两个或两个以上的成分;
- 如果A成分直接依存于B成分,而C成分在句中位于A和B之间,那么C或者直接依存于B,或者直接依存于A和B之间的某一成分;
- 中心成分左右两面的其它成分相互不发生关系。
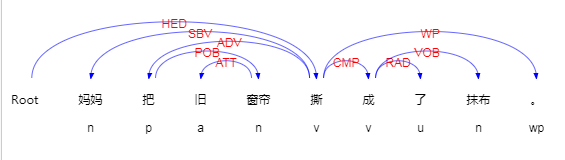


依存分析:中文依存句法分析简介 哈工大LTP文档
8.NLP应用(信息检索,情感分析,文章摘要,OCR,语音识别,图文描述,问答系统,知识图谱)
8.1 (命名)实体识别
1 #########初始化jieba分词工具包############# 2 import jieba 3 stop_words_path = "../../data/stop_words.txt" 4 jieba.dt.tmp_dir = '..\..\cache\\' 5 jieba.dt.cache_file = 'jieba.cache' 6 7 stoplist = set() 8 with open(stop_words_path, 'rb') as f: 9 while (True): 10 word = f.readline().decode('utf-8') 11 if word: 12 if '\r\n' in word: word = word.replace('\r\n', '') 13 stoplist.add(word) 14 else: 15 break 16 #########初始化pyltp哈工大中文NLP工具包############# 17 import os 18 LTP_DATA_DIR = 'model/ltp_data' # ltp模型目录的路径 19 ner_model_path = os.path.join(LTP_DATA_DIR, 'ner.model') # 命名实体识别模型路径,模型名称为`pos.model` 20 pos_model_path = os.path.join(LTP_DATA_DIR, 'pos.model') # 词性标注模型路径,模型名称为`pos.model` 21 from pyltp import NamedEntityRecognizer 22 recognizer = NamedEntityRecognizer() # 初始化实例 23 recognizer.load(ner_model_path) # 加载模型 24 from pyltp import Postagger 25 postagger = Postagger() # 初始化实例 26 postagger.load(pos_model_path) # 加载模型 27 28 29 def get_ner( new_doc,Nh_list,Ns_list,Ni_list ): 30 ''' 31 抽取出文档的命名实体 32 :param new_doc:文本内容,utf-8编码的str 33 :param Nh_list:存储人名的结果,list 34 :param Ns_list:存储地名的结果,list 35 :param Ni_list: 存储机构名的结果,list 36 :return: 37 ''' 38 seg_list = jieba.cut(new_doc) 39 words = ','.join( seg_list ).encode('utf-8') 40 words = words.split(',') 41 postags = postagger.postag(words) 42 netags = recognizer.recognize(words, postags) 43 for i in range( len(netags) ): 44 word = words[i].decode(encoding='utf-8') 45 if 'Nh' in netags[i]: 46 if word in Nh_list:continue 47 Nh_list.append(word) 48 if 'Ns' in netags[i]: 49 if word in Ns_list: continue 50 Ns_list.append(word) 51 if 'Ni' in netags[i]: 52 if word in Ni_list: continue 53 Ni_list.append(word) 54 # print( '人名: %s' % (','.join(Nh_list).encode('utf-8')) ) 55 # print( '地名: %s' % (','.join(Ns_list).encode('utf-8')) ) 56 # print( '机构名: %s' % (','.join(Ni_list).encode('utf-8')) )
情感分析:电商情感分析(svm代码 rnn代码 基于实体级别的情感分析knn代码)
文章摘要:抽取式方法(基于特征和关键词的TextTeaser 基于图的TextRank 考虑相关性和多样性)生成式方法(谷歌Seq2Seq-attention模型及中文版)
OCR:(centos安装tesseract pytesseract识别例子 Tesseract-OCR识别中文与训练字库实例)
语音识别:
图文描述:
聊天机器人(ChatterBbot 中文对话系统语料库 dynamic-seq2seq chatbot)
问答系统:
知识图谱:SPARQL查询 ;【转】基于VSM的命名实体识别、歧义消解和指代消解

