
热门标签
当前位置: article > 正文
yolov5模型训练结果分析_yolov5模型的准确率
作者:Monodyee | 2024-03-20 01:49:45
赞
踩
yolov5模型的准确率
本文训练了50轮安全帽检测数据集,分析训练结果如下:
| 检测精度 | 检测速度 |
|---|---|
| Precision;Recall;F1_score | 前传耗时 |
| IOU交并比 | FPS每秒帧数 |
| P-R曲线 | flops浮点运算数量 |
| AP;mAP |
检测精度
- 混淆矩阵confusion_matrix
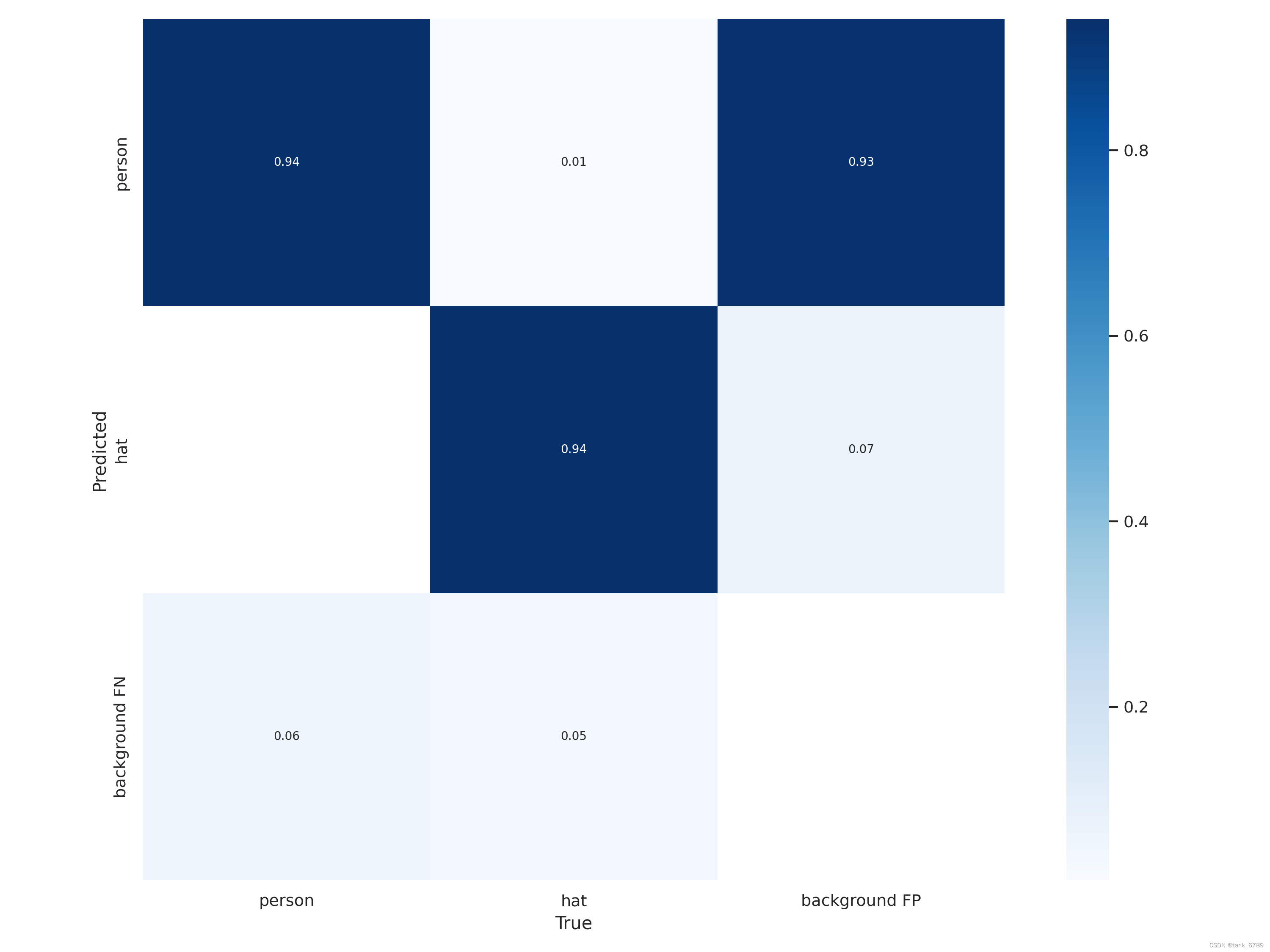
- 用来查看机器是不是把几个不同的类混淆了,比如把一个类当成另一个类。
- 矩阵的x轴横坐标代表真实类别,y轴纵坐标代表预测类别。矩阵中的每个值Aij表示第j类被预测为第i类的概率。
- 理想情况:除background外其余形成对角矩阵。
- P&R&P-R&F1_curve
- 准确率Precision:(检测的准不准确)检测的效果好不好,检测到的区域是不是都为正确区域。P=TP/TP+FP
- 理想值:1
- 召回率Recall:(检测的全不全面)该检测到的区域是不是都检测到了。R=TP/TP+FN;FN是该检测到但是没有检测出的区域。
- 理想值:1
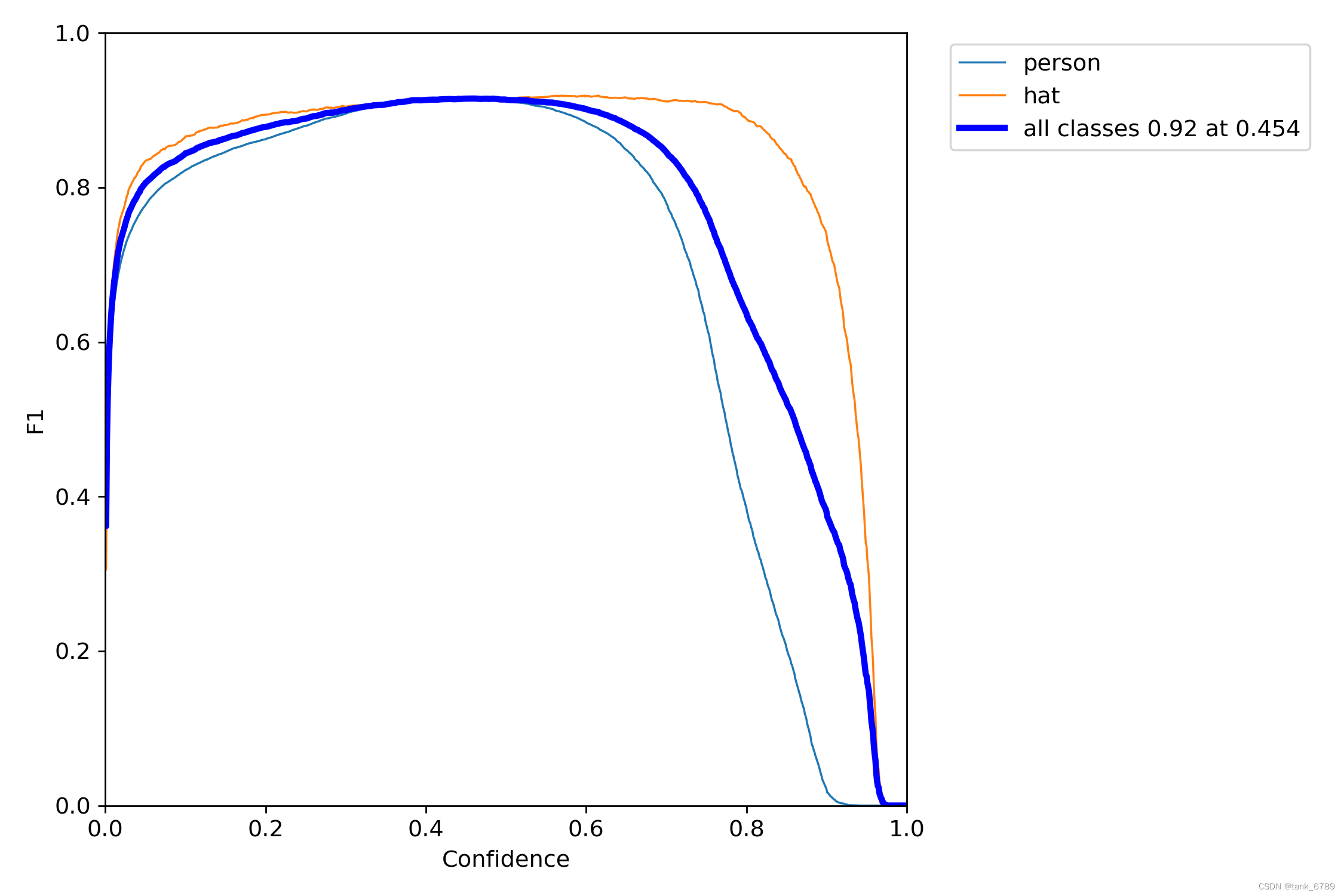
- P_curve:准确率和置信度的关系图
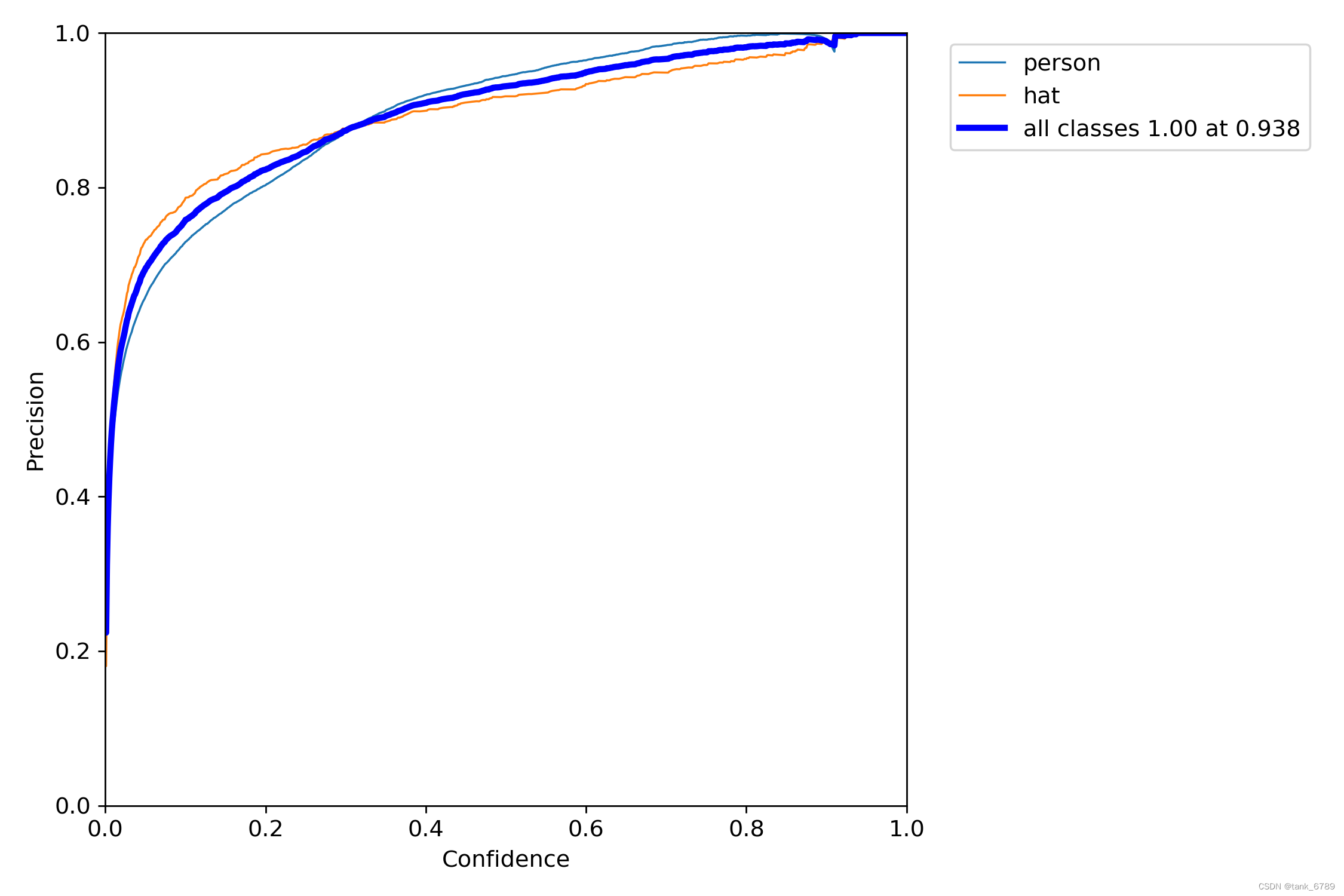
该图描述随着置信度阈值的增加,P值的变化;置信度设为某一数值的时候,各个类别识别的准确率。
- R_curve:召回率和置信度的关系
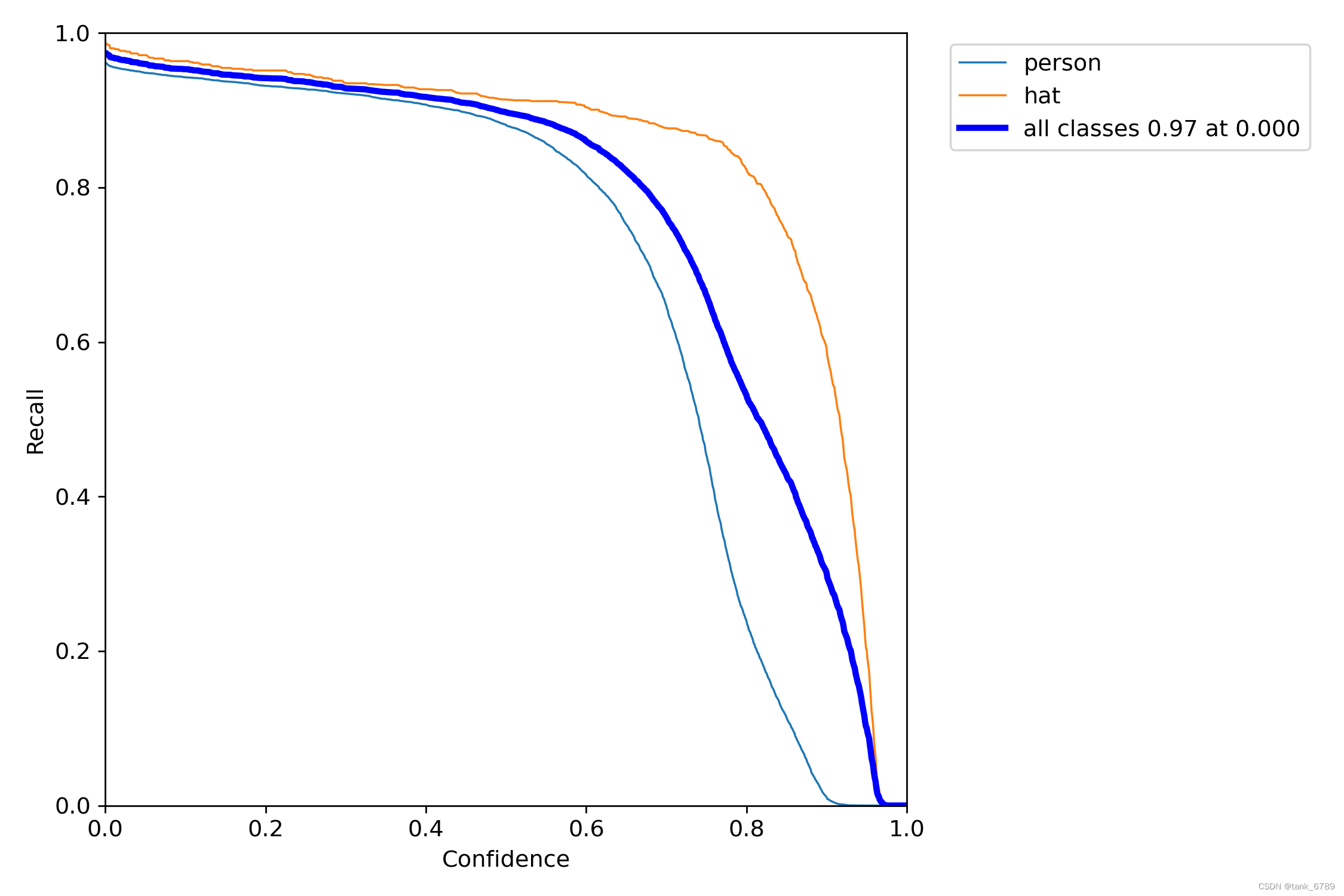
当设置置信度为某一数值的时候,各个类别的查全的概率。
- PR_curve
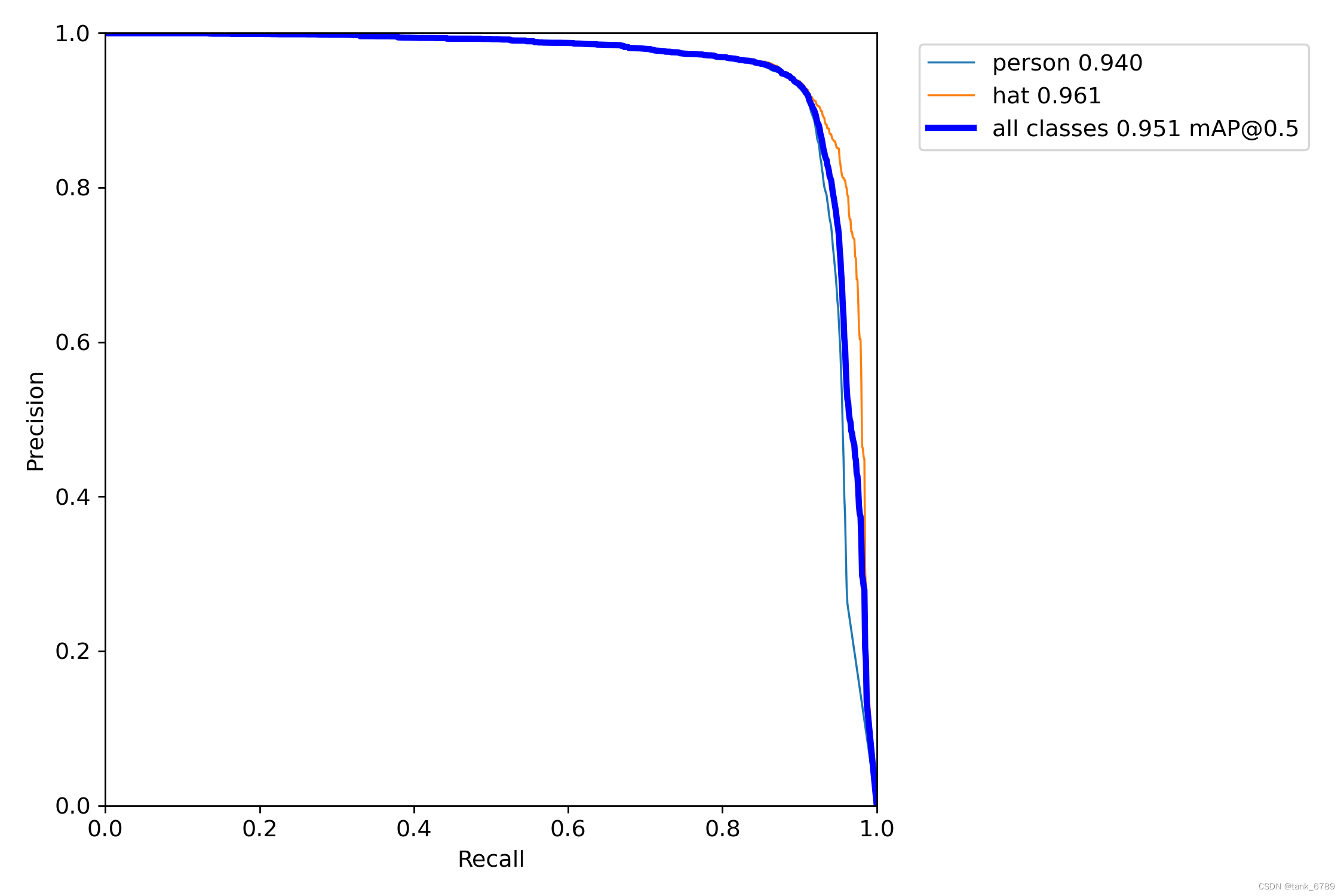
精度和召回率的关系图,而是是有些矛盾存在的。精度越高,召回率越低,理想情况是(1,1)点,即在准确度很高的情况下,尽可能检测到全部的类别。二者围成的面积就是mAP值,mAP面积越接近于1,效果越好。
- F1_curve
- Labels:
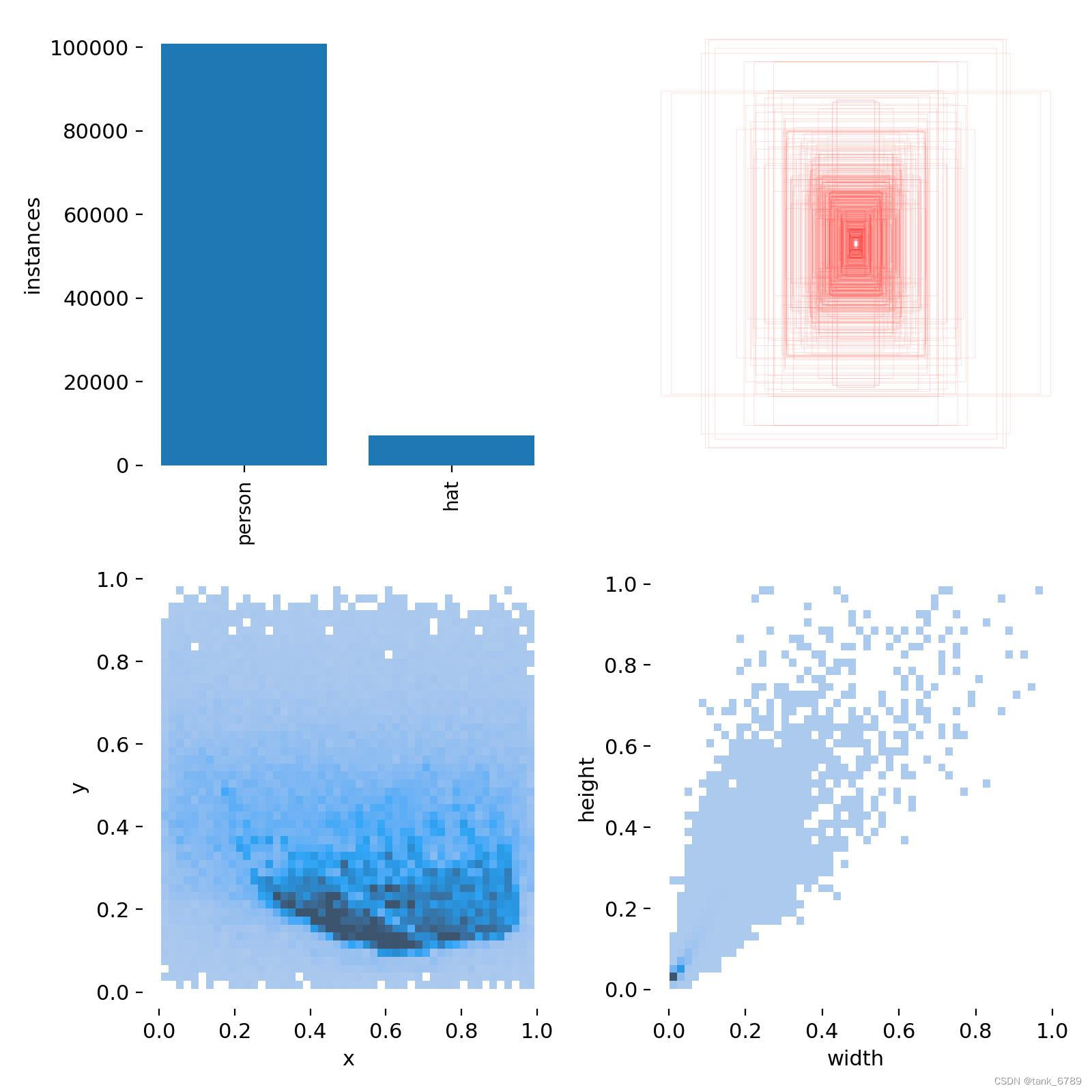
第一个图是训练集的数据量,每个类别有多少个
第二个是框的尺寸和数量
第三个是center点的位置。
第四个是labeld的高宽。可以看出头部一般相比于整个图片比较小,所以看到样本大多分布在(0-0.2,0-0.2)
4. result.png
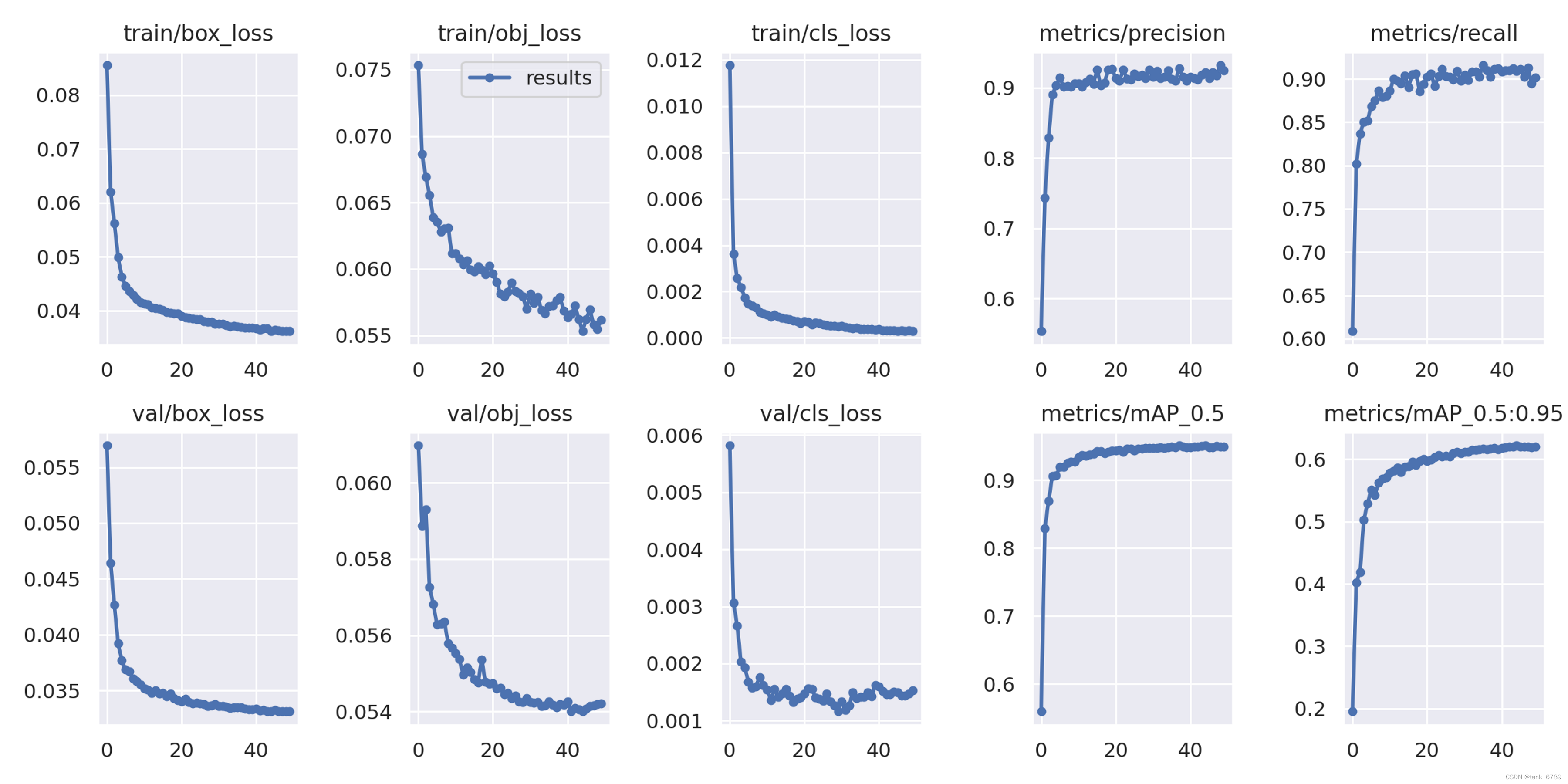
- Loss function:损失函数越小越好,描述模型的预测值和真实值不一样的程度。极大程度上决定了模型的性能。
- 定位损失box_loss:预测框与真实框之间的误差(GIOU)
- 置信度损失obj_loss:
- 类别损失cls_loss:计算锚框与对应的标定框类别是否一致
- mAP@0.5:0.95:表示在不同的IOU阈值(从0.5到0.95,步长为0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均Map。
mAP@0.5:表示阈值大于0.5的平均mAP
检测速度
- 前传耗时(ms):从输入一张图像到输出最终结果所消耗的时间,包括前处理耗时(如图像归一化)、网络前传耗时、后处理耗时(如非极大值抑制)。
- 每秒帧数FPS (Frames Per Second): 每秒钟能处理的图像数量,越高越好。
- 浮点运算量(FLOPS):处理一张图像所需要的浮点运算数量,跟具体软硬件没有关系,可以公平地比较不同算法之间的检测速度。
参考:
YOLO-V5训练结果的分析与评价:https://blog.csdn.net/weixin_45751396/article/details/126726120
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/269790
推荐阅读

相关标签

