
- 1关于element-ui 的upload组件 在vue中应用的几点说明(主要说http-request自定义上传过程的参数的使用)_element ui upload http-request 一种是表单参数一种是正常参数
- 2HarmonyOS 鸿蒙开发DevEco Studio OpenHarmony:开发OpenHarmony npm包_open harmony package manager
- 3Androidd五大布局LinearLayout,RelativeLayout,AbsolutLayout,FrameLayoutTablelayout_鸿蒙tablelayout如何如何按权重分配剩余空间
- 4一文读懂自然语言处理NLP(图解+学习资料)_图示法表示语言处理的过程
- 5ArkTS快速入门_arkts接口如何编写
- 6Spring Boot_writerbuilderenhancer
- 7MQTT 使用MQTT.fx实现阿里云通信_阿里云mqtt如何通信
- 8理解LVM(一):lvm入门介绍
- 9Error inflating class com.baidu.mapapi.map.MapView
- 10odoo 继承_odoo继承
字符编码_三个字节有符号转为
赞
踩
输入字符–>计算机根据编码表转换成二进制数,然后进行计算–>再将二进制的计算结果通过编码表转换成字符,反馈给用户。
ASCII
ASCII码表全称是“美国信息交换标准代码”。
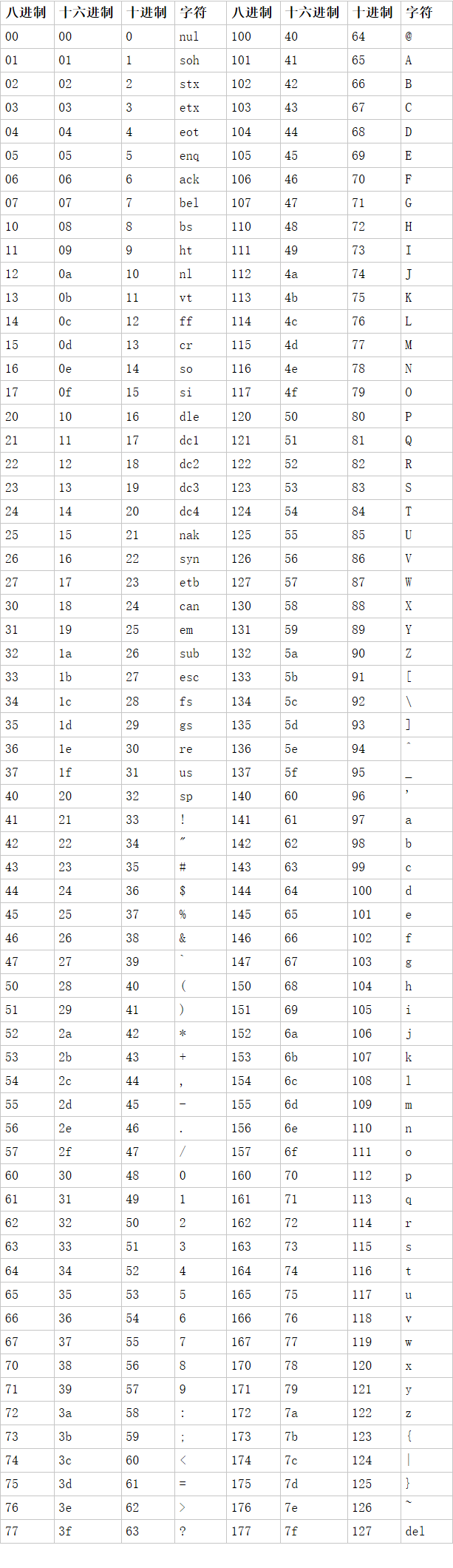
在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格”SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
缺陷:英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。并且一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号。
Unicode
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode(统一码,万国码),就像它的名字都表示的,这是一种所有符号的编码。
Unicode有两套标准,一套叫UCS-2(Unicode-16),用2个字节为字符编码,另一套叫UCS-4(Unicode-32),用4个字节为字符编码。
以目前常用的UCS-2为例,它可以表示的字符数为2^16=65535,基本上可以容纳所有的欧美字符和绝大部分的亚洲字符 。
缺陷:1.无法区分Unicode和ASCII,计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?2.英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
UTF-8
UTF-8是Unicode的实现方式之一。
互联网的普及,强烈要求出现一种统一的编码方式。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
1.对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2.对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
| 字节 | 二进制 |
|---|---|
| 1 | 0xxxxxxx |
| 2 | 110xxxxx 10xxxxxx |
| 3 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
记事本的编码格式

1.ANSI是指默认的编码方式,并不是确定的一种编码,在简体中文操作系统指的是 GB2312,在繁体操作系统指的是 BIG5。(泛指最早每种国家语言各自实现的编码方式,各个编码互相之间不兼容)
2.Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码。这个选项用的little endian格式。(以汉字”严”为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。)
3.Unicode big endian编码与上一个选项相对应。
4.UTF-8
为了区分记事本用的是哪种编码方式,会在前面加上标签,也就是BOM(位元组顺序记号(Byte Order Mark))。
FF FE,则为Unicode big endian
FE FF,则为Unicode
EF BB BF,则为UTF-8
没有标签,则为ANSI
Encoding
利用Encoding类实现字符串与字节数组的转换
//利用gb2312编码把'我'转换成字节数组
byte []bs=Encoding.GetEncoding("gb2312").GetBytes(new char[] { '我' });
foreach (byte item in bs)
{
Console.WriteLine(item.ToString("x2"));
}
//ce
//d2
//利用系统默认编码把'我'转换成字节数组
byte []bs=Encoding.Default.GetBytes(new char[] { '我' });
foreach (byte item in bs)
{
Console.WriteLine(item.ToString("x2"));
}
//ce
//d2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

