
- 1简单介绍Hadoop实操_fayson hadoop实操
- 2微博舆情分析系统
- 3vue3为什么使用带有 .value 的 ref,而不是普通的变量_vue中ref使用时为什么要加value
- 4Corrupt JPEG data: premature end of data segment
- 5基于java springboot框架+微信小程序原生开发框架+mysql数据库的养老服务系统 计算机毕业设计 微信小程序开发_微信小程序+springboot+mysql项目
- 6Android面试官爱问的12个自定义View的问题
- 7[No000012D]WPF(5/7)依赖属性
- 8安卓开发学习之SystemServer启动过程_initbeforestartservices
- 9php在线解密工具,zend5.2,zend5.3,zend5.4,支持ioncube,魔方,sourceguardian,goto,微擎加密,混淆eval等解密_sourceguardian解密
- 10公众号文章目录整理_公众号文章目录索引
《Hadoop权威指南4》第3章 Hadoop分布式文件系统_hflush 元数据
赞
踩
Hadoop权威指南4
第3章 Hadoop分布式文件系统
管理网络中跨多台计算机存储的文件系统称为分布式文件系统(distributed filesystem)。Hadoop自带一个称为HDFS的分布式文件系统。
3.1 HDFS的设计
HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上。
- 超大文件:几百MB、GB、TB、PB大小的文件
- 流式数据访问:一次写入、多次读取的访问模式
- 商用硬件:HDFS只需要普通硬件,不必要运行在昂贵且高可靠的硬件上
- 低时间延迟的数据访问:不适合在HDFS上运行
- 大量小文件:namenode将文件系统的元数据存储在内存中,所以文件总数受限,不适合大量小文件
- 多用户写入,任意修改文件:HDFS中的文件写入只支持 单个写入者 ,而且写操作总是以“只添加”方式在文件 末尾写 数据
3.2 HDFS的概率
3.2.1 数据块
HDFS的块(block)默认128MB,文件被划分为块大小的多个分块(chunk),作为单独的存储单元。
- 一个文件的大小可以大于网络中的任意一个磁盘的容量
- 抽象块而非整个文件作为存储单元,简化了存储子系统的设计
- 块非常适合用于数据备份进而提供数据容错能力和提高可用性
3.2.2 NameNode和DataNode
HDFS集群有两类节点以管理节点-工作节点模式运行:一个namenode(管理节点)和多个datanode(工作节点)
- namenode管理文件系统的命名空间
- 客户端 (client)代表用户通过与namenode和datanode交互来访问整个文件系统
- datanode是文件系统的工作节点:存储并检索数据块(受客户端或namenode调度),并且定期向namenode发送所存储数据块的列表
对namenode的容错非常重要,Hadoop提供两种机制:
- 备份组成文件系统元数据持久状态的文件:写入本地磁盘的同时,写入一个网络文件系统(NFS)
- 使用辅助namenode定期合并编辑日志和命名空间镜像,但它不能用作namenode。
3.2.3 块缓存
通常datanode从磁盘中读取块,但对于访问频繁的文件,其对应的块可能被显式地缓存在datanode的内存中,以堆外块缓存(off-heap block cache)的形式存在
3.2.4 联邦HDFS
namenode的内存中保存文件系统的元数据,其内存会成为限制系统横向扩展的瓶颈,联邦HDFS允许系统通过添加namenode实现扩展,每个namenode管理文件系统命名空间中的一部分。
- 每个namenode维护一个命名空间卷:命名空间元数据+数据块池
- 命名空间卷相互独立,互不通信,甚至一个namenode失效也不影响另一个namenode
- datanode需要注册到每个namenode
3.2.5 HDFS的高可用性
namenode存在单点失效问题,且恢复失效namenode的时间很长。Hadoop2增加了HDFS的高可用性(HA)支持,配置了一对活动-备份(active-standby)namenode。架构上有如下修改:
- namenode之间需要通过高可用共享存储实现编辑日志的共享
- datanode需要同时向两个namenode发送数据块处理报告
- 客户端需要使用特定的机制来处理namenode的失效问题
- 辅助namenode的角色被备用namenode所包含,备用namenode为活动namenode的命名空间设置周期性检查点
3.3 命令行接口
HDFS有很多接口,命令行是最简单的,也是许多开发者最熟悉的。
伪分布式配置时,有2个属性项:
- fs.defaultFS,设置为hdfs://localhost/,用于设置Hadoop的默认文件系统,文件系统由URI指定
- dfs.replication,设置为1,这样文件副本为1,不然默认为3
文件系统的基本操作
- 从本地文件系统将一个文件复制到HDFS



- 把文件复制回本地文件系统,并检查一致性

3.4 Hadoop 文件系统
Hadoop有一个抽象的文件系统概念,HDFS只是其中的一个实现,Java抽象类org.apache.hadoop.fs.FileSystem定义了Hadoop中一个文件系统的客户端接口,且有一些具体实现:


Hadoop对文件系统提供许多接口,一般使用URI来选取合适的文件系统实例进行交互,列出本地文件系统根目录下的文件命令如下:
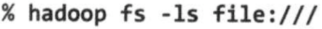
接口
-
HTTP
由WebHDFS协议提供HTTP REST API使得其他语言开发的应用能够更方便地与HDFS交互 -
C语言
Hadoop提供一个名为libhdfs的C语言库,是Java FileSystem接口类的一个镜像。开发滞后于Java API -
NFS
使用Hadoop的NFSv3网关将HDFS挂载为本地客户端的文件系统 -
FUSE
使用Hadoop的Fuse-DFS功能模块,HDFS可以作为一个标准的本地文件系统进行挂载。
3.5 Java接口
本节主要探索Hadoop的FileSystem类:它是与Hadoop的某一文件系统进行交互的API。
3.5.1 从Hadoop URL读取数据
使用java.net.URL对象打开数据流,从中读取数据。格式如下图:

3.5.2 通过FileSystem API读取数据
范例 3-2 使用FileSystem以标准输出格式显示Hadoop文件系统中的文件,如下图:

3.5.3 写入数据
FileSystem类有一系列新建文件的方法。
- 最简单的方法是给准备新建的文件指定一个Path对象,然后返回一个用于写入数据的输出流:

- 使用append()方法在一个现有文件末尾追加数据:

3.5.4 目录
FileSystem实例提供了创建目录的方法:

3.5.5 查询文件系统
- 文件元数据:FileStatus
FileStatus类封装了文件系统中文件和目录的元数据,包括文件长度、块大小、副本、修改时间、所有者信息及其权限信息。 - 列出文件
列出目录中的内容:

- 文件模式
单个操作处理一批文件的需求可以用通配符来实现,Hadoop提供了2个FileSystem方法:

Hadoop支持的通配符与Unix bash shell相同:

- PathFilter 对象
3.5.6 删除数据
使用FileSystem的delete()方法可以永久性删除文件或目录

3.6 数据流
3.6.1 剖析文件读取

3.6.2 剖析文件写入

3.6.3 一致模型
文件系统的一致模型描述了文件读/写的数据可见性。HDFS于POSIX要求不同
- 新建一个文件后,在文件系统的命名空间中立即可见,但,文件的内容不保证立即可见。当前正在写入的块对其他reader不可见
- FSDataOutputStream调用hflush()方法,使写入的数据都到达datanode了,但是不一定写入了磁盘
- 调用hsync()方法,可以确保数据写入datanode的磁盘
3.7 通过distcp并行复制
- 复制文件

- 复制目录

- distcp可以保持HDFS集群的均衡,将-m选项设定为多于节点的数量

