
- 1APP如何发布到Google play 商店?以及有哪些需要注意的点_app上架谷歌商店
- 2Python中jieba分词自定义字典失效?_jieba自定义词典不生效
- 3揭秘无忧秘书智脑:AI绘画功能引领创意新潮流
- 4HarmonyOS鸿蒙基于Java开发: 分布式数据服务
- 5建立一个名为Student的类,该类有以下几个私有数据成员:学生姓名、学号、性别和年龄。还有以下两个成员函数:一个用于初始化学生姓名、学号、性别和年龄的构造函数,一个用于输出学生信息的函数。_创建一个学生类universitystudent,该学生类中包含属性:私有的姓名name, 私有的性
- 6本地测试(开发模式)Hbuilder 打包vue移动APP [初学记录]_hbuilder 隔离环境打包vue项目 生成 测试 开发环境
- 7请问一下这个回归模型里面,DIFF下面的数字代表什么啊,按道理来说如果是p值的话,小于0.01才应该标注三颗星呀,请问这里的DIFF(t值)代表的是啥_stata0.01几个星
- 8docker实战(2)
- 9图像修复方法总结以及深度学习的论文汇总(更新中。。。)_论文中传统的图像修复方法有哪些
- 10android 启动另一个app,Android APP打开另一个APP的几种实现总结
大语言模型工作原理:AI如何理解与创造语言?
赞
踩
大型语言模型(LLM),如GPT、BERT等,基于深度学习技术,从海量文本中学习语言的模式和规律,核心任务是预测接下来最可能出现的单词,从而实现自然语言生成和理解。
数据处理与学习
这些模型内嵌有数十亿到数千亿的参数,通过大量的数据学习获得,每个参数都是对特定语言知识的一种编码,涵盖词汇、语法规则、语境关联和语言用法等信息。这些参数的集合构成了模型对自然语言的全面理解。

LLM在处理数据时不仅学习语言的基本结构,还学习如何根据上下文和语境正确地解释和应用这些语言元素。这意味着模型能够理解同一个词或短语在不同情境中可能有不同的含义。例如,"bank"一词在金融和地理两个不同上下文中分别表示不同的概念。这种理解使得LLM能够更准确地处理自然语言。
特别是在处理地域特定的成语时。LLM通过分析大量跨文化的文本,学习到不同地区和文化中语言的独特用法。这种全面的学习使得LLM能够更好地理解和生成特定文化背景下的文本。
训练过程
模型的训练阶段是一个计算密集型的过程,它要求大量的计算资源来处理和分析庞大的数据集。在这个阶段,模型通过高性能的计算系统,如GPU集群,来学习和适应语言模式和规则。这一过程不仅需要处理大量的信息,而且对先进的计算资源有着高度依赖,以确保训练的效率和效果。
开发者们从互联网上收集了大量的文本数据,如新闻文章、社交媒体帖子、书籍、科学论文等,作为训练材料。这些数据集不仅包括语法结构的学习,还包括对语言的深层次理解,例如文化背景、语境含义和情感色彩等。模型通过这些数据学习语言的结构,以及如何在不同上下文中适当地使用语言。最终使模型能够根据给定的上下文准确预测下一个单词或短语。同时依赖于高性能的GPU(图形处理单元)集群,进行处理和分析这些庞大的数据集。
预测与生成
LLM通过分析输入的文本序列来预测下一个最可能的单词。这种预测不是随机的,而是基于模型通过大量数据训练得到的对语言的综合理解。这个过程涉及对词汇、语法和语境的分析。
假设模型接收到“我今天去了”这样的输入,它的预测基于它在训练过程中接触到的类似句子。如果在它的训练数据中,“我今天去了”后面常跟“商场”或“公司”,模型会将这些作为可能的选项。但这不仅仅是基于频率的简单匹配。模型还考虑上下文的细节,可能还包括对话历史或相关文本的内容,以更准确地预测下一个词。
这种预测过程体现了LLM的高级语言理解能力。模型不仅仅是在记忆单词或短语,而是在学习和模仿人类语言使用的复杂性。这包括理解句子的含义,捕捉语言的微妙变化,并在此基础上生成新的、合适的内容。
微调与个性化
尽管LLM在训练时接触过海量的数据,但它们也可以通过微调来适应特定的应用场景。微调是在预训练学习了广泛语言知识的基础上,进一步针对特定任务进行的训练过程。使模型更好地理解和执行与特定领域或应用相关的任务。
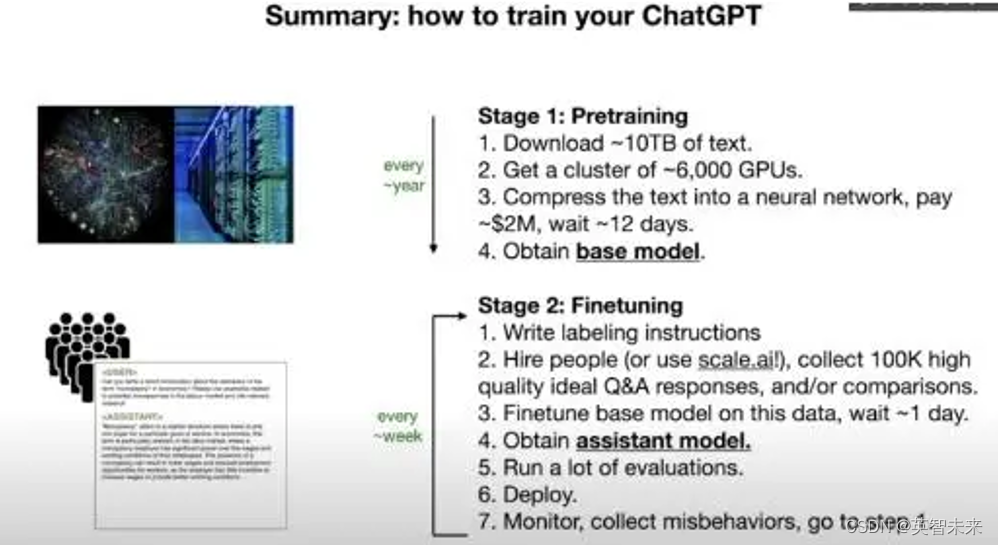
比如,如果我们想让LLM在医疗咨询中表现得更好,我们可能会选择医疗相关的对话和文本作为训练数据,包括医学论文、病例报告、医生和患者之间的对话记录等。通过专注于这些特定类型的数据,LLM能够更深入地理解医学术语、诊疗过程和病患交流的特点。这不仅增强了模型在处理医疗相关查询时的准确性,也使其能够更贴近实际的医疗场景需求。
随着技术的进步,LLM正在逐步成为一种更加智能和适应性强的工具。从自动写作、聊天机器人到语言翻译和情感分析,甚至在程序代码生成等技术领域都有显著应用。这些模型能够根据特定的需求生成高质量的文本,或理解复杂的语言输入。通过深入理解这些模型的工作原理和应用,我们可以更好地利用它们的能力,为未来创造更多可能。

