
- 1【特纳斯电子】基于单片机的智能衣柜-实物设计_单片机智能衣柜实物
- 2关于tomcat 报错 找不到oracle.jdbc.driver.OracleDriver 的解决办法_tomcat class not found oracle.jdbc.driver.oracledr
- 3教你删除Mac下的iCloud数据_m2芯片系统桌面有icloud数据怎么删除
- 4TypeError: forward() got an unexpected keyword argument ‘label‘_got an unexpected keyword argument 'laber
- 5改造你的AI服务器——AI容器化简明教程(四)具体使用_nvidia_visible_devices
- 6腾讯弱网络测试工具QNET申请试用_qnet不能用了,现在用什么
- 7Docker 基础实战教程:入门_头歌docker基础实战教程一:入门
- 83d Object
- 9C++实验九 数组程序设计(一)_输入一个正整数n,再输入n个整数,存入数组a中,先将数组a中的这n个数逆序存放,
- 10AI工程师的笔记本环境配置_运行ai 大模型 macbook配置
HashMap底层实现原理解析
赞
踩
一、HashMap底层实现原理解析
我们常见的有数据结构有三种结构:
- 数组结构
- 链表结构
- 哈希表结构
下面我们来看看各自的数据结构的特点:
1)数组结构: 存储区间连续、内存占用严重、空间复杂度大
优点:随机读取和修改效率高,原因是数组是连续的(随机访问性强,查找速度快)
缺点:插入和删除数据效率低,因插入数据,这个位置后面的数据在内存中都要往后移动,且大小固定不易动态扩展。
2)链表结构:存储区间离散、占用内存宽松、空间复杂度小
优点:插入删除速度快,内存利用率高,没有固定大小,扩展灵活
缺点:不能随机查找,每次都是从第一个开始遍历(查询效率低)
3)哈希表结构:结合数组结构和链表结构的优点,从而实现了查询和修改效率高,插入和删除效率也高的一种数据结构
HashMap底层是哈希表结构
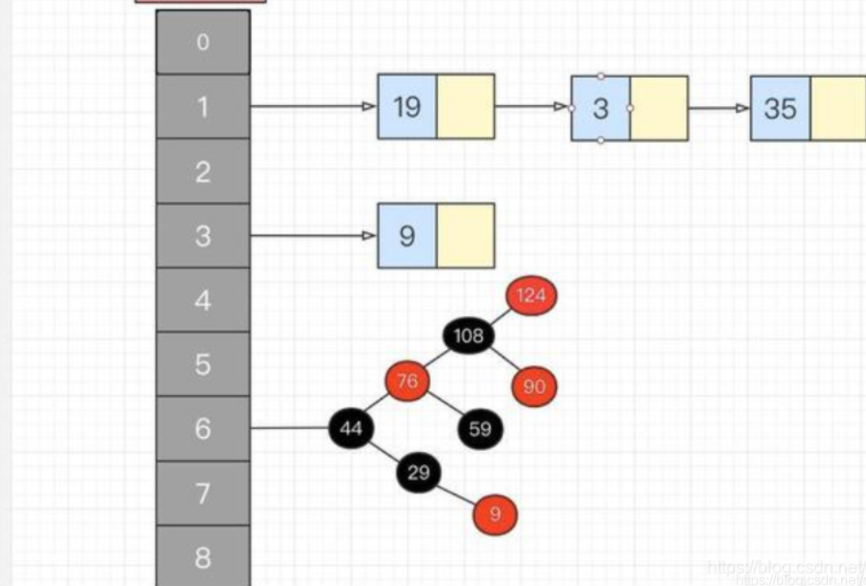 HashMap中的put()和get()的实现原理:
HashMap中的put()和get()的实现原理:
1)map.put(k,v)实现原理
(1)首先将k,v封装到Node对象当中(节点)。
(2)然后它的底层会调用K的hashCode()方法得出hash值。
(3)通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
2、map.get(k)实现原理
(1)先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
(2)通过上一步哈希算法转换成数组的下标之后,在通过数组下标快速定位到某个位置上。如果这个位置上什么都没有,则返回null。如果这个位置上有单向链表,那么它就会拿着K和单向链表上的每一个节点的K进行equals,如果所有equals方法都返回false,则get方法返回null。如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
为何随机增删、查询效率都很高的原因是?
增删是在链表上完成的,而查询只需扫描部分,则效率高。
HashMap集合的key,会先后调用两个方法,hashCode and equals方法,这这两个方法都需要重写。
为什么放在hashMap集合key部分的元素需要重写equals方法?
因为equals方法默认比较的是两个对象的内存地址
二、HashMap红黑树原理分析
相比 jdk1.7 的 HashMap 而言,jdk1.8最重要的就是引入了红黑树的设计,红黑树除了插入操作慢其他操作都比链表快,当hash表的单一链表长度超过 8 个的时候,数组长度大于64,链表结构就会转为红黑树结构。当红黑树上的节点数量小于6个,会重新把红黑树变成单向链表数据结构。
为什么要这样设计呢?好处就是避免在最极端的情况下链表变得很长很长,在查询的时候,效率会非常慢。

- 红黑树查询:其访问性能近似于折半查找,时间复杂度 O(logn);
- 链表查询:这种情况下,需要遍历全部元素才行,时间复杂度 O(n);
简单的说,红黑树是一种近似平衡的二叉查找树,其主要的优点就是“平衡“,即左右子树高度几乎一致,以此来防止树退化为链表,通过这种方式来保障查找的时间复杂度为 log(n)。
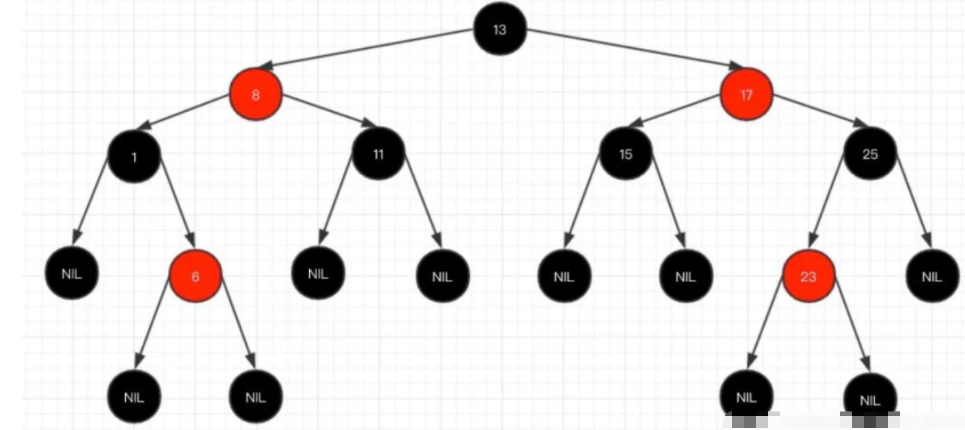
关于红黑树的内容,网上给出的内容非常多,主要有以下几个特性:
1、每个节点要么是红色,要么是黑色,但根节点永远是黑色的;
2、每个红色节点的两个子节点一定都是黑色;
3、红色节点不能连续(也即是,红色节点的孩子和父亲都不能是红色);
4、从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;
5、所有的叶节点都是是黑色的(注意这里说叶子节点其实是上图中的 NIL 节点);
在树的结构发生改变时(插入或者删除操作),往往会破坏上述条件 3 或条件 4,需要通过调整使得查找树重新满足红黑树的条件。
三、HashMap的原理1.7 和1.8 的区别
- jdk1.7中底层是由数组+链表实现;jdk1.8中底层是由数组+链表/红黑树实现
- 可以存储null键和null值,线程不安全
- 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
- 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
- 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀
hash冲突
当两个key通过hashCod计算相同时(其实hashCode是随机产生的,是有可能hashCode相同),则发生了hash冲突,开放定址法、再哈希法、链地址法、建立公共溢出区
HashMap解决hash冲突的方式是用链表。当发生hash冲突时,则将存放在数组中的Entry设置为新值的next,说白就是比如A和B都hash后都映射到下标i中,之前已经有A了,当map.put(B)时,将B放到下标i中,A则为B的next,所以新值存放在数组中,旧值在新值的链表上
- 开放定址法:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中
- 再哈希法:同时构造多个不同的哈希函数,当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。
- 链地址法:这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
- 建立公共溢出区:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
- ability_main.xml代码:
[详细] -->赞
踩

