
- 1C#个人珍藏基础类库分享 — 8、通用工具帮助类ToolHelper_c# 常用类库
- 2经济地理学复习要点总结(完整)_区位条件和区位因子的区别
- 3鸿蒙DevEco开发模拟器无法启动问题_鸿蒙模拟器启动失败
- 4node-red连接mysql数据库,进行数据的传输存储_nodered+数据库批量导入数据
- 5(Java企业 / 公司项目)微服务Sentinel限流如何使用?_java sentinel限流
- 6超详细Windows10/Windows11 子系统(WSL2)安装Ubuntu20.04(带桌面环境)_wsl安装ubuntu20.04
- 7收藏!TikTok下载&注册教程 苹果/安卓/鸿蒙版详细步骤_收藏!tiktok下载&注册教程 苹果/安卓/鸿蒙版详细步骤
- 8springboot 订单重复提交_Spring Boot (一) 校验表单重复提交
- 9自定义View之多点触控之双指放大与缩小_多点触控缩放 算法
- 10【AWS系列】第四讲:什么是 AWS Serverless
分布式事务的几种解决方案
赞
踩
一.基础概念
1. 什么是事务
事务可以看做是一次大的活动,它由不同的小活动组成,这些活动 要么全部成功, 要么全部失败
2.本地事务
在计算机系统中,更多的是通过 关系型数据库来控制事务,这是利用数据库 本身的事务特性来实现的,因此叫 数据库事务,由于应用主要靠关系数据库来控制事务,而数据库通常和应用在同一个服务器,所以基于关系型数据库的事务又被称为 本地事务
3.数据库事务的四大特性:ACID
A(Atomic):原子性
构成事务的所有操作,要么 都执行完成,要么 全部不执行,不可能出现部分成功部分失败的情况
C(Consistency):一致性
在事务执行前后,数据库的 一致性约束没有被破坏。比如:张三向李四转 100 元,转账前和转账后的数据是正确状态这叫一致性,如果出现张三转出 100 元,李四账户没有增加 100 元这就出现了数 据错误,就没有达到一致性
I(Isolation):隔离性
数据库中的事务一般都是并发的,隔离性是指 并发的两个事务的执行互不干扰,一个事务不能看到其他事务的运行过程的中间状态。通过配置 事务隔离级别可以避免脏读、重复读问题
D(Durability):持久性
事务完成之后,该事务对数据的更改会持久到数据库,且不会被回滚
总结:
数据库事务在实现时会将一次事务的所有操作全部纳入到一个不可分割的执行单元,该执行单元的所有操作要么都成功,要么都失败,只要其中任一操作执行失败,都将导致整个事务的回滚
4. 分布式事务
随着互联网的快速发展,软件系统由原来的单体应用转变为分布式应用,分布式事务顾名思义就是要在 分布式系统中实现事务,它其实是由 多个本地事务组合而成。对于分布式事务而言几乎满足不了 ACID,其实对于单机事务而言大部分情况下也没有满足 ACID,不然怎么会有 四种隔离级别呢?所以更别说分布在不同数据库或者不同应用上的分布式事务了
(1).单体应用向微服务的演变
随着互联网的发展,互联网企业的业务也在不断的飞速发展,进而导致系统的架构也在不断的发生着变化。总体来说,系统的架构大致经历了: 单体应用架构—>垂直应用架构—>分布式架构—>SOA架构—>微服务架构的演变。 当然,很多互联网企业的系统架构已经向Service Mesh(服务化网格)演变
1).单体应用架构
互联网早期,一般的网站应用流量较小,只需要一个应用,将所有的功能代码打包成一个服务,部署到服务器上就能支撑公司的业务。这样也能够减少开发、部署和维护的成本
比如在电商系统中涉及的业务主要有:用户管理、商品管理、订单管理、支付管理、库存管理、物流管理等等模块,初期会将所有模块写到一个Web项目中,然后统一部署到一个nignx服务器中
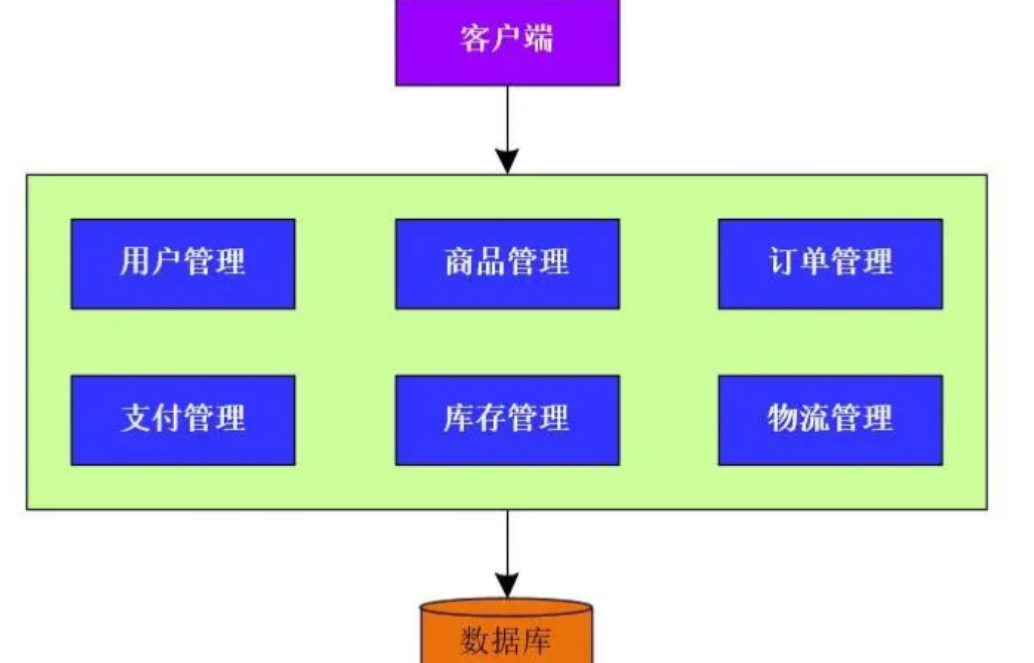
单体应用架构的优点:
a.架构简单,适用于小型项目,项目开发和维护成本低
b.所有项目模块部署到一起,对于小型项目来说,维护方便
其缺点也是比较明显的:
a.所有模块耦合在一起,虽然对于小型项目来说,维护方便。但是,对于大型项目来说,却是不易开发和维护的
b.项目的各模块之间过于耦合,如果一旦有一个模块出现问题,则整个项目将不可用(容错率低)
c.无法针对某个具体模块来提升性能
d.无法对项目进行水平扩展
正是由于单体应用架构存在着诸多的缺点,才逐渐演变为 垂直应用架构
2).垂直应用架构
随着企业业务的不断发展,发现单节点的单体应用 不足以支撑业务的发展,于是企业会将单体应用部署多份,分别放在 不同的服务器上。但是,此时会发现不是所有的模块都会有比较大的访问量。如果想针对项目中的 某些模块进行 优化和 性能提升,此时对于单体应用来说,是做不到的。于是垂直应用架构诞生了。
垂直应用架构就是将原来一个项目应用进行 拆分,将其拆分为 互不想干的几个应用,以此来 提升系统的整体性能。这里,同样以电商系统为例,在垂直应用架构下,可以将整个电商项目拆分为:电商交易系统、后台管理系统、CMS管理系统等
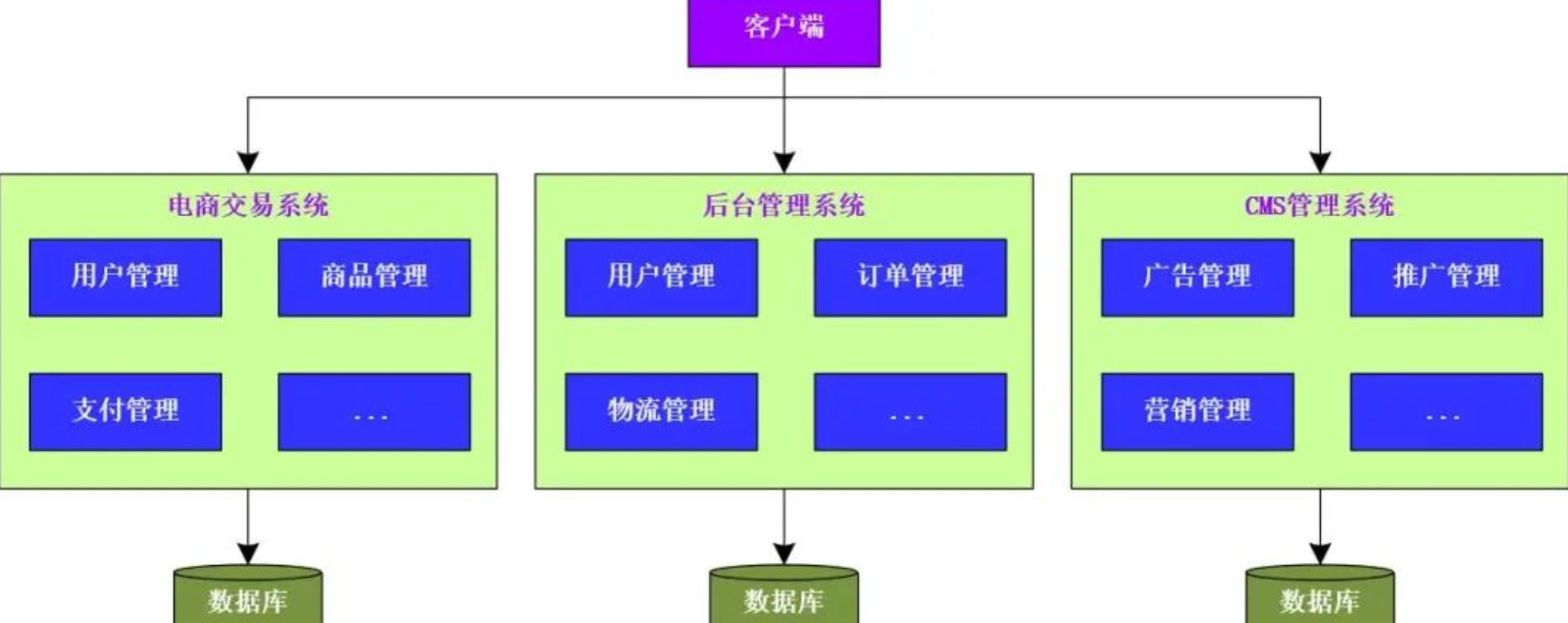
将单体应用架构拆分为垂直应用架构之后,一旦访问量变大,我们只需要针对访问量大的业务增加服务器节点即可,无需针对整个项目增加服务器节点了
架构的优点:
a.系统进行了拆分,可根据不同系统的访问情况,有针对性的进行优化
b.能够实现应用的水平扩展
c.各系统能够分担整体访问的流量,解决了并发问题
d.一个系统发生了故障,不应用其他系统的运行情况,提高了整体的容错率
架构的缺点:
a.拆分后的各系统之间相对比较独立,无法进行互相调用
b.各系统难免存在重叠的业务,会存在重复开发的业务,后期维护比较困难
3).分布式架构
系统演变为垂直应用架构之后,当垂直应用越来越多,重复编写的业务代码就会越来越多。此时,需要将 重复的代码抽象出来,形成 统一的服务供其他系统或者业务模块来进行调用。此时,系统就会演变为 分布式架构,在分布式架构中,会将系统整体拆分为 服务层和 表现层。服务层封装了 具体的业务逻辑供表现层调用,表现层则负责处理与页面的 交互操作
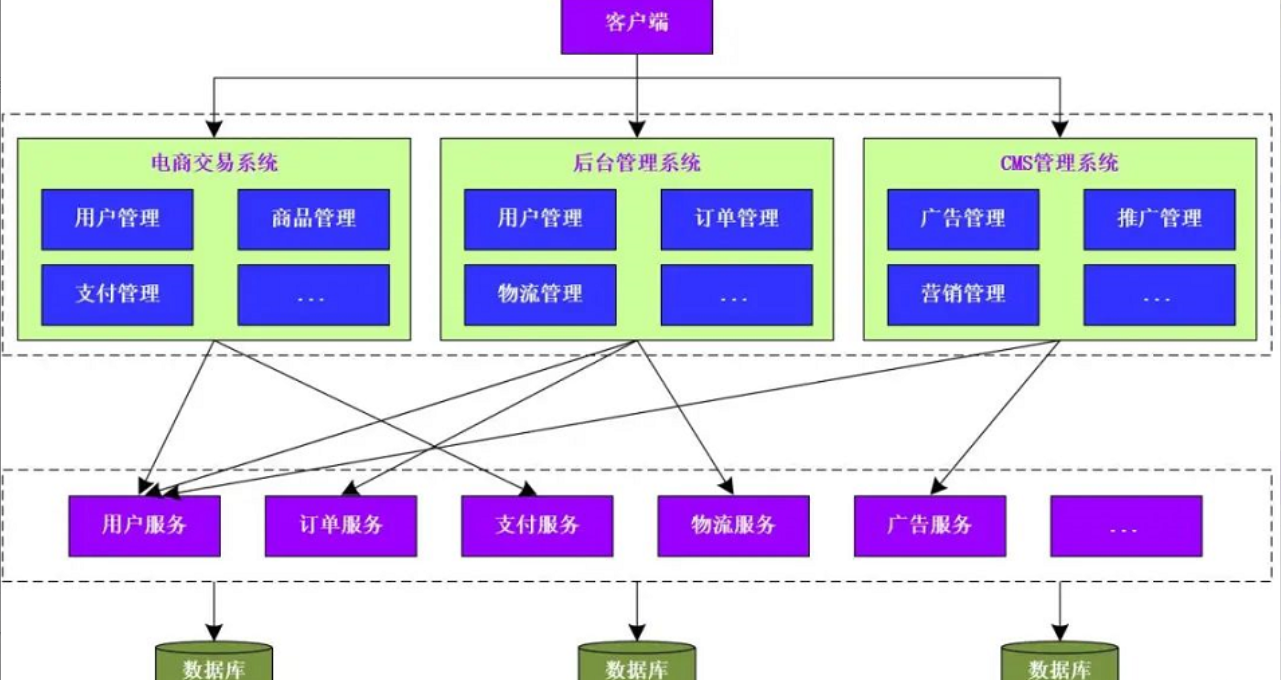
架构的优点:
a.将重复的业务代码抽象出来,形成公共的访问服务,提高了代码的复用性
b.可以有针对性的对系统和服务进行性能优化,以提升整体的访问性能
架构的缺点:
a.系统之间的耦合度变高,调用关系变得复杂,难以维护
4).SOA架构
在分布式架构下,当部署的服务越来越多,重复的代码就会越来越多,对于容量的评估,小服务资源的浪费等问题比较严重。此时,就需要增加一个统一的调度中心来对集群进行实时管理。此时,系统就会演变为SOA(面向服务)的架构
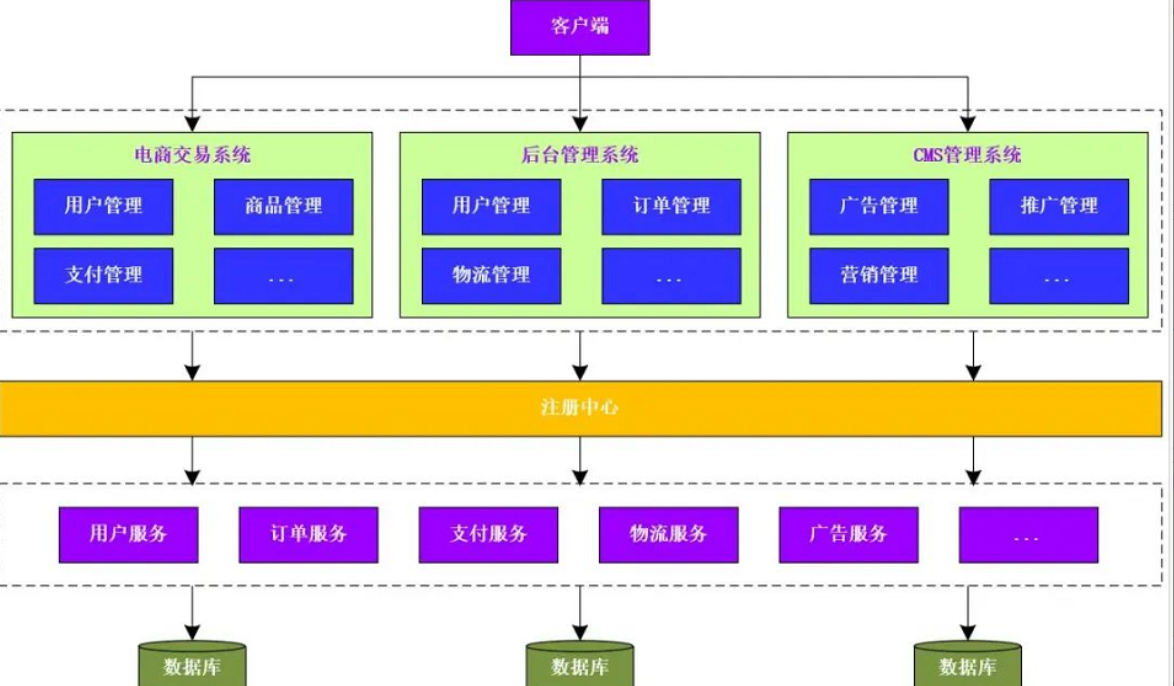
架构的优点:
a.使用注册中心解决了各个服务之间的服务依赖和调用关系的自动注册与发现
架构的缺点:
a.各服务之间存在依赖关系,如果某个服务出现故障可能会造成服务的雪崩的问题
b.服务之间的依赖与调用关系复杂,测试部署的困难比较大
5).微服务架构
随着业务的发展,在SOA架构的基础上进一步扩展,将其彻底拆分为 微服务架构,在微服务架构下,将一个大的项 目拆分为一个个小的可以 独立部署的微服务,每个微服务都有 自己的数据库

微服务架构与SOA架构的不同
微服务架构比SOA架构 粒度更加精细,让专业的人去做专业的事提高开发效率,服务与服务之间 相互不影响。微服务架构中,每个服务 独立治理, 部署, 维护,微服务架构 更加轻巧,轻量级.SOA架构中可能数据库存储会发生共享,微服务强调 每个服务都是单独的数据库,保证每个服务与服务之间互不影响。项目体现特征微服务架构比SOA架构更适合于互联网公司敏捷开发,快速版本迭代因为粒度非常精细
架构的优点:
a.服务彻底拆分,各服务独立打包、独立部署和独立升级
b.每个微服务负责的业务比较清晰,利于后期扩展和维护
c.微服务之间可以采用Restful和RPC轻量级协议进行通信
架构的缺点:
a.开发的成本比较高
b.涉及到各服务的容错性问题
c.涉及到数据的一致性问题
d.涉及到分布式事务问题
(2).分布式事务概念说明
分布式系统会把一个应用系统拆分为可独立部署的多个服务,因此需要服务与服务之间 远程协作才能完成 事务操作,这种分布式系统环境下由不同的服务之间通过 网络远程协作完成 事务称之为 分布式事务,例如:用户注册送积分事务、创建订单减库存事务,银行转账事务等都是分布式事务,必须要 「保证不同服务状态结果的一致性」。本地事务依赖数据库本身提供的事务特性来实现,因此以下逻辑可以控制本地事务:
<code class="language-plaintext hljs">begin transaction;
//1.本地数据库操作:张三减少金额
//2.本地数据库操作:李四增加金额
commit transation;</code>但是在分布式环境下,会变成下边这样:
<code class="language-plaintext hljs">begin transaction;
//1.本地数据库操作:张三减少金额
//2.远程调用:让李四增加金额
commit transation;</code>可以设想,当远程调用让李四增加金额成功了,由于网络问题远程调用并没有返回,此时本地事务提交失败就回滚了张三减少金额的操作,此时张三和李四的数据就不一致了
因此在分布式架构的基础上,传统数据库事务就无法使用了,张三和李四的账户不在一个数据库中甚至不在一个应用系统里,实现转账事务需要通过远程调用,由于网络问题就会导致分布式事务问题
(3). 分布式事务产生的情景
1).跨JVM进程产生分布式事务
典型的场景就是微服务架构:微服务之间通过 远程调用完成事务操作。比如:订单微服务和库存微服务,下单的同时订单微服务请求库存微服务减少库存

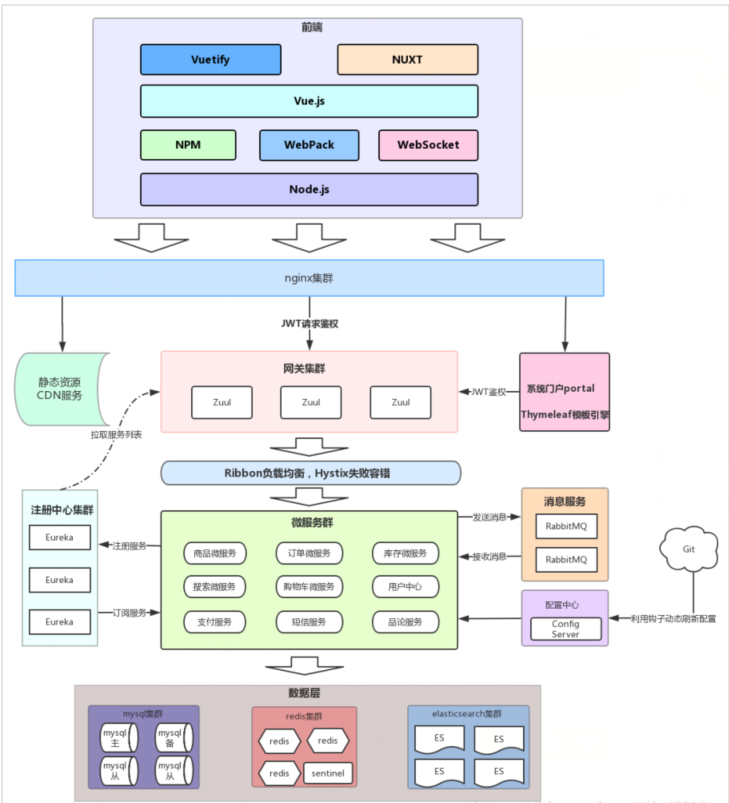
2).跨数据库实例产生分布式事务
单体系统访问多个数据库实例:当单体系统需要访问多个数据库(实例)时就会产生分布式事务。比如:用户信息和订单信息分别在两个MySQL实例存储,用户管理系统删除用户信息,需要分别删除用户信息及用户的订单信息,由于数据分布在不同的数据实例,需要通过不同的数据库链接去操作数据,此时产生分布式事务
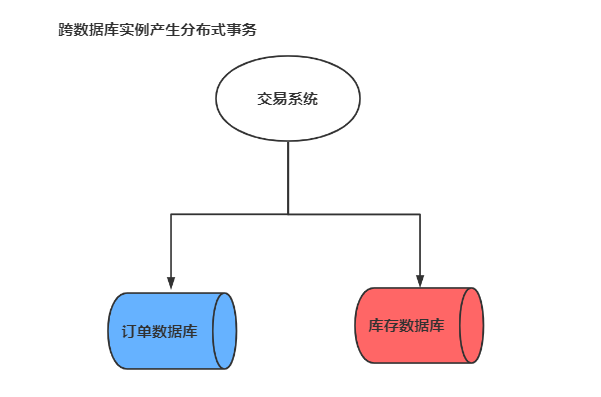
3).多服务访问同一个数据库实例
订单微服务和库存微服务即使访问同一个数据库也会产生分布式事务,原因就是 跨JVM进程,两个微服务持有了不同的数据库链接进行数据库操作,此时产生分布式事务
5. 分布式事务基础理论
通过前面的学习,了解到了分布式事务的基础概念。与本地事务不同的是,分布式系统之所以叫分布式,是因为提供服务的各个节点分布在不同机器上,相互之间通过 网络交互,不能因为有一点网络问题就导致整个系统无法提供服务, 网络因素成为了分布式事务的考量标准之一,因此,分布式事务需要更进一步的理论支持
(1).CAP理论
1).理解CAP
CAP 是 Consistency、Availability、Partition tolerance 三个单词的缩写,分别表示 一致性、 可用性、分区容忍性.为了方便对CAP理论的理解,结合电商系统中的一些业务场景来理解CAP
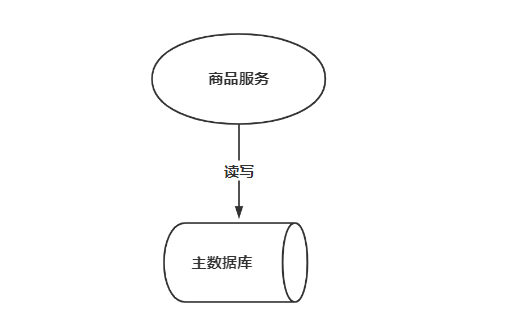
如下图,是商品信息管理的执行流程:
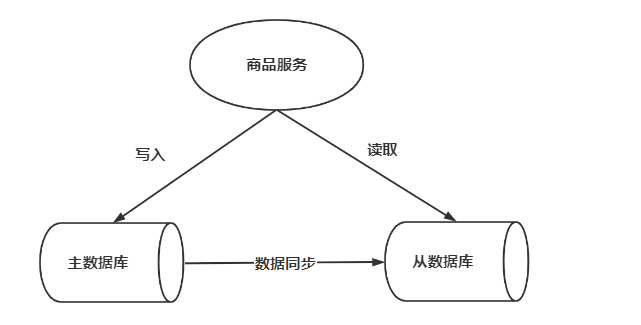
整体执行流程如下
a.商品服务请求主数据库写入商品信息(添加商品、修改商品、删除商品)
b.主数据库向商品服务响应写入成功
c.商品服务请求从数据库读取商品信息
C - Consistency
一致性是指写操作后的读操作可以读取到最新的数据状态,当数据分布在多个节点上,从任意结点读取到的数据都是 最新的状态
上图中,商品信息的读写要满足一致性就是要实现如下目标:
-
商品服务写入主数据库成功,则向从数据库查询新数据也成功
-
商品服务写入主数据库失败,则向从数据库查询新数据也失败
如何实现一致性?
-
写入主数据库后要将数据同步到从数据库
-
写入主数据库后,在向从数据库同步期间要将从数据库锁定,待同步完成后再释放锁,以免在新数据写入成功后,向从数据库查询到旧的数据
分布式系统一致性的特点:
-
由于存在数据同步的过程,写操作的响应会有一定的延迟
-
为了保证数据一致性会对资源暂时锁定,待数据同步完成释放锁定资源
-
如果请求数据同步失败的结点则会返回错误信息,一定不会返回旧数据
A - Availability
可用性是指任何事务操作都可以得到 响应结果,且不会出现响应超时或响应错误,也就是在集群中一部分节点 「故障」后,集群整体 「是否还能响应」客户端的读写请求。(对数据更新具备高可用性)
上图中,商品信息读取满足可用性就是要实现如下目标:
-
从数据库接收到数据查询的请求则立即能够响应数据查询结果
-
从数据库不允许出现响应超时或响应错误
如何实现可用性?
-
写入主数据库后要将数据同步到从数据库
-
由于要保证从数据库的可用性,不可将从数据库中的资源进行锁定
-
即时数据还没有同步过来,从数据库也要返回要查询的数据,哪怕是旧数据,如果连旧数据也没有则可以按照约定返回一个默认信息,但不能返回错误或响应超时
分布式系统可用性的特点:
-
所有请求都有响应,且不会出现响应超时或响应错误,也就是当单个组件无法可用,操作依然可以完成
P - Partition tolerance
通常分布式系统的各各结点部署在 不同的子网,这就是 网络分区,不可避免的会出现由于 网络问题而导致结点之间 通信失败,此时仍可对外提供服务,这叫 分区容忍性
上图中,商品信息读写满足分区容忍性就是要实现如下目标:
-
主数据库向从数据库同步数据失败不影响读写操作
-
其一个结点挂掉不影响另一个结点对外提供服务
如何实现分区容忍性?
-
尽量使用异步取代同步操作,例如使用异步方式将数据从主数据库同步到从数据,这样结点之间能有效的实现松耦合
-
添加从数据库结点,其中一个从结点挂掉其它从结点提供服务
分布式分区容忍性的特点:
-
分区容忍性分是布式系统具备的基本能力
2).CAP组合方式
上边商品管理的例子是否 同时具备 CAP 呢?
在所有分布式事务场景中 不会同时具备 CAP 三个特性,因为在具备了P的前提下C和A是不能共存的
比如,下图满足了P即表示实现分区容忍:

本图分区容忍的含义是:
a.主数据库通过网络向从数据库同步数据,可以认为主从数据库部署在不同的分区,通过网络进行交互
b.当主数据库和从数据库之间的网络出现问题不影响主数据库和从数据库对外提供服务
c.其中一个节点挂掉不影响另一个节点对外提供服务
如果要实现 C 则必须保证 数据一致性,在数据同步的时候为防止向从数据库查询不一致的数据则需要将从数据库数据锁定,待同步完成后解锁,如果同步失败从数据库要返回错误信息或超时信息。
如果要实现 A 则必须保证 数据可用性,不管任何时候都可以向从数据查询数据,则不会响应超时或返回错误信息。通过分析发现在 满足P的前提下 C 和 A 存在矛盾性
所以在生产中对分布式事务处理时要根据需求来确定满足 CAP 的哪两个方面?
I.AP
放弃一致性,追求分区容忍性和可用性,这是很多分布式系统设计时的选择。
例如:上边的商品管理,完全可以实现 AP,前提是只要用户可以接受所查询到的数据在一定时间内不是最新的即可。
通常实现 AP 都会保证 最终一致性,后面将的 BASE 理论就是根据 AP 来扩展的,一些业务场景比如:订单退款,今日退款成功,明日账户到账,只要用户可以接受在一定的时间内到账即可
II.CP
放弃可用性,追求一致性和分区容错性,zookeeper 其实就是追求的强一致,又比如 跨行转账,一次转账请求要等待双方银行系统都完成整个事务才算完成
III.CA
放弃分区容忍性,即不进行分区,不考虑由于网络不通或结点挂掉的问题,则可以实现一致性和可用性。那么系统将不是一个标准的分布式系统, 最常用的关系型数据就满足了 CA
上边的商品管理,如果要实现 CA 则架构如下:
主数据库和从数据库中间不在进行数据同步,数据库可以响应每次的查询请求,通过事务隔离级别实现每个查询请求都可以返回最新的数据
3). 总结
CAP 是一个已经被证实的理论, 一个分布式系统最多只能同时满足:一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance)这 三项中的两项。它可以作为进行架构设计、技术选型的考量标准,对于多数大型互联网应用的场景,结点众多、部署分散,而且现在的集群规模越来越大,所以 节点故障、 网络故障是常态,而且要保证服务可用性达到 N 个 9(99.99..%),并要达到良好的响应性能来提高用户体验,因此一般都会做出如下选择: 保证 P 和 A , 舍弃 C 强一致,保证最终一致性
(2). BASE 理论
1).强一致性和最终一致性
CAP 理论告诉我们一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance)这三项中的两项,其中AP在实际应用中较多,AP 即舍弃一致性,保证可用性和分区容忍性,但是在实际生产中很多场景都要实现一致性,比如前边我们举的例子主数据库向从数据库同步数据,即使不要一致性,但是最终也要将数据同步成功来保证数据一致,这种一致性和 CAP 中的一致性不同,CAP 中的一致性要求 在任何时间查询每个结点数据都必须一致,它强调的是强一致性,但是最终一致性是允许可以在一段时间内每个结点的数据不一致,但是经过一段时间每个结点的数据必须一致,它强调的是最终数据的一致性
2).Base 理论介绍
BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写。BASE 理论是对 CAP 中 AP 的一个扩展,通过牺牲强一致性来获得可用性,当出现故障允许部分不可用但要保证核心功能可用,允许数据在一段时间内是不一致的,但最终达到一致状态。满足BASE理论的事务,我们称之为“柔性事务”
-
基本可用:分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。如电商网站交易付款出现问题了,商品依然可以正常浏览
-
软状态:由于不要求强一致性,所以BASE允许系统中存在中间状态(也叫软状态),这个状态不影响系统可用性,如订单的"支付中"、“数据同步中”等状态,待数据最终一致后状态改为“成功”状态
-
最终一致:最终一致是指经过一段时间后,所有节点数据都将会达到一致。如订单的"支付中"状态,最终会变 为“支付成功”或者"支付失败",使订单状态与实际交易结果达成一致,但需要一定时间的延迟、等待
下面介绍分布式事务的几种解决方案
分布式场景业界常见的解决方案有 2PC、3PC、TCC、可靠消息最终一致性、最大努力通知这几种。
二.2PC(两阶段提交)
1.简介
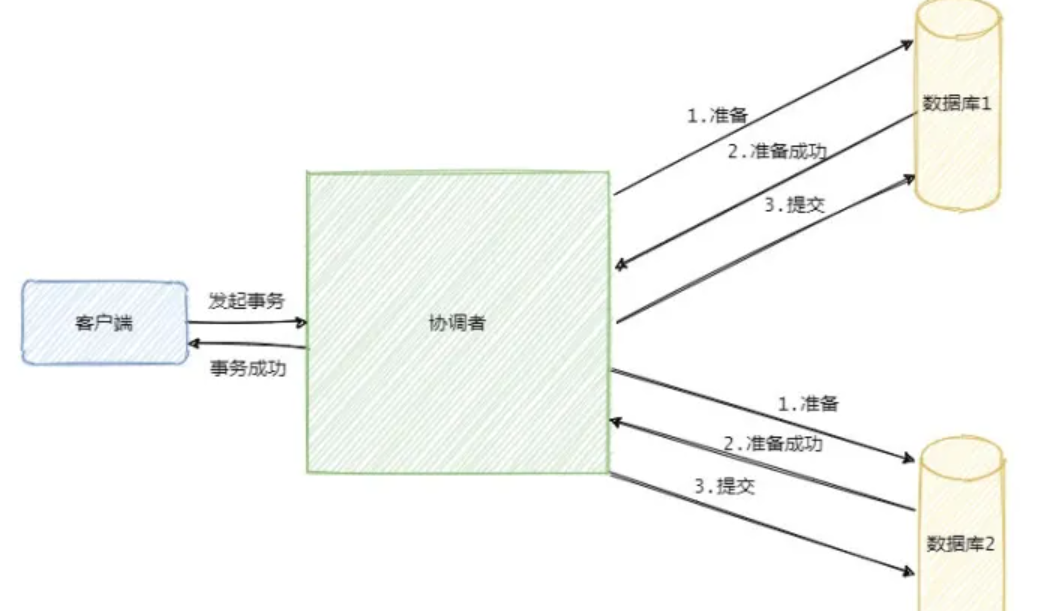
2PC(Two-phase commit protocol),中文叫两阶段提交, 两阶段提交是一种强一致性设计,2PC 引入一个 事务协调者((Coordinator))的角色来 协调管理各参与者(也可称之为各本地资源)的行为( 提交和回滚),并最终决定这些参与者是否要真正执行事务.
两阶段是将整个事务流程分为两个阶段:分别指的是 准备阶段(Prepare phase)和 提交阶段(commitphase)两个阶段, 2是指两个阶段, P是指准备阶段, C是指提交阶段。 注意:这只是协议或者说是理论指导,只阐述了大方向,具体落地还是有会有差异的
2.举个栗子说明
张三和李四好久不见,老友约起聚餐,饭店老板要求先买单,才能出票,这时张三和李四分别抱怨近况不如意,囊中羞涩,都不愿意请客,这时只能AA。只有张三和李四都付款,老板才能出票安排就餐。但由于张三和李四都是铁公鸡,形成了尴尬的一幕:
准备阶段:老板要求张三付款,张三付款,老板要求李四付款,李四付款。
提交阶段:老板出票,两人拿票纷纷落座就餐。
例子中形成了一个事务,若张三或李四其中一人拒绝付款,或钱不够,店老板都不会给出票,并且会把已收款退回。
整个事务过程由事务管理器和参与者组成,店老板就是事务管理器,张三、李四就是事务参与者,事务管理器负责决策整个分布式事务的提交和回滚,事务参与者负责自己本地事务的提交和回滚
在计算机中部分关系数据库如Oracle、MySQL支持两阶段提交协议,如下:
-
准备阶段(Prepare phase):事务管理器给每个参与者发送Prepare消息,每个数据库参与者在本地执行事务,并写本地的Undo/Redo日志,此时事务没有提交。(Undo日志是记录修改前的数据,用于数据库回滚,Redo日志是记录修改后的数据,用于提交事务后写入数据文件)
-
提交阶段(commit phase):如果事务管理器收到了参与者的执行失败或者超时消息时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据事务管理器的指令执行提交或者回滚操作,并释放事务处理过程中使用的锁资源。
注意:必须在最后阶段释放锁资源
3.图示说明
下图展示了2PC的两个阶段
两阶段提交总的图示
成功情况

失败情况
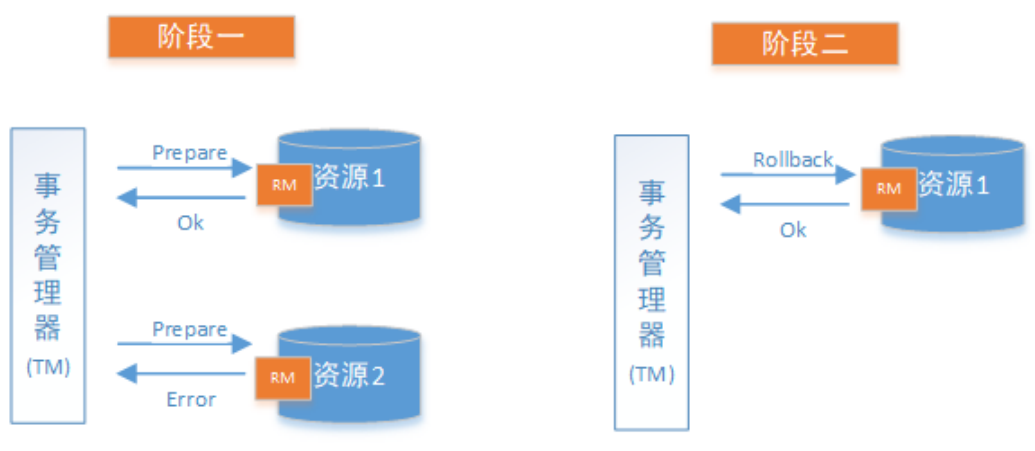
上面图解了两阶段总的提交图示,在这里具体分析每个阶段的情况
准备阶段(Prepare phase)
在 准备阶段所有参与者都返回准备成功,那么协调者则向所有参与者发送 提交事务命令,然后等待所有事务都提交成功之后,返回事务执行成功.
假如在 准备阶段有一个参与者返回失败,那么协调者就会向所有参与者发送回滚事务的请求,即分布式事务执行失败
成功情况
失败情况

4. 第二阶段提交失败的情况
(1).如果在第二阶段执行的是回滚事务操作
那么答案是 不断重试,直到所有参与者都回滚了,不然那些在第一阶段准备成功的参与者会一直 阻塞着
(2).如果第二阶段执行的是提交事务操作
那么答案也是不断重试,因为有可能一些参与者的事务已经提交成功了,这个时候只有一条路,就是头铁往前冲, 不断的重试,直到提交成功,到最后真的不行只能 人工介入处理
5.分析
首先 2PC 是一个同步阻塞协议,像第一阶段协调者会等待所有参与者响应才会进行下一步操作,当然第一阶段的协调者有超时机制,假设因为网络原因没有收到某参与者的响应或某参与者挂了,那么超时后就会判断事务失败,向所有参与者发送回滚命令。在第二阶段协调者的没法超时,只能不断重试
6.协调者故障分析
首先协调者是一个 单点 ,存在 单点故障 问题
(1). 假设协调者在发送准备命令之前挂了,这时事务还没开始,没啥毛病,假设协调者在发送准备命令之后挂了,这就出问题了,因为有些参与者执行了处于事务资源锁定的状态,不仅事务执行不下去,还会因为锁定了一些公共资源而阻塞系统其它操作。
(2). 假设协调者在发送回滚事务命令之前挂了,那么事务也是执行不下去,且在第一阶段那些准备成功参与者都阻塞着。
(3). 假设协调者在发送回滚事务命令之后挂了,这个还行,至少命令发出去了,很大的概率都会回滚成功,资源都会释放。但是如果出现网络分区问题,某些参与者将因为收不到命令而阻塞着。
(4). 假设协调者在发送提交事务命令之前挂了,这个不行,这下是所有资源都阻塞着。
(5). 假设协调者在发送提交事务命令之后挂了,这个还行,也是至少命令发出去了,很大概率都会提交成功,然后释放资源,但是如果出现网络分区问题某些参与者将因为收不到命令而阻塞着。
7.协调者故障,通过选举得到新协调者
因为协调者单点问题,因此可以通过选举等操作选出一个新协调者来顶替。
如果处于第一阶段,其实影响不大都回滚好了,在第一阶段事务肯定还没提交。如果处于第二阶段,假设参与者都没挂,此时新协调者可以向所有参与者确认它们自身情况来推断下一步的操作。
假设有个别参与者挂了!这就有点不好办了,比如协调者发送了回滚命令,此时第一个参与者收到了并执行,然后协调者和第一个参与者都挂了。
此时其他参与者都没收到请求,然后新协调者来了,它询问其他参与者都说OK,但它不知道挂了的那个参与者到底O不OK,所以它傻了。问题其实就出在每个参与者自身的状态只有自己和协调者知道,因此新协调者无法通过在场的参与者的状态推断出挂了的参与者是什么情况。虽然协议上没说,不过在实现的时候我们可以灵活的让协调者将自己发过的请求在哪个地方记一下,也就是日志记录,这样新协调者来的时候不就知道此时该不该发了?
但是就算协调者知道自己该发提交请求,那么在参与者也一起挂了的情况下没用,因为你不知道参与者在挂之前有没有提交事务。如果参与者在挂之前事务提交成功,新协调者确定存活着的参与者都没问题,那肯定得向其他参与者发送提交事务命令才能保证数据一致。如果参与者在挂之前事务还未提交成功,参与者恢复了之后数据是回滚的,此时协调者必须是向其他参与者发送回滚事务命令才能保持事务的一致。所以说极端情况下还是无法避免数据不一致问题。下面来看一个代码:这个代码就是实现了 2PC,但是相比于2PC增加了写日志的动作、参与者之间还会互相通知、参与者也实现了超时。这里要注意,一般所说的2PC,不含上述功能,这都是实现的时候添加的。
<code class="language-plaintext hljs">协调者:
write START_2PC to local log; //开始事务
multicast VOTE_REQUEST to all participants; //广播通知参与者投票
while not all votes have been collected {
wait for any incoming vote;
if timeout { //协调者超时
write GLOBAL_ABORT to local log; //写日志
multicast GLOBAL_ABORT to all participants; //通知事务中断
exit;
}
record vote;
}
//如果所有参与者都ok
if all participants sent VOTE_COMMIT and coordinator votes COMMIT {
write GLOBAL_COMMIT to local log;
multicast GLOBAL_COMMIT to all participants;
} else {
write GLOBAL_ABORT to local log;
multicast GLOBAL_ABORT to all participants;
}
参与者:
write INIT to local log; //写日志
wait for VOTE_REQUEST from coordinator;
if timeout { //等待超时
write VOTE_ABORT to local log;
exit;
}
if participant votes COMMIT {
write VOTE_COMMIT to local log; //记录自己的决策
send VOTE_COMMIT to coordinator;
wait for DECISION from coordinator;
if timeout {
multicast DECISION_REQUEST to other participants; //超时通知
wait until DECISION is received; /* remain blocked*/
write DECISION to local log;
}
if DECISION == GLOBAL_COMMIT
write GLOBAL_COMMIT to local log;
else if DECISION == GLOBAL_ABORT
write GLOBAL_ABORT to local log;
} else {
write VOTE_ABORT to local log;
send VOTE_ABORT to coordinator;
}
每个参与者维护一个线程处理其它参与者的DECISION_REQUEST请求:
while true {
wait until any incoming DECISION_REQUEST is received;
read most recently recorded STATE from the local log;
if STATE == GLOBAL_COMMIT
send GLOBAL_COMMIT to requesting participant;
else if STATE == INIT or STATE == GLOBAL_ABORT;
send GLOBAL_ABORT to requesting participant;
else
skip; /* participant remains blocked */
}</code>8.总结
(1).PC 是一种尽量保证强一致性的分布式事务,因此它是同步阻塞的,而同步阻塞就导致长久的资源锁定问题,所有事务参与者在等待其它参与者响应的时候都处于同步阻塞状态,无法进行其它操作,总体而言效率低,
(2).单点故障问题,调者在 2PC 中起到非常大的作用,发生故障将会造成很大影响。特别是在阶段二发生故障,所有参与者会一直等待状态,无法完成其它操作
(3).在极端条件下存在数据不一致的风险,如果协调者只发送了部分 Commit 消息,此时网络发生异常,那么只有部分参与者接收到 Commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致
(4).太过保守 任意一个节点失败就会导致整个事务失败,没有完善的容错机制
(5).具体的实现可以变形,而且 2PC 也有变种,例如 Tree 2PC、Dynamic 2PC。
(6).2PC 适用于数据库层面的分布式事务场景,而我务需求有时候不仅仅关乎数据库,也有可能是上传一张图片或者发送一条短信
(7).响应时间较长:整个消息链路是串行的,要等待响应结果,不适合高并发的场景
9. 2PC方案
实现2PC的方案有以下几种: XA方案,Seata方案
(1).XA方案
PC的传统方案是在 数据库层面实现的,如Oracle、MySQL都支持2PC协议,为了统一标准减少行业内不必要的对接成本,需要制定标准化的处理模型及接口标准,国际开放标准组织Open Group定义了 分布式事务处理模型DTP( Distributed Transaction Processing Reference Model)
下面以新用户注册送积分为例来说明XA方案的内容
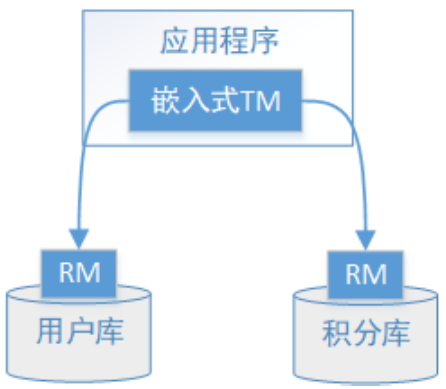
执行流程如下:
1).应用程序(AP)持有用户库和积分库两个数据源
2).应用程序(AP)通过TM通知用户库RM新增用户,同时通知积分库RM为该用户新增积分,RM此时并未提交事务,此时用户和积分资源锁定
3).TM收到执行回复,只要有一方失败则分别向其他RM发起回滚事务,回滚完毕,资源锁释放
4).TM收到执行回复,全部成功,此时向所有RM发起提交事务,提交完毕,资源锁释放
DTP模型定义如下角色
-
AP(Application Program):即应用程序,可以理解为使用DTP分布式事务的程序
-
RM(Resource Manager):即资源管理器,可以理解为事务的参与者,一般情况下是指一个数据库实例,通过资源管理器对该数据库进行控制,资源管理器控制着分支事务
-
TM(Transaction Manager):事务管理器,负责协调和管理事务,事务管理器控制着全局事务,管理事务生命周期,并协调各个RM,全局事务是指分布式事务处理环境中,需要操作多个数据库共同完成一个工作,这个工作即是一个全局事务
-
DTP模型定义TM和RM之间通讯的接口规范叫XA,简单理解为数据库提供的2PC接口协议,基于数据库的XA协议来实现2PC又称为XA方案
以上三个角色之间的交互方式如下:
-
TM向AP提供 应用程序编程接口,AP通过TM提交及回滚事务
-
TM交易中间件通过XA接口来通知RM数据库事务的开始、结束以及提交、回滚等
总结
整个2PC的事务流程涉及到三个角色AP、RM、TM: AP指的是使用2PC分布式事务的应用程序;RM指的是资源管理器,它控制着分支事务;TM指的是事务管理器,它控制着整个全局事务
步骤:
1)在准备阶段RM执行实际的业务操作,但不提交事务,资源锁定;
2)在提交阶段TM会接受RM在准备阶段的执行回复,只要有任一个RM执行失败,TM会通知所有RM执行回滚操作,否则,TM将会通知所有RM提交该事务。提交阶段结束资源锁释放。
XA方案的问题
-
需要本地数据库支持XA协议
-
资源锁需要等到两个阶段结束才释放,性能较差
(2).Seata方案
Seata是由阿里中间件团队发起的开源项目 Fescar,后更名为Seata,它是一个是开源的分布式事务框架。传统2PC的问题在Seata中得到了解决,它通过对本地关系数据库的分支事务的协调来驱动完成全局事务,是工作在应用层的中间件。主要优点是性能较好,且不长时间占用连接资源,它以高效并且对业务0侵入的方式解决微服务场景下面临的分布式事务问题,它目前提供AT模式(即2PC)及TCC模式的分布式事务解决方案
(3).Seata的设计思想
Seata的设计目标其一是对业务无侵入,因此从业务无侵入的2PC方案着手,在传统2PC的基础上演进,并解决2PC方案面临的问题。Seata把一个分布式事务理解成一个包含了若干分支事务的全局事务,全局事务的职责是协调其下管辖的分支事务达成一致,要么一起成功提交,要么一起失败回滚。此外,通常分支事务本身就是一个关系数据库的本地事务,下图是全局事务与分支事务的关系图:
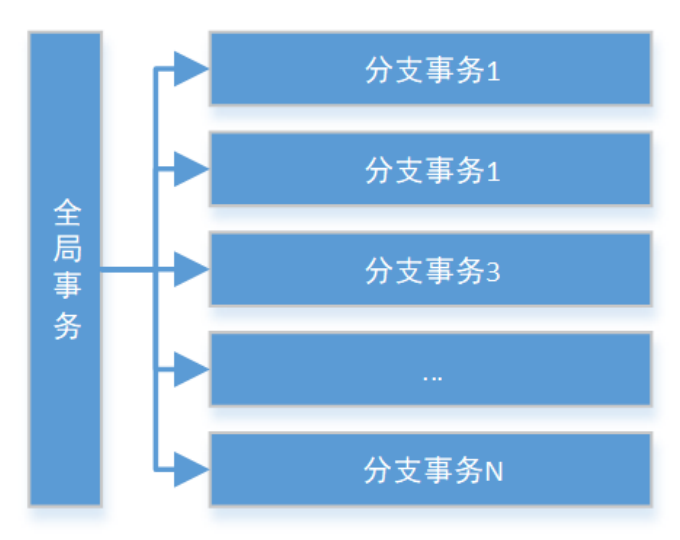
与 传统2PC 的模型类似,Seata定义了3个组件来协议分布式事务的处理过程:

-
Transaction Coordinator (TC): 事务协调器,它是独立的中间件,需要独立部署运行,它维护全局事务的运行状态,接收TM指令发起全局事务的提交与回滚,负责与RM通信协调各各分支事务的提交或回滚。
-
Transaction Manager (TM): 事务管理器,TM需要嵌入应用程序中工作,它负责开启一个全局事务,并最终向TC发起全局提交或全局回滚的指令。
-
Resource Manager (RM): 控制分支事务,负责分支注册、状态汇报,并接收事务协调器TC的指令,驱动分支(本地)事务的提交和回滚。
还是以新用户注册送积分来举例Seata的分布式事务过程:
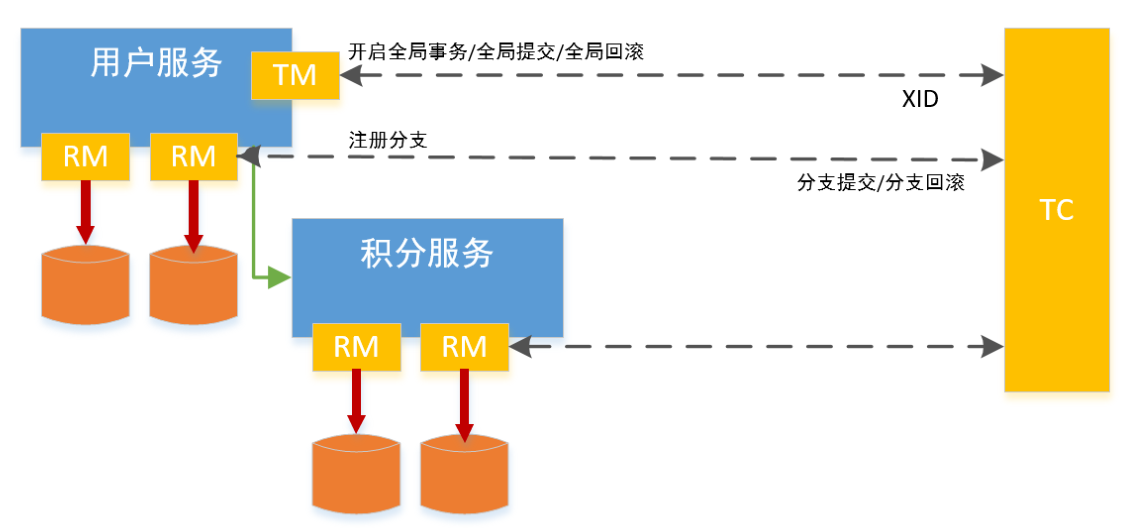
(1).具体的执行流程如下
-
用户服务的 TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的XID
-
用户服务的 RM 向 TC 注册 分支事务,该分支事务在用户服务执行新增用户逻辑,并将其纳入 XID 对应全局事务的管辖
-
用户服务执行分支事务,向用户表插入一条记录
-
逻辑执行到远程调用积分服务时(XID 在微服务调用链路的上下文中传播),积分服务的RM 向 TC 注册分支事务,该分支事务执行增加积分的逻辑,并将其纳入 XID 对应全局事务的管辖
-
积分服务执行分支事务,向积分记录表插入一条记录,执行完毕后,返回用户服务
-
用户服务分支事务执行完毕
-
TM 向 TC 发起针对 XID 的全局提交或回滚决议
-
TC 调度 XID 下管辖的全部分支事务完成提交或回滚请求
(2).Seata实现2PC与传统2PC的差别:
-
架构层次方面,传统2PC方案的 RM 实际上是在数据库层,RM 本质上就是数据库自身,通过 XA 协议实现,而Seata的 RM 是以jar包的形式作为中间件层部署在应用程序这一侧的
-
两阶段提交方面,传统2PC无论第二阶段的决议是commit还是rollback,事务性资源的锁都要保持到Phase2完成才释放。而Seata的做法是在Phase1 就将本地事务提交,这样就可以省去Phase2持锁的时间,整体提高效率
(4).seata实现2PC事务
1 ).业务说明
本示例通过Seata中间件实现分布式事务,模拟三个账户的转账交易过程.两个账户在三个不同的银行(张三在bank1、李四在bank2),bank1和bank2是两个个微服务,交易过程:张三给李四转账指定金额
上述交易步骤,要么一起成功,要么一起失败,必须是一个整体性的事务

2).程序组成部分
本示例程序组成部分如下:
数据库:MySQL-5.7.25
包括bank1和bank2两个数据库
微服务框架
seata客户端(RM、TM)
seata服务端(TC):seata-server-0.7.1
微服务及数据库的关系 :
dtx/dtx-seata-demo/seata-demo-bank1 银行1,操作张三账户, 连接数据库bank1
dtx/dtx-seata-demo/seata-demo-bank2 银行2,操作李四账户,连接数据库bank2
服务注册中心:dtx/discover-server
本示例程序技术架构如下:

交互流程如下:
-
请求bank1进行转账,传入转账金额
-
bank1减少转账金额,调用bank2,传入转账金额
3).创建数据库
导入数据库脚本:资料\sql\bank1.sql、资料\sql\bank2.sql
包括如下数据库:
bank1库,包含张三账户
<code class="language-plaintext hljs">CREATE DATABASE `bank1` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';</code>
<code class="language-plaintext hljs">DROP TABLE IF EXISTS `account_info`;
CREATE TABLE `account_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`account_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '户
主姓名',
`account_no` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '银行
卡号',
`account_password` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT
'帐户密码',
`account_balance` double NULL DEFAULT NULL COMMENT '帐户余额',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT =Dynamic;
INSERT INTO `account_info` VALUES (2, '张三的账户', '1', '', 10000);</code>bank2库,包含李四账户
<code class="language-plaintext hljs">CREATE DATABASE `bank2` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';</code>
<code class="language-plaintext hljs">CREATE TABLE `account_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`account_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '户
主姓名',
`account_no` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '银行
卡号',
`account_password` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT
'帐户密码',
`account_balance` double NULL DEFAULT NULL COMMENT '帐户余额',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT =Dynamic;
INSERT INTO `account_info` VALUES (3, '李四的账户', '2', NULL, 0);</code>分别在bank1、bank2库中创建undo_log表,此表为seata框架使用:
<code class="language-plaintext hljs">CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;</code>4).启动TC(事务协调器)
(1)下载seata服务器
下载地址:https://github.com/seata/seata/releases/download/v0.7.1/seata-server-0.7.1.zip
也可以直接解压:seata-server-0.7.1.zip
(2)解压并启动
[seata服务端解压路径]/bin/seata-server.bat -p 8888 -m file
注:其中8888为服务端口号;file为启动模式,这里指seata服务将采用文件的方式存储信息
如上图出现“Server started...”的字样则表示启动成功
5). discover-server
discover-server是服务注册中心,测试工程将自己注册至discover-server
6. 导入案例工程dtx-seata-demo并配置
在src/main/resource中,新增registry.conf、file.conf文件,内容可拷贝seata-server-0.7.1中的配置文件子。
在registry.conf中registry.type使用file:
在file.conf中更改service.vgroup_mapping.[springcloud服务名]-fescar-service-group = "default",并修改service.default.grouplist =[seata服务端地址]
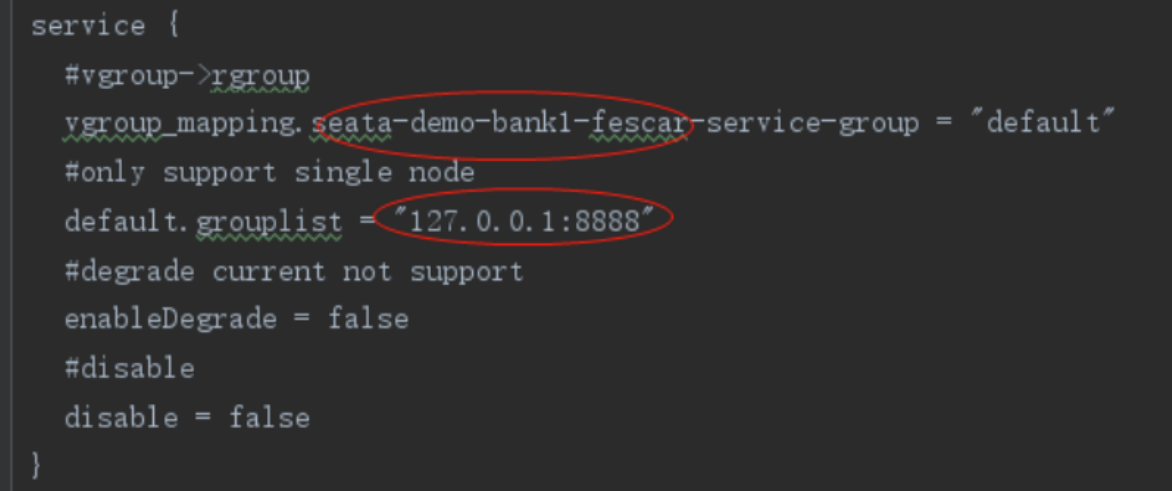
关于vgroup_mapping的配置:
vgroup_mapping:事务分组服务名 = Seata Server集群名称(默认名称为default)
default.grouplist = Seata Server集群地址
7). Seata执行流程
(1).正常提交流程
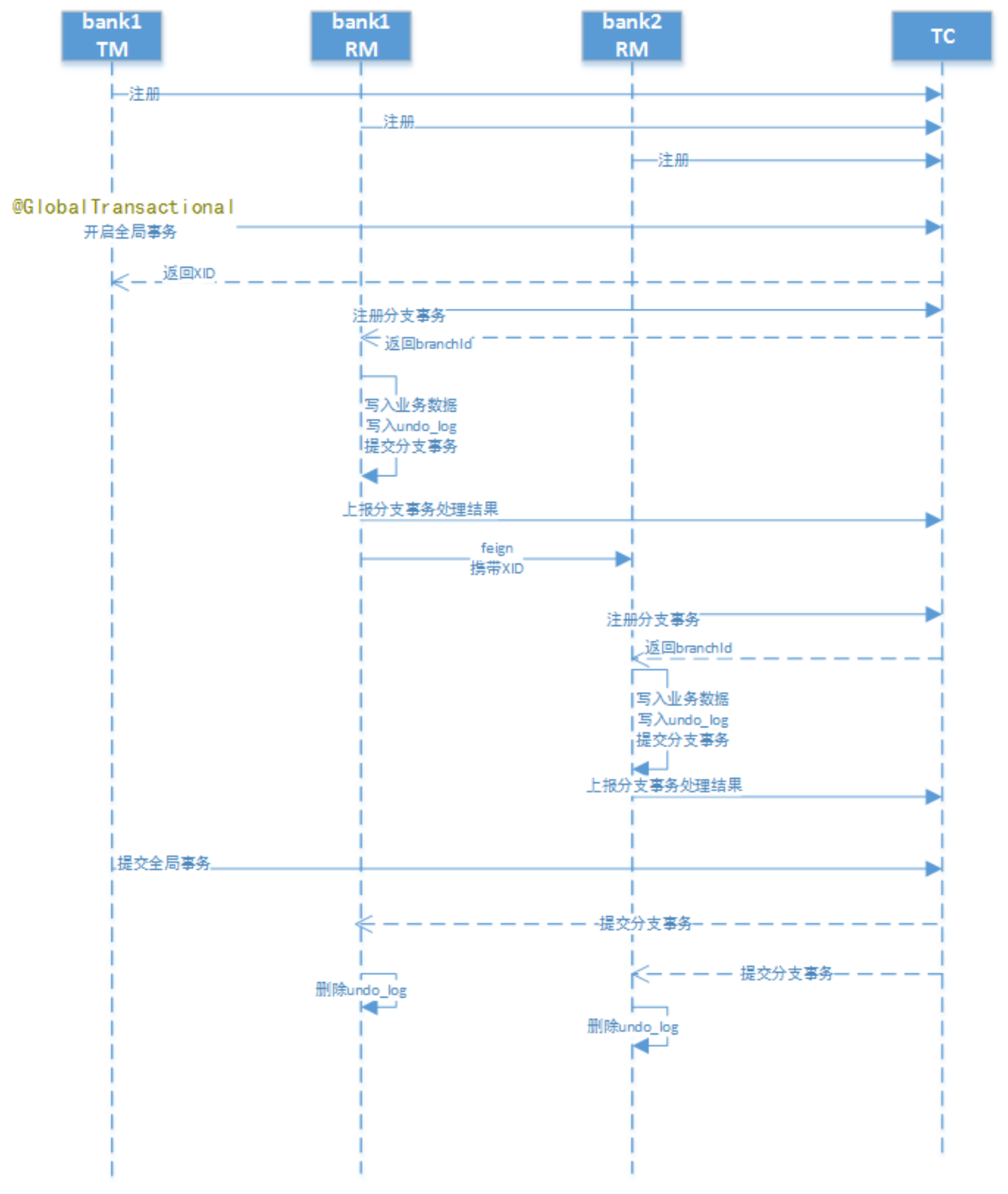
(2).回滚流程
回滚流程省略前的RM注册过程

要点说明:
-
每个RM使用DataSourceProxy连接数据库,其目的是使用ConnectionProxy,使用数据源和数据连接代理的目的就是在第一阶段将undo_log和业务数据放在一个本地事务提交,这样就保存了只要有业务操作就一定有undo_log。
-
在第一阶段undo_log中存放了数据修改前和修改后的值,为事务回滚作好准备,所以第一阶段完成就已经将分支事务提交,也就释放了锁资源。
-
TM开启全局事务开始,将XID全局事务id放在事务上下文中,通过feign调用也将XID传入下游分支事务,每个分支事务将自己的Branch ID分支事务ID与XID关联。
-
第二阶段全局事务提交,TC会通知各各分支参与者提交分支事务,在第一阶段就已经提交了分支事务,这里各各参与者只需要删除undo_log即可,并且可以异步执行,第二阶段很快可以完成。
-
第二阶段全局事务回滚,TC会通知各各分支参与者回滚分支事务,通过 XID 和 Branch ID 找到相应的回滚日志,通过回滚日志生成反向的 SQL 并执行,以完成分支事务回滚到之前的状态,如果回滚失败则会重试回滚操作。
8). dtx-seata-demo-bank1
dtx-seata-demo-bank1实现如下功能:
a.张三账户减少金额,开启全局事务
b.远程调用bank2向李四转账
(1)DAO
<code class="language-plaintext hljs">@Mapper@Component
public interface AccountInfoDao {
//更新账户金额
@Update("update account_info set account_balance = account_balance + #{amount} where
account_no = #{accountNo}")
int updateAccountBalance(@Param("accountNo") String accountNo, @Param("amount") Double
amount);
}</code>(2)FeignClient
远程调用bank2的客户端
<code class="language-plaintext hljs">@FeignClient(value = "seata‐demo‐bank2",fallback = Bank2ClientFallback.class)public interface Bank2Client {
@GetMapping("/bank2/transfer")
String transfer(@RequestParam("amount") Double amount);
}
@Componentpublic class Bank2ClientFallback implements Bank2Client{
@Override
public String transfer(Double amount) {
return "fallback";
}
}</code>(3)Service
<code class="language-plaintext hljs">@Servicepublic class AccountInfoServiceImpl implements AccountInfoService {
private Logger logger = LoggerFactory.getLogger(AccountInfoServiceImpl.class);
@Autowired
AccountInfoDao accountInfoDao;
@Autowired
Bank2Client bank2Client;
//张三转账
@Override
@GlobalTransactional
@Transactional
public void updateAccountBalance(String accountNo, Double amount) {
logger.info("******** Bank1 Service Begin ... xid: {}" , RootContext.getXID());
//张三扣减金额
accountInfoDao.updateAccountBalance(accountNo,amount*‐1);
//向李四转账
String remoteRst = bank2Client.transfer(amount);
//远程调用失败
if(remoteRst.equals("fallback")){
throw new RuntimeException("bank1 下游服务异常");
}
//人为制造错误
if(amount==3){
throw new RuntimeException("bank1 make exception 3");
}
}
}</code>将@GlobalTransactional注解标注在全局事务发起的Service实现方法上,开启全局事务:
GlobalTransactionalInterceptor会拦截@GlobalTransactional注解的方法,生成全局事务ID(XID),XID会在整个分布式事务中传递。
在远程调用时,spring-cloud-alibaba-seata会拦截Feign调用将XID传递到下游服务。
(4)Controller
<code class="language-plaintext hljs">@RestControllerpublic class Bank1Controller {
@Autowired
AccountInfoService accountInfoService;
//转账
@GetMapping("/transfer")
public String transfer(Double amount){
accountInfoService.updateAccountBalance("1",amount);
return "bank1"+amount;
}
}</code>9). dtx-seata-demo-bank2
dtx-seata-demo-bank2实现如下功能:
a.李四账户增加金额。
dtx-seata-demo-bank2在本账号事务中作为分支事务不使用@GlobalTransactional
(1)DAO
<code class="language-plaintext hljs">@Mapper@Component
public interface AccountInfoDao {
//向李四转账
@Update("UPDATE account_info SET account_balance = account_balance + #{amount} WHERE
account_no = #{accountNo}")
int updateAccountBalance(@Param("accountNo") String accountNo, @Param("amount") Double
amount);
}</code>(2)Service
<code class="language-plaintext hljs">@Servicepublic class AccountInfoServiceImpl implements AccountInfoService {
private Logger logger = LoggerFactory.getLogger(AccountInfoServiceImpl.class);
@Autowired
AccountInfoDao accountInfoDao;
@Override
@Transactionalpublic void updateAccountBalance(String accountNo, Double amount) {
logger.info("******** Bank2 Service Begin ... xid: {}" , RootContext.getXID());
//李四增加金额
accountInfoDao.updateAccountBalance(accountNo,amount);
//制造异常
if(amount==2){
throw new RuntimeException("bank1 make exception 2");
}
}
}</code>(3)Controller
<code class="language-plaintext hljs">@RestControllerpublic class Bank2Controller {
@Autowired
AccountInfoService accountInfoService;
@GetMapping("/transfer")
public String transfer(Double amount){
accountInfoService.updateAccountBalance("2",amount);
return "bank2"+amount;
}
}</code>10). 测试场景
-
张三向李四转账成功
-
李四事务失败,张三事务回滚成功
-
张三事务失败,李四事务回滚成功
-
分支事务超时测试
(5).小结
传统2PC(基于数据库XA协议)和Seata实现2PC的两种2PC方案,由于Seata的0侵入性并且解决了传统2PC长期锁资源的问题,所以推荐采用Seata实现2PC
Seata实现2PC要点:
-
全局事务开始使用 @GlobalTransactional标识
-
每个本地事务方案仍然使用@Transactional标识
-
每个数据都需要创建undo_log表,此表是seata保证本地事务一致性的关键
三.3PC
1.简介
3PC 的出现是为 了解决 2PC 的一些问题,相比于 2PC 它在 参与者中也引入了 超时机制,并且 新增了一个阶段使得参与者可以利用这一个阶段统一各自的状态。3PC 包含了三个阶段:分别是 准备阶段、预提交阶段和提交阶段,对应的英文就是: CanCommit、 PreCommit 和 DoCommit
看起来是把 2PC 的提交阶段变成了预提交阶段和提交阶段,但是 3PC 的准备阶段协调者只是询问参与者的自身状况,比如你现在还好吗?负载重不重?这类的,而预提交阶段就是和 2PC 的准备阶段一样,除了事务的提交该做的都做了,提交阶段和 2PC 的一样
2.图示

不管哪一个阶段有参与者返回失败都会宣布事务失败,这和 2PC 是一样的(当然到最后的提交阶段和 2PC 一样只要是提交请求就只能不断重试)
3.变化
首先准备阶段的变更成不会直接执行事务,而是会先去询问此时的参与者是否有条件接这个事务,因此不会一来就干活直接锁资源,使得在某些资源不可用的情况下所有参与者都阻塞着。而预提交阶段的引入起到了一个统一状态的作用,它像一道栅栏,表明在预提交阶段前所有参与者其实还未都回应,在预处理阶段表明所有参与者都已经回应了。
假如你是一位参与者,你知道自己进入了预提交状态那你就可以推断出来其他参与者也都进入了预提交状态。但是多引入一个阶段也多一个交互,因此性能会差一些,而且绝大部分的情况下资源应该都是可用的,这样等于每次明知可用执行还得询问一次。
4.影响
2PC 是同步阻塞的,上面已经分析了协调者挂在了提交请求还未发出去的时候,所有参与者都已经锁定资源并且阻塞等待着。那么引入了超时机制,参与者就不会傻等了,如果是等待提交命令超时,那么参与者就会提交事务了,因为都到了这一阶段了大概率是提交的,如果是等待预提交命令超时,那该干啥就干啥了,反正本来啥也没干。然而超时机制也会带来数据不一致的问题,比如在等待提交命令时候超时了,参与者默认执行的是提交事务操作,但是有可能执行的是回滚操作,这样一来数据就不一致了。
3PC 的引入是为了解决提交阶段 2PC 协调者和某参与者都挂了之后新选举的协调者不知道当前应该提交还是回滚的问题。新协调者来的时候发现有一个参与者处于预提交或者提交阶段,那么表明已经经过了所有参与者的确认了,所以此时执行的就是提交命令。
所以说 3PC 就是通过引入预提交阶段来使得参与者之间的状态得到统一,也就是留了一个阶段让大家同步一下。但是这也只能让协调者知道该如果做,但不能保证这样做一定对,这其实和上面 2PC 分析一致,因为挂了的参与者到底有没有执行事务无法断定。所以说 3PC 通过预提交阶段可以减少故障恢复时候的复杂性,但是不能保证数据一致,除非挂了的那个参与者恢复。
总结:
3PC 相对于 2PC 做了一定的改进:引入了参与者超时机制,并且增加了预提交阶段使得故障恢复之后协调者的决策复杂度降低,但整体的交互过程更长了,性能有所下降,并且还是会存在数据不一致问题。
所以 2PC 和 3PC 都不能保证数据100%一致,因此一般都需要有定时扫描补偿机制。
四.TCC(补偿事务)
1.简介
2PC 和 3PC 都是数据库层面的,而 TCC 是业务层面的分布式事务,就像我前面说的分布式事务不仅仅包括数据库的操作,还包括发送短信等,这时候 TCC 就派上用场了。TCC 是 Try、Confirm、Cancel 三个词语的缩写,TCC 要求每个分支事务实现三个操作: 预处理 Try、 确认 Confirm、 撤销 Cancel
Try 指的是预留,即资源的预留和锁定, 注意是预留
Confirm 指的是业务确认操作,这一步其实就是真正的执行了
Cancel 指的是撤销回滚操作,可以理解为把预留阶段的动作撤销了
步骤:
TM 首先发起所有的分支事务的 Try 操作,任何一个分支事务的Try操作执行失败,TM 将会发起所有分支事务的 Cancel 操作,若 Try 操作全部成功,TM 将会发起所有分支事务的 Confirm 操作,其中 Confirm/Cancel 操作若执行失败,TM 会进行重试
2. TCC 分为三个阶段
(1). Try 阶段是做完业务检查(一致性)及资源预留(隔离),此阶段仅是一个初步操作,它和后续的 Confirm 一起才能真正构成一个完整的业务逻辑
(2). Confirm 阶段是做确认提交,Try 阶段所有分支事务执行成功后开始执行 Confirm。通常情况下,采用 TCC 则认为 Confirm 阶段是不会出错的。即:只要 Try 成功,Confirm 一定成功。若 Confirm 阶段真的出错了,需引入重试机制或人工处理
(3). Cancel 阶段是在业务执行错误需要回滚的状态下执行分支事务的业务取消,预留资源释放。通常情况下,采用 TCC 则认为 Cancel 阶段也是一定成功的。若 Cancel 阶段真的出错了,需引入重试机制或人工处理
3. TM 事务管理器
TM事务管理器可以实现为独立的服务,也可以让全局事务发起方充当 TM 的角色,TM 独立出来是为了成为公用组件,是为了考虑系统结构和软件复用。TM 在发起全局事务时生成全局事务记录,全局事务 ID 贯穿整个分布式事务调用链条,用来记录事务上下文, 追踪和记录状态,由于 Confirm 和 Cancel 失败需进行重试,因此需要实现为幂等,幂等性是指同一个操作无论请求多少次,其结果都相同
4.举例说明
从思想上看和 2PC 差不多,都是先试探性的执行,如果都可以那就真正的执行,如果不行就回滚。
比如说一个事务要执行A、B、C三个操作,那么先对三个操作执行预留动作。如果都预留成功了那么就执行确认操作,如果有一个预留失败那就都执行撤销动作。来看下流程,TCC模型还有个事务管理者的角色,用来记录TCC全局事务状态并提交或者回滚事务
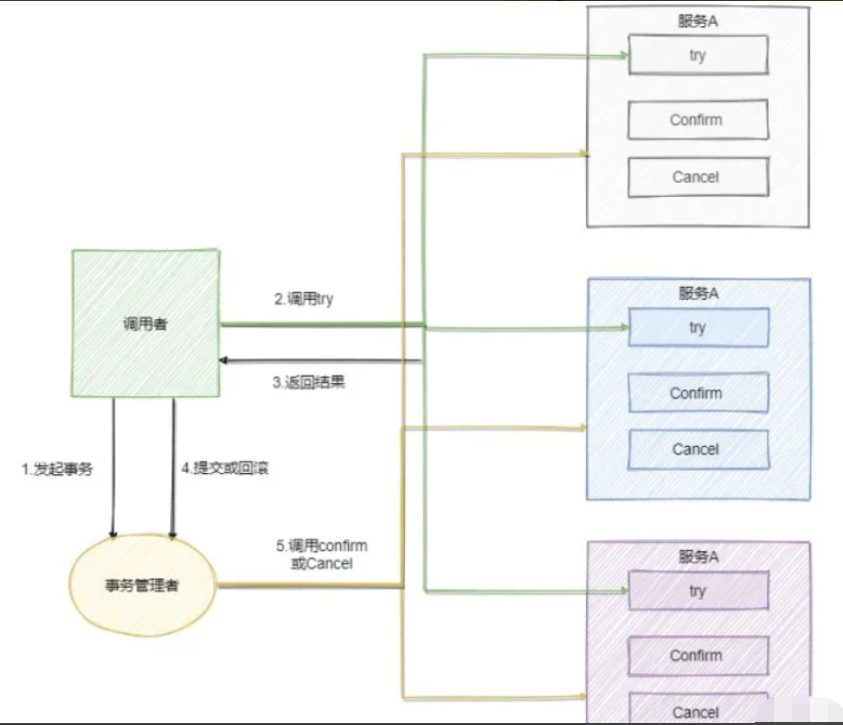
可以看到流程还是很简单的,难点在于业务上的定义,对于每一个操作你都需要定义三个动作分别对应Try - Confirm - Cancel。因此 TCC 对业务的侵入较大和业务紧耦合,需要根据特定的场景和业务逻辑来设计相应的操作。还有一点要注意,撤销和确认操作的执行可能需要重试,因此还需要保证操作的幂等。相对于 2PC、3PC ,TCC 适用的范围更大,但是开发量也更大,毕竟都在业务上实现,不过也因为是在业务上实现的,所以TCC可以跨数据库、跨不同的业务系统来实现事务
再比如:订单减库存操作
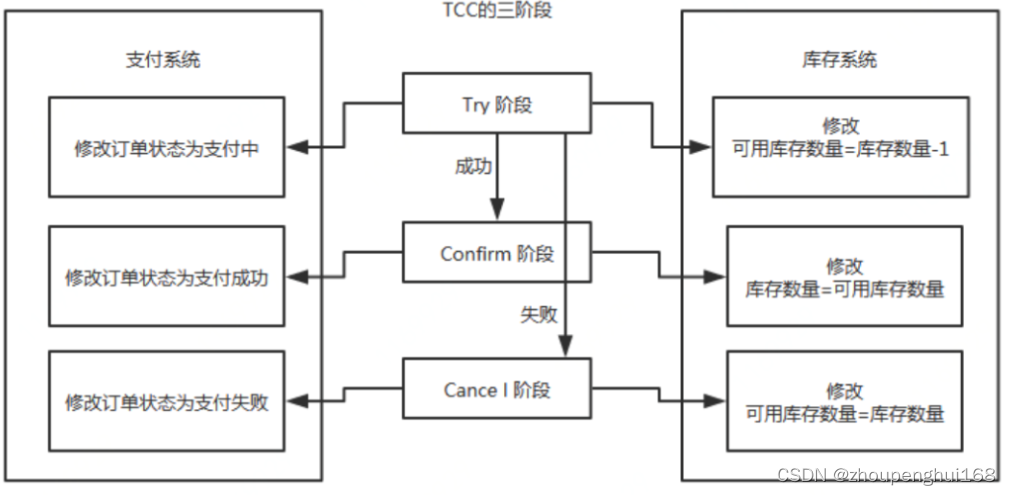
执行流程:
-
Try阶段:订单系统将当前订单状态设置为支付中,库存系统校验当前剩余库存数量是否大于1,然后将可用库存数量设置为库存剩余数量-1,
- 如果Try阶段「执行成功」,执行Confirm阶段,将订单状态修改为支付成功,库存剩余数量修改为可用库存数量
- 如果Try阶段「执行失败」,执行Cancel阶段,将订单状态修改为支付失败,可用库存数量修改为库存剩余数量
5.TCC 异常处理
TCC需要注意三种异常处理分别是 空回滚、 幂等、 悬挂
空回滚
在没有调用 TCC 资源 Try 方法的情况下,调用了二阶段的 Cancel 方法,Cancel 方法需要识别出这是一个空回滚,然后直接返回成功。
出现原因:当一个分支事务所在服务宕机或网络异常,分支事务调用记录为失败,这个时候其实是没有执行 Try 阶段,当故障恢复后,分布式事务进行回滚则会调用二阶段的 Cancel 方法,从而形成空回滚。
解决思路:关键就是要识别出这个空回滚,思路很简单就是需要知道一阶段是否执行,如果执行了,那就是正常回滚;如果没执行,那就是空回滚。前面已经说过 TM 在发起全局事务时生成全局事务记录,全局事务 ID 贯穿整个分布式事务调用链条。再额外增加一张分支事务记录表,其中有全局事务 ID 和分支事务 ID,第一阶段 Try 方法里会插入一条记录,表示一阶段执行了。Cancel 接口里读取该记录,如果该记录存在,则正常回滚;如果该记录不存在,则是空回滚
幂等
为了保证 TCC 二阶段提交重试机制不会引发数据不一致,要求 TCC 的二阶段 Try、Confirm 和 Cancel 接口保证幂等,这样不会重复使用或者释放资源。如果幂等控制没有做好,很有可能导致数据不一致等严重问题。
解决思路:在上述"分支事务记录"中增加执行状态,每次执行前都查询该状态
悬挂
悬挂就是对于一个分布式事务,其二阶段 Cancel 接口比 Try 接口先执行。
出现原因:在 RPC 调用分支事务 Try 时,先注册分支事务,再执行 RPC 调用,如果此时 RPC 调用的网络发生拥堵,通常 RPC 调用是有超时时间的,RPC 超时以后,TM 就会通知 RM 回滚该分布式事务,可能回滚完成后,RPC 请求才到达参与者真正执行,而一个 Try 方法预留的业务资源,只有该分布式事务才能使用,该分布式事务第一阶段预留的业务资源就再也没有人能够处理了,对于这种情况,我们就称为悬挂,即业务资源预留后没法继续处理。
解决思路:如果二阶段执行完成,那一阶段就不能再继续执行。在执行一阶段事务时判断在该全局事务下,"分支事务记录"表中是否已经有二阶段事务记录,如果有则不执行 Try
举例,场景为 A 转账 30 元给 B,A 和 B 账户在不同的服务
方案
<code class="language-plaintext hljs">账户 A
try:
检查余额是否够30元
扣减30元
confirm:
空
cancel:
增加30元
账户 B
try:
增加30元
confirm:
空
cancel:
减少30元</code>方案说明
(1)账户 A,这里的余额就是所谓的业务资源,按照前面提到的原则,在第一阶段需要检查并预留业务资源,因此,我们在扣钱 TCC 资源的 Try 接口里先检查 A 账户余额是否足够,如果足够则扣除 30 元。 Confirm 接口表示正式提交,由于业务资源已经在 Try 接口里扣除掉了,那么在第二阶段的 Confirm 接口里可以什么都不用做。Cancel 接口的执行表示整个事务回滚,账户A回滚则需要把 Try 接口里扣除掉的 30 元还给账户。
(2)账号B,在第一阶段 Try 接口里实现给账户 B 加钱,Cancel 接口的执行表示整个事务回滚,账户 B 回滚则需要把 Try 接口里加的 30 元再减去。
方案问题分析
-
如果账户 A 的 Try 没有执行在 Cancel 则就多加了 30 元
-
由于 Try、Cancel、Confirm 都是由单独的线程去调用,且会出现重复调用,故都需要实现幂等
-
账号 B 在 Try 中增加 30 元,当 Try 执行完成后可能会其它线程给消费了
-
如果账户 B 的 Try 没有执行在 Cancel 则就多减了 30 元
问题解决
-
账户 A 的 Cancel 方法需要判断 Try 方法是否执行,正常执行 Try 后方可执行 Cancel
-
Try、Cancel、Confirm方法实现幂等
-
账号 B 在 Try 方法中不允许更新账户金额,在 Confirm 中更新账户金额
-
账户 B 的 Cancel 方法需要判断 Try 方法是否执行,正常执行 Try 后方可执行 Cancel
优化方案
<code class="language-plaintext hljs">账户 A
try:
try幂等校验
try悬挂处理
检查余额是否够30元
扣减30元
confirm:
空
cancel:
cancel幂等校验
cancel空回滚处理
增加可用余额30元
账户 B
try:
空
confirm:
confirm幂等校验
正式增加30元
cancel:
空</code>6.小结
如果拿 TCC 事务的处理流程与 2PC 两阶段提交做比较,2PC 通常都是在跨库的 DB 层面,而 TCC 则在应用层面的处理,需要通过业务逻辑来实现。相比于上面介绍的2PC,解决了2PC的几个缺点:
-
1.「解决了协调者单点」,由主业务方发起并完成这个业务活动。业务活动管理器也变成多点,引入集群。
-
2.「同步阻塞」:引入超时,超时后进行补偿,并且不会锁定整个资源,将资源转换为业务逻辑形式,粒度变小。
-
3.「数据一致性」,有了补偿机制之后,由业务活动管理器控制一致性
这种分布式事务的实现方式的优势在于,可以让应用自己定义数据操作的粒度,使得降低锁冲突、提高吞吐量成为可能。不足之处则在于对应用的侵入性非常强,业务逻辑的每个分支都需要实现 Try、Confirm、Cancel 三个操作,此外,其实现难度也比较大,需要按照网络状态、系统故障等不同的失败原因实现不同的回滚策略
五.本地消息表(异步确保)
1.介绍
本地消息表与业务数据表处于同一个数据库中,这样就能 利用本地事务来保证在对这两个表的操作实现分布式事务,并且使用了消息队列来保证最终一致性
2.步骤
(1).在数据库中存放一张本地消息的表, 在分布式事务操作的一方执行写业务数据的操作之后向本地消息表发送一个消息, 将业务的执行和将消息放入消息表中的操作放在同一个事务中,这样就能保证消息放入本地表中业务肯定是执行成功的 本地事务能保证这个消息一定会被写入本地消息表中
(2).之后将本地消息表中的消息转发到 Kafka /RabbitMQ等消息队列中,如果转发成功,消息状态可以直接改成已成功,并将消息从本地消息表中删除,否则继续重新转发,重新转发就得保证对应服务的方法是幂等的,而且一般重试会有最大次数,超过最大次数可以记录下报警让人工处理
(3).在分布式事务操作的另一方从消息队列中读取一个消息,并执行消息中的操作,可以看到本地消息表其实实现的是最终一致性,容忍了数据暂时不一致的情况
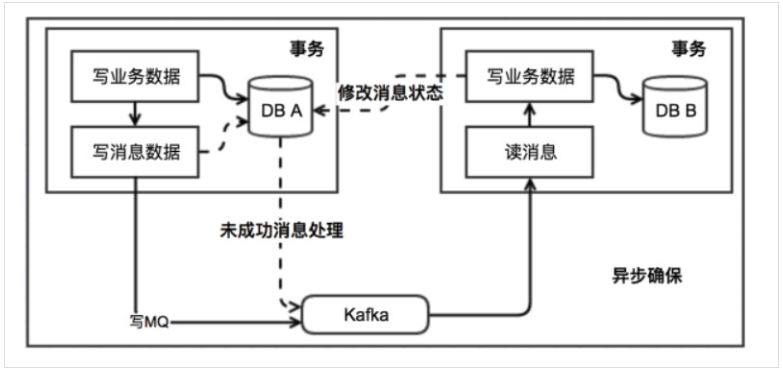
3.优缺点
优点: 一种非常经典的实现,避免了分布式事务,实现了最终一致性
缺点: 消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理
六.MQ 事务消息
有一些第三方的MQ是支持事务消息的,比如RocketMQ,他们支持事务消息的方式也是类似于采用的二阶段提交,但是市面上一些主流的MQ都是不支持事务消息的,比如 RabbitMQ 和 Kafka 都不支持。以阿里的 RocketMQ 中间件为例,其思路大致为:
第一阶段Prepared消息,会拿到消息的地址。
第二阶段执行本地事务,第三阶段通过第一阶段拿到的地址去访问消息,并修改状态。
也就是说在业务方法内要想消息队列提交两次请求,一次发送消息和一次确认消息。如果确认消息发送失败了RocketMQ会定期扫描消息集群中的事务消息,这时候发现了Prepared消息,它会向消息发送者确认,所以生产方需要实现一个check接口,RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。
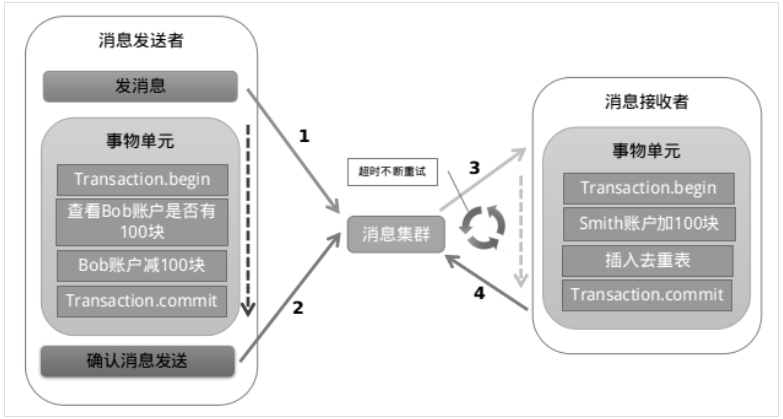
优点: 实现了最终一致性,不需要依赖本地数据库事务
缺点: 实现难度大,主流MQ不支持,RocketMQ事务消息部分代码也未开源
七.最大努力通知
1.什么是最大努力通知
最大努力通知也是一种解决分布式事务的方案,下边是一个是充值的例子:

2.交互流程
(1).账户系统调用充值系统接口
(2).充值系统完成支付处理向账户发起充值结果通知,
(3).若通知失败,则充值系统按策略进行重复通知
(4).账户系统接收到充值结果通知修改充值状态
(5).账户系统未接收到通知会主动调用充值系统的接口查询充值结果
通过上边的例子总结最大努力通知方案的目标:发起通知方通过一定的机制最大努力将业务处理结果通知到接收方
具体包括:
(1).有一定的消息重复通知机制。因为接收通知方可能没有接收到通知,此时要有一定的机制对消息重复通知
(2).消息校对机制。如果尽最大努力也没有通知到接收方,或者接收方消费消息后要再次消费,此时可由接收方主动向通知方查询消息信息来满足需求。
3.最大努力通知与可靠消息一致性有什么不同?
(1).解决方案思想不同
可靠消息一致性,发起通知方需要保证将消息发出去,并且将消息发到接收通知方,消息的可靠性关键由发起通知方来保证。最大努力通知,发起通知方尽最大的努力将业务处理结果通知为接收通知方,但是可能消息接收不到,此时需要接 收通知方主动调用发起通知方的接口查询业务处理结果,通知的可靠性关键在接收通知方。
(2).两者的业务应用场景不同
可靠消息一致性关注的是交易过程的事务一致,以异步的方式完成交易。最大努力通知关注的是交易后的通知事务,即将交易结果可靠的通知出去。
(3).技术解决方向不同
可靠消息一致性要解决消息从发出到接收的一致性,即消息发出并且被接收到。最大努力通知无法保证消息从发出到接收的一致性,只提供消息接收的可靠性机制。可靠机制是,最大努力的将消息通知给接收方,当消息无法被接收方接收时,由接收方主动查询消息(业务处理结果)
4.解决方案
通过对最大努力通知的理解,采用 MQ 的 ack 机制就可以实现最大努力通知
方案1
本方案是利用 MQ 的 ack 机制由 MQ 向接收通知方发送通知,流程如下: 发起通知方将通知发给 MQ。使用普通消息机制将通知发给MQ。 注意:如果消息没有发出去可由接收通知方主动请求发起通知方查询业务执行结果。(后边会讲) 接收通知方监听 MQ。 接收通知方接收消息,业务处理完成回应 ack。 接收通知方若没有回应 ack 则 MQ 会重复通知。 MQ会按照间隔 1min、5min、10min、30min、1h、2h、5h、10h的方式,逐步拉大通知间隔,直到达到通知要求的时间窗口上限。 接收通知方可通过消息校对接口来校对消息的一致性。
方案 2
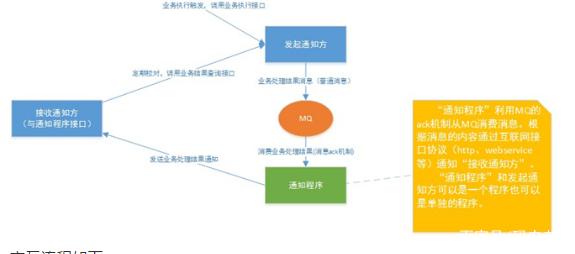
交互流程如下
(1).发起通知方将消息发给 MQ。 使用可靠消息一致方案中的事务消息保证本地事务和消息的原子性,最终将通知先发给 MQ。
(2).通知程序监听 MQ,接收 MQ 的消息。 方案 1 中接收通知方直接监听 MQ,方案 2 中由通知程序监听 MQ。 通知程序若没有回应 ack 则 MQ 会重复通知。
(3).通知程序通过互联网接口协议(如 htp、webservice)调用接收通知方案接口,完成通知。 通知程序调用接收通知方案接口成功就表示通知成功,即消费 MQ 消息成功,MQ 将不再向通知程序投递通知消息。
(4).接收通知方可通过消息校对接口来校对消息的一致性
方案1和方案2的不同点
(1).方案 1 中接收通知方与 MQ 接口,即接收通知方案监听 MQ,此方案主要应用与内部应用之间的通知。
(2).方案 2 中由通知程序与 MQ 接口,通知程序监听 MQ,收到 MQ 的消息后由通知程序通过互联网接口协议调用接收通知方。此方案主要应用于外部应用之间的通知,例如支付宝、微信的支付结果通知。 6.4 小结 最大努力通知方案是分布式事务中对一致性要求最低的一种,适用于一些最终一致性时间敏感度低的业务;最大努力通知方案需要实现如下功能: 消息重复通知机制 消息校对机制
5.小结
最大努力通知方案是分布式事务中对一致性要求最低的一种,适用于一些最终一致性时间敏感度低的业务;最大努力通知方案需要实现如下功能:
-
消息重复通知机制
-
消息校对机制
八.可靠消息最终一致性
1.什么是可靠消息最终一致性事务
可靠消息最终一致性方案是指当事务发起方执行完成本地事务后并发出一条消息,事务参与方(消息消费者)一定能够接收消息并处理事务成功,此方案强调的是只要消息发给事务参与方最终事务要达到一致
此方案是利用消息中间件完成,如下图:

事务发起方(消息生产方)将消息发给消息中间件,事务参与方从消息中间件接收消息,事务发起方和消息中间件之间,事务参与方(消息消费方)和消息中间件之间都是通过网络通信,由于网络通信的不确定性会导致分布式事务问题。
2.可靠消息最终一致性方案要解决以下几个问题
(1).本地事务与消息发送的原子性问题
本地事务与消息发送的原子性问题即:事务发起方在本地事务执行成功后消息必须发出去,否则就丢弃消息。即实现本地事务和消息发送的原子性,要么都成功,要么都失败。本地事务与消息发送的原子性问题是实现可靠消息最终一致性方案的关键问题。
下面这种操作,先发送消息,在操作数据库:
<code class="language-plaintext hljs">begin
//1.发送MQ
//2.数据库操作
commit transation;</code>这种情况下无法保证数据库操作与发送消息的一致性,因为可能发送消息成功,数据库操作失败。那么第二种方案,先进行数据库操作,再发送消息:
<code class="language-plaintext hljs">begin
//1.数据库操作
//2.发送MQ
commit transation;</code>这种情况下貌似没有问题,如果发送 MQ 消息失败,就会抛出异常,导致数据库事务回滚。但如果是超时异常,数据库回滚,但 MQ 其实已经正常发送了,同样会导致不一致。
(2).事务参与方接收消息的可靠性
事务参与方必须能够从消息队列接收到消息,如果接收消息失败可以重复接收消息。
(3).消息重复消费的问题
由于网络2的存在,若某一个消费节点超时但是消费成功,此时消息中间件会重复投递此消息,就导致了消息的重复消费。 要解决消息重复消费的问题就要实现事务参与方的方法幂等性。
3.解决方案
(1).本地消息表方案
本地消息表这个方案最初是 eBay 提出的,此方案的核心是通过本地事务保证数据业务操作和消息的一致性,然后通过定时任务将消息发送至消息中间件,待确认消息发送给消费方成功再将消息删除。
下面以注册送积分为例来说明:下例共有两个微服务交互,用户服务和积分服务,用户服务负责添加用户,积分服务负责增加积分。
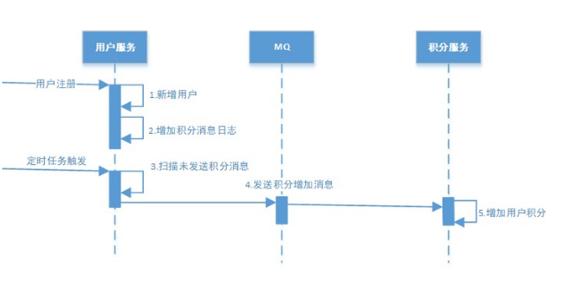
交互流程如下:
用户注册 用户服务在本地事务新增用户和增加 "积分消息日志"。(用户表和消息表通过本地事务保证一致)
<code class="language-plaintext hljs">begin transaction
//1.新增用户
//2.存储积分消息日志
commit transation</code>这种情况下,本地数据库操作与存储积分消息日志处于同一个事务中,本地数据库操作与记录消息日志操作具备原子性。
定时任务扫描日志 如何保证将消息发送给消息队列呢? 经过第一步消息已经写到消息日志表中,可以启动独立的线程,定时对消息日志表中的消息进行扫描并发送至消息中间件,在消息中间件反馈发送成功后删除该消息日志,否则等待定时任务下一周期重试。 消费消息 如何保证消费者一定能消费到消息呢? 这里可以使用 MQ 的 ack(即消息确认)机制,消费者监听 MQ,如果消费者接收到消息并且业务处理完成后向 MQ 发送 ack(即消息确认),此时说明消费者正常消费消息完成,MQ 将不再向消费者推送消息,否则消费者会不断重试向消费者来发送消息。 积分服务接收到"增加积分"消息,开始增加积分,积分增加成功后向消息中间件回应 ack,否则消息中间件将重复投递此消息。 由于消息会重复投递,积分服务的"增加积分"功能需要实现幂等性。
3.小结
可靠消息最终一致性就是保证消息从生产方经过消息中间件传递到消费方的一致性: 本地事务与消息发送的原子性问题。 事务参与方接收消息的可靠性。
可靠消息最终一致性事务适合执行周期长且实时性要求不高的场景。引入消息机制后,同步的事务操作变为基于消息执行的异步操作, 避免了分布式事务中的同步阻塞操作的影响,并实现了两个服务的解耦。
九.总结
1.分布式事务对比分析
2PC
最大的诟病是一个阻塞协议。RM 在执行分支事务后需要等待 TM 的决定,此时服务会阻塞并锁定资源。由于其阻塞机制和最差时间复杂度高,因此,这种设计不能适应随着事务涉及的服务数量增加而扩展的需要,很难用于并发较高以及子事务生命周期较长(long-running transactions) 的分布式服务中。
TCC
如果拿TCC事务的处理流程与2PC两阶段提交做比较,2PC 通常都是在跨库的 DB 层面,而 TCC 则在应用层面的处理,需要通过业务逻辑来实现。这种分布式事务的实现方式的优势在于,可以让应用自己定义数据操作的粒度,使得降低锁冲突、提高吞吐量成为可能。而不足之处则在于对应用的侵入性非常强,业务逻辑的每个分支都需要实现 Try、Confirm、Cancel 三个操作。此外,其实现难度也比较大,需要按照网络状态、系统故障等不同的失败原因实 现不同的回滚策略。典型的使用场景:满减,登录送优惠券等。
可靠消息最终一致性
事务适合执行周期长且实时性要求不高的场景。引入消息机制后,同步的事务操作变为基于消息执行的异步操作, 避免了分布式事务中的同步阻塞操作的影响,并实现了两个服务的解耦。典型的使用场景:注册送积分,登录送优惠券等。
最大努力通知
分布式事务中要求最低的一种,适用于一些最终一致性时间敏感度低的业务;允许发起通知方处理业务失败,在接收通知方收到通知后积极进行失败处理,无论发起通知方如何处理结果都会不影响到接收通知方的后续处理;发起通知方需提供查询执行情况接口,用于接收通知方校对结果。典型的使用场景:银行通知、支付结果通知等。
| 2PC | TCC | 可靠消息 | 最大努力通知 | |
| 一致性 | 强一致性 | 最终一致性 | 最终一致性 | 最终一致性 |
| 吞吐量 | 低 | 中 | 高 | 高 |
| 实现复杂度 | 易 | 难 | 中 | 易 |
2.总结
在条件允许的情况下,尽可能选择本地事务单数据源,因为它减少了网络交互带来的性能损耗,且避免了数据弱一致性带来的种种问题。若某系统频繁且不合理的使用分布式事务,应首先从整体设计角度观察服务的拆分是否合理,是否高内聚低耦合?是否粒度太小?分布式事务一直是业界难题,因为网络的不确定性,而且我们习惯于拿分布式事务与单机事务 ACID 做对比。无论是数据库层的 XA、还是应用层 TCC、可靠消息、最大努力通知等方案,都没有完美解决分布式事务问题,它们不过是各自在性能、一致性、可用性等方面做取舍,寻求某些场景偏好下的权衡

