
- 1DeBERTa_mlm预训练
- 22019 新年 Flag —— Will 著_手写新年flag图片
- 3自然语言处理:TF-IDF(基于python)_python tf-idf
- 4成都市酷客焕学新媒体科技有限公司:助力品牌闪耀短视频舞台
- 5FTTO接入详解_联通ftto介绍
- 6Waving Goodbye to Low-Res: A Diffusion-Wavelet Approach for Image Super-Resolution (Paper reading)
- 7Windows下安装pymssql 常见错误及解决方法_tree = parsing.p_module(s, pxd, full_module_name)
- 8智能时代的语言巨人:ChatGPT 与文心一言哪个更强?
- 9Java区块链视频教程百度云_区块链开发入门到精通视频教程
- 102023.5--YOLOV5 版本6.2简化推理代码!打开即用!_yolov5推理代码简化
MySQL - 数据库分库分表后,我们怎么保证ID全局唯一_分库分表如何保证数据唯一性
赞
踩
读写分离主从复制(数据库读写分离方案,实现高性能数据库集群)的方案去应对,后来又面临了大并发写入的时候,系统数据库采用了分库分表的方案(数据库分库分表方案,优化大量并发写入所带来的性能问题),通过垂直拆分以及水平拆分的方式,将数据分到多个库和多个表中去应对的,即现在是这样的一套分布式存储结构。
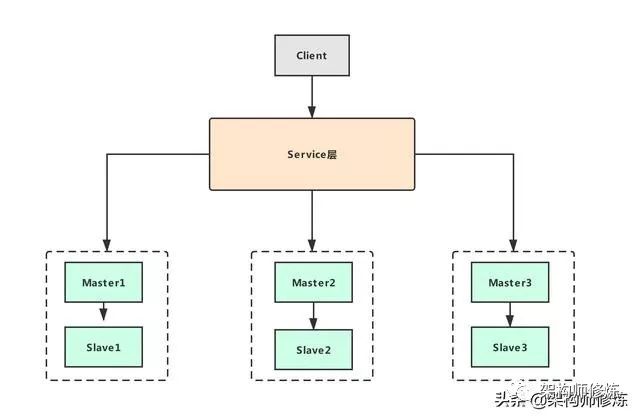
数据库分库分表那篇也讲到了,使用了分库分表势必会带来和我们之前使用不大相同的问题。今天,我将其中一个和我们开发息息相关的问题提出来进行讲解,也就是我们开发中所使用的的主键的问题。我们知道,以前我们单库的时候,主键唯一ID是自增的,现在好了,我们的数据被分到多个库的多个表里面了,如果我们还是使用之前的主键自增策略,那么这样就会出现两个数据插入到了两个不同的表会出现相同的ID值,这时我们该怎么去使用呢?
对于什么是主键,主键该怎么选,今天不做讲解,我相信大家可能比我还精通,我们今天主要是讲唯一主键ID在分布式存储系统下怎么生成,保证ID的唯一性且符合我们业务需要,才是我们开发人员最关心的实战。
UUID
这个时候,你可能会说,自增用不了,那我就是用UUID嘛,这个UUID生成出来的就是唯一的。的确,在我以前在一个公司中的确接触到是使用UUID来生成唯一主键ID的,而且性能还可以。但是,我想提一点的就是,当这个ID和我们业务交集不相关的时候是可以使用UUID生成主键的。比如,一般我们业务是需要用来做查询的,而且最好是单调递增的,这样我们的UUID就很不适合了。
主键ID单调递增有什么好处呢?
1,就拿我们用户关注航班这个模块来说,我们查看某个航班关注用户按照时间的先后进行排序。因为现在的ID是时间上有序的,所以现在我们就可以按照ID来进行排序了,同时这样对于有些并不是要存储时间的业务来说,会减少不少的存储空间。
2,有序的ID可以提升数据写入的性能
我们知道主键其实在数据库中就是一种索引,而索引在MySql数据库的B+数据结构中是顺序存储的,所以每次插入的时候就是递增排序的,直接追加到后面就行。如果是无序的话,则每次插入数据之前还得查找它应该所在的位置,这无疑就会增加数据的异动等相关的开销,如下图:
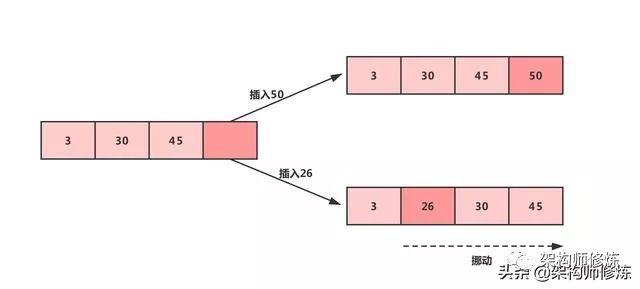
如上图所示,如果我们生成的ID是有序的,那这个 50 就直接插在尾部就行了,如果是无序的话,突然生成了一个 26,我们还得先找到 26 需要存放的位置,然后还要对其后面数据进行挪位置。
3,UUID不具备业务相关性
我们现在开发的项目都是依据公司业务开展的,而我们的唯一ID一般都是和业务有关系的,比如,有些订单ID中带上了时间的维度、机房的维度以及业务类型等维度。也就是为了我方便进行定位是那种业务的订单,才会这么设计的,是不是。
而UUID是由32位的16进制数字组成的字符串,不仅在存储空间上造成浪费,更不具备我们业务相关性。那我们该怎么解决呢?其实twitter提出来的Snowflake 算法就能很好满足我们现在的要求,满足了主键ID的全局唯一性、单调递增性,也可以满足我们的业务相关。所以,我们现在使用的唯一ID生成方式就是使用Snowflake算法,这个算法其实很简单。下面我们来对其进行讲解,并对其相应改造使其能用到我们的开发业务中来。
Snowflake 算法原理
Snowflake 是由 64 比特bit二进制数字组成的,一共分为4大部分:
- 1位默认不使用
- 41位时间戳
- 10位机器ID
- 12位序列号

- 我们从上图中可以看出snowflake算法的第二部分的41位时间戳,大概可以支撑2^41/1000/60/60/24/365 年,也就是大约有69年。我们设计一个系统用69年应该是足够了吧。
- 10位的机器ID我们可以怎么使用呢?我们可以划分成大概2到3位IDC,也就是可以支撑4到8个IDC机房;然后划分7到 8 位的机器ID,即可以支撑128~256台机器。
- 12位的序号,就代表每个节点每毫秒可以生成4096个ID序号。
如何改造
我们现在已经知道了Snowflake 算法的核心原理,并且知道了其有64位的二进制数据,那我们就可以根据自己业务进行改造以更好的来为我们业务服务。一般不同的公司对其进行改造的方式都不尽相同,但是道理都是一样的。我们可以这么做:
- 我们是减少序列号的位数,增加机器ID的位数,是为了用来支撑我们单IDC的更多机器。
- 将我们业务ID加入进去用来区分我们不同的业务。比如,1位0 + 41位时间戳 + 6位IDC(64个IDC) + 6位业务信息(支撑64种业务) + 10位自增序列(每毫秒1024个ID)

如此,我们就可以在单机房部署这么一个统一ID发号器,然后用Keeplive 保证高可用(对于高可用不熟悉的回去看看哈「高可用」你们服务器挂了怎么办,我们是这样做的)可以将不同的业务模块ID加入进去,这样的好处是即使哪个业务出问题了,我只看ID号我就分析出来,比如,我看到现在ID号有我的订单ID业务,我就去看订单模块。
开发如何使用
现在我们知道Snowflake 算法原理了,还知道了我们可以进行改造了。那我们开发人员该怎么去使用,来为我们业务生成统一的唯一ID呢?
1,直接嵌入到业务代码
嵌入业务代码的意思就是,这个snowflake算法就部署在和我们业务相同的服务器上,这样我们代码使用的时候,就不用了跨网络调用,性能相对比较好。但是也是有缺点的,因为我们的业务机器肯定是很多的,这就意味着我们发号器算法需要更多的机器ID位数。同时,太多的业务服务器我们会很难保证业务机器id的唯一性,这里就需要引用zookeeper一致性组件来保证每次机器重启都能能获得唯一的机器ID。
2,独立部署成发号器服务
也就是说,我们将其作为单独的服务部署到单独的机器上,已对外提供服务。这样就是多了网络的传输,不过影响不大,比如,我可以将其部署成一个主备的方式对外提供发号服务,机器ID可以用作序列号使用,这样也就是会有更多的自增序号,有部分大厂就是以这样单独的服务提供出来的。
开发中避坑大法
1,虽然snowflake很优秀,但是它是基于系统时间的,万一我们系统的时间不准怎么办,就会造成我们的ID会重复。那我们的做法就是,要利用系统的对时功能,一旦发现时间不一致,就暂停发号器,等到时钟准了在启用。
2,还有一个坑比较关键,也是常发生的,就是当我们的QPS并发不高的时候,比如每毫秒只生成一个ID号,这样就是直接结果是,每次生成的ID末尾都是1,这样我们分库分表就会出现问题呀对吧,因为我们用这个ID去分库分表呀,会造成数据不均匀,是吧,忘记了去复习哈(数据库分库分表方案,优化大量并发写入所带来的性能问题)那我们怎么解决呢?
我们可以将时间戳记录从毫秒记录改为秒记录,这样我一秒可以发好多个号了
生成的序列号起始号随机启动,比如这一秒起始号是10,我下一秒随机了变成了28,这样就更加分散开了。
总结,今天我们针对分库分表之后带来的第一个直接影响我们开发的问题,就是主键ID唯一性的问题,然后说到了使用Snowflake算法去解决,并且对其原理和使用进行了详细的讲解,同时,还将其在使用中遇到的坑给讲出来了,也对其进行了填坑分析,让大家直接避免遇到同样的问题。当然生成唯一ID有多种,我们根据业务选择合适我们自己的就好,你们是基于什么方式生成的可以也可以告诉大家。

