
- 1深度化的人脸检测与识别技术—进展与展望_基于seetaface的多时相人脸识别与检索系统开发
- 2Redis 逻辑过期策略设计思路_redis逻辑过期
- 3动能技术问答丨13.56M刷卡芯片技术问答(二)_si522a
- 4搭建Hadoop3.x完全分布式集群_hadoop3集群搭建
- 5Pytorch实现LSTM案例学习(1)_pytorch lstm的参数提取
- 6ChatGPT 类大语言模型为什么会带来“神奇”的涌现能力?
- 7【FPGA-DSP】第九期:音频信号处理
- 8go to home"" href="/w/菜鸟追梦旅行/article/detail/372415" target="_blank">Vue路由router详细总结_"
go to home " - 9java 获取远程系统启动时间_从Java中的RuntimeMXBean获取系统启动时间
- 10这么多年,终于有人讲清楚 Transformer 了!
MySQL8高级_读写分离和分库分表_linux mysql8 读写 分离
赞
踩
MySQL8高级_读写分离和分库分表
第01章 高性能架构模式
互联网业务兴起之后,海量用户加上海量数据的特点,单个数据库服务器已经难以满足业务需要,必须考虑数据库集群的方式来提升性能。高性能数据库集群的第一种方式是“读写分离”,第二种方式是“分库分表”。
1、读写分离
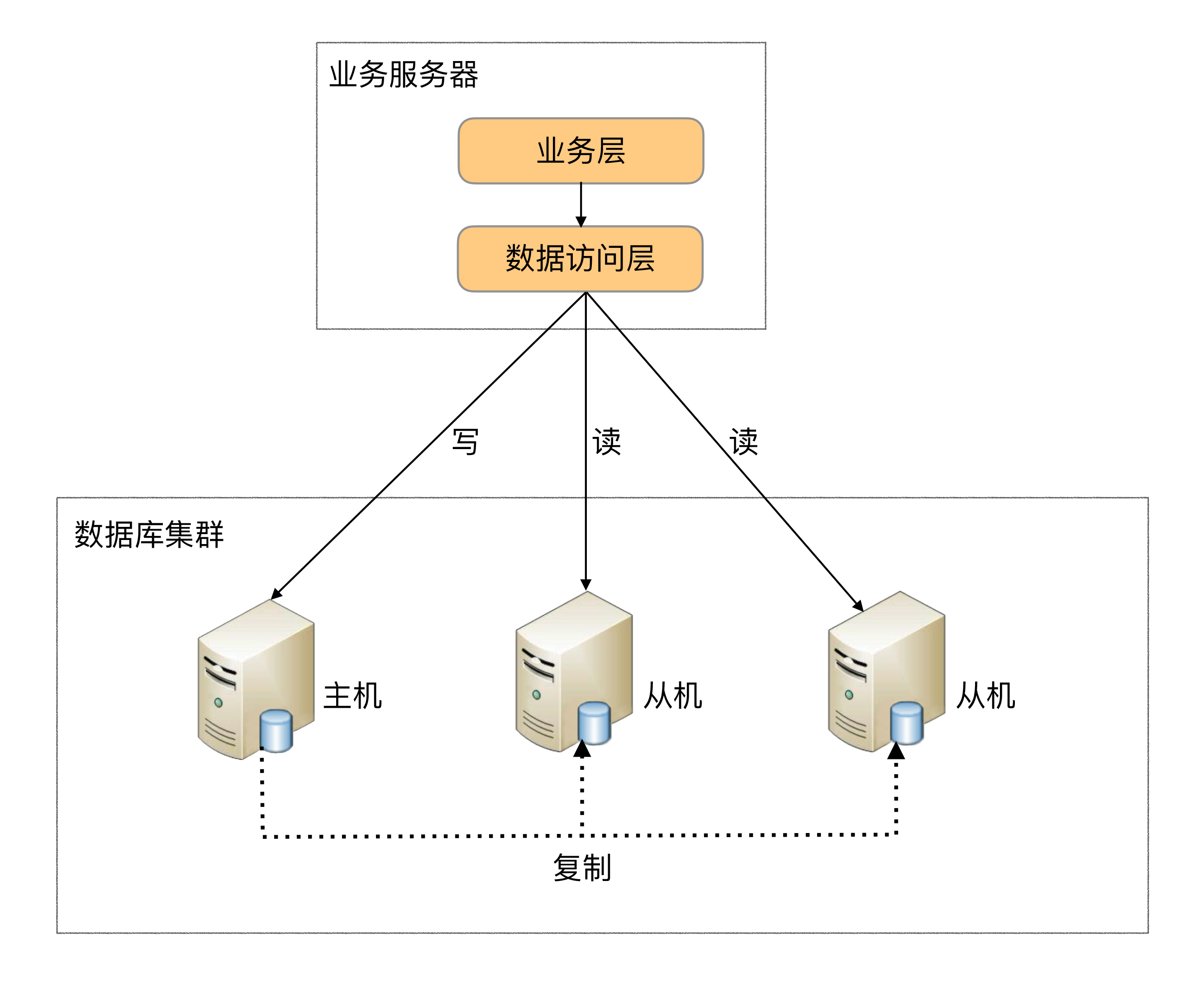
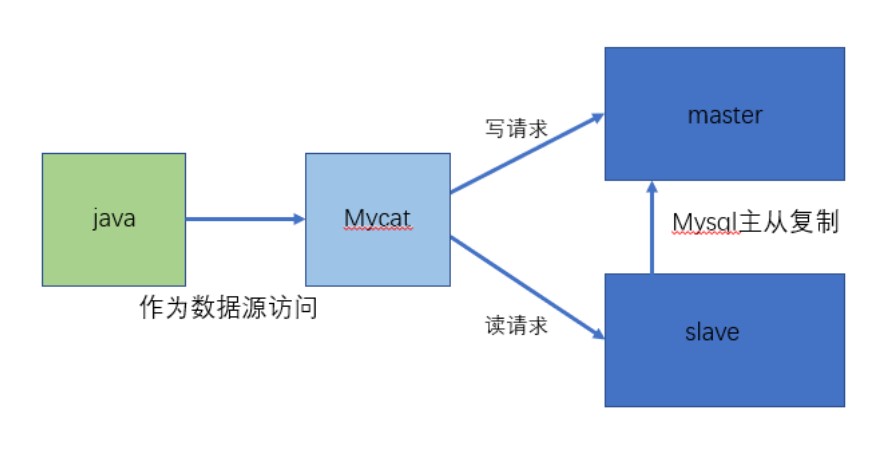
**读写分离原理:**读写分离的基本原理是将数据库读写操作分散到不同的节点上,下面是其基本架构图。
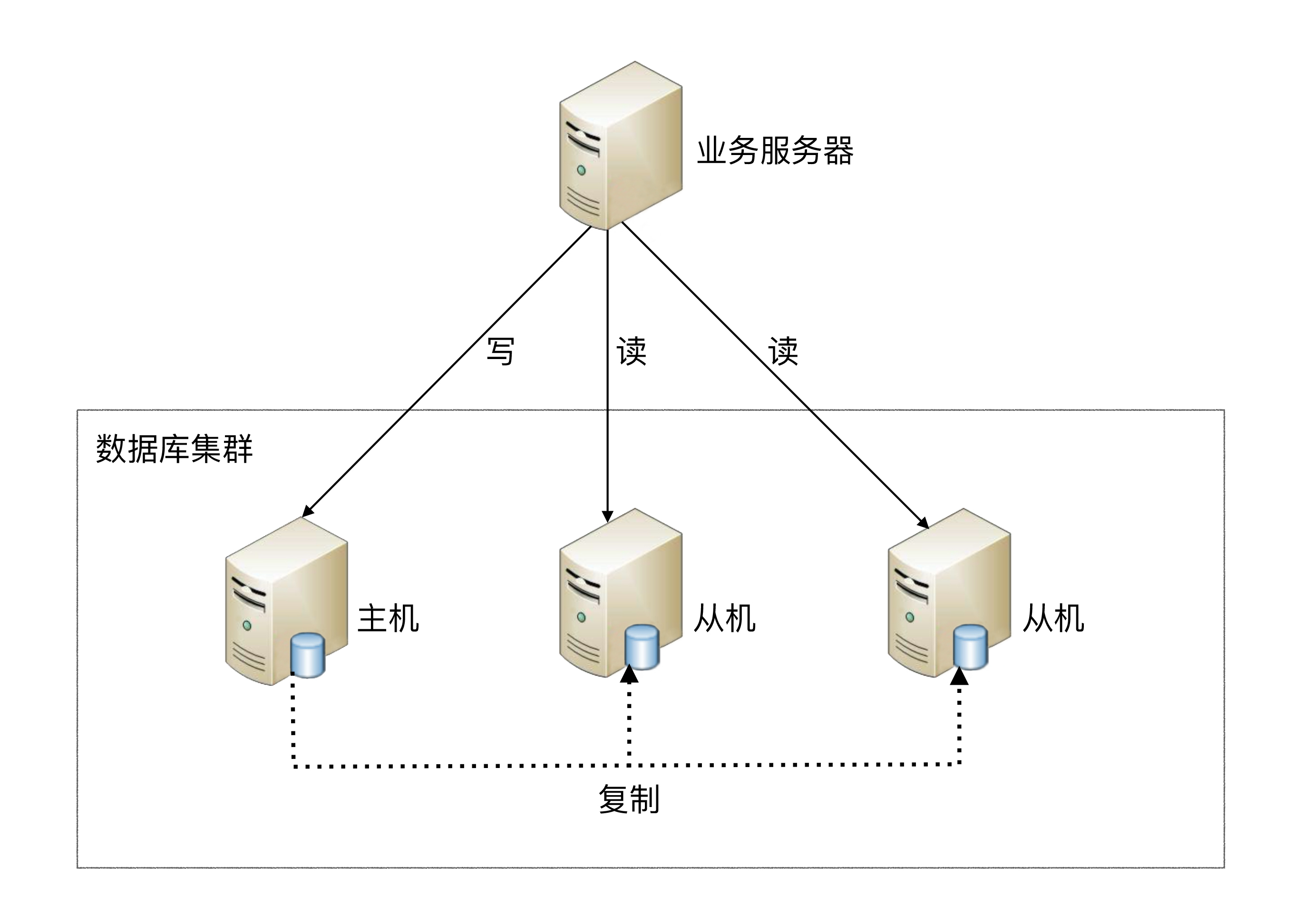
读写分离的基本实现:
- 数据库服务器搭建
主从集群,一主一从、一主多从都可以。 - 数据库主机负责
写操作或读写操作,从机只负责读操作。 - 数据库主机通过
复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据。 - 业务服务器将写操作发给数据库主机,将读操作发给数据库从机。
2、分库分表(数据库分片)
读写分离的问题:
读写分离分散了数据库读写操作的压力,但没有分散存储压力,为了满足业务数据存储的需求,就需要将存储分散到多台数据库服务器上。
2.1、分库
业务分库指的是按照业务模块将数据分散到不同的数据库服务器。例如,一个简单的电商网站,包括用户、商品、订单三个业务模块,我们可以将用户数据、商品数据、订单数据分开放到三台不同的数据库服务器上,而不是将所有数据都放在一台数据库服务器上。
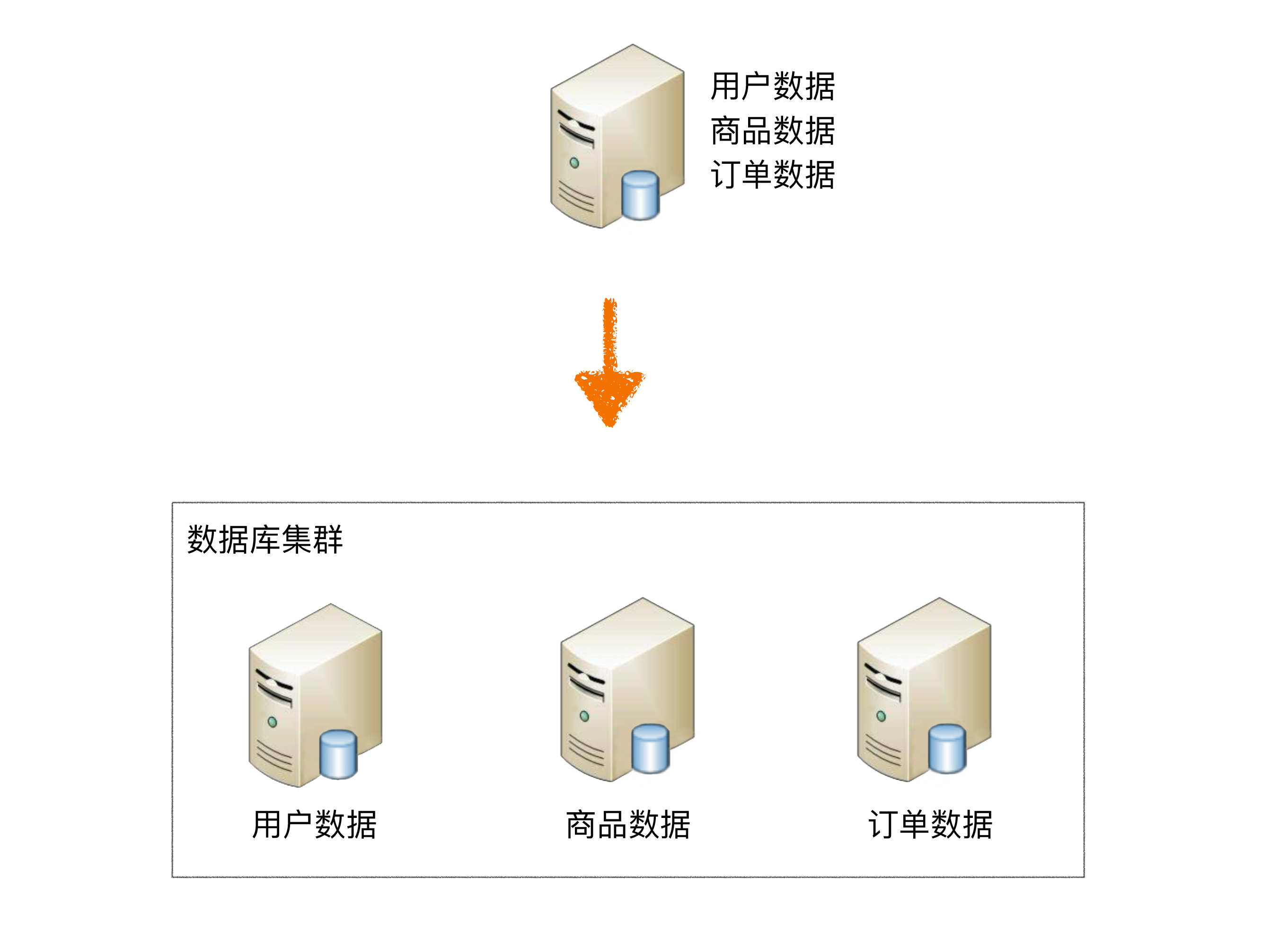
业务分库带来的复杂性:
- join操作问题
- 实务问题
- 成本问题
2.2、分表
同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。例如,淘宝的几亿用户数据,如果全部存放在一台数据库服务器的一张表中,肯定是无法满足性能要求的,此时就需要对单表数据进行拆分。
单表数据拆分有两种方式:垂直分表和水平分表。示意图如下:
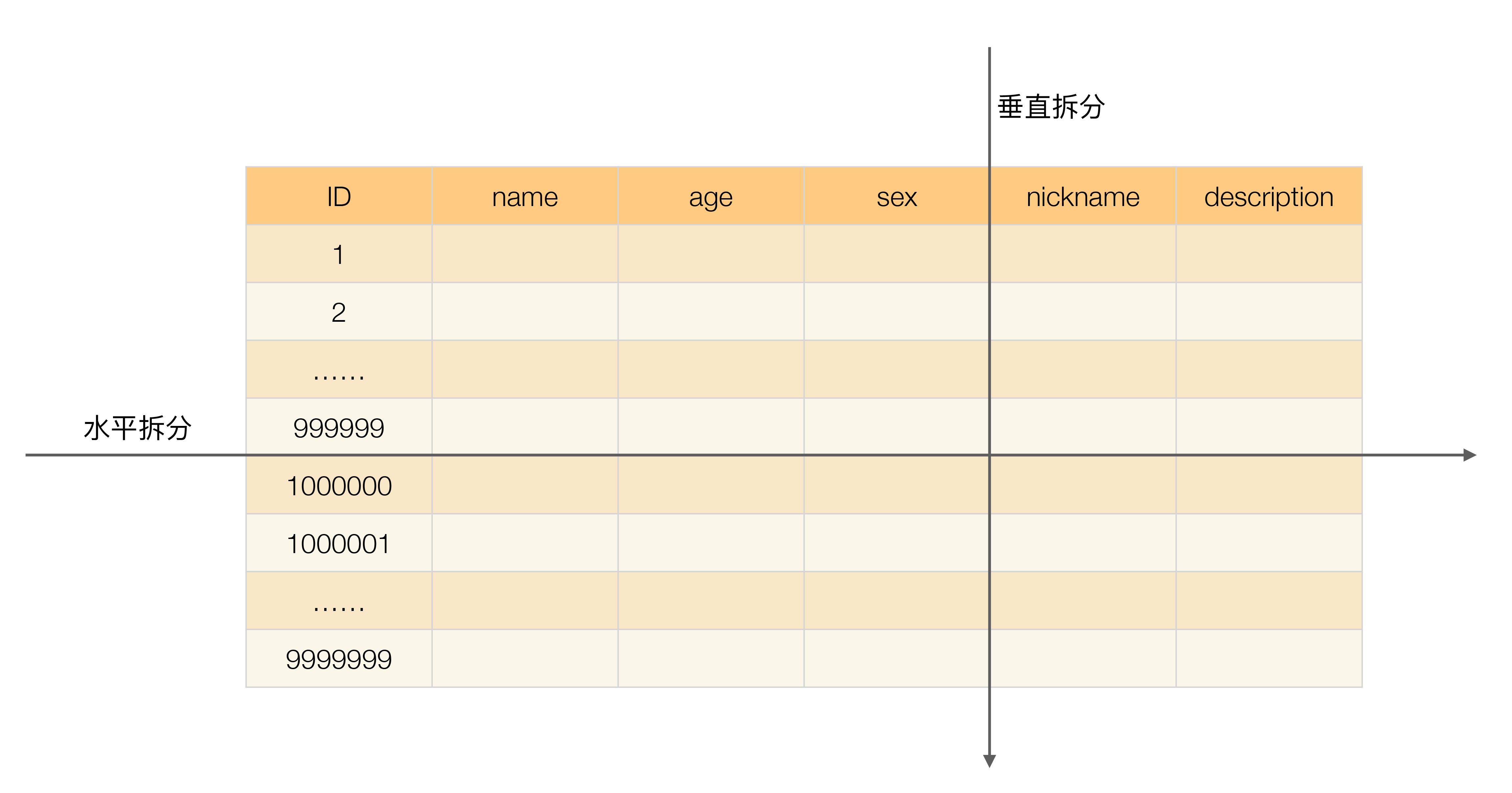
上面这个示例比较简单,只考虑了一次切分的情况,实际架构设计过程中并不局限切分的次数,可以切两次,也可以切很多次。
单表进行切分后,是否将多个表分散在不同的数据库服务器中,可以根据实际的切分效果来确定。单表切分为多表后,新的表即使在同一个数据库服务器中,也可能带来可观的性能提升,如果性能能够满足业务要求,可以不拆分到多台数据库服务器,毕竟业务分库也会引入很多复杂性;如果单表拆分为多表后,单台服务器依然无法满足性能要求,那就需要将多个表分散在不同的数据库服务器中。
2.2.1、垂直分表
垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。
例如,前面的例子是一个婚恋网站的用户表,在筛选用户时,主要是用 age 和 sex 两个字段进行查询,而 nickname 和 description 两个字段主要用于展示,一般不会在业务查询中用到。description 本身又比较长,因此我们可以将这两个字段独立到另外一张表中,这样在查询 age 和 sex 时,就能带来一定的性能提升。
垂直分表带来的复杂性:
2.2.2、水平分表
水平分表适合表行数特别大的表。
有的公司要求单表行数超过 5000 万就必须进行分表,这个数字可以作为参考,但并不是绝对标准,关键还是要看表的访问性能。
垂直分表带来的复杂性:
- id策略
- join操作
- count操作
- order by操作
3、实现方式
读写分离和分库分表具体的实现方式一般有两种:中间件封装 和 程序代码封装。
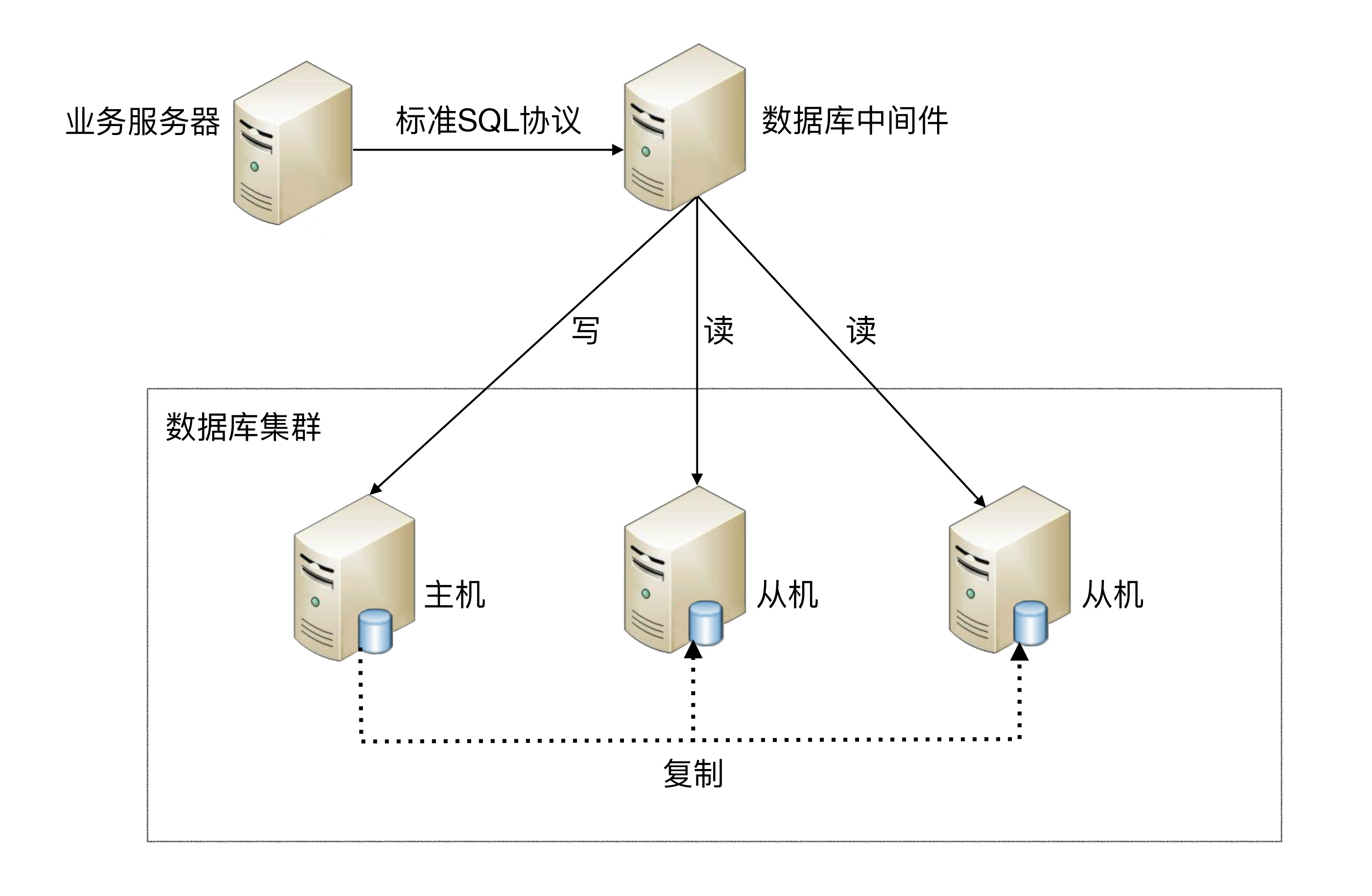
3.1、中间件封装
中间件封装指的是独立一套系统出来,实现读写操作分离和数据库服务器连接的管理。对于业务服务器来说,访问中间件和访问数据库没有区别,在业务服务器看来,中间件就是一个数据库服务器。
**基本架构是:**以读写分离为例
3.2、程序代码封装
程序代码封装指在代码中抽象一个数据访问层(或中间层封装),实现读写操作分离和数据库服务器连接的管理。
**其基本架构是:**以读些分离为例
第02章 MySQL主从复制
1、MySQL主从复制原理
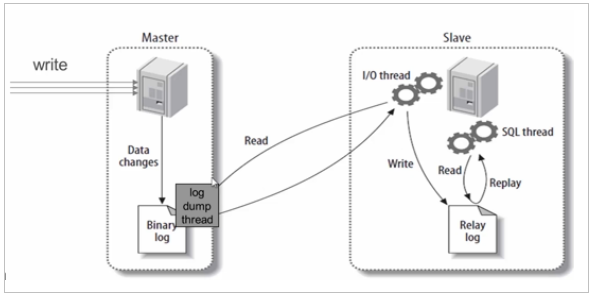
基本原理:
slave会从master读取binlog来进行数据同步
具体步骤:
-
step1:master将数据改变记录到二进制日志(binary log)中。- 二进制日志由配置文件log-bin参数指定
- 这些记录过程叫做二进制日志事件(binary log events)
-
step2:slave将master的binary log events拷贝到它的中继日志(relay log)中。- slave的
I/O线程去请求主库 的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中 - master会生成一个
log dump 线程,用来给slave的I/O线程线程传输binlog
- slave的
-
step3:slave重做中继日志中的事件,将改变反映到自己的数据中。- slave的
SQL线程,读取relay log日志,并解析成具体操作,从而实现主从操作一致,最终数据一致。
- slave的
由此可见主从复制过程需要网络传输或大量的IO操作,这些操作会导致数据同步的延时
复制的基本原则:
-
每个master可以有多个salve
-
每个slave只有一个master
-
每个slave只能有一个唯一的服务器ID
2、一主一从常见配置
第一种:服务器规划:使用docker方式创建
第二种:克隆虚拟机,使用两台虚拟机的MySQL
-
注意:修改uuid值
vim /var/lib/mysql/auto.cnf 下更改uuid,重启服务
使用uuidgen生成
2.1、主服务器配置
-
step1:操作MySQL主服务器配置文件:
vim /etc/my.cnf- 1
配置如下内容:
[mysqld]
# 服务器唯一id
server-id=1
# # 启用二进制日志,日志名是mysql-bin
log-bin=mysql-bin
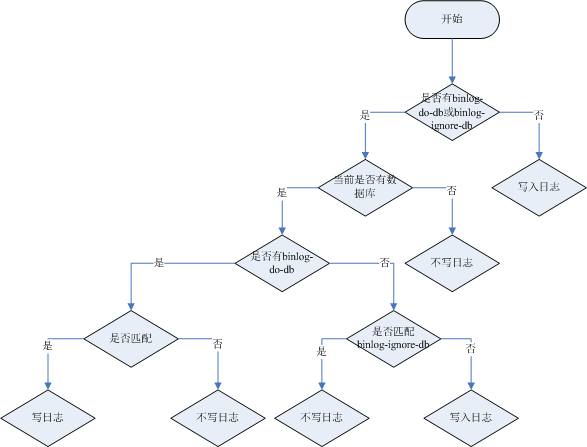
# # 设置不需要复制的数据库
binlog-ignore-db=mysql
binlog-ignore-db=infomation_schema
# # 设置需要复制的数据库
binlog-do-db=mytestdb
# # 设置logbin格式
binlog_format=STATEMENT
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
logbin格式说明:
- binlog_format=STATEMENT:日志记录的是主机数据库的
写指令,性能高,但是now()之类的函数以及获取系统参数的操作会出现主从数据不同步的问题。 - binlog_format=ROW(默认):日志记录的是主机数据库的
写后的数据,批量操作时性能较差,解决now()或者 user()或者 @@hostname 等操作在主从机器上不一致的问题。 - binlog_format=MIXED:是以上两种level的混合使用,有函数用ROW,没函数用STATEMENT,但是无法识别系统变量
binlog-ignore-db和binlog-do-db的优先级问题:
- step2:重新启动MySQL主服务器:
端口3306
systemctl restart mysqld
- 1
- step3:主机中创建slave用户:
-- 创建slave用户
CREATE USER 'atguigu_slave'@'%';
-- 设置密码
ALTER USER 'atguigu_slave'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
-- 授权
GRANT REPLICATION SLAVE ON *.* TO 'atguigu_slave'@'%';
-- 刷新权限
FLUSH PRIVILEGES;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- step4:主机中查询master状态:
执行完此步骤后不要再操作主服务器MYSQL,防止主服务器状态值变化
SHOW MASTER STATUS;
- 1
记下File和Position的值。执行完此步骤后不要再操作主服务器MYSQL,防止主服务器状态值变化。

**注意:**上面的步骤中,如果启动后,对配置文件进行了修改,则需要重启MySQL容器,重启后需要重新查看master状态
2.2、从服务器配置
- step1:修改MySQL从服务器配置文件:
vim /etc/my.cnf
- 1
配置如下内容:
[mysqld]
# 服务器唯一id
server-id=2
# 启用中继日志
relay-log=mysql-relay
- 1
- 2
- 3
- 4
- 5
-
step2:启动MySQL从服务器:
systemctl start mysqld- 1
-
step3:在从机上配置主从关系:
在从机上执行以下SQL操作(192.168.197.128是主服务器的IP)
CHANGE MASTER TO MASTER_HOST='192.168.197.128',
MASTER_USER='atguigu_slave',MASTER_PASSWORD='123456', MASTER_PORT=3306,
MASTER_LOG_FILE='mysql-bin.000003',MASTER_LOG_POS=1075;
- 1
- 2
- 3
2.3、启动主从复制
启动从机的复制功能,执行SQL:
START SLAVE;
-- 查看状态(不需要分号)
SHOW SLAVE STATUS\G
- 1
- 2
- 3
**两个关键进程:**下面两个参数都是Yes,则说明主从配置成功!

2.4、实现主从复制
在主机中执行以下SQL,在从机中查看数据库、表和数据是否已经被同步
CREATE DATABASE mytestdb;
USE mytestdb;
CREATE TABLE mytbl(id INT,NAME VARCHAR(16));
INSERT INTO mytbl VALUES(1, 'zhang3');
INSERT INTO mytbl VALUES(2, @@hostname);
- 1
- 2
- 3
- 4
- 5
2.5、停止和重置
需要的时候,可以使用如下SQL语句
-- 在从机上执行。功能说明:停止I/O 线程和SQL线程的操作。
stop slave;
-- 在从机上执行。功能说明:用于删除SLAVE数据库的relaylog日志文件,并重新启用新的relaylog文件。
reset slave;
-- 在主机上执行。功能说明:删除所有的binglog日志文件,并将日志索引文件清空,重新开始所有新的日志文件。
-- 用于第一次进行搭建主从库时,进行主库binlog初始化工作;
reset master;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.6、常见错误
则可能的解决办法是:
1)停止stop slave; 再启动start slave;看是否能正常运行
2)两个服务器的防火墙是否关闭,是否互相能ping通
3)配置文件是否正确、是否重启了服务器
4)连接主机的语句是否正确
- 可能是uuid 一致(master,slave uuid) vim /var/lib/mysql/auto.cnf 下更改uuid,重启服务 {克隆的话,提前改}
使用uuidgen生成
错误1
启动主从复制后,常见错误是Slave_IO_Running: No 或者 Connecting 的情况,此时查看下方的 Last_IO_ERROR错误日志,根据日志中显示的错误信息在网上搜索解决方案即可
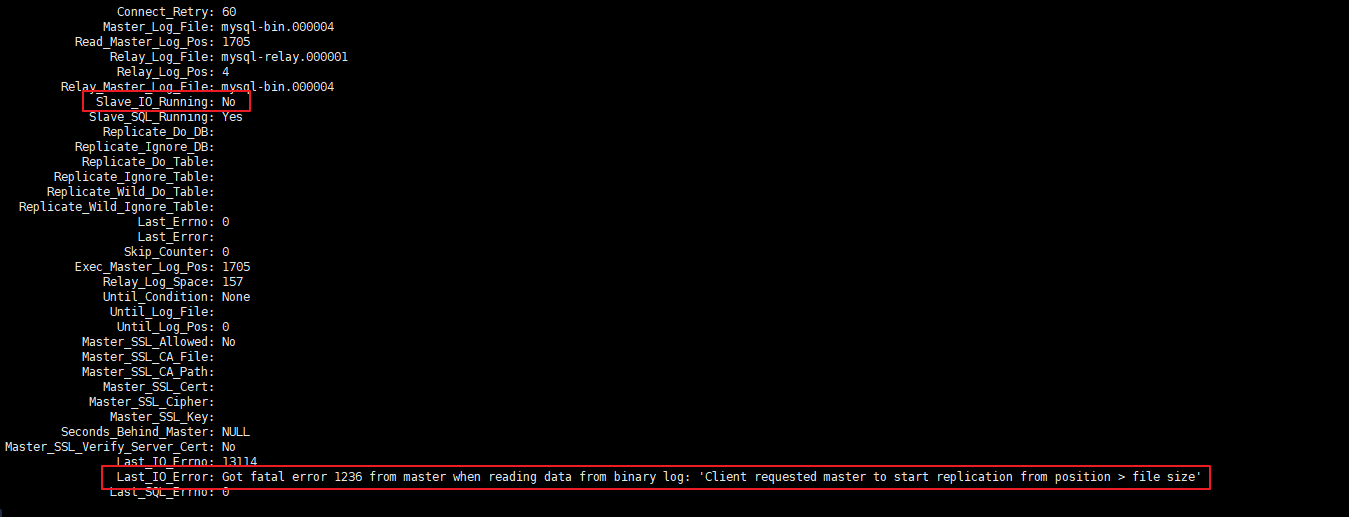
典型的错误例如:Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Client requested master to start replication from position > file size'
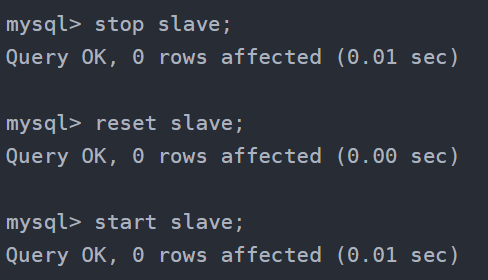
解决方案:
-- 在从机停止slave
STOP SLAVE;
-- 在主机查看mater状态
SHOW MASTER STATUS;
-- 在主机刷新日志
FLUSH LOGS;
-- 再次在主机查看mater状态(会发现File和Position发生了变化)
SHOW MASTER STATUS;
-- 修改从机连接主机的SQL,并重新连接即可
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
错误2
启动docker容器后提示 WARNING: IPv4 forwarding is disabled. Networking will not work.
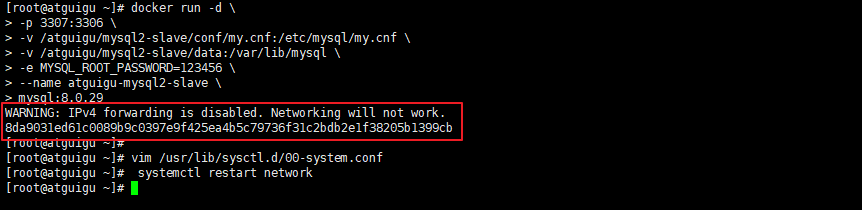
此错误,虽然不影响主从复制的搭建,但是如果想从远程客户端通过以下方式连接docker中的MySQL则没法连接
C:\Users\administrator>mysql -h 192.168.100.201 -P 3306 -u root -p
- 1
解决方案:
#修改配置文件:
vim /usr/lib/sysctl.d/00-system.conf
#追加
net.ipv4.ip_forward=1
#接着重启网络
systemctl restart network
- 1
- 2
- 3
- 4
- 5
- 6
错误3
如果想通过图形客户端连接MySQL,但是报告如下错误,因为旧版本的MySQL图形界面,使用了不同的密码策略
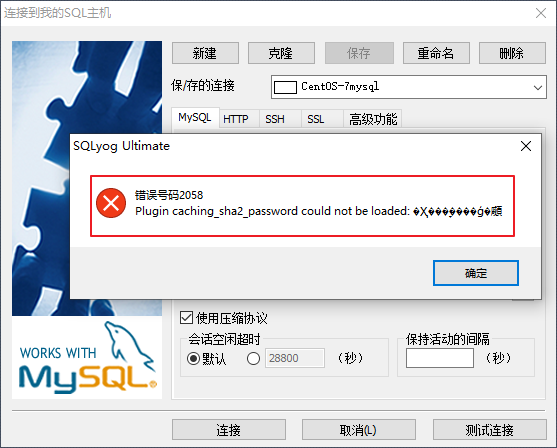
**解决方案:**登录到MySQL的命令行窗口,然后 执行这条SQL:
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '任意密码';
- 1
第03章 MyCat
1、简介
1.1、什么是MyCat
在第一章中我们提到,读写分离和分库分表具体的实现方式一般有两种:中间件封装 和 程序代码封装。
MyCat就是一个数据库中间件。
网址:http://www.mycat.org.cn/

1.2、MyCat的作用
- 读写分离
- 数据库分片
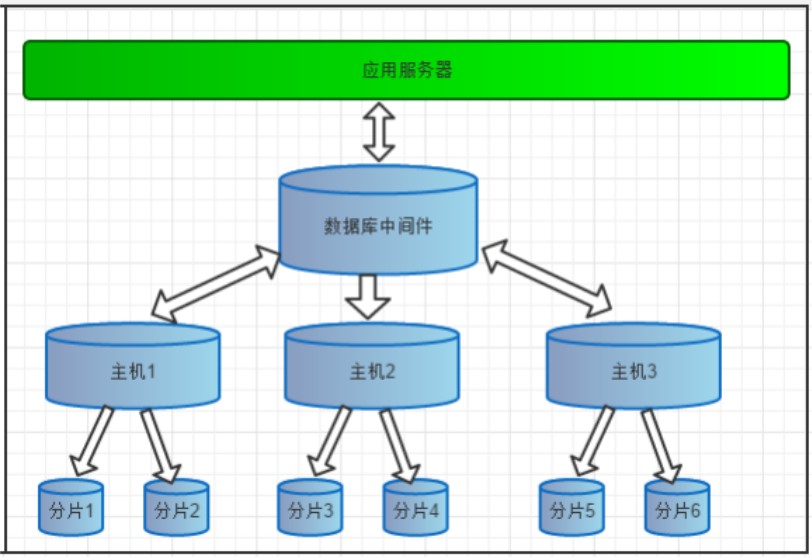
- 多数据源整合
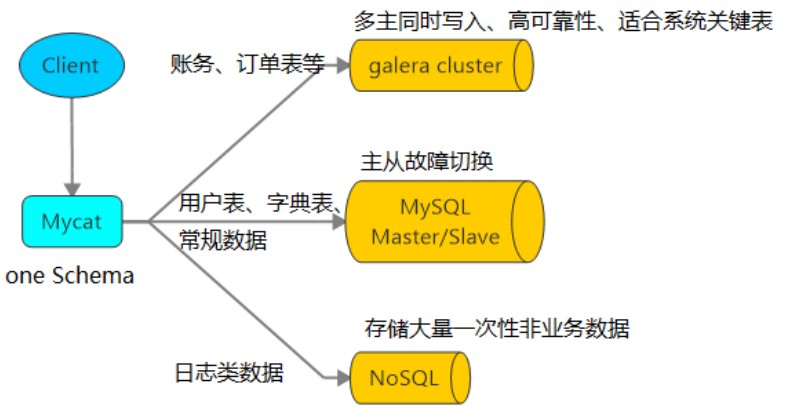
1.3、安装MyCat
因为MyCat没有官方的docker镜像文件,而Linux系统上的MyCat安装也十分方便,因此我们直接将它安装在Linux系统上。
**解压:**MyCat解压即可使用。把课前资料中的Mycat-server-1.6.7.6-release-20220524173810-linux.tar.gz上传到/opt目录下,解压获得MyCat:
cd /opt
tar -zxvf Mycat-server-1.6.7.6-release-20220524173810-linux.tar.gz
- 1
- 2
**配置文件:**打开MyCat目录结构如下

-
bin:二进制执行文件
-
conf:配置文件目录 -
lib:依赖
-
logs:日志
1.2、配置MyCat
**核心的配置有3个:**conf目录
- server.xml:定义用户以及系统相关变量,如端口等
- schemal.xml:定义逻辑库、表、分片节点等内容
- rule.xml:定义分片规则
**server配置:**server.xml中配置了MyCat作为虚拟数据库的基本信息

2、MyCat实现读写分离
2.1、配置
**schema.xml配置:**配置虚拟库(TESTDB)和真实数据库(mytestdb)的映射信息,实现读写分离。
将以下配置替换schema.xml中的内容。
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 虚拟库与真实库的映射 name="TESTDB" 虚拟库的名字,对应刚刚在server.xml中设置的TESTDB sqlMaxLimit="100",允许最大查询记录数 checkSQLschema="false" 是否自动去掉SQL语句 dbname.tablename 前的 dbname dataNode="dn1" 指向虚拟库对应的真实database,值为dataNode标签的name --> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" randomDataNode="dn1"> <table name="mytbl" dataNode="dn1"/> </schema> <!-- 每一个dataNode就是一个数据库分片 name:名称 dataHost:真实库的主机信息,对应<dataHost>标签 database:真实database名称 --> <dataNode name="dn1" dataHost="host1" database="mytestdb" /> <!-- 真实库的主机信息 name:主机名 maxCon:最大连接, minCon:最小连接 balance:负载均衡方式:0~3四种选项。0,不开启读写分离。1~3都开启,区别是主服务器是否参与读 writeType:写负载均衡。永远设置0 dbDriver:驱动类型,推荐native,可选jdbc switchType:主从的自动切换 slaveThreshold:读写分离场景下,主从延迟超出阈值slaveThreshold,则从库不参与此次的负载均衡 --> <dataHost name="host1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="jdbc:mysql://192.168.200.129:3306" user="root" password="123456"> <!-- can have multi read hosts --> <readHost host="hostS1" url="jdbc:mysql://192.168.200.130:3306" user="root" password="123456" /> </writeHost> </dataHost> </mycat:schema>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
**读写分离:**以上配置文件中读写分离的关键配置是:
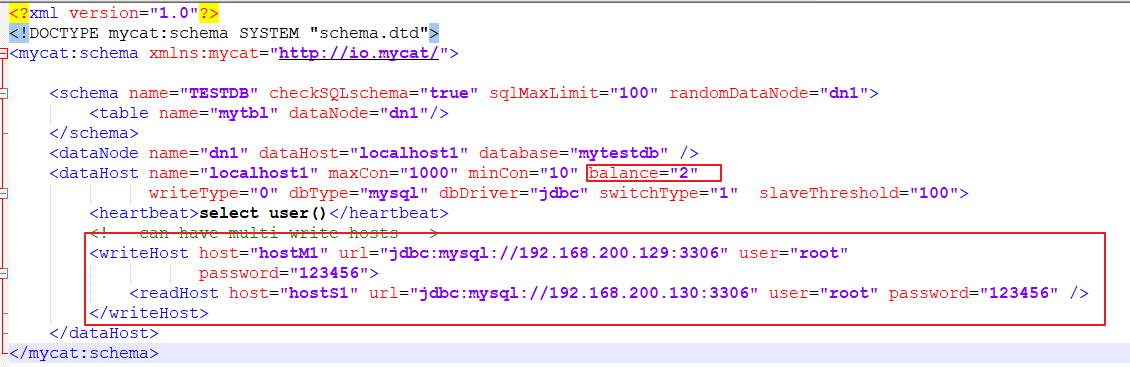
其中balance是负载均衡类型,目前的取值有4 种:
(1)balance=“0”, 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
(2)balance=“1”,全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
(3)balance=“2”,所有读操作都随机的在 writeHost、readhost 上分发。
(4)balance=“3”,所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力
为了能看到读写分离的效果,把schema.xml中的balance设置成2,会在两个主机间切换查询 (2只限于测试,生产环境请选择1或3)
2.2、启动MyCat
# 进入 mycat/bin目录: cd /opt/mycat/bin # 启动: ./mycat start # 控制台启动: ./mycat console # 停止: ./mycat stop # 重启: ./mycat restart # 状态: ./mycat status # 查看日志文件: mycat/logs/wrapper.log
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
首先确认关闭MyCat主机防火墙:
systemctl stop firewalld.service
- 1
连接MyCat:默认端口是:8066
mysql -h192.168.200.129 -P8066 -uroot -p
- 1
在从库中往mytbl表中新增一条数据:
USE TESTDB;
INSERT INTO mytbl VALUES(10, 'atguigu');
- 1
- 2
- 3
在MyCat中查看记录:
SELECT * FROM mytbl;
- 1
读取数据会随机在主 ,从机上!
现在:mycat 安装了 主机下 ip - 129
第一次连接的时候,几乎100% 会出现一个问题! 无效数据! ERROR 1184 (HY000): Invalid DataSource:0
解决方案:
-
如果你windows 有 mysql 的客户端 ,试着用window mysql 客户端连接一下mycat 执行命令!
-
单独在配置一个mycat; {jdk – mysql 的客户端 }
mycat 坑!
3、MyCat数据分片
3.1、mycat分片原理
MyCat的分片实现:

**逻辑库(schema) :**MyCat作为一个数据库中间件,起到一个程序与数据库的桥梁作用。开发人员无需知道MyCat的存在,只需要知道数据库的概念即可。为了让MyCat更透明,它会把自己“伪装”成一个MySQL数据库,因此需要有一个虚拟的 database,在MyCat中也叫逻辑库,英文就是schema。
**逻辑表(table):**既然有逻辑库,那么就会有逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
**分片节点(dataNode):**数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)。
**节点主机(dataHost):**数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
**分片规则(rule):**前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
3.2、分片分析
**注意:**分库分表必须是干净的库和表(不能有数据)
分片原则:
能不切分尽量不要切分。数据量不是很大的库或者表,尽量不要分片。单表行数 500W ,或者数据超过2G,才考虑分库分表!尽量按照功能模块分库,避免跨库join。
#客户表 rows:20万 CREATE TABLE `customer`( id INT AUTO_INCREMENT, NAME VARCHAR(200), PRIMARY KEY(id) ); #订单表 rows:600万 CREATE TABLE `orders`( id INT AUTO_INCREMENT, order_type INT, customer_id INT, amount DECIMAL(10,2), PRIMARY KEY(id) ); #订单详细表 rows:600万 CREATE TABLE `orders_detail`( id INT AUTO_INCREMENT, detail VARCHAR(2000), order_id INT, PRIMARY KEY(id) ); #订单状态字典表 rows:20 CREATE TABLE `dict_order_type`( id INT AUTO_INCREMENT, order_type VARCHAR(200), PRIMARY KEY(id) );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
问题:以上四个表如何分库?
答案:客户表分在一个数据库,另外三张都需要关联查询,分在另外一个数据库。
3.3、创建MySQL服务器
服务器规划:使用docker方式创建,主从服务器IP一致
- 服务器1:容器名
atguigu-mysql-a,端口3308 - 服务器2:容器名
atguigu-mysql-b,端口3309
3.3.1、创建服务器
为了方便,这里我们就不创建配置文件和数据目录的映射了
#先开启防火墙(否则无法创建成功) systemctl start firewalld.service # 创建并启动MySQL服务器a:端口3308 docker run -d \ -p 3308:3306 \ -e MYSQL_ROOT_PASSWORD=123456 \ --name atguigu-mysql-a \ mysql:8.0.29 # 创建并启动MySQL服务器b:端口3309 docker run -d \ -p 3309:3306 \ -e MYSQL_ROOT_PASSWORD=123456 \ --name atguigu-mysql-b \ mysql:8.0.29 #再关闭防火墙 systemctl stop firewalld.service
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3.3.2、创建数据库和表
在atguigu-mysql-a上添加order库
#进入容器:
docker exec -it atguigu-mysql-a env LANG=C.UTF-8 /bin/bash
#进入容器内的mysql命令行
mysql -uroot -p
-- 第一次登录后修改默认密码插件,以便旧版本的图形客户端访问
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
-- 创建数据库
CREATE DATABASE `order`;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在atguigu-mysql-b上添加user库
#进入容器:
docker exec -it atguigu-mysql-b env LANG=C.UTF-8 /bin/bash
#进入容器内的mysql命令行
mysql -uroot -p
-- 第一次登录后修改默认密码插件,以便旧版本的图形客户端访问
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
-- 创建数据库
CREATE DATABASE `user`;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.4、分库实现
停止MyCat
在从机执行
./mycat stop
- 1
- 2
主节点 :dn1 129 创建 orders 数据库 与 三张表
从节点 :dn2 130 创建 orders 数据库 与 一张客户表
配置schema.xml实现MyCat分库:

具体内容如下:
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1" dataNode="dn1"> <table name="customer" dataNode="dn2"/> </schema> <!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743" /> --> <dataNode name="dn1" dataHost="localhost1" database="orders" /> <dataNode name="dn2" dataHost="localhost2" database="orders" /> <!--<dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" /> <dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" /> <dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" /> <dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> --> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="2" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="jdbc:mysql://192.168.200.129:3306" user="root" password="123456"> </writeHost> <!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> --> </dataHost> <dataHost name="localhost2" maxCon="1000" minCon="10" balance="2" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM2" url="jdbc:mysql://192.168.200.130:3306" user="root" password="123456"> </writeHost> <!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> --> </dataHost> </mycat:schema>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
启动MyCat:
./mycat start
- 1
连接MyCat
首先确认关闭MyCat主机防火墙:
systemctl stop firewalld.service
- 1
连接MyCat:默认端口是:8066
mysql -h192.168.200.129 -P8066 -uroot -p
- 1
测试分库
在MyCat中查看有哪些表:
USE TESTDB;
SHOW TABLES;
-- 在MyCat中执行四张表的建表语句,发现table被分别创建在了dn1和dn2中
- 1
- 2
- 3
- 4
- 5
**注意:**有的环境下在MyCat客户端能够创建表到不同的主机下,但由于兼容性问题,看到的表可能不完整
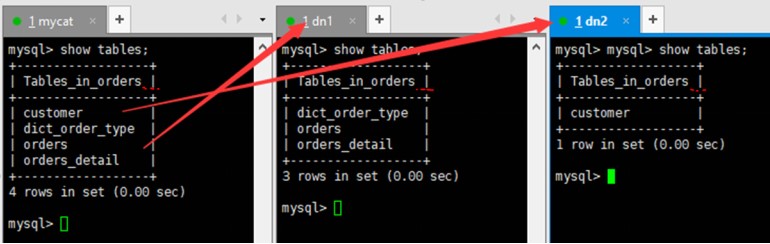
3.5、分表实现
接下来以order表做分表演示
先停止mycat服务:
./mycat stop
- 1
首先在rule.xml中配置分表规则
<tableRule name="order_rule">
<rule>
<columns>customer_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
-- 修改原有配置文件的数据 3---2
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在schema.xml中配置使用分表规则
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1" dataNode="dn1">
<table name="customer" dataNode="dn2"/>
<table name="orders" dataNode="dn1,dn2" rule="order_rule" ></table>
</schema>
- 1
- 2
- 3
- 4
手动在数据节点dn2上建orders表
-- 执行orders的建表语句
#订单表 rows:600万
CREATE TABLE `orders`(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
最后启动mycat
./mycat start
- 1
往MyCat中插入几条数据:
-- 在mycat里向orders表插入数据,INSERT时字段不能省略
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
测试分表
在mycat、dn1、dn2中查看orders表数据,分表成功
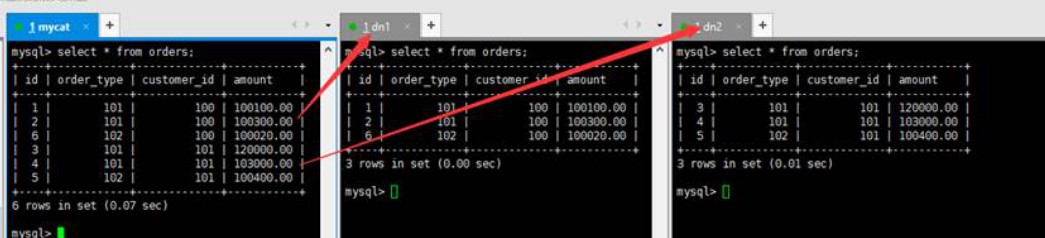
3.6、跨库JOIN
停止MyCat
./mycat stop
- 1
修改schema配置文件
<table name="orders" dataNode="dn1,dn2" rule="order_rule" fetchStoreNodeByJdbc="true">
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" />
</table>
- 1
- 2
- 3
在数据节点dn2上建orders_detail表
-- 执行orders_detail的建表语句
#订单详细表 rows:600万
CREATE TABLE `orders_detail`(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
启动MyCat
./mycat start
- 1
访问Mycat向orders_detail表插入数据
INSERT INTO orders_detail(id,detail,order_id) VALUES(1,'detail1',1);
INSERT INTO orders_detail(id,detail,order_id) VALUES(2,'detail1',2);
INSERT INTO orders_detail(id,detail,order_id) VALUES(3,'detail1',3);
INSERT INTO orders_detail(id,detail,order_id) VALUES(4,'detail1',4);
INSERT INTO orders_detail(id,detail,order_id) VALUES(5,'detail1',5);
INSERT INTO orders_detail(id,detail,order_id) VALUES(6,'detail1',6);
- 1
- 2
- 3
- 4
- 5
- 6
在mycat、dn1、dn2中运行两个表join语句
SELECT o.*, od.detail FROM orders o INNER JOIN orders_detail od ON o.id = od.order_id;
- 1
3.7、全局表
3.7.1、什么是全局表
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,考虑到字典表具有以下几个特性:
(1)变动不频繁
(2)数据量总体变化不大
(3)数据规模不大,很少有超过数十万条记录
鉴于此,Mycat 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
(1)全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
(2)全局表的查询操作,只从一个节点获取
(3)全局表可以跟任何一个表进行 JOIN 操作
3.7.2、配置全局表
停止MyCat
修改schema配置文件
<table name="orders" dataNode="dn1,dn2" rule="order_rule" fetchStoreNodeByJdbc="true" >
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" />
</table>
<table name="dict_order_type" dataNode="dn1,dn2" type="global" ></table>
- 1
- 2
- 3
- 4
在dn2创建dict_order_type表
CREATE TABLE `dict_order_type`(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);
- 1
- 2
- 3
- 4
- 5
启动MyCat
访问Mycat向dict_order_type表插入数据
INSERT INTO dict_order_type(id,order_type) VALUES(101,'type1');
INSERT INTO dict_order_type(id,order_type) VALUES(102,'type2');
- 1
- 2
在Mycat、dn1、dn2中查询表数据

3.8、全局序列
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。
为此,Mycat 提供了全局 sequence,并且提供了包含本地配置和数据库配置等多种实现方式。
3.8.1、本地文件
此方式 Mycat 将 sequence 配置到文件中,当使用到 sequence 中的配置后,Mycat 会更新classpath 中的 sequence_conf.properties 文件中 sequence 当前的值。
优点:本地加载,读取速度较快
缺点:抗风险能力差,Mycat所在主机宕机后,无法读取本地文件。
3.8.2、时间戳方式
全局序列ID = 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加) 换算成十进制为 18 位数的 long 类型,每毫秒可以并发 12 位二进制的累加。

第一位:固定为0 二进制里面第一个bit如果是1,表示负数,我们需要生产的数据都是正数,所以第一位要给 0
41bit: 时间戳
数值取值范围 2^41 -1
10 bit:
前5位可以为机房id, 后5位可以代表机器id。 也可以根据公司的实际情况自由定制。
12 bit: 自增序列
同一毫秒内,同一机器可以产生2^12-1 = 4096 个不同的id。
优点:配置简单
缺点:18位ID过长
3.8.3、自主生成全局序列
可在java项目里自己生成全局序列,如下:
根据业务逻辑组合
可以利用 redis的单线程原子性 incr来生成序列
但,自主生成需要单独在工程中用java代码实现,引入了分布式项目的复杂性。
3.8.4、数据库方式
利用数据库的一个表来进行计数累加。
停止MyCat
在dn1主机上创建全局序列表
CREATE TABLE MYCAT_SEQUENCE (
NAME VARCHAR(50) NOT NULL,
current_value INT NOT NULL,
increment INT NOT NULL DEFAULT 100,
PRIMARY KEY(NAME)
) ENGINE=INNODB;
-- 查询当前序列
SELECT * FROM MYCAT_SEQUENCE;
-- 删除全局序列表
TRUNCATE TABLE MYCAT_SEQUENCE;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
创建全局序列所需函数
官方提供
DELIMITER $$ CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS VARCHAR(64) DETERMINISTIC BEGIN DECLARE retval VARCHAR(64); SET retval="-999999999,null"; SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR)) INTO retval FROM MYCAT_SEQUENCE WHERE NAME = seq_name; RETURN retval; END $$ DELIMITER ; DELIMITER $$ CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNS VARCHAR(64) DETERMINISTIC BEGIN UPDATE MYCAT_SEQUENCE SET current_value = VALUE WHERE NAME = seq_name; RETURN mycat_seq_currval(seq_name); END $$ DELIMITER ; DELIMITER $$ CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64) DETERMINISTIC BEGIN UPDATE MYCAT_SEQUENCE SET current_value = current_value + increment WHERE NAME = seq_name; RETURN mycat_seq_currval(seq_name); END $$ DELIMITER ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
在dn1节点上初始化序列表记录
INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES ('ORDERS', 400000,100);
- 1
修改MyCat配置
修改sequence_db_conf.properties:vim sequence_db_conf.properties
意思是 ORDERS这个序列在dn1这个节点上,具体dn1节点是哪台机子,请参考schema.xml

server.xml
全局序列类型:0-本地文件,1-数据库方式,2-时间戳方式。此处应该修改成1。
1
重启Mycat
验证全局序列
登录MyCat,插入数据
INSERT INTO orders(id,amount,customer_id,order_type) VALUES(NEXT VALUE FOR MYCATSEQ_ORDERS,1000,101,102);
- 1
查询数据
SELECT * FROM orders;
- 1
重启Mycat后,再次插入数据,再查询(模拟Mycat备机上线)
- 并不是每次生成序列都读写数据库,这样效率太低。
- Mycat会预加载一部分号段到Mycat的内存中,这样大部分读写序列都是在内存中完成的。
- 如果内存中的号段用完了 Mycat会再向数据库要一次。
- 问:如果Mycat崩溃了 ,内存中的序列岂不是都没了?
- 是的。如果是这样,那么Mycat启动后会向数据库申请新的号段,原有号段会弃用。
- 也就是说如果Mycat重启,那么损失是当前的号段没用完的号码,但是不会因此出现主键重复

