
- 1显卡的技术参数
- 2飞致云开源社区月度动态报告(2024年2月)
- 3通过ES-Hadoop实现Hive读写Elasticsearch数据_elasticsearch-hadoop
- 4Mac下安装配置git/idea连接GitHub_mac git与idea
- 5部署langchain-chatchat时报错ImportError: cannot import name ‘PromptTemplate‘ from ‘langchain.prompts.chat_cannot import name 'prompttemplate' from 'langchai
- 6【头歌-Python】Python第五章作业(初级)(7~16)_头歌python第五章答案初级
- 7在IDEA上使用token登录github_idea怎么登陆gitlab,一直需要一个token
- 8编程实现将rdd转换为dataframe:源文件内容如下(_Spark Core 解析:RDD
- 9git安装与配置以及操作github最后再说手svn,git,GitHub,gitlab的区别
- 10OSS云存储概念、在阿里云中如何创建、控制台上传下载删除文件以及访问日志设置_阿里云可以设置禁用文件下载
yolov5 网络结构_yolov5头部网络
赞
踩
YOLOv5(You Only Look Once version 5)是目标检测任务中的一种深度学习模型,其网络结构相对简单,但非常有效。下面是一个大概思路,用于明白整个流程,但是我们讲解不按这个走哦。
输入层(Input Layer): YOLOv5的输入层接受图像数据,通常是固定大小的图像。输入图像会经过一系列的卷积和下采样操作,最终生成不同尺度的特征图。
特征提取网络(Backbone): YOLOv5采用CSPDarknet53作为特征提取网络,其中包含了一系列卷积层、批次归一化层和Leaky ReLU激活函数。这一部分负责从输入图像中提取高级特征。
下采样层(Downsampling): 在CSPDarknet53中,包含了多个下采样操作,使得特征图的尺寸逐渐减小。
Neck(特征融合部分): YOLOv5引入了PANet(Path Aggregation Network)用于特征融合,以更好地处理不同尺度的目标。PANet用于合并来自不同层次特征图的信息,提高了模型的性能。
检测头(Detection Head): YOLOv5的检测头包括多个输出层,每个输出层负责检测不同尺寸的目标。每个输出层生成预测框的边界框坐标、类别概率以及目标存在的置信度。
Anchor Boxes(锚框): YOLOv5使用锚框(anchors)作为预测框的基准,不同尺度的特征图对应不同大小的锚框。
激活函数(Activation Function): YOLOv5中使用的激活函数是Leaky ReLU,它在隐藏层中引入非线性。
损失函数(Loss Function): YOLOv5使用的损失函数包括目标位置的均方误差、目标存在的二值交叉熵(BCE)以及类别概率的交叉熵。
YOLOv5的结构遵循先进的目标检测思想,通过使用不同尺度的特征图和锚框,以及引入特征融合的机制,实现对不同尺寸目标的有效检测。这种网络结构使得YOLOv5在速度和准确性之间取得了平衡,适用于多种目标检测任务。
下面我们一点一点攻破这个难题。
1.yolov5网络
基于深度学习的目标检测主要包含三个部分:
骨干网络(Backbone):用于特征提取,已在大型数据集(例如ImageNet|COCO等)上完成预训练,拥有预训练参数的卷积神经网络,例如:ResNet-50、Darknet53等
颈部网络(Neck):在Backone和Head之间,会添加一些用于收集不同阶段中特征图的网络层。
头部网络(Head):主要用于预测目标的种类和位置(bounding boxes)
基于深度学习的目标检测模型的结构是这样的:输入->主干->脖子->头->输出。主干网络提取特征,脖子提取一些更复杂的特征,然后头部计算预测输出。
下面就是yolov5的主要网络结构:
- 骨干网络(Backbone): New CSP-Darknet53
- 颈部网络(Neck): SPPF, New CSP-PAN
- 头部网络(Head): YOLOv3 Head
参考博客:YOLOv5【网络结构】超详细解读总结!!!建议收藏✨✨!_yolov5网络结构详解-CSDN博客
yolov5官网给出了5中模型,我们下面就以yolov5s.yaml举例
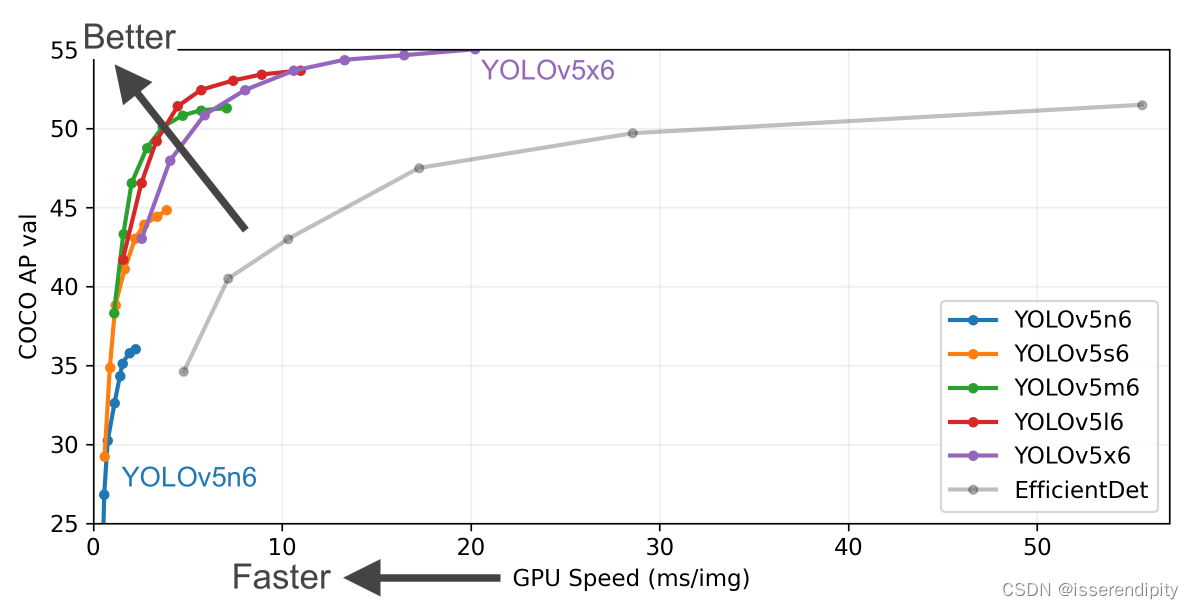
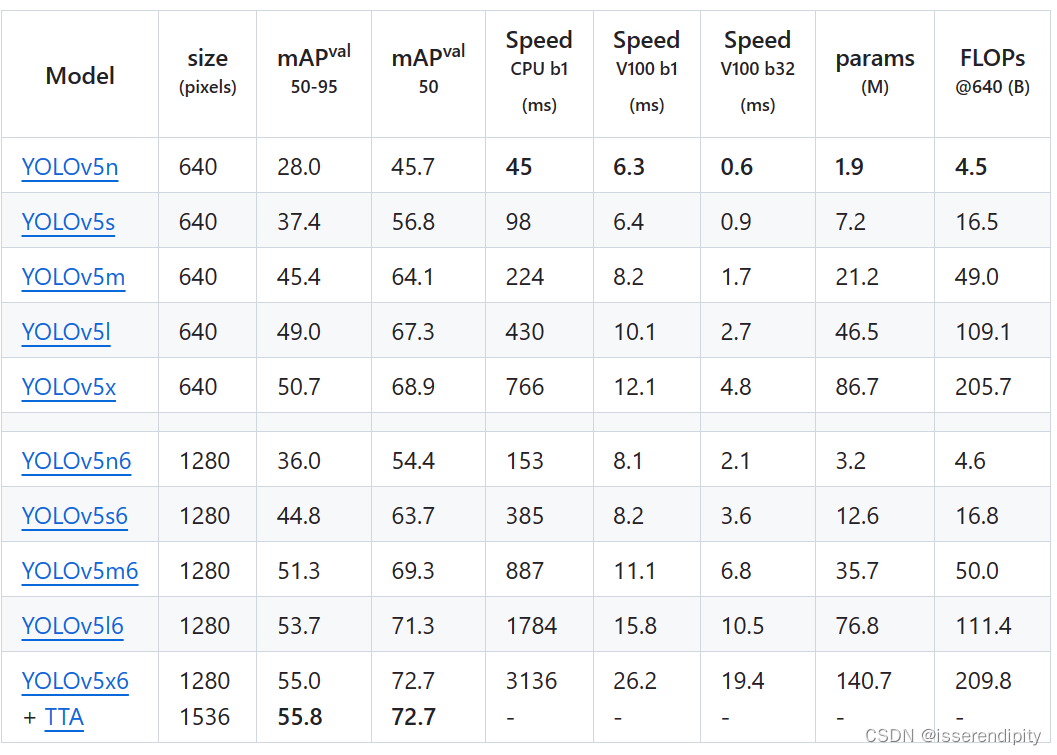
以上数据在官网,大家可以按需索取
一般来说,map越高,参数量(params)越大,速度(speed)越慢,效果越好(需要根据具体模型,具体实验),模型的内存越大。
有一个问题,那就是下面的size变大了,为什么后面那些参数都比上面的大呢,先埋个坑,后面回答。还有那个TTA是什么呢。(可以先跳转到2.3部分看回答)
2.yolov5s.yaml配置部分
这个模型一共有25个模块。
- 推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

