
- 1【转】C# 温故而知新:Stream篇(—)_c#stream的子类
- 2垃圾邮件检测:LSTM与Transformer模型在SpamAssassin数据集上的应用_lstm垃圾邮件分类
- 3网络安全相关证书资料——OSCP、CISP-PTE
- 4阿里云实现短信发送_阿里云发送段兴
- 5500个计算机毕业设计项目推荐(源码+论文+PPT)_计算机毕设项目
- 6Attention注意力机制及其在计算机视觉中的应用_attention+视觉
- 7解决每次打开pycharm都特别慢的几个方法_pycharm启动慢
- 8SpringBoot + Mockito单元测试_spring boot mockito
- 9谁说前端已死?低代码没干掉我,chatGPT 又如何!_前端死路一条
- 10【数据结构与算法】图(Graph)【详解】_graph 图
注意力恢复和地标估计之间的迭代协作实现深度面部超级分辨率(读书笔记)_deep iterative collaboration
赞
踩
Deep Face Super-Resolution with Iterative Collaboration between Attentive Recovery and Landmark Estimation 2020 CVPR

: 注意力恢复和地标估计之间的迭代协作实现深度面部超级分辨率
1、引言
1.1 摘要
主要思想
背景:基于深度学习和人脸先验的工作已经能成功的超分辨 严重退化的人脸图像。
痛点:现有方法没有充分利用先验知识,因为诸如地标和分量图之类的人脸先验信息总是由低分辨率或粗超分辨率图像估计,这可能不准确,从而影响恢复性能。
解决:提出了一种深度人脸超分辨率(FSR)方法,该方法在两个递归网络之间进行迭代协作,分别关注人脸图像恢复和路标估计,两个过程之间的迭代信息交互提高了彼此的性能。在每个循环步骤中,恢复分支利用地标的先验知识来生成更高质量的图像,从而促进更准确的地标估计。此外,设计了一个新的注意力融合模块,以加强地标地图的引导,其中面部组件单独生成并集中注意力,以更好地恢复。
1.2 介绍
背景: An end-to-end trained network [5] introduces facial landmark heatmaps and parsing maps 有一些局限性。
一方面,他们难以估计准确的先验信息,因为定位和对齐过程应用于低质量且远离最终结果的LR输入图像或粗SR图像。因此,给定不精确的先验,SR的指导可能是错误的。
另一方面,大多数方法只是将恢复和先验预测优化为多任务学习问题,并通过简单的级联操作合并先验信息。然而,由于可能无法充分捕捉和利用不同组件的结构变化,因此此类指导不够直接和明确。因此,应该探索更强大的方案来利用面部先验信息。
提出方法: a deep iterative collaboration method for face super-resolution 人脸超分辨率的深度迭代协作方法。

该架构由两个分支组成,一个循环SR分支用于人脸恢复和一个循环校准分支用于地标估计。两个分支相互协作,逐步获得更好的SR图像和更精确的界标
:concatenation 级联
“⊕” : addition 加法
贡献:
①提出 人脸超分辨率的深度迭代协作方法,与以往不同:让人脸识别和对齐过程相互促进
②提出 在每个循环步骤中,每个分支的先前输出都被馈送到下一个步骤中的另一个分支,以便两个分支相互协作以获得更好的性能
③提出 一个新的注意融合模块(attentive fusion module)来整合地标信息,而不是拼接操作(concatenation operation)
首先,作者建立了一个递归架构(recurrent architecture),而不是非常深度的生成模型,同时设计了一个递归沙漏网络(recurrent hourglass network),而不是传统的堆叠沙漏网络(conventional stacked hourglass networks)[25]。在每个循环步骤中,每个分支的先前输出都被馈送到下一个步骤中的另一个分支,以便两个分支相互协作以获得更好的性能。此外,在两个分支中实现的反馈方案都提高了整个框架的效率。其次,作者提出了一个新的注意融合模块(attentive fusion module)来整合地标信息,而不是拼接操作。具体来说,我们利用估计的界标图(attentive fusion module)来生成多个注意力图( multiple attention maps),每一个都揭示了一个面部关键部件的几何结构。受益于特定于组件的注意机制,可以单独提取每个组件的特征,这可以通过组卷积( group convolutions)容易地完成。
2. 详情
2.1 方法
在人脸超级分辨率中,我们的目标是恢复输入LR人脸图像的面部细节 I(LR),和得到SR结果I(SR)。我们设计了一个深度迭代协作网络(a deep iterative collaboration network),该网络通过输入的LR图像,迭代地、逐步地估计高质量的SR图像和地标图。为了增强SR和对齐过程之间的协作,我们设计了一种新的注意力融合模块(attentive fusion module ),该模块有效地集成了两个信息源。最后,我们应用对抗损失来监督框架的训练(an adversarial loss to supervise the training of the framework),并生成具有高保真细节(attentive fusion module )的增强SR人脸.
2.2 具体模块
2.2.1 深度迭代协作( Deep Iterative Collaboration)
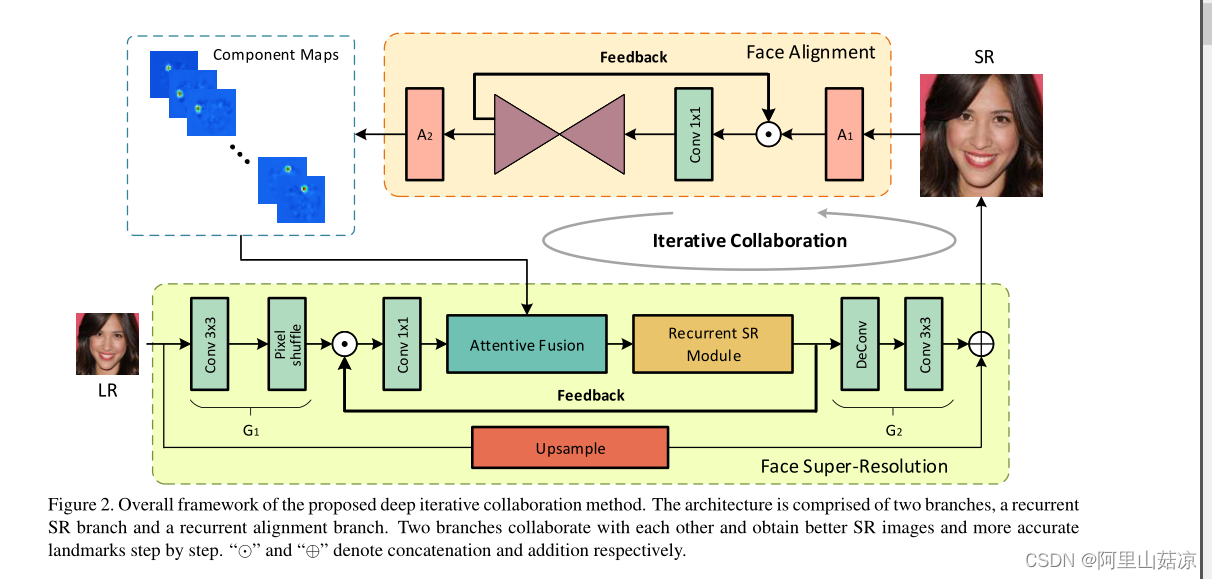
在这个框架中,人脸恢复和地标定位是同时递归执行的。我们可以通过精确的地标图(landmark maps )获得更好的SR图像,因为如果输入面具有更高的质量,则可以更准确地估计地标。这两个过程可以相互增强,并逐步实现更好的性能。 最后,通过足够的步骤,我们可以获得准确的SR结果和关键点热图。

循环SR分支G 由低分辨率特征提取器G1、递归块GR和高分辨率生成层G2组成。GR包括注意力融合模块和循环SR模块(attentive fusion module and a recurrent SR module)。

与SR分支类似,递归对齐分支包括预处理块A1、递归沙漏块AR和后处理块A2。
脸部SR过程(the SR branch ):
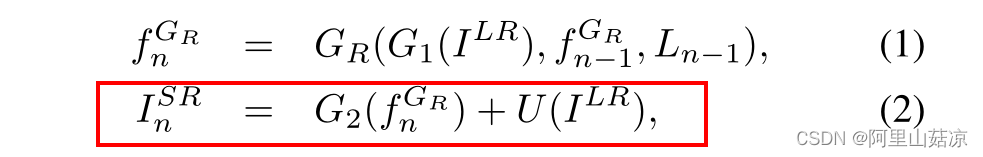
1.对于第n步,其中n=1,···,n,SR分支通过使用对齐结果
和前一步n的反馈信息
来恢复SR图像
2.U表示一个上采样操作
3.
:G1提取的LR特征
面部对齐分支(the face alignment branch):

1.
:上一步的循环特征
2.
:由A1预处理块 从SR图像提取出的SR features
经过N步,我们得到
,随着N的增加,输出更令人满意
注意:在第一次没有来自前一步的循环特征和地标地图,使用了一个额外的类似的SR模块,该模块在第一步之前只将LR特性作为输入,以获得![]() 作为后续步骤的初始化。同时,我们使
作为后续步骤的初始化。同时,我们使![]() 初始化脸对齐分支。
初始化脸对齐分支。
像素级损失函数(the pixel-wise loss functions)

:人脸SR(face SR )损失函数
:地标估计(landmark estimation)损失函数
是地面真实的HR图像和地标热图。
最终输出I(SR):
![]()
2.2.2 注意融合模块(Attentive Fusion Module)
现有痛点:
在现有方法中,直接利用面部先验知识的方法是将面部先验与SR特征连接起来,并将整个优化过程视为多任务学习问题。然而,面部结构可能没有得到充分的利用,因为不同面部的特征通常是由一个共享网络提取的。因此,存在于不同面部组件中的特定结构配置先验可能会被网络所忽略。因此,为了获得更好的性能,不同的面部部件应该被单独恢复。[3] 通过强化学习利用了面部各部分的全局相关性。然而,序列修补重建(the sequential patch reconstruction)不能显式有效地利用面部先验信息,这也限制了对不同面部成分的专门生成。
提出方法:通过一个新的结构感知的专注融合模块来实现上述目标,以便充分利用地标L的指导。
假设每个地标热图有K个通道,表示K个地标的位置。这些地标可以被分成P个子集,属于包括左眼、右眼、鼻子、嘴巴和下颌线在内的面部组件。每组中的通道被加在一起,形成相应面部组件的热图,表示为{Cp}Pp=1,如下图:

左边的部分说明了从关键点地图中提取注意力地图的方法。右侧部分显示了注意力融合模块的流程图。输入特征由卷积层扩展。然后在注意图的指导下,通过一系列的组卷积层来提取构件特有的特征。我们将特征与通过频道维度广播的关注图相乘(“⊗”)。最后,将加权特征相加,形成输出。
使用此方法而不是直接融合学习到的地标的原因:
(1)我们明确地突出了每个面部部位的局部结构来进行差异化恢复;
(2)通过分组过程,通道的数量大大减少,以提高框架的效率。然后,我们可以通过softmax函数沿着这些热图的通道维度计算出P个相应的注意力图

(x,y)代表注意力地图Mp的空间坐标,并且应用分组卷积来生成单个特征fp(如图3)
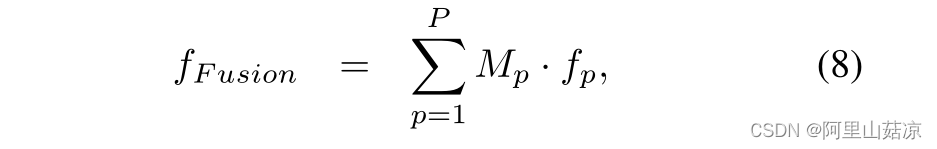
fF usion表示所提出的关注融合模块的输出特征
注意:注意融合模块是递归SR分支的一部分,因此梯度可以递归地反向传播到SR和对齐分支。此外,界标估计不仅可以通过施加在循环对准分支上的损失进行监督,还可以通过注意力融合模块对FSR结果进行修正。
2.2.3 目标函数(Objective Functions)
对抗性损失:
鉴别器D(discriminator D),通过最小化来区分基本真值和超分辨对应值

同时,生成器试图欺骗鉴别器并最小化
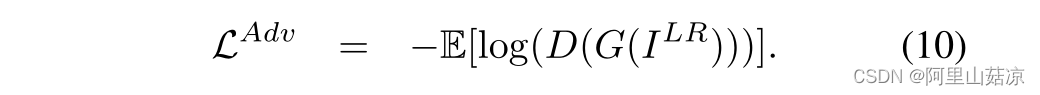
感知损失:
使用感知损失来增强SR图像的感知质量。采用预训练的人脸识别模型LightCNN 对图像进行特征提取。这种损失通过减小SR和HR图像特征φ(ISR)和φ(IHR)之间的欧氏距离来提高感知相似性。
感知损失:

总体目标:
通过最小化以下总体目标函数来优化生成器
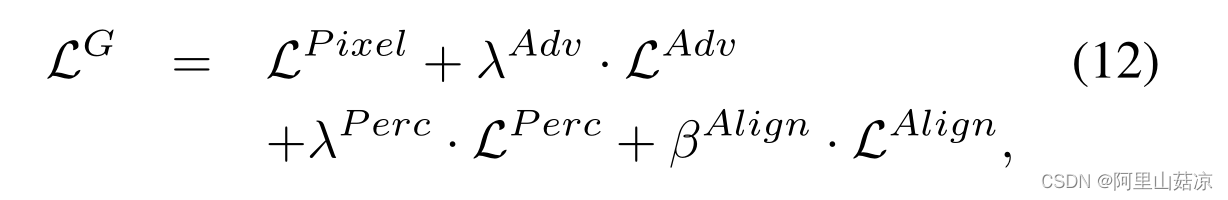
λAdv和λP erc分别表示对抗性损失和知觉损失的权衡参数。由于循环对齐模块作为整个框架的一部分进行了优化,因此总体目标还包括由βAlign加权的这一损失项。为了训练面向峰值信噪比的模型DIC,我们设置λadv=λPerc=0。然后利用完全损失得到感知愉悦模DICGAN。
3. 实验结果
(1)与最新技术的比较:(Comparison with the State-of-the-Arts):
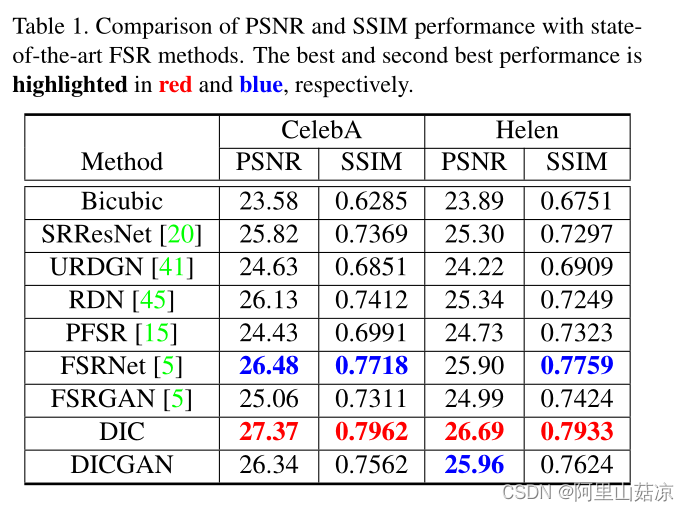
DIC方法与最新的FSR方法进行了比较。表1列出了CelebA和Helen的定量结果。可以观察到,DIC方法在两个数据集上都取得了最好的PSNR和SSIM性能。

DIC恢复了正确的细节,而其他方法都不能得到满意的结果。与最先进的FSR方法的视觉比较。其他FSR方法可能会在关键面部部位产生结构扭曲或产生不期望的伪影。作者提出的DIC和DICGAN方法在处理大姿态和旋转变化方面具有显著优势,其原因是迭代对齐块可以逐步预测更准确的地标来指导每一步的重建,在保留面部结构和生成更好的细节,即使脸部有较大的姿态和旋转。定性比较表明,该方法优于其他FSR方法。最好在屏幕上观看。
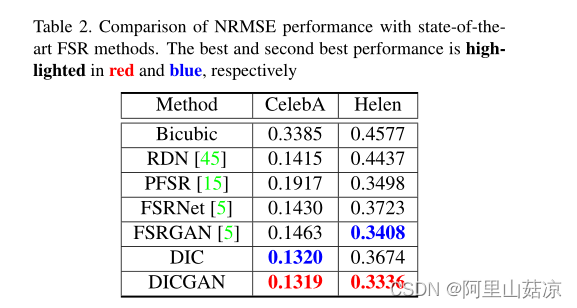
表2 显示了作者的方法和其他比较的SR方法的NRMSE值。我们可以看到DICGAN方法在两个数据集上都优于其他方法。虽然其他SR方法也使用人脸先验,如地标和分量地图,但先验信息是从输入LR人脸图像或面部结构严重不清楚和退化的粗恢复的图像估计。因此,这些面部先验对重建的指导作用有限。因此,恢复的图像也可能包含相应的结构错误。不同的是,作者的方法在每一步都对路标估计进行了修正,以提供更准确的辅助
NRMSE性能与最先进的FSR方法的比较。最佳和次最佳的性能分别用红色和蓝色突出显示
(2)迭代学习研究(Study of Iterative Learning):

CelebA 和 Helen上不同步法的定量比较。最好的结果会被突出显示 。
可以看到从第1步到第4步,性能逐渐变好。表3和表4中的NRMSE值远低于表2中的NRMSE值。原因是参数比表2中用于估计地标的堆叠沙漏模型要少得多,但是能获得更准确的对齐结果,是因为模型能够学习在不同级别的超分辨图像中捕获人脸结构,以便在每个步骤中提供相对准确的地标,更好地协作。

不同步骤的视觉比较。通过迭代协作,视觉质量和定量测量都得到了逐步的改善。
(3)注意融合的效果(Effects of Attentive Fusion):

所提出的注意融合模块的视觉效果。
第一行显示了注意力地图和地面真实图像。第二行是由对应的面部成分特征恢复的SR输出。组件专门化生成验证了所提注意融合模块的有效性。
(4)消融研究(Ablation Study):

当SR网络失去人脸标志提供的引导时,SR网络捕获人脸结构配置的能力减弱,SR质量严重下降。此外,DIC-CL比DIC-NL更有优势,因为它通过串联的方式合并了先验信息。由于集成,还可以观察到较大的增强。然而,dicl - cl方法的SR性能与DIC方法相比还有很大差距。原因是,连接地标地图是面向SR的隐性知识,在提供足够的指导方面是有限的。不同的是,作者的DIC方法不仅集成了结构知识,而且明确地引入了组件专用的特征提取,以获得更逼真的SR图像。

