
- 1java 前端加密后端解密_前端登陆加密和后端解密
- 2NLP的学习笔记(1)_基于统计方法的哲学基础的理性主义方法
- 3OpenStack介绍(及资源)
- 4python使用requests模块下载文件并获取进度提示
- 5C++从入门到精通——auto的使用
- 6激活函数小结:ReLU、ELU、Swish、GELU等_swigelu
- 7[机器学习] 第二章 模型评估与选择 1.ROC、AUC、Precision、Recall、F1_score_怎样在真阳率限制的情况下选择模型
- 8Linux——线程概念与线程的创建
- 9【证明】期望风险最小化等价于后验概率最大化_期望风险最小化 后验概率最大化
- 10osg 倾斜数据纹理_高科技构筑逼真效果——无人机倾斜摄影技术在实景三维建模的应用及展望...
A Comprehensive Overhaul of Feature Distillation
赞
踩
A Comprehensive Overhaul of Feature Distillation
我们研究了实现网络压缩的特征蒸馏方法的设计方面,并提出了一种新的特征蒸馏方法,其中蒸馏损失的设计是为了使教师变换、学生变换、蒸馏特征位置和距离函数等各个方面产生协同作用。我们提出的蒸馏损失包括一个带有新设计的余量ReLU的特征变换、一个新的蒸馏特征位置和一个部分L2距离函数,以跳过对学生的压缩有不利影响的冗余信息。在ImageNet中,我们提出的方法与ResNet50的top-1误差达到21.65%,超过了教师网络ResNet152的性能。我们提出的方法在图像分类、物体检测和语义分割等各种任务中进行了评估,并在所有任务中取得了显著的性能改进。The code is available at bhheo.github.io/overhaul
1. Introduction
在许多使用神经网络的机器学习任务中经历了显著的进步,研究人员已经开始致力于网络压缩和增强。人们提出了几种方法,如模型修剪、模型量化和知识蒸馏,以使模型更小,成本效益更高。其中,知识蒸馏法正在被积极研究。知识蒸馏指的是在一个较大的网络(教师)的监督下,帮助较小的网络(学生)的训练过程的方法。与其他压缩方法不同,它可以缩小网络的规模,而不考虑教师和学生网络之间的结构差异。由于允许架构上的灵活性,知识提炼正在成为下一代网络压缩方法的雏形。
Hinton等人[8]提出了一种使用教师网络的softmax输出的知识提炼(KD)方法。由于两个输出的尺寸相同,这种方法可以应用于任何一对网络结构。然而,高性能教师网络的输出与ground truth没有明显区别。因此,只转移输出类似于用ground truth训练学生,使得输出提炼的性能受到限制。为了更好地利用教师网络中包含的信息,人们提出了几种方法来代替输出蒸馏的特征蒸馏。FitNets[22]提出了一种方法,鼓励学生网络模仿教师网络的隐藏特征值。尽管特征提炼是一种很有前途的方法,但FitNets的性能改进并不明显。
在FitNets之后,人们提出了如下的特征提炼的变体方法。[30, 28]中的方法将特征转化为具有降低维度的表示,并将其转移给学生。尽管降低了维度,但据报道,抽象的特征表示确实导致了性能的提高。最近提出了一些方法(FT[13],AB[7])来增加蒸馏中的传输信息量。FT[13]使用自动编码器将特征编码为一个 “因子”,以减轻信息的泄漏。
AB[7]侧重于激活一个网络,只转移特征的标志(the sign of features)。这两种方法通过增加转移的信息量显示出更好的提炼性能。然而,FT[13]和AB[7]对教师的特征值进行了变形,这给性能的提高留下了进一步的空间。
在本文中,我们提出了一种新的特征蒸馏损失,进一步提高了特征蒸馏的性能,这种损失是通过对教师transform、学生transform、蒸馏特征位置和距离函数等各种设计方面的调查而设计的。我们的方法旨在从特征中转移两个因素。第一个目标是ReLU之后的特征响应的大小,因为它承载了大部分的特征信息。第二个是每个神经元的激活状态。最近的研究[20, 7]表明,神经元的激活状态强烈地代表了一个网络的表现力,在提炼时应该考虑它。

图1. 蒸馏方法的性能。AT [30], FT [13], AB [7]和提议的方法在ImageNet上的表现。图中显示了用每种蒸馏方法训练的ResNet50的准确率(%)。请注意,ResNet152的准确率为78.31%,是作为教师使用的。
为此,我们提出了一个margin ReLU函数,将蒸馏特征位置改为ReLU的前面(change the distillation feature position to the front of ReLU),并使用部分L2距离函数来跳过不必要的信息的蒸馏。所提出的损失明显改善了特征蒸馏的性能。在我们的实验中,我们在不同的领域评估了我们提出的方法,包括分类(CIFAR[15],ImageNet[23]),对象检测(PASCAL VOC[2])和语义分割(PASCAL VOC)。如图1所示,在我们的实验中,所提出的方法显示出优于现有的最先进的方法甚至是教师模型的性能。
2. Motivation

图2. 特征提炼的一般训练方案。教师变换Tt、学生变换Ts和距离d的形式因方法不同而不同。
在本节中,我们研究了实现网络压缩的特征蒸馏方法的设计方面,并介绍了我们的方法与前述方法不同的新方面。首先,我们描述了特征蒸馏法中损失函数的一般形式。如图2所示,教师网络的特征表示为Ft,学生网络的特征为Fs。为了匹配特征维度,分别为Tt和Ts,我们对特征Ft和Fs进行变换。变换后的特征之间的距离d被用作损失函数 L d i s t i l l L_{distill} Ldistill。换句话说,特征提炼的损失函数被概括为

学生网络是通过最小化蒸馏损失 L d i s t i l l L_{distill} Ldistill来训练的。
理想的做法是设计蒸馏损失,以便在不遗漏教师任何重要信息的情况下转移所有特征信息。为了实现这一目标,我们旨在设计一种新的特征蒸馏损失,在这种损失中,所有重要的教师信息都被尽可能地转移,以提高蒸馏性能。为了达到这个目的,我们分析了特征蒸馏损失的设计方面。如表1所述,特征蒸馏损失的设计方面可分为4类:教师变换、学生变换、蒸馏特征位置和距离函数。
Teacher transform. 教师transform Tt将教师的隐藏特征转换为easy-to-transfer form。它是特征提炼的重要部分,也是导致提炼中信息缺失的主要原因。AT[30]、FSP[28]和Jacobian[26]通过教师transform降低了特征向量的维度,造成严重的信息缺失。FT[13]使用由用户决定的压缩比,AB[7]利用二值化形式的原始特征,使得这两种方法使用的特征与原始特征不同。除了FitNets[22],现有方法中的大多数教师变换都会导致在蒸馏损失中使用的教师特征出现信息缺失。
由于特征包括不利信息和有利信息,因此区分它们并避免遗漏有利信息是很重要的。在所提出的方法中,我们使用一种新的ReLU激活,称为margin ReLU,用于教师转换。在我们的margin ReLU中,积极的(有益的)信息被使用,而消极的(不利的)信息被压制。因此,所提出的方法可以在不遗漏有益信息的情况下进行提炼。
Student transform. 通常情况下,学生变换Ts使用与教师变换Tt相同的函数。因此,在像AT[30]、FSP[28]、Jacobian[26]和FT[13]这样的方法中,教师变换和学生变换的信息量都是一样的。FitNets和AB不减少教师特征的维度,并使用1×1的卷积层作为学生的变换,以与教师的特征维度匹配。在这种情况下,学生的特征大小并没有减少,而是增加了,所以没有信息丢失。在我们的方法中,我们使用这种不对称格式的变换作为学生的变换。
Distillation feature position. 除了特征转换的类型外,我们在挑选蒸馏发生的位置时也要注意。FitNets使用一个任意的中间层的末端作为蒸馏点,这已被证明有很差的性能。我们把具有相同空间大小的层组称为层组[29, 3]。在AT[30]、FSP[28]和Jacobian[26]中,蒸馏点位于每个层组的末端,而在FT中它只位于最后一个层组的末端。这导致了比FitNets更好的结果,但仍然缺乏对教师的ReLU激活值的考虑。ReLU允许有益的信息(正面)通过,并过滤掉不利的信息(负)。
因此,知识蒸馏必须在承认这种信息溶解的情况下进行设计**。在我们的方法中,我们设计了蒸馏损失,将特征带到ReLU函数的前面,称为pre-ReLU。正值和负值在前ReLU的位置被保留,没有任何变形。所以,它适合于蒸馏**。
Distance function. 大多数蒸馏方法都天真地采用L2或L1距离。然而,在我们的方法中,我们需要根据我们的教师转换,以及我们在pre-ReLU位置的蒸馏点设计一个合适的距离函数。在我们的设计中,pre-ReLU的信息是由教师转移给学生的,但pre-ReLU特征的负值包含不利的信息。前ReLU功能的负值被ReLU的激活所阻断,不被教师网络使用。所有数值的转移可能对学生网络产生不利影响。为了处理这个问题,我们提出了一个新的距离函数,称为部分L2距离,其目的是跳过对negative区域的信息提炼。

3. Approach
在本节中,我们描述了第2节中概述的蒸馏方法。我们首先描述在我们的方法中发生蒸馏的位置,然后解释新设计的损失函数。
3.1. Distillation position
激活函数是神经网络的一个重要组成部分。神经网络的非线性归功于这个函数。模型的性能受到激活函数类型的显著影响。在各种激活函数中,整流线性单元(ReLU)[19]被用于大多数计算机视觉任务。大多数网络[16, 25, 27, 5, 6, 29, 3, 9, 24]使用ReLU或与ReLU非常相似的修改版本[18, 14]。ReLU只是对正值应用了一个线性映射。对于负值,它消除了这些值并将其固定为零,这就防止了不必要的信息往后走。通过考虑ReLU的知识提炼的精心设计,有可能只转移必要的信息。
遗憾的是,前面的研究大多没有认真考虑激活函数的问题。我们将网络的最小单元,如ResNet[5]中的残差块和VGG[25]中的Conv-ReLU,定义为一个层块。大多数方法中的蒸馏发生在层块的末端,忽略了它是否与ReLU有关。
在我们提出的方法中,蒸馏的位置位于第一个ReLU和层块的末端之间。这个位置使学生在通过ReLU之前就能达到教师的保留信息。图3描述了一些架构的分馏位置。在simple block[16, 25, 27, 9]和residual block[5]的情况下,蒸馏发生在ReLU之前还是之后这一事实构成了我们提出的方法与其他方法的区别。然而,对于使用pre-activation的网络[6, 29],差异较大。
由于每个区块的末尾都没有ReLU,我们的方法必须在下一个区块找到ReLU。在像PyramidNet[3, 24]这样的结构中,我们提出的方法可以在1×1卷积层之后到达ReLU。尽管定位策略可能会根据结构的不同而变得复杂,但它对性能有很大影响。正如我们的实验所证明的那样,我们新的蒸馏位置明显提高了学生的性能。
由于每个区块的末尾都没有ReLU,我们的方法必须在下一个区块找到ReLU。在像PyramidNet[3, 24]这样的结构中,我们提出的方法可以在1×1卷积层之后到达ReLU。尽管定位策略可能会根据结构的不同而变得复杂,但它对性能有很大影响。正如我们的实验所证明的那样,我们新的蒸馏位置明显提高了学生的性能。
3.2. Loss function
根据第2节的格式,我们解释了我们提出的方法中的教师变换Tt、学生变换Ts和距离函数d。由于教师Ft的特征值是ReLU之前的值,正值有教师利用的信息,而负值没有。如果教师的一个值是正的,学生必须产生与教师相同的值。相反,如果老师的一个值是负的,学生应该产生一个小于零的值,以使神经元的激活状态相同。Heo等人[7]指出,要使学生的数值小于零,需要一个margin。因此,我们提出了一个保留正值的教师转换,同时给出一个负的margin。

这里,m是一个小于零的margin值。我们把这个函数命名为margin ReLU。图4中描述了几种类型的教师变换。margin ReLU的设计是为了给出一个比教师的负值更容易跟踪的负值。Heo等人用一个任意的标量值来设置margin,这并不反映教师的权重值。

在我们提出的方法中,margin值m被定义为负响应的 channel-by-channel expectation value,margin ReLU使用对应于输入的每个通道的值(and the margin ReLU uses values that correspond to each channel of the input)。对于一个通道C和教师特征 F t i F^i_t Fti的第i个元素,一个通道的margin m C m_C mC被设定为所有训练图像的期望值。

期望值可以在训练过程中直接计算,也可以用前一batch归一化层的参数计算。在我们提出的方法中,margin ReLU σ m C ( ⋅ ) σ_{m_C}(\cdot) σmC(⋅)被用作教师变换Tt,为学生网络产生目标特征值。对于学生变换,使用一个由1×1卷积层[22, 7]和批量归一化层组成的回归器。
现在我们解释一下我们的距离函数d。我们提出的方法transfers the representation before ReLU。因此,考虑到ReLU,距离函数应该被改变。在教师的特征中,positive responses实际上是用于网络的,这意味着教师的positive responses应该通过它们的准确值来转移。然而,negative responses却没有。
对于教师的negative responses,如果学生的反应高于目标值,就应该减少,但如果学生的反应低于目标值,就不需要增加,因为negative responses无论其值如何,都同样被ReLU所阻断。对于教师和学生的特征表示, T , S ∈ R W × H × C T ,S∈\mathbb R^{W×H×C} T,S∈RW×H×C,让张量的第i个分量为Ti,Si∈R。 我们的部分L2距离(dp)定义为

其中T是教师特征的位置,S是学生特征的位置。
我们提出的方法使用边际ReLU σ m C ( x ) σ_{m_C}(x) σmC(x)作为教师变换Tt,使用由1×1卷积层组成的回归器 r ( ⋅ ) r(\cdot) r(⋅)作为学生变换Ts,并使用部分L2距离(dp)作为距离函数。所提方法的蒸馏损失为:

我们提出的方法是使用蒸馏损失Ldistill作为连续蒸馏进行的。因此,最终的损失函数是蒸馏损失和任务损失之和。

任务损失指的是一个网络的任务所规定的损失。如图3所示,提炼的特征位置是在一个空间大小的最后一个块之后和ReLU之前。在一个输入为32×32的网络中,如CIFAR[15],有三个目标层,而在ImageNet[23]中,目标层的数量为四个。
3.3. Batch normalization
我们进一步研究知识提炼中的批量归一化。批量归一化[11]被用于最近的网络架构中,以稳定训练。最近一项关于批规范化的研究[10]解释了批规范化的训练模式和评估模式之间的区别。批量规范化层的每种模式在网络中的作用是不同的。因此,在进行知识提炼时,有必要考虑是在训练模式还是评估模式下使用教师。
通常情况下,学生的特征是逐批规范化的(normalized batch by batch)。因此,来自教师的特征也必须以同样的方式进行规范化。换句话说,在提炼信息时,教师的批归一化层的模式应该是训练模式。为了做到这一点,我们在1×1卷积层之后附加了一个batch normalization层,并将其作为学生transform,将来自老师的知识以训练模式带入。因此,我们提出的方法实现了额外的性能改进。这个问题适用于所有的知识提炼方法,包括我们提出的方法。
我们在第4.5.3节中实证分析了针对批量规范化问题的各种知识提炼方法。
4.5. Analysis
我们分析了可能的因素,这些因素会导致我们提出的方法的性能提高。第一个分析是通过蒸馏法学习的教师和学生之间的输出相似度。通过这一点,我们验证了我们的方法在多大程度上迫使学生跟随老师。之后,我们对我们提出的方法进行了消减研究。我们衡量了我们提出的方法的每个组成部分对性能的贡献程度。最后,我们讨论了第3.3节中提到的批量规范化的模式是如何影响知识提炼的。所有的实验都是基于表2的设置(c)。

表2. CIFAR-100上各种网络架构的实验设置。网络架构表示为WideResNet(深度)-(通道乘法),用于Wide Residual网络[29],PyramidNet-(深度)(通道系数)用于PyramidNet[3]。
4.5.1 Teacher-student similarity
KD[8]迫使学生的输出与教师的输出相似。输出蒸馏的目的是很直观的,即如果一个学生产生的输出与教师的输出相似,其表现也会相似。然而,在特征蒸馏的情况下,有必要调查学生的输出如何变化。为了了解学生对老师的模仿程度,我们在一个一致的设置下测量老师和学生的输出的相似性。在CIFAR-100的测试集上,我们测量教师和学生输出之间的KL散度。
由于分类性能也有助于减少KL分歧,所以也测量了与ground truth的交叉熵。结果列于表7。只在训练的早期阶段应用蒸馏的方法,初始蒸馏(FitNets[22],AB[7]),增加了与教师和ground truth的KL散度。根据这个结果,很难说这些方法的学生网络在模仿他们的教师网络。

同时,公式6中的连续蒸馏方法(KD[8],AT[30],Jacobian[26],FT[13])以及我们提出的方法都减少了KL散度,这意味着教师和学生的相似度相对较高。具体来说,与其他连续蒸馏方法相比,我们的方法显示出相当高的相似度。换句话说,我们提出的方法可以训练学生产生与老师最相似的输出。这种相似性是我们提出的方法性能提高的主要原因之一。
4.5.2 Ablation study
进行了消融实验,其中逐一添加了消融成分,以测量其效果。结果显示在表9中。基线是基于区块末端位置的L2损失的蒸馏方法。使用ReLU前位置的版本(第3.1节)提供了最大的改进,因为它有助于在ReLU前用负值和正值有效转移激活边界。第二个改进是由损失函数(第3.2节)实现的,它可以防止转移无用和有害的小于小负值的负值。The batch-norm mode(第3.3节)也对性能的提高做出了贡献。总之,所有建议的组件的组合导致了拟议方法性能的显著提高。

4.5.3 Batch normalization
在第3.3节中,我们提到了与知识蒸馏中批BN的模式有关的问题。为了研究这个问题,我们测量了当教师的BN的模式不同时,知识蒸馏方法的性能变化。实验结果如表8所示。使用特征以外的其他信息的蒸馏方法(KD[8],Jacobian[26])在每一种批规范化模式之间都显示出marginal 差异。

AT[30]使用减弱的特征进行蒸馏,在评估模式下表现出更好的效果。然而,不挤压特征的方法(FitNets[22]、FT[13]、AB[7])在训练模式下始终表现得更好。我们的方法在使用训练模式时尤其显示出大幅度的改进。请注意,前面几节的所有实验都是利用了批判性规范层的较好模式,因为每篇论文中都没有提到这一点。总之,在包括我们的方法在内的许多蒸馏方法中,应该仔细选择适当的批量规范化类型。
Appendix
A. margin evaluation
我们计算了每个通道的margin,并使用margin ReLU与通道margin
m
C
m_C
mC。margin是特征负值的期望值,可以在训练过程中直接获得,也可以使用批量规范化层。我们解释一下如何使用批量规范层来获得margin。对于一个通道C和教师特征
F
t
i
F^i_t
Fti的第i个元素,通道
m
C
m_C
mC的margin被设定为训练图像上的期望值。
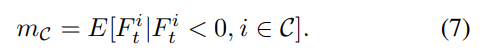
一般来说,我们不可能知道
F
t
i
F^i_t
Fti的分布,所以必须通过训练过程中的平均运算(average operation)来获得期望值。然而,当ReLU之前有一个BN层时,BN层决定了一个batch的特征
F
t
i
F^i_t
Fti的分布。BN层将每个通道的特征归一化为具有特定均值μ和方差σ的高斯分布。
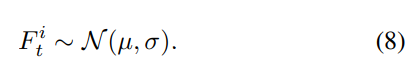
每个通道的均值和方差(μ,σ)的值对应于BN层的参数(β,γ)。所以,它可以通过分析教师网络得到。利用
F
t
i
F^i_t
Fti的分布,我们可以直接计算出margin的值。
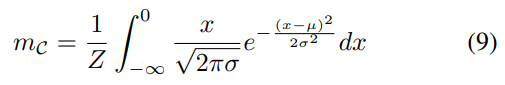
使用高斯分布的pdf进行积分可以得到期望值,其中范围小于零。积分的结果可以用正态分布的cdf函数Φ(-)以简单的形式表示。
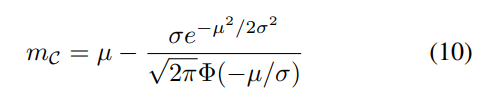
利用公式10,所提出的方法在训练过程中不需要采样和平均,就可以得到channel-wise的margin。在本文的实验中,如果ReLU之后是batch normalize,则通过使用公式10获得margin。否则,期望值由训练过程中的平均操作获得。

