
- 1one-hot编码
- 2基于Django 框架搭建学习平台系统,实现KNN、ID3、C4.5、SVM、朴素贝叶斯、BP神经网络等算法及流程管理 附代码_编程实现knn算法、id3算法以及c4.5算法
- 3matlab simulink_简单五步实现 MATLAB/Simulink 锂电池建模
- 4英文文本关键词抽取——使用NLTK进行关键词抽取_使用nltk抽取 英语文本关键词 例子
- 5ArcGIS二次开发(一)——搭建开发环境以及第一个简单的ArcGIS Engine 程序_arcengine vs
- 6Unet代码实现(PyTorch)_unet代码pytorch
- 7阿里云国际站:云服务器ECS如何查看快照以及快照容量?_阿里云快照在哪里找
- 8ubuntu 安装配置 ollama ,添加open-webui_ollama ubuntu
- 9UTF-8汉字编码16进制对照---转载_::4c4c937b67cc8d785cea1e42ccea185c:6012
- 10剑桥寒假项目-手语识别笔记_csl中国手语数据
探索图文处理的未来:知名学府与合合信息团队分享NLP实践经验,人工智能引领技术革新_智能图文与nlp
赞
踩
相信最近很多朋友关注的公众号和短视频号都有关于ChatGPT的文章或者视频,对此我就不再过多描述“生成式人工智能”是促成ChatGPT落地的重要技术,“ChatGPT之父”阿尔特曼曾说:“我认为我们离生成式人工智能还有一定距离。至于判断标准,根据我过去五年甚至更长时间的观察和思考,生成式人工智能的诞生是一个渐进式过程(也就是所谓的“缓慢起飞”),而不会是某一清晰的时刻——至少不会是某个获得公认的清晰时刻。”
既然生成式人工智能的诞生是一个渐进式过程,那么哪些领域场景将会逐渐展现出强大的人工智能适用性呢?在由中国图象图形学学会(CSIG)主办,合合信息、CSIG文档图像分析与识别专业委员会联合承办的“CSIG图像图形企业行”活动中,我们得以思索一二。
此次活动以“图文智能处理与多场景应用技术展望”为主题,特邀来自上海交大、厦门大学、复旦大学、中科大的学者与合合信息技术团队一道,面向行内研究者分享图像文档处理中的结构建模、底层视觉技术、跨媒体数据协同应用、生成式人工智能及对话式大型语言模型等研究及实践成果。
一、生成式人工智能是否会是下一个风口?
上海交通大学人工智能研究院杨小康院长在大会上分享了生成式人工智能与元宇宙为主题的技术研究。
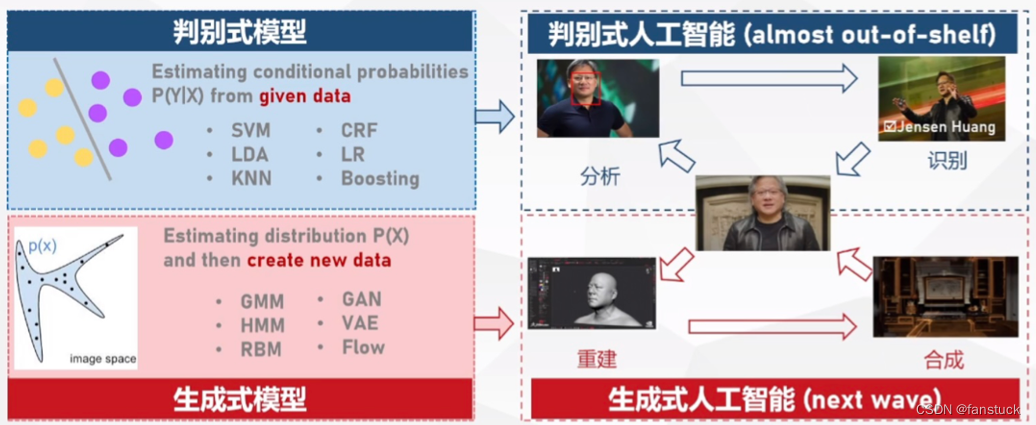
1.何为生成式人工智能?
判别式人工智能是以“分析-识别”为基础,开拓了目标识别和分类回归等一系列的研究应用,而生成式人工智能则以“重建合成”方式用于生成各种形式的内容。生成式人工智能是一种人工智能技术,可以学习大量数据并生成与原始数据类似的新数据。生成式人工智能通常使用神经网络或其他机器学习算法来学习数据的模式和规律,并使用这些模式和规律生成新的数据。与传统的分类或回归任务不同,生成式人工智能的目标是生成新的数据而不是对现有数据进行分类或回归。
生成式人工智能通常有两种主要的方法:基于概率模型的生成式模型和基于深度学习的生成式模型。基于概率模型的生成式模型使用概率分布来描述数据的生成过程,并从中抽样生成新的数据。基于深度学习的生成式模型通常使用变分自编码器(VAE)或生成对抗网络(GAN)等深度学习模型来生成新的数据。这些模型可以从数据中学习到复杂的分布和模式,并使用这些分布和模式来生成新的数据。
2.生成式人工智能面临的挑战
生成式人工智能的应用范围非常广泛,但它也面临着一些挑战:
数据不足:生成式人工智能需要大量的数据才能学习到数据的模式和规律,但在某些领域中,如医疗、金融等,数据的获取和共享可能受到限制,因此可能会面临数据不足的问题。
模型不稳定:生成式人工智能模型通常比传统的分类或回归模型更加复杂,因此可能会面临模型不稳定的问题,即同样的输入数据可能会生成不同的输出数据。
难以控制生成结果:生成式人工智能生成的数据通常是自动生成的,因此难以对其进行控制,无法保证生成结果的准确性和可靠性。
生成结果可能不符合伦理和道德标准:生成式人工智能可能生成具有敏感性和争议性的内容,如虚假新闻、歧视性评论等,这可能会对社会和公众产生负面影响。
难以评估和验证:生成式人工智能生成的数据通常没有明确的标准和指标来评估其质量和准确性,因此难以进行验证和评估。
针对这些挑战,研究人员正在开发新的方法和技术来解决这些问题,如使用更加稳定的模型结构、引入更多的约束和先验知识来控制生成结果等。同时,加强伦理和道德标准的监管和规范也是必要的。

3.生成式人工智能场景运用
杨小康院长还分享了生成式世界模型以及生成式虚拟数字人,通过此类技术可以让世界模型更逼近物理现实: 表观模拟到物理现象内部机理去推断,使得数字人更逼真、更通用:;在世界模型上训练智能体,可反哺真实世界中的决策过程,通过立体视觉渲染、多模态驱动、动态模拟技术实现数字人与世界模型交互。

此外,他还介绍了物理现象的视觉仿真与推理: 神经流体研究上的一些突破进展,以及世界模型的持续预测学习的挑战和难点,世界模型表征解耦等学术研究。总结为生成式人工智能为构建基于视觉直觉的物理世界模型和虚拟数字人提供了可行的途径。
此外生成式人工智能在各个领域都有广泛的应用:
文本生成:生成式人工智能可以用来生成各种类型的文本,如新闻文章、小说、诗歌等。这项技术可以被应用于自动化写作、智能客服、智能推荐等场景中。
图像生成:生成式人工智能可以生成新的图像,例如艺术风格转换、图像修复、视频超分辨率等。这项技术可以被应用于电影制作、视频游戏开发、产品设计等场景中。
音频生成:生成式人工智能可以生成各种类型的音频,如音乐、人声、环境声音等。这项技术可以被应用于音乐创作、语音合成、声音修复等场景中。
对话生成:生成式人工智能可以通过学习人类对话的模式和语言规律来生成对话。这项技术可以被应用于智能客服、智能语音助手等场景中。
视频生成:生成式人工智能可以生成新的视频内容,例如视频剪辑、视频合成、视频特效等。这项技术可以被应用于电影制作、广告制作、视频游戏开发等场景中。
3D模型生成:生成式人工智能可以生成各种类型的3D模型,如人物、建筑、汽车等。这项技术可以被应用于产品设计、游戏开发、虚拟现实等场景中。
总之,生成式人工智能在各种场景中都有广泛的应用,可以帮助人类创造更多、更优秀的内容,并提高人类的生产力和创造力。
二、复杂图文处理的未来发展将如何?
中国科学技术大学语音及语言信息处理国家工程研究中心副教授杜俊就团队在文档结构层次化重建领域的最新进展进行分享:如何让机器像人一样可以结合不同模态信号认识理解世界。
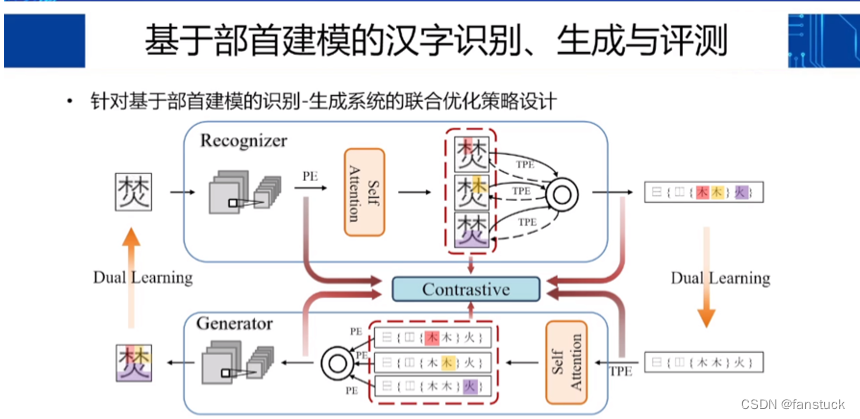
1.更深层次的汉字解构研究
基于部首建模的汉字识别、生成与评测,是一种利用汉字的组成部分(部首)来进行汉字处理的方法。该方法可以应用于汉字的识别、生成和评测等多个领域。可以有效提高识别的准确率和速度,用于自动生成汉字书法字体,或者用于生成汉字组合成语言文字,如汉藏语、汉文蒙文等。

基于部首建模的汉字识别、生成与评测的实现过程是一个基于数据、特征和模型的训练和应用过程,需要涉及到数据处理、特征提取、模型训练、预测和优化等多个方面的技术和方法。
部首分解:将汉字按照部首进行分解,得到每个汉字的部首组成部分。
特征提取:对每个部首进行特征提取,例如提取每个部首的笔画数、形状、结构等特征。
模型训练:基于提取的特征,建立机器学习模型,例如支持向量机(SVM)、神经网络等模型,并利用已知的汉字数据集进行训练。
2.自动分析表格结构
杜俊教授提出基于SEM的表格结构识别,SEM(Structural Element Matching)是一种基于结构元素匹配的表格结构识别方法。该方法的原理是在表格识别过程中,将表格的结构看作一种由多个结构元素组成的结构,并将每个结构元素表示为一组特征,然后通过比对待识别表格和预定义的结构元素库中的结构元素,来确定待识别表格的结构和单元格内容。
具体而言,SEM的步骤如下:
预处理:对待识别表格进行预处理,包括图像二值化、去除表格线等。
结构元素库构建:构建包含常见表格结构元素的结构元素库,如表头、行、列、合并单元格等。
特征提取:对待识别表格中的每个像素点提取一组特征,如像素点的颜色、位置、大小、形状等。
结构元素匹配:将待识别表格中的每个像素点的特征与结构元素库中的结构元素进行比对,找出与之最匹配的结构元素。
结构元素组合:根据匹配结果,将结构元素组合成表格的结构和单元格内容。
通过这样的方式,SEM能够对表格进行准确的结构和内容识别,具有较高的准确率和鲁棒性。但是,该方法需要预定义结构元素库,因此对于不同类型和形式的表格,需要进行相应的结构元素库设计和优化,这可能会带来一定的挑战。

3.更精细化的文档解构模型
杜俊教授提还出现阶段文档分析任务中,大多数研究是针对单页内的文章要素的解析,但从内容角度看,许多文档页与页之间内容有关联。该方法的原理是利用预训练的语言模型(如BERT、GPT等)对篇章级的文档进行编码和表示,然后使用相应的解码器将文档中的每个句子或段落与相应的结构类型(如标题、正文、列表等)进行匹配和分类。在这个过程中,模型通常会利用上下文信息、语法规则和语义知识等多个方面的信息,以提高分类的准确性和鲁棒性。
具体而言,该方法的步骤如下:
预处理:对篇章级的文档进行预处理,如分句、分段、去除停用词等。
文档编码:使用预训练的语言模型对文档中的每个句子或段落进行编码,得到其语义表示。
结构类型分类:将文档中的每个句子或段落与相应的结构类型(如标题、正文、列表等)进行匹配和分类,通常使用基于机器学习或深度学习的分类器来实现。
结构化输出:将分类结果转化为结构化的数据,如HTML、XML或JSON等格式,以便进行自动化处理和分析。
这种方法的优点在于可以将篇章级的文档转化为结构化的数据,使得文本数据的自动化处理和分析变得更加容易和高效。但是,该方法需要大量的标注数据和计算资源来训练和优化模型,因此对于某些场景可能不太适用。

三、人工智能结合机器视觉又会在图文处理有何种突破?
1.底层视觉与图像扫描的结合
底层视觉(Low-level vision)主要研究如何提高或恢复各类场景下的图像/视频内容,如清晰度提升,低质量及破损图像恢复等,是计算机视觉领域的重要研究方向之一。其理论和方法在手机图像采集与处理,医疗图像分析等领域发挥着至关重要的作用。底层视觉技术的缺陷将会导致很多high-level视觉系统(检测,识别理解)难以作为成熟产品真正落地。合合信息郭丰俊博士在本次报告中,分享了合合信息技术团队在文档图像处理系统中所做的底层视觉研究工作,从底层视觉技术的直接应用及对下游任务的影响等方面,阐述底层视觉技术在文档图像处理/识别场景下的价值与思考。
2.文档处理与人工智能的结合
文档处理与人工智能的结合,是指将人工智能技术应用于文档处理领域,通过自然语言处理、图像识别、机器学习等技术,对文档进行自动化处理和分析。
具体而言,文档处理与人工智能的结合可以实现以下功能:
1. 文本识别:通过图像识别技术,将纸质文档或扫描件转化为可编辑的文本格式,以便进行后续处理和分析。
2. 文本分类:通过机器学习技术,将文本按照特定的分类方式进行自动分类,如按主题、按语言、按情感等。
3. 信息抽取:通过自然语言处理技术,从文本中自动抽取出特定的信息,如人名、地名、时间等,以便进行自动化处理和分析。
4. 文本摘要:通过自然语言处理技术,将长篇文本自动化地进行摘要,提取出其中的关键信息,以便浏览和阅读。
5. 文档翻译:通过自然语言处理技术,将文档进行自动翻译,实现多语言文档的处理和分析。
6. 知识图谱:通过自然语言处理和图谱技术,将文档中的知识点提取出来,并将其构建为知识图谱,以便进行知识管理和分析。
文档处理与人工智能的结合,可以实现对大量文档的自动化处理和分析,提高工作效率和准确性,降低人力成本和时间成本,对于企业的知识管理和业务分析具有重要的意义。
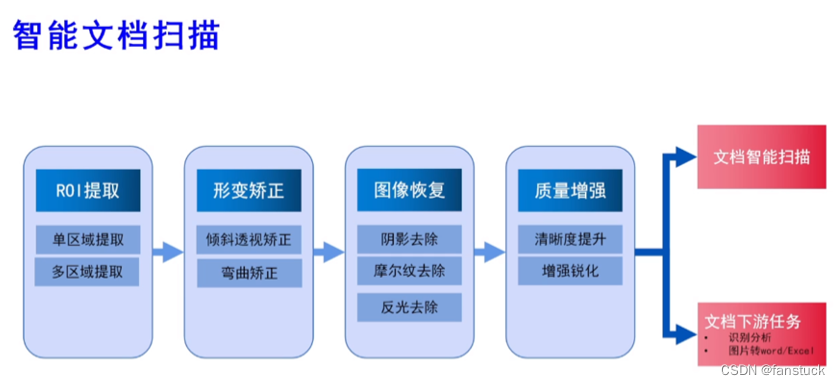
合合信息智能文档处理技术采用精准的图像裁剪、形变矫正以及去除阴影和摩尔纹等技术,利用人工智能技术对文档图像进行增强和清晰度提升,从而提高文档图像的质量和阅读体验。通过这种方法,可以有效提升文档处理下游任务的质量和效率,例如识别转换和图像分析等。目前,该技术已经被应用于智能文字识别产品,为来自全球上百个国家和地区的数亿用户提供了服务。

四.活动展望总结
根据众位学术技术大咖的分享来看,未来图文智能处理的发展将会更加智能化、自动化和可定制化。具体来说,未来的图文智能处理技术将会更加注重生成式人工智能技术的应用,例如深度学习、自然语言处理、计算机视觉等。这将使得处理效果更加准确和高效。同时,未来的图文智能处理技术将会更加自动化,例如自动识别文档类型、自动分类文档、自动提取文档信息等,这将进一步提高文档处理的效率和准确性。此外,未来的图文智能处理技术也将会更加可定制化,根据不同的行业和应用场景,为客户提供量身定制的解决方案。这将有助于满足客户的不同需求,提升客户的体验和满意度。

